はじめに
初めまして、ashと申します。
普段は社内の業務改善等々にに携わっており、プログラミング使わないと効率化できなくなってきたので勉強し始めました。
まだ初心者なので、生ぬるい目で見てもらえたら嬉しいです。
作ったもの
社内で新人さんが入ってきた時に部品の種類が多すぎて、下記の問題が起きてた
- 覚えられない
- 一覧表が作れない
- 毎回聞きづらい
なので、図面を入れたら部品種別を教えてくれるアプリがあったら色々解決しそうと思ったので作ってみました。
内容
- 画像処理
- ぼかし
- 左右反転
- 白黒反転
- 180度回転
- 学習モデル
- 実装結果
- まとめ
- おまけ renderデプロイでハマったこと
実行環境
- Visual Studio Code
- Python 3.11.2
アプリ
1.画像処理
図面は社内にあるので、収集は省きます。
問題はその種類毎の図面枚数にバラつきがあって、多いものは100枚超準備できるが、少ないものは20枚程度でした。
機械学習には最低でも50枚は必要と聞いたので、図面を選別&水増ししました。
選別
手書きが入っている図面は除外して、不鮮明な場合でも手書きが無ければ、okとしました。
水増し
下記の画像処理を使用して水増ししていきました。
使用ライブラリ
import os
import cv2
ぼかし加工
#保存フォルダパス
folder_path = r"C:\Users\ash\Desktop\フォルダ"
#フォルダ内画像を処理
for filename in os.listdir(folder_path):
img_path = os.path.join(folder_path, filename)
img = cv2.imread(img_path)
# ぼかし処理
blurred_img = cv2.GaussianBlur(img, (51,51), 0)
# 保存
save_path = os.path.join(folder_path, f"blurred_{filename}")
cv2.imwrite(save_path, blurred_img)
#保存する時に同じ名前だと上書きになるので注意
左右反転
#保存フォルダパス
folder_path = r"C:\Users\ash\Desktop\フォルダ"
#フォルダ内画像を処理
for filename in os.listdir(folder_path):
img_path = os.path.join(folder_path, filename)
img = cv2.imread(img_path)
# 左右反転処理
flip_img = cv2.flip(img, 1)
# 保存
save_path = os.path.join(folder_path, f"flip_{filename}")
cv2.imwrite(save_path, flip_img)
白黒反転
#保存フォルダパス
folder_path = r"C:\Users\ash\Desktop\フォルダ"
#フォルダ内画像を処理
for filename in os.listdir(folder_path):
img_path = os.path.join(folder_path, filename)
