追記(2025/4/19)
生成AI初心者向けにApple Silicon MacでGUIのみで生成できるツールとその解説を作成ので、こちらも参照してください。
M4 Mac mini
M4チップ搭載の Mac miniは、最小スペックメモリ16GBSSD256GBであれば2024年12月26日時点で税込94800円、学生や教職員なら割引を利用すれば税込79800円と安価に購入できます。
Apple SiliconのMacはCPUとGPUでメモリを共有するユニファイドメモリなので、吊るしのM4 Mac miniでもGPUは最大16GBまでメモリを扱えます(OSやアプリ等がCPU向けに少なくとも2GBは消費するので、実際は16GB-2GB=14GBぐらいまででしょうけど)。さらに、M4 Mac miniはAI用のNeural Engineも搭載しているので、より有用性が高いかもしれません。
この記事では、画像生成AIツールの定番であるStable Diffusion WebUIとComfyUI、特定の画風やキャラクタを再現できるようモデルを修正できるLoraを作成用の定番ツールsd-scripts、Neural Engineを活用して画像生成するAppleのフレームワークCore MLを利用したApple製の画像生成ツールcoremltoolsなどをコマンドラインでインストールして動作させる方法を解説し、どの程度動作するか検証していきます。
なお、画像生成はStable MatrixのようなGUIでもある程度実現可能ですが、不都合が生じる場合もあったので、この記事ではコマンドラインでのインストールや実行等を中心に説明していきます。
macOSでのコマンドライン操作に慣れていない方はあらかじめこちらなどを参考にしてコマンドラインの操作に慣れておいてください。なお、この記事で入力説明のコマンドの最初についている『% 』はプロンプトなので、入力する際には『% 』は取ってください。
さらに動画生成AIHunyuanVideoを動かすことができたので、こちらも説明します(2025/1/5追加)。
動作確認した機器構成
M4 Mac mini(最小スペック構成)
| 種類 | 内容 |
|---|---|
| CPU | 10コア(高性能4コア+ 高効率6コア) |
| GPU | 10コア |
| NE | 内蔵Apple Neural Engine |
| メモリ | 16GB |
| OS | macOS sequoia(15.2) |
Windowsマシン(比較対象)
| 種類 | 内容 |
|---|---|
| CPU | Ryzen 5600 |
| GPU | Geforce 3060 (VRAM 12GB) |
| メモリ | 32GB (16GB×2) |
| OS | Windows 11(23H2) |
事前準備
インストール用フォルダの準備
この解説では基本的に~/sd以下にインストールしていきます。どの場所でも問題ないの変更する場合は適宜フォルダを読み替えてください。次のコマンドでsdフォルダを作成して移動してします。
% mkdir sd
% cd sd
xcodeのインストール
画面下のDockのLaunchpadのその他からターミナルを起動してください。
最初に開発ツールのコマンドライン版のxcodeをインストールします。
% xcode-select --install
実行するとコマンドライン版のxcodeがインストールされていない場合、

というダイアログが出るので、インストールを押して、契約に同意してインストールしてください。インストールに結構な時間がかかります。
brewのインストール
次にmacOS用のさまざまなツールをインストールできるbrewをインストールします。
% /bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"
==> Checking for `sudo` access (which may request your password)...
Password:
...
Press RETURN/ENTER to continue or any other key to abort:
パスワードを聞かれるので入力し、さらに続けるか聞かれるので、Enterキーを押してインストールします。
...
==> Next steps:
- Run these commands in your terminal to add Homebrew to your PATH:
echo >> /Users/asfdrwe/.zprofile
echo 'eval "$(/opt/homebrew/bin/brew shellenv)"' >> /Users/asfdrwe/.zprofile
eval "$(/opt/homebrew/bin/brew shellenv)"
- Run brew help to get started
- Further documentation:
https://docs.brew.sh
最後に環境変数の設定をするように指示があるので、設定してください(HOME環境変数を利用してユーザ名に関わらず実行できるよう変更しています)。
% echo >> $HOME/.zprofile
% echo 'eval "$(/opt/homebrew/bin/brew shellenv)"' >> $HOME/.zprofile
% eval "$(/opt/homebrew/bin/brew shellenv)"
brewコマンドが正常に動作するか確認してください。
% brew
Example usage:
brew search TEXT|/REGEX/
brew info [FORMULA|CASK...]
brew install FORMULA|CASK...
...
必要なツールのインストール
brewを使って、cmake,protobuf, rust, python@3.10, git, wgetを必要なツールをインストールします(後述の Stable Diffusion WebUI のガイドに合わせているので不要なものも入っているかも)。
% brew install cmake protobuf rust python@3.10 git wget
Metal Performance Shader対応Pytorchの動作確認
ディープラーニングを利用するAIツールの多くはPytorchを利用して動作します。Apple SiliconのCPUとGPUを活用するには、PyTorchがMetal Performance Shader(mps)で動作するか確認する必要があります。
Apple公式のPytorchの解説 の説明を参考に動作確認します。
まず、mpsに動作確認用環境を作り、mpsフォルダに移動して仮想環境を有効にします。
プロンプトの最初に(mps)が付くようになります。
% python3.10 -m venv mps
% cd mps
% . bin/activate
(mps) ...
