この記事はリンクアンドモチベーションアドベントカレンダー2022の20日目の記事です。
テックブログのお知らせ
弊社ではテックブログもやっております。宜しければこちらもどうぞ!
https://link-and-motivation.hatenablog.com/
はじめに
私は、2021年に新卒入社して以来、データチームでデータサイエンティストとして働いています。
私たちのチームでは、機械学習によって解約予測モデルを作成することでヘルススコア1を算出し、
顧客価値向上のためのPDCAサイクルを回す材料にしています。
(私たちの取り組みはこちらの記事(データ民主化を進める上で大事な3つの事)でも紹介しています。)
本記事では、現在私たちが使用している解約予測モデルの技術紹介と、NumPyroという確率プログラミングのパッケージの紹介もしていきます。
これまで
現在の解約予測モデルの形に至るまで、様々な紆余曲折を経てきました。
ここではその一部をご紹介します。
ブラックボックスモデル
当初はLightGBMなどのブラックボックスモデルを使っていました。
ブラックボックスモデルのいいところは、とにかく特徴量をたくさん盛り込むことで、
機械が特徴量間の優劣を自動的に判断し、最も精度の良いモデルを作ってくれることです。
解約予測の精度は高くなりましたが、特徴量の重みがどのようなカスタマーサクセスのストーリーに沿っているか説明できず、
結果として、なぜ解約リスクがあるのか、どうしたら解約阻止できるのか、という説明可能性が乏しかったことで、
目的である「顧客価値向上のためのPDCAサイクルを回すこと」が困難になってしまいました。
PyStan
ブラックボックスモデルでの反省から、説明可能性を上げるために統計モデリングを使用することにしました。
データによる示唆とプロダクトのドメイン知識の両面から特徴量の選定と重み付けを行ったため、モデルの結果に対する説明可能性が上がり、
結果的に「顧客価値向上のためのPDCAサイクルを回すこと」ができるようになりました。
人間が前提知識によって変数の決定や重みづけをすることができるため、
サービスの変化や外部環境の変化に遅れることなく対応することができるようになりました。
現在の解約予測モデル
現在は、NumPyroというPythonパッケージを使って解約予測モデルを作っています。
なぜNumPyro?
まず、簡単にNumPyroの紹介をします。
NumPyro は、JAX と呼ばれる高速なバックエンドを持っていることが特徴の確率プログラミングのパッケージであり、モデルのパラメータ推定などを高速に行えるのが、大きな特徴のひとつになっています。
また、NumPyro は Python のパッケージであることから、Python の経験者にとっては、比較的少ない学習コストで統計モデリングや確率プログラミングという新しい世界を覗いてみることができることも大きなメリットのひとつとなっています。
(引用元:NumPyro で学ぶ ベイズ統計モデリング 【基礎編】)
背景となっているJAXとは、機械学習に主に使われる計算ライブラリで、NumPyのような感覚で書くことができます。
JAXには、強力な自動微分システムが含まれており、GPUやTPUなどのハードウェアアクセラレーションを使用することもできます。
そのため、NumPyroを用いることで従来使用していたPystanよりも高速に推論を行うことができるようになりました。