img = cv2.imread(img_path)
# 画像を白黒反転
img_inverted = cv2.bitwise_not(img)
# 保存
save_path = os.path.join(folder_path, f"inverted_{filename}")
cv2.imwrite(save_path, img_inverted)
180度回転
#保存フォルダパス
folder_path = r"C:\Users\ash\Desktop\フォルダ"
#フォルダ内画像を処理
for filename in os.listdir(folder_path):
img_path = os.path.join(folder_path, filename)
img = cv2.imread(img_path)
# 180度回転処理
rotated_img = cv2.rotate(img, cv2.ROTATE_180)
# 保存
save_path = os.path.join(folder_path, f"rotated_{filename}")
cv2.imwrite(save_path, rotated_img)
2.学習モデル
コード全体
import os
import cv2 #画像処理
import matplotlib.pyplot as plt
import numpy as np
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
from keras.models import Sequential
from keras.utils import to_categorical
from keras.layers import Input, Conv2D, MaxPooling2D, Flatten, Dense, Activation
# 画像を読み込むディレクトリのパス
image_dir = r'C:\Users\ash\Desktop\フォルダ'
# データの前処理
resized_images = [] #モノクロ変換&リサイズした画像を格納するリスト
labels = [] #部品のラベル
np.random.seed(3)
#部品のラベル
for label in ["A", "B","C","D"]:
#読みこむファイル指定
image_files = os.listdir(os.path.join(image_dir, label))
#125枚ランダムに選択
image_files = np.random.choice(image_files, size=125, replace=False)
for file in image_files:
# 画像の読み込み
image_path = os.path.join(image_dir, label, file)
image = cv2.imread(image_path, cv2.IMREAD_GRAYSCALE) # モノクロに変換
# 画像のリサイズ
image = cv2.resize(image, (100, 100)) #100×100に変換
# 画像をNumpy配列に格納する
resized_images.append(image)