PyTorchをインストールします。
% pip install --pre torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/nightly/cpu
動作確認用Pythonプログラムを動かします。次の内容のtest.pyをテキストエディット等で作成してください。
import torch
if torch.backends.mps.is_available():
mps_device = torch.device("mps")
x = torch.ones(1, device=mps_device)
print (x)
else:
print ("MPS device not found.")
コマンドラインで作るなら次のように入力してください。
% cat << EOF > test.py
import torch
if torch.backends.mps.is_available():
mps_device = torch.device("mps")
x = torch.ones(1, device=mps_device)
print (x)
else:
print ("MPS device not found.")
EOF
test.pyを実行して動作確認します。正常ならtensor([1.], device='mps:0')が表示されます。
% python3 test.py
tensor([1.], device='mps:0')
元のフォルダに戻ってください。
% cd ..
Hugging Faceへのアクセス設定
Hugging Faceとcivitaiは生成AIモデルの定番サイトです。アカウントを作成してログインしてないとダウンロードできない場合があるので、まず、アカウントを作成して、コマンドからHugging Faceにアクセスできるようにしてください。
Hugging Face にログインしたら、右上のアイコンから AccessTokens を選び、Create New Token で Token type: Read、Token name は test としてアクセストークンを作成してください。

このアクセストークンを利用してコマンド経由でHugging Faceできるように設定します。
hugginface-cliをpipでインストールします。
% pip install huggingface-hub
hugginface-cliでアクセストークンによるログインを行います。
% huggingface-cli login
アクセストークンを手で入力するかペーストしてEnterキーを押し
To log in, `huggingface_hub` requires a token generated from https://huggingface.co/settings/tokens .
Enter your token (input will not be visible):
yとEnterキーを押して信用できる状態にします。
Add token as git credential? (Y/n)
...
Login successful.
...
と表示されていればOKです。
mps テスト用仮想環境から出ます。
% deactivate
Stable Diffusion WebUIによる画像生成
インストール
基本的には公式サイトのApple Silicon用説明に従ってインストールします。事前準備ですでに行なっている部分があるのでそこは飛ばします。
Stable Diffusion WebUI をインストール
gitを利用して Stable Diffusion WebUI をインストールします。
% git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui
stable-diffusion-webuiフォルダに移動します。
% cd stable-diffusion-webui
画像生成AI用モデルはなんでもいいのですが、とりあえず、animazine-xl-3.1をダウンロードして使います。アニメ調の画像に強い SDXL版モデルです。Files and versions にある animagine-xl-3.1.safetensors の↓を押してダウンロードし、models/Stable-diffusionフォルダに移動させてください。
もしくはコマンドでmodels/Stable-diffusionフォルダにwgetコマンドでダウンロードするならば、次のようにします。
% wget -O models/Stable-diffusion/animagine-xl-3.1.safetensors 'https://huggingface.co/cagliostrolab/animagine-xl-3.1/resolve/main/animagine-xl-3.1.safetensors?download=true'
起動