また、Stan特有の言語を覚えなくてもよく、Numpyに似たコードの書き方ができるため、Pythonを触ったことがある人にとってはとっつきやすい点も有用でした。
実装例
実際に使っている細かい設定等は共有できませんが、例としてNumPyroの使い方を共有できたらと思います。
まず、必要なパッケージをインストールします。
import numpyro
from numpyro import distributions as dist
import numpy as np
import jax
次に、NumPyroではGPUやTPUを使っても速くならないケースも多々あるそうなのでcpuを設定し、
並列数は4に設定します。
numpyro.set_platform('cpu')
numpyro.set_host_device_count(4)
変数xに対する結果y(0 or 1)がある2次元のデータを想定します。
モデル定義は以下のようにできます。(xは正規分布を仮定)
def model_sample(x, y):
a = numpyro.sample('a', dist.Normal(0, 10))
b = numpyro.sample('b', dist.Normal(0, 10))
mu = a * x + b
theta = jax.nn.sigmoid(mu)
prob = numpyro.deterministic("prob", theta)
numpyro.sample('obs', dist.Bernoulli(logits=mu), obs=y)
サンプリングは以下のように行います。
1,2行目はサンプリングの設定を行なっており、3,4行目でMCMCによるサンプリングを行なっています。
nuts = numpyro.infer.NUTS(model_sample)
mcmc = numpyro.infer.MCMC(nuts, num_warmup=500, num_samples=3000, num_chains=4)
mcmc.run(jax.random.PRNGKey(0), x=x, y=y)
mcmc_samples = mcmc.get_samples()
また、事後サンプリングも以下のようにして、簡単に行うことができます。
predictive = numpyro.infer.Predictive(model_sample, mcmc_samples)
ppc_samples = predictive(jax.random.PRNGKey(1), x=x, y=y)
まとめ
私たちのチームでは、統計モデリングによって、ヘルススコアを算出しています。
NumPyroの導入は今年からでしたが、初学者の私でも少し扱えるようになったので、
これから統計モデリングをされる方は、ぜひNumPyroを挑戦してみてください。
NumPyroは、まだまだ歴史が浅いため日本語の情報や本が少ないです。
入口として、前述のNumPyro で学ぶ ベイズ統計モデリング 【基礎編】はおすすめです。
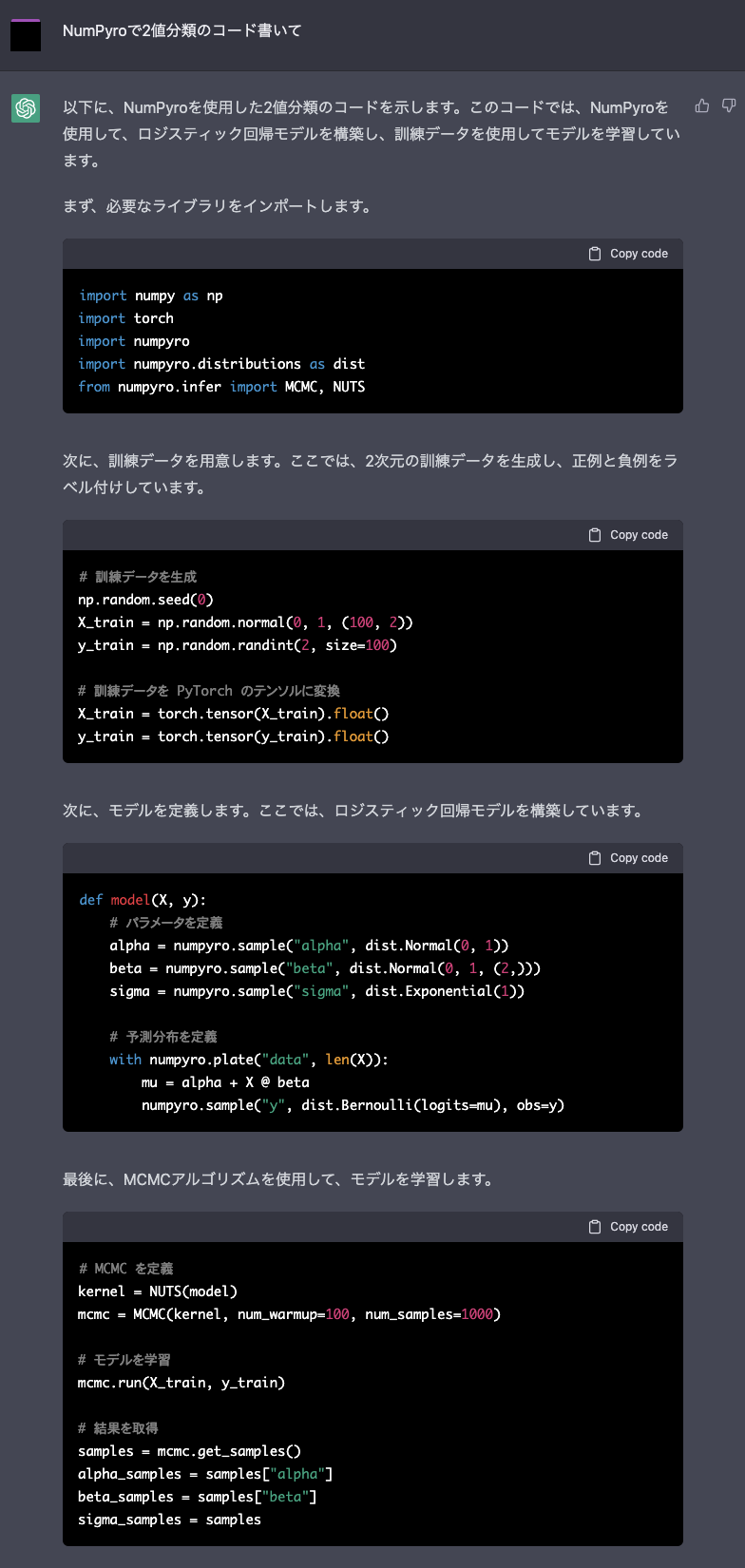
もっとお手軽な方法としては、ChatGPTに「NumPyroで2値分類のコード書いて」などと投げてみると、
一旦それっぽい骨組みを作ってくれるので、そこから始めてみてもいいかもしれません。