labels.append(label)
# ラベルをOne-Hotエンコード 分類を数値化
le = LabelEncoder()
le.fit(labels)
labels_encoded = le.transform(labels)
labels_onehot = to_categorical(labels_encoded)
# トレーニングデータとテストデータを7:3で分割する ランダムシード値は42固定
X_train, X_test, y_train, y_test = train_test_split(np.array(resized_images), labels_onehot, test_size=0.3, random_state=42)
#分割したトレーニングデータをスケーリング処理
#画素値の範囲を0から1に変換しモデルの学習をより安定させる
X_train = X_train / 255.0
X_test = X_test / 255.0
#モデルの定義__活性化関数シグモイド
model = Sequential()
model.add(Conv2D(input_shape=(100, 100, 1), filters=32, kernel_size=(3, 3), strides=(1, 1), padding="same"))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(filters=32, kernel_size=(3, 3), strides=(1, 1), padding="same"))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(filters=64, kernel_size=(3, 3), strides=(1, 1), padding="same"))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(filters=64, kernel_size=(3, 3), strides=(1, 1), padding="same"))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten())
model.add(Dense(256))#活性化関数
model.add(Activation('relu'))
model.add(Dense(128))
model.add(Activation('relu'))
model.add(Dense(64))
model.add(Activation('relu'))
model.add(Dense(32))
model.add(Activation('relu'))
model.add(Dense(4))
model.add(Activation('softmax'))
#学習過程の設定 ・最適化 ・損失関数 ・評価指数
model.compile(optimizer='sgd', loss='categorical_crossentropy',
metrics=['accuracy'])
#訓練 バッチサイズ,エポック数,ログ表示,データセット