./webui.shで実行します。初回はさまざまなものをダウンロードしたりインストールしたりするので時間がかかります。
% ./webui.sh
自動的に Safari が立ち上がって、http://127.0.0.1:7860に接続するはずです。

なお、標準ではwebui-macos-env.shが読み込まれます。中身を開いて確認すると、--skip-torch-cuda-test --upcast-sampling --no-half-vae --use-cpu interrogateオプションを付けて実行され、GPUが使えない場合はCPUで動かすようexport PYTORCH_ENABLE_MPS_FALLBACK=1を付けて実行されるよう設定されています。
Stable Matrix を利用する場合
Stable Matrixの使い方はこの辺を参照してください。ただし、Stable Matrix での Stable Diffusion WebUI のデフォルトの実行オプションが macOS に対しては不適切になっていて動作が遅いので、パッケージのギア印から起動オプションの設定で、--no-halfを外し、Extra Launch Argumentsに--skip-torch-cuda-test --upcast-sampling --no-half-vae --use-cpu interrogateを指定して、webui-macos-env.shと同様の起動オプション設定にしてください。設定を変更しないと画像生成に10分以上かかるはずです。
画像生成
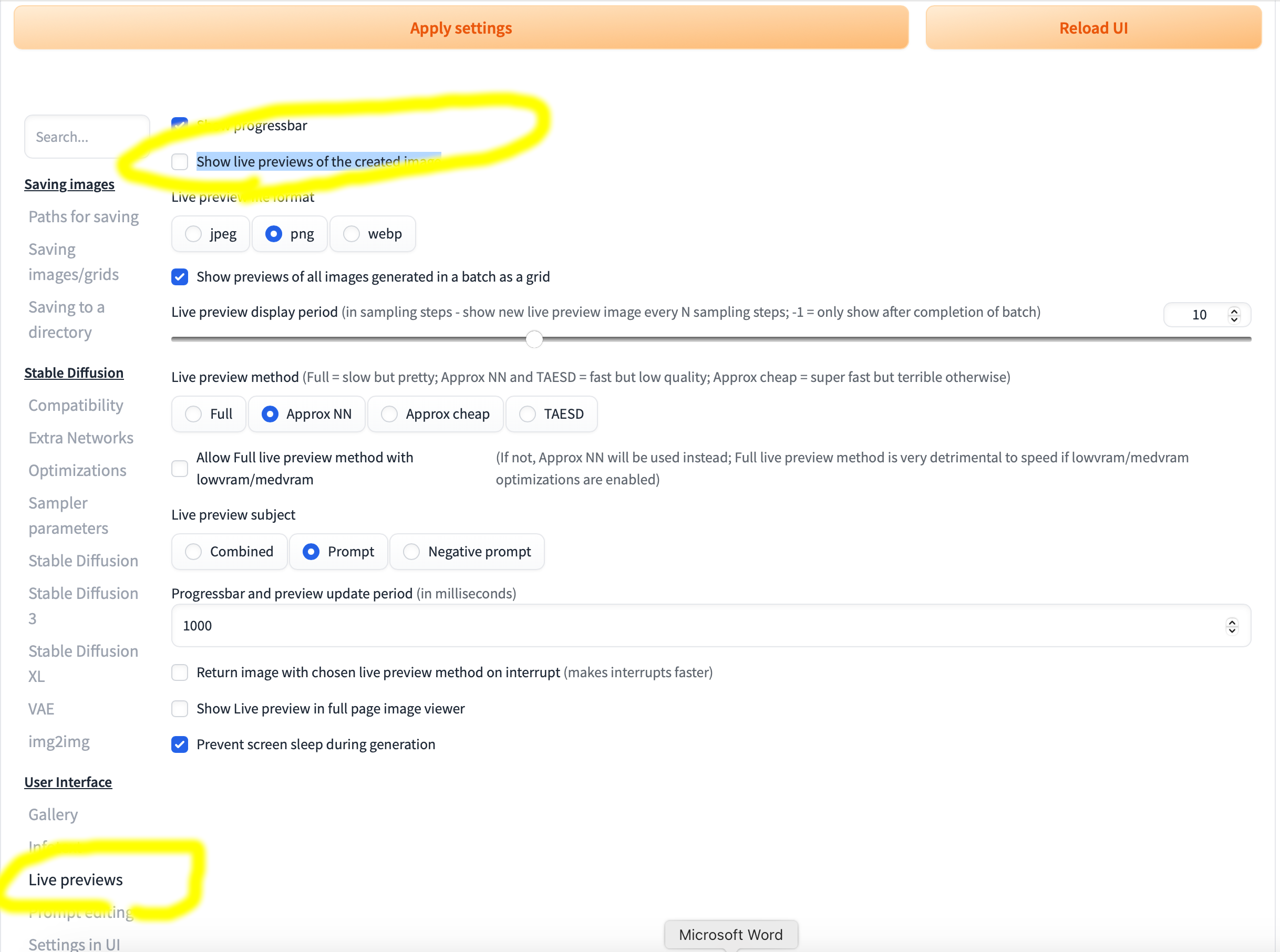
最初に、Settings タブの User Interface の Live previews の『Show live previews of the created image』のチェックを外し、上の『Apply settings』を押してください。付けているとプレビュー画像を生成するため動作が遅くなります。設定の反映に少々時間がかかる場合があるので、10分経っても反映されないなら、ターミナルでCtrl+Cを押して WebUI を止めて、もう一度./webui.shで起動しなおしてください。
txt2img タブに戻って一番上の Stable Diffusion checkpoint にダウンロードしたanimagine-xl-3.1.safetensorsを選んでモデルを読み込ませます。モデルのロードに少々時間がかかります。
プロンプトに生成したい画像に関する文章を入力してください。試しに、教室で微笑んでいる女の子の768x768サイズの画像を生成します。次の設定を行い、Generateを押して生成します。
| 設定項目 | 設定内容 |
|---|---|
| Sampling method | Euler a |
| Sampling steps | 20 |
| Width | 768 |
| Height | 768 |
| CFG Scale | 7 |
| Prompt | masterpiece, anime coloring, 1girl, classroom, smile, standing, school uniform |
| Negative Prompt | bad quality, worst quality |

生成された画像はoutputsフォルダのtxt2imgs-imagesの日付のフォルダに保存されます。
生成の高速化
上の768x768サイズの画像は53.8秒で生成できていますが、Geforce 3060だと同じ設定で9.6秒です。512x512の画像では23.2秒、1024x1024の画像では99.97秒に対して、Geforce 3060では512x512の画像が4.9秒、1024x1024の画像が15.7秒です。
この速度でも使えなくはないですが、Stable Diffusion WebUIでも可能な高速に生成できる手法があります。こちらを参考に、Loraを活用したSDXL-Lightningを利用してみます。Lora はモデルを修正することで、高速化を行ったり、そのモデルで再現できない画風やキャラクタなどを再現できるようにする追加学習モデルです。
Filesからsdxl_lightning_2step_lora.safetensorsをダウンロードして、Stable Diffusion WebUI のmodelsフォルダ内のLoraフォルダに移動させてください。
コマンドでmodels/Loraフォルダにダウンロードする場合、ターミナルのメニューのシェルの新規ウィンドウで新しいターミナルを起動させて、そちらで次のコマンドを入力してください。
% wget -O ~/sd/stable-diffusion-webui/models/Lora/sdxl_lightning_2step_lora.safetensors 'https://huggingface.co/ByteDance/SDXL-Lightning/resolve/main/sdxl_lightning_2step_lora.safetensors?download=true'