history = model.fit(X_train, y_train, batch_size=16, epochs=75, verbose=1, validation_data=(X_test, y_test))
#評価
score = model.evaluate(X_test, y_test, batch_size=16, verbose=0)
print('validation loss:{0[0]}\nvalidation accuracy:{0[1]}'.format(score))
#acc, val_accのプロット
#トレーニングデータに対しての正解率を表示
plt.plot(history.history["accuracy"], label="accuracy", ls="-", marker="o")
#テストデータに対しての正解率
plt.plot(history.history["val_accuracy"], label="val_accuracy", ls="-", marker="x")
plt.ylabel("accuracy")
plt.xlabel("epoch")
plt.legend(loc="best")
plt.show()
#モデルを保存
model.save("my_model.h5")
4.実装結果
まだ一部の部品だけだが、各部品で識別できていた。
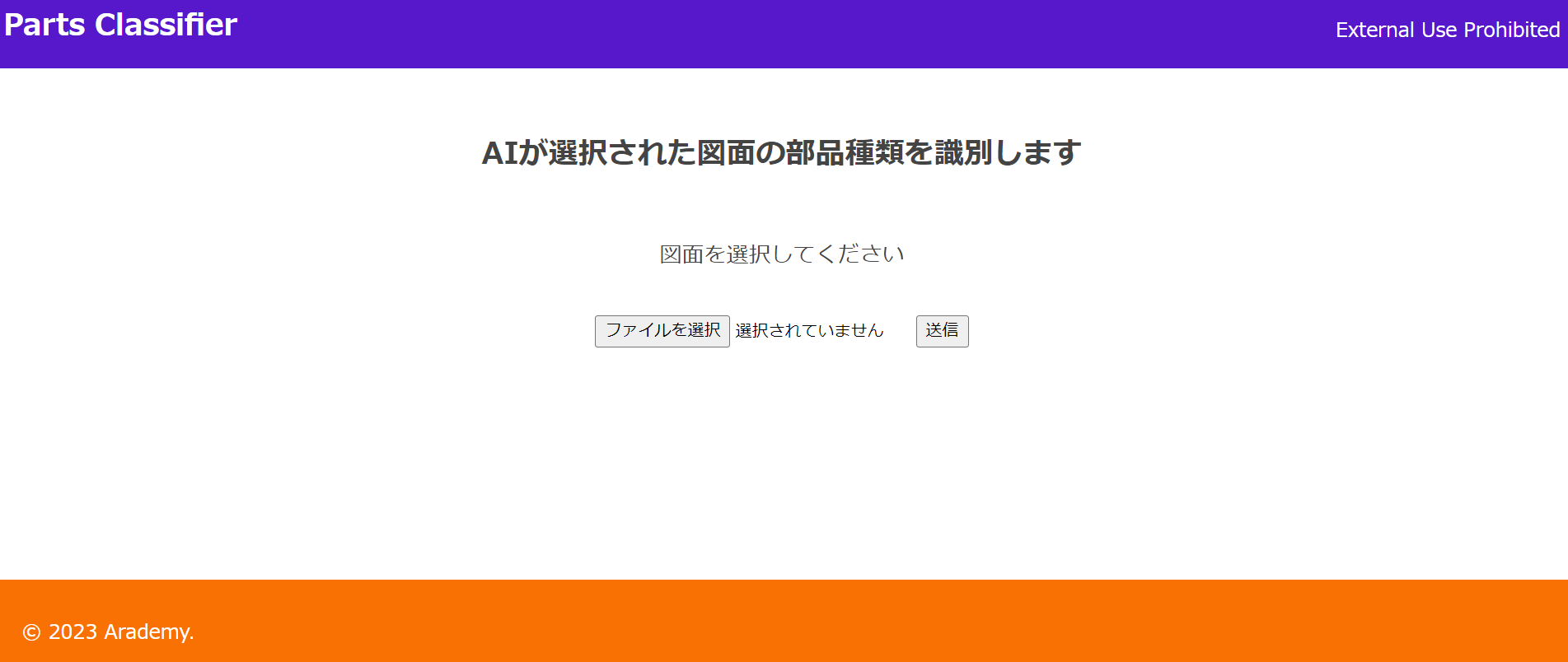
webアプリ実装画面
- ファイルを選択を押して
- 送信を押すと識別結果が出る
エポック数の違いによる学習結果
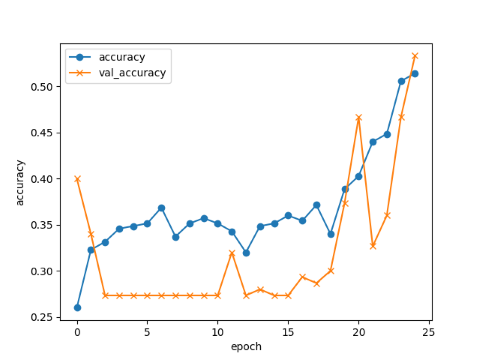
エポック数25
acc, val_acc共に0.55近辺で終了
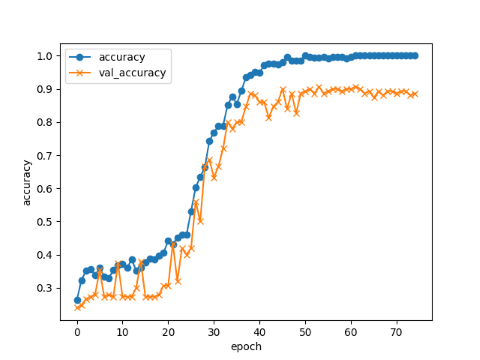
エポック数75
acc, val_acc共に50回辺りから0.9以上
5.まとめ
このままでは部品数が少なく使用できるレベルではないですが、部品を追加していけば実用レベルにいける可能性は見えました。
ですが、軽微な違いが多い図面を識別することが難しいこともわかりました。
図面の識別の全てを任せられませんが、大分類を見分けてもらえるサポート的な役割で使用できないか検討していこうと思います。
6.おまけ renderのデプロイでハマったこと
初めてrenderにデプロイしましたが、かなりハマりました。
原因としてデプロイする際にPythonのverが合わないことによる、ライブラリのインストールエラーが発生していました。
はる@フルスタックチャンネル様の情報を参考に下記のように設定をして、解決できました。
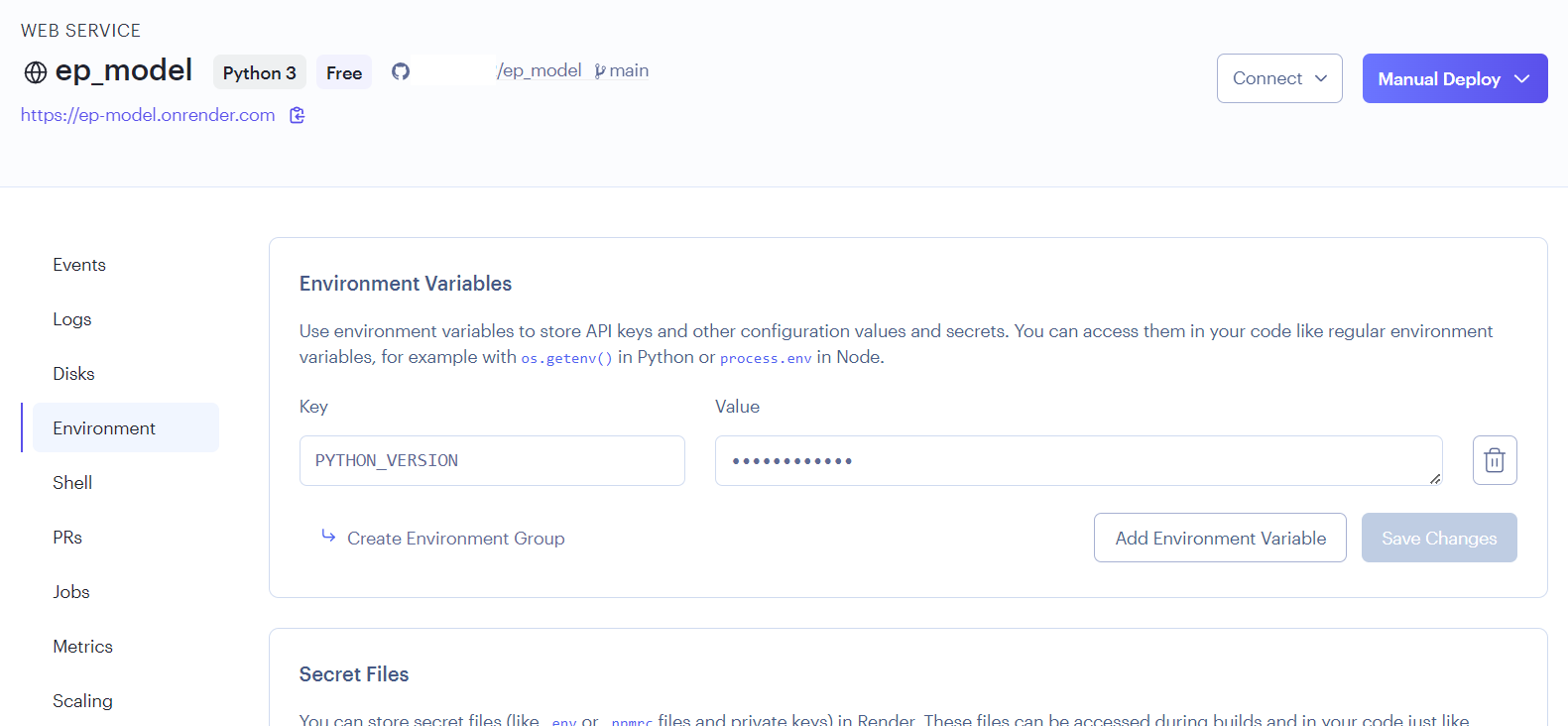
ダッシュボードからデプロイに失敗したサービスを選択
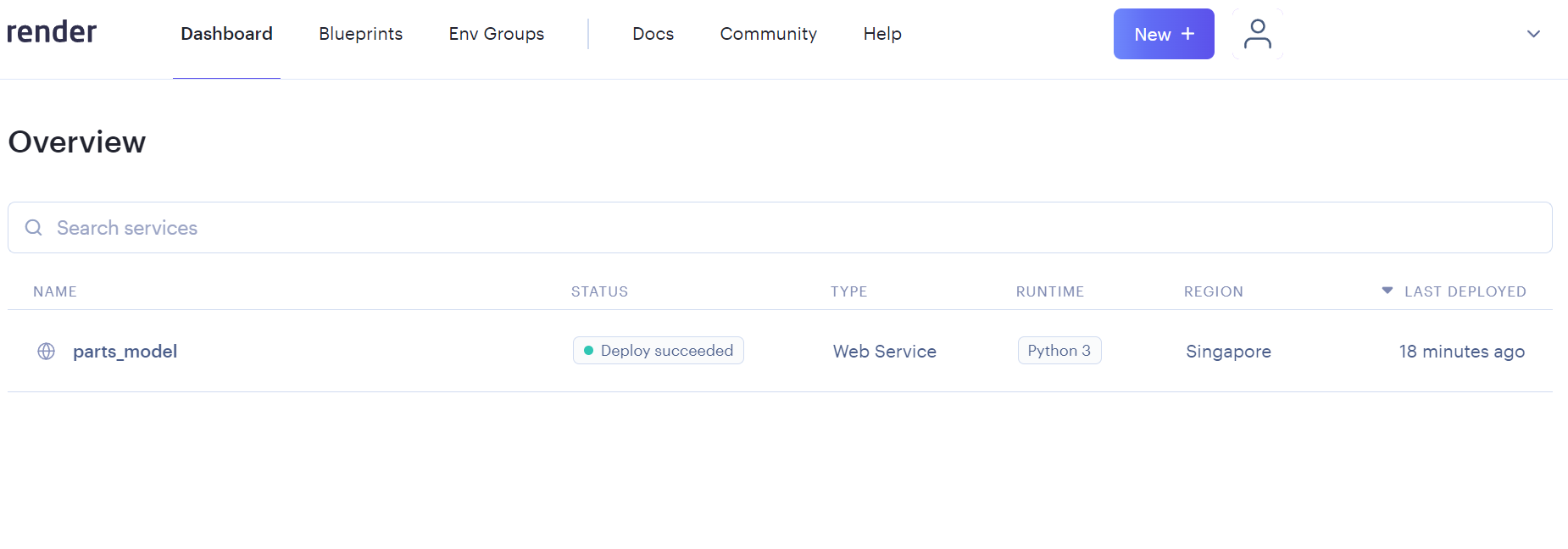
Environmentを選択してEnvironment Variablesの追加で下記を追加
key : PYTHON_VERSION
Value : 3.11.2
Save Changes で保存
再デプロイ
SettingsのAuto-Deployがyesになっていれば、勝手にデプロイが再開されると思います。