Lora タブの右端の再読み込みを押して Lora ファイルの更新を行い、出てきたsdxl_lightning_2step_lora をクリックして、プロンプトに追加させます。 『Sampleing steps』を6、『CFG Scale』を2にしてGenerateを押して生成してください。Lora 設定初回時は Lora の読み込みがあるので多少時間がかかりますが、2回目以降は6ステップなので高速に画像生成されます。2回目以降の生成では17.6秒で生成されました。ただ生成画像の品質は少し劣るようで、この速度なら使えなくはないですが品質が微妙です。なお、Geforce 3060では同設定で4.5秒です。

こちらで紹介されているDMD2も使ってみます。<lora:sdxl_lightning_2step_lora:1>をプロンプトから削除して、dmd2_sdxl_4step_loraを使って同様の設定の場合で2回目以降の場合は18秒で生成されます。生成画像の品質はこちらも微妙です。なお、Geforce 3060では4.5秒です。
このほか、Stable Diffusion WebUIの細かい使い方は、『stable diffusion webui 使い方』等で検索して調べてください。
Safari を閉じて、ターミナルで Ctrl+Cを 押して Stable Diffusion WebUI を終了させてください。
sdフォルダに戻ます。
% cd ..
reforgeについて
Stable Diffusion WebUIの派生版にreforgeがあります。
Geforce で動かす場合 reforge の方が高速の場合が多いのですが、M4 Mac mini で試したところ、画像生成のたびに UNet モデルのロード→アンロード→VAE モデルのロード→アンロードを繰り返す上に、生成も遅いです(何も設定しない場合15分50秒かかりました)。起動オプションを色々試してみたのですがうまくいきませんでした。適切な設定をすれば reforge のほうが良い可能性がありますが、現状うまく動いていないので、インストールと実行の仕方だけ書いておきます。
インストール
% git clone https://github.com/Panchovix/stable-diffusion-webui-reForge
% cd stable-diffusion-webui-reForge
% python3.10 -m venv venv
% . venv/bin/activate
% pip install -r requirements.txt
% pip install --pre torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/nightly/cpu
起動
% ./webui.sh
(reforge はターミナルでCtrl+Cを押せば終了します。reforge 使用後に引き続き次の ComfyUI の画像生成を行う場合は
% deactivate
% cd ..
で仮想環境から出て、元のフォルダに戻ってください)
ComfyUIによる画像生成
次にComfyUIを使っていきます。
Stable Diffusion WebUI と違って使い方は直感的ではありませんが、潜在拡散モデル(Latent Diffusion Models)の仕組みをそのままワークフローとして表現することで画像を生成できます。潜在拡散モデルの仕組みについてはこちらの解説スライドなどを参考にしてください。
インストール
公式サイトの説明に従ってインストールします。
git経由でファイルをインストールし、
% git clone https://github.com/comfyanonymous/ComfyUI.git
ComfyUIフォルダに移動し、
% cd ComfyUI
venvによる仮想環境を構築して有効にします(プロンプトに(ComfyUI)が付きます)。
% python3.10 -m venv ComfyUI
% . ComfyUI/bin/activate
pipで必要なファイルをインストールします。
% pip install -r requirements.txt
% pip install --pre torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/nightly/cpu
Stable Diffusion WebUI に入っているモデルを ComfyUI でも使えるようにシンボリックリンクを張ります。
% cd models/checkpoints
% ln -s ../../../stable-diffusion-webui/models/Stable-diffusion
% cd ../loras
% ln -s ../../../stable-diffusion-webui/models/Lora
% cd ../..
起動
次のコマンドで起動します。
% python3 main.py
Stable Diffusion WebUI と違ってブラウザが自動起動しないので、
To see the GUI go to: http://127.0.0.1:8188
と表示されたら、手動で Safari を起動し、http://127.0.0.1:8188を開いてください。

2024年12月28日の時点で ComfyUI は新しい操作画面と日本語メニューが表示になっています。この記事では変更せず進めますが、現時点の ComfyUI のネットの解説記事は古い操作画面と英語メニューのものが多いので、変更したい場合は、右下のギアマークから設定のロケールを English にして、Menu を Disable にしてください。
Stable Matrixを利用する場合
ComfyUI は Stable Matrix でも問題なく動きます。ASCIIに解説記事があります。
画像生成
メニューのワークフローから『テンプレートを参照』を選び、画像生成を選んでください。標準の画像生成用ワークフローが読み込まれます。

次のように設定してください。
| ノード名 | 設定項目 | 設定内容 |
|---|---|---|
| チェックポイントを読み込む | ckpt名 | Stable-Diffusion/animagine-xl-3.1.safetensors |
| 上のCLIPテキストエンコード(プロンプト) | テキスト欄 | masterpiece, anime coloring, 1girl, classroom, smile, standing, school uniform |
| 下のCLIPテキストエンコード(プロンプト) | テキスト欄 | bad quality, worst quality |
| Kサンプラー | cfg | 7 |
| Kサンプラー | サンプラー名 | euler_ancestral |
| 空の潜在画像 | 幅 | 768 |
| 空の潜在画像 | 高さ | 768 |
設定できたら、一番下の実行を押してください。
初回はモデルの読み込みと CLIP での処理の時間がかかります。2回目以降はモデルの読み込みが不要になり、プロンプトを変えない場合 CLIP の処理もなくなり、Kサンプラーでの潜在画像生成とVAEの潜在画像のデコードのみになるので、より高速に生成されます(2回目で58.77秒、Geforce 3060では8.32秒)。生成された画像はoutputフォルダに保存されます。
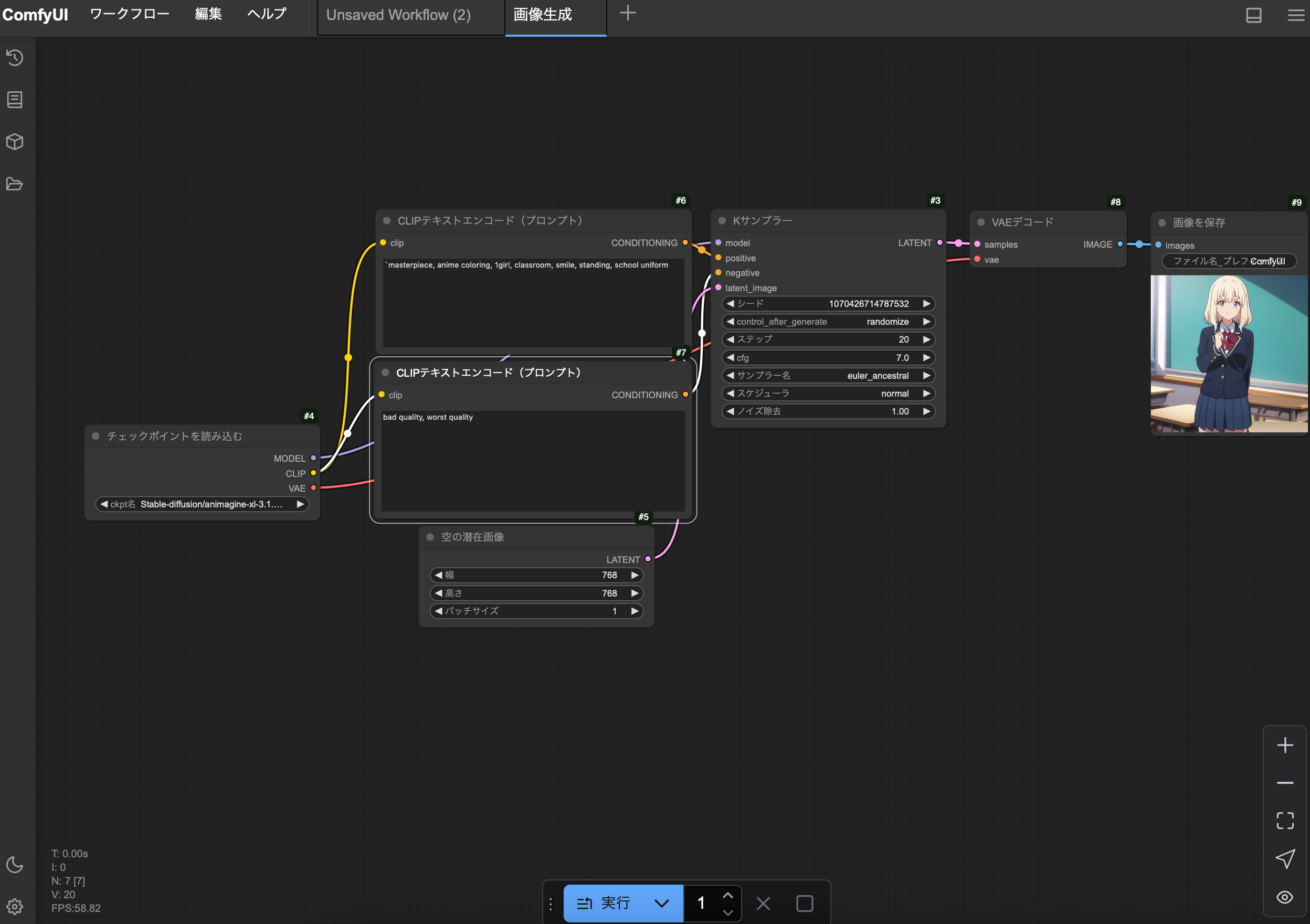
なお、512x512の画像は23.23秒、1024x1024は118.06秒でした。Geforce 3060では512x512が4.30秒、1024x1024が14.36秒です。
Loraの使用
Stable Diffusion WebUI と同様に高速化 Lora を使ってみます。右クリックして『Add Node』の『ローダー』の『Loraを読み込む』を選びます。Lora/dmd2_sdxl_4step_lora.safetensorsを選びます。
次に『チェックポイントから読み込む』の『右のMODEL』を『Loraを読み込む』の『左のモデル』につなぎ、『Loraを読み込む』の『右のモデル』を『Kサンプラー』の『左のmodel』につなぎます。『チェックポイントから読み込む』の『右のCLIP』を『Loraを読み込む』の『左のクリップ』につなぎ、『Loraを読み込む』の『右のクリップ』を上の『CLIPテキストエンコード(プロンプト)』と下の『CLIPテキストエンコード(プロンプト)』それぞれの『clip』につなぎます。
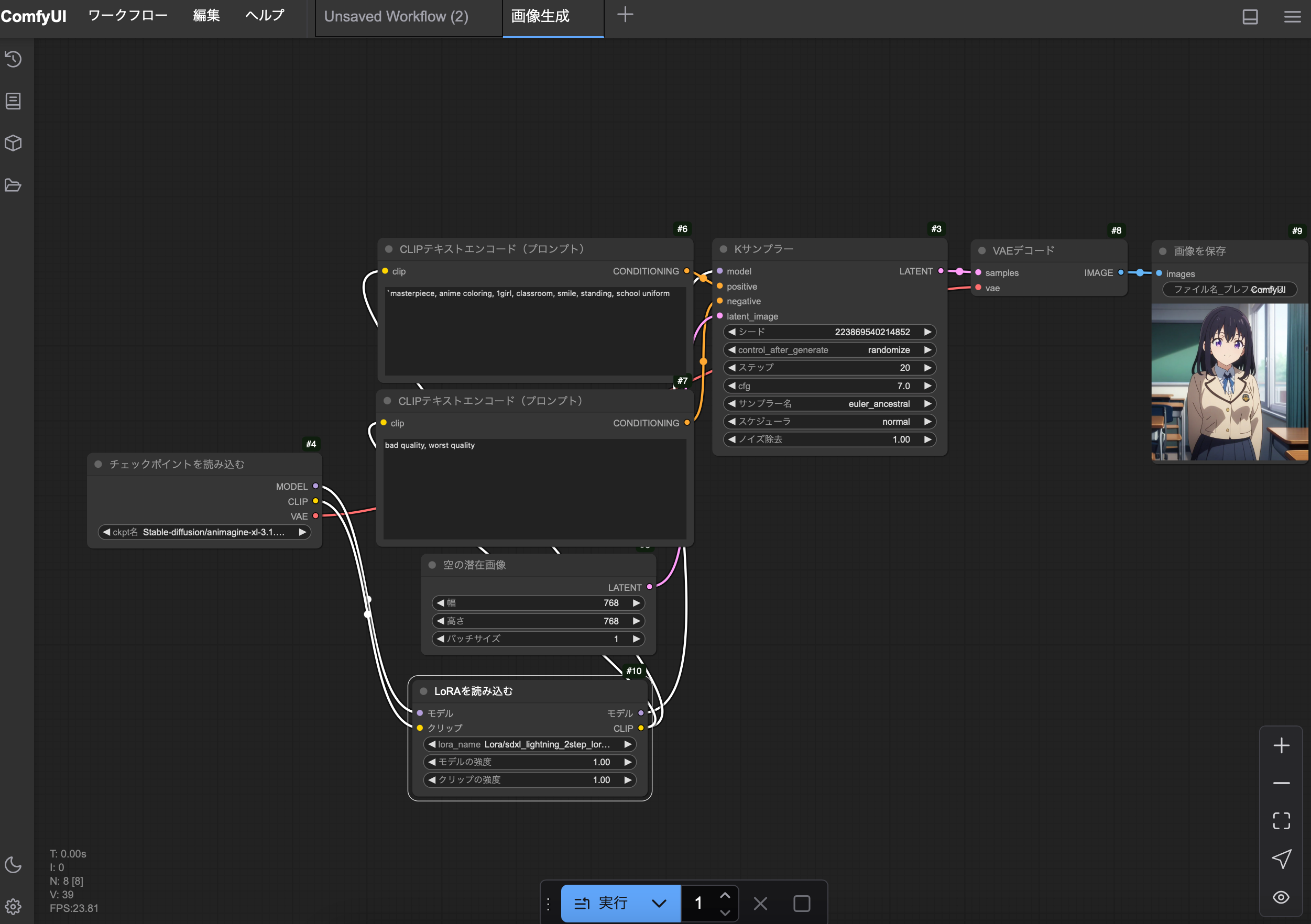
さらに、『Kサンプラー』の『ステップ』を6、『cfg』を2にして実行を押してください。画像生成自体は22秒等で終わるのですが、勝手に Lora のアンロードを行なっているようで、全体としては50秒ぐらいかかります。Geforce 3060では3.16秒で生成されます。勝手にアンロードするのを防ぐ方法はいまのところわかりません。
Loraのマージ
モデルに Lora をマージすれば、別途 Lora をロードする必要がなくなるので、Lora をマージしたモデルを作成してみましょう。メニューの右の+を押して新しいワークフローを開き、編集からワークフローをクリアを選びワークフローを空にします。
右クリックして『Add Node』から、『ローダー』の『チェックポイントを読み込む』を追加し、『ローダー』の『Loraを読み込む』を追加し、『高度な』の『モデルマージ』の『チェックポイントを保存』を追加します。『チェックポイントを読み込む』では Stable-Diffusion/animagine-xl-3.1.safetensors を選び、『Loraを読み込む』では Lora/dmd2_sdxl_4step_lora.safetensors を選びます。モデルの強度とクリップの強度はそのまま1にします。『チェックポイントを読み込む』の『右のMODEL』を『Loraを読み込む』の『左のモデル』につなぎ、『チェックポイントを読み込む』の『右のCLIP』を『Loraを読み込む』の『左のクリップ』につなぎ、『チェックポイントを読み込む』の『右のVAE』を『チェックポイントを保存』の『左のvae』につなぎ、『Loraを読み込む』の『右のCLIP』を『チェックポイントを保存』の『左のclip』につなぎます。実行を押してマージします。マージには時間がかかります。またストレージをかなり使うので、"No space left on device" という空き容量が足らないエラーが出た場合、空き容量を確保してからもう一度実行してください(実際はメモリ不足でエラーになっている気がするので、不要なものも閉じてからもう一度実行してください)。

マージされたモデルはoutputフォルダのcheckpointsフォルダ内にComfyUI_00001_.safetensorsとして保存されます。models/checkpointsフォルダに移動させてください。
Finderで移動させるか、コマンドで行うならターミナルのメニューのシェルから新規ウィンドウを押して別のウィンドウを作成して次のようにします。
% cd sd/ComfyUI
% mv output/checkpoints/ComfyUI_00001_.safetensors models/checkpoints
ブラウザを再読み込みして、ワークフローのテンプレートを参照から画像生成を選んで、『チェックポイントを読み込む』に ComfyUI_00001_.safetensors を指定し、プロンプト等は先ほどのLoraの使用と同じ設定にして画像生成してください。
2回目以降は余計なモデルのロードがないので、画像生成が23.56秒でできるようになりました。
このほか、ComfyUI の細かい使い方は、『ComfyUI 使い方』等で検索して調べてください。
ターミナルで Ctrl+C を押して ComfyUI を終了させ、仮想環境から出てsdフォルダに戻ります。
% deactivate
% cd ..
sd-scriptsによるLora作成 (2025/3/29修正)
sd-scriptsは Lora 作成用ツールです。必要に応じて特定の画風やキャラクタを Lora として追加学習すれば、それらの再現が可能となります。
なお、この辺から動作が何かおかしくなることがあります。その場合は、Macを再起動して、cdコマンドで適切なフォルダに移動し、仮想環境を有効にしてやりなおしてください。
こちらを参考に実験した結果、正しく学習できると思われる条件を見つけました。
- mixed precisionは無効に
- メモリが足らなくなりやすくなるので、network_dimは16以下に設定
- 省メモリのLionスケジューラを使う
インストール
gitでインストールします。
% git clone https://github.com/kohya-ss/sd-scripts.git
sd-scriptsフォルダに移動します。
% cd sd-scripts
venvで仮想環境を構築し、有効にします(プロンプトに(sdscripts)が付きます)。
% python3.10 -m venv sdscripts
% . sdscripts/bin/activate
次にpipで必要なパッケージをインストールするのですが、
$ pip install -r requirements.txt
bitsandbytesの依存関係でエラーが出ます。
...
ERROR: Could not find a version that satisfies the requirement bitsandbytes==0.43.0 (from versions: 0.31.8, 0.32.0, 0.32.1, 0.32.2, 0.32.3, 0.33.0, 0.33.1, 0.34.0, 0.35.0, 0.35.1, 0.35.2, 0.35.3, 0.35.4, 0.36.0, 0.36.0.post1, 0.36.0.post2, 0.37.0, 0.37.1, 0.37.2, 0.38.0, 0.38.0.post1, 0.38.0.post2, 0.38.1, 0.39.0, 0.39.1, 0.40.0, 0.40.0.post1, 0.40.0.post2, 0.40.0.post3, 0.40.0.post4, 0.40.1, 0.40.1.post1, 0.40.2, 0.41.0, 0.41.1, 0.41.2, 0.41.2.post1, 0.41.2.post2, 0.41.3, 0.41.3.post1, 0.41.3.post2, 0.42.0)
ERROR: No matching distribution found for bitsandbytes==0.44.0
仕方がないので、sedコマンドを利用して、bitsandbytes==0.44.0となっている箇所をbitsandbytesに修正します。
% sed -e 's/bitsandbytes==0.44.0/bitsandbytes/' < requirements.txt > tmp.txt
% mv -f tmp.txt requirements.txt
もう一度pipを実行し、最新版 PyTorch をインストールします。
% pip install -r requirements.txt
% pip install --pre torch torchvision --extra-index-url https://download.pytorch.org/whl/nightly/cpu
LyCORISで学習できるようlycoris-loraもpipで入れます。
% pip install lycoris-lora
一旦 SDXL 用 Lora 学習ツールのsdxl_train_network.pyを動かしてみると
% python3 sdxl_train_network.py
...
A module that was compiled using NumPy 1.x cannot be run in
NumPy 2.2.1 as it may crash. To support both 1.x and 2.x
versions of NumPy, modules must be compiled with NumPy 2.0.
Some module may need to rebuild instead e.g. with 'pybind11>=2.12'....
...
File "/opt/homebrew/Cellar/python@3.10/3.10.16/Frameworks/Python.framework/Versions/3.10/lib/python3.10/importlib/__init__.py", line 126, in import_module
return _bootstrap._gcd_import(name[level:], package, level)
ImportError: numpy.core.multiarray failed to import
と出て正常に実行できないので、numpy 1.26.4をインストールします。
% pip install numpy==1.26.4
もう一度sdxl_train_network.pyを動かしてみると
$ python3 sdxl_train_network.py
...
in __init__
assert resolution is not None, f"resolution is required / resolution(解像度)指定は必須です"
AssertionError: resolution is required / resolution(解像度)指定は必須です
このエラーはオプション指定が足らないというエラーなので、正常に動作しています。
sd-scripts は HuggingFaceのaccelerateというモジュールを利用して、NVIDIA の cuda バックエンドや Apple の mps バックエンドなどを統一的に利用できるようにしています。acclerate configで accelerate の設定ができるので設定します。
% accelerate config
矢印キーを使って、
This machine
No distributed training
NO
NO
fp16
と設定してください。
以後はaccelerate launch --num_cpu_threads_per_process 4 sdxl_train_network.pyとすることで Lora 学習用スクリプトsdxl_train_network.pyを4スレッドで実行します。
ずんだもんのLora作成
ずんだもんというキャラクタの Lora を作成します。公式にAI学習用のデータセットが公開されているので利用します。
準備
まず、ブラウザで Google Drive にあるずんだもん公式学習データセットを開いてください。下から2番目のzundamonの右端の3点メニューを押してダウンロードします。Sarafiでダウンロードした場合標準ではDownloadフォルダのzundamonフォルダに展開された形でデータセットがダウンロードされるはずです。Finder 等でzundamon(1).png,zundamon(1).txt,zundamon(2).png...が入っているか確認してください。
次に学習用データセットフォルダdatasetと Lora 出力フォルダoutputsを作成します。
% mkdir dataset
% mkdir outputs
ダウンロードフォルダのzundamonフォルダをdatasetフォルダ内に1_zundamonという名前に変更して移動させてください。
% mv ~/Downloads/zundamon dataset/1_zundamon
Lora学習の実行
Lora の学習を行います。
学習設定は次のようにします。
| オプション指定 | 設定項目 | 内容 |
|---|---|---|
| --pretrained_model_name_or_path="../stable-diffusion-webui/models/Stable-diffusion/animagine-xl-3.1.safetensors | 対象モデル | animagine |
| --output_name="zundamon" | 出力ファイル名 | zundamon |
| --network_module=lycoris.kohya | 学習モジュール | lycoris.kohya |
| --resolution="768" | 学習画像解像度 | 768 |
| --optimizer_type="Lion" | オプティマイザ | Lion |
| --max_train_epochs=10 --save_every_n_epochs=2 | Lora生成 | 2ステップごとに10ステップまで生成 |
| --network_args "algo=loha" "conv_dim=16" "conv_alpha=1" --network_dim=16 --network_alpha=1 | network設定 | アルゴリズム loha、次元 16、alpha 1 |
このほか細かいオプションを追加しています。
次のコマンドで学習します(非常に長いですがコピー&ペーストしてください)。1時間以上かかるので実行後は終了するまで待っていてください。avr_lossがnanになった場合は学習に失敗しているので確認が必要です。Geforce 3060の場合は全く同じオプションで12分34秒、--mem_eff_attnを--xformersにした場合は11分41秒で学習できました。
% accelerate launch --num_cpu_threads_per_process 4 sdxl_train_network.py --network_module=lycoris.kohya --caption_extension=".txt" --resolution="768" --enable_bucket --bucket_no_upscale --learning_rate=1 --cache_latents --gradient_checkpointing --save_precision="fp16" --save_model_as=safetensors --optimizer_type="Lion" --max_train_epochs=10 --save_every_n_epochs=2 --pretrained_model_name_or_path="../stable-diffusion-webui/models/Stable-diffusion/animagine-xl-3.1.safetensors" --train_data_dir="dataset" --output_dir="outputs" --output_name="zundamon" --mem_eff_attn --lr_scheduler="cosine" --network_args "algo=loha" "conv_dim=16" "conv_alpha=1" --network_dim=16 --network_alpha=1
ほかにも色々オプションがあり、さまざまな学習が可能となっています。オプションの詳細はsd-scriptsの文書を参照してください。
正常に学習できている場合、outputsフォルダにzundamon.safetensors, zundamon-000002.safetensors,...の5個のファイルができているはずです。
Stalble Diffusion WebUIフォルダのmodelsフォルダのLoraフォルダに移動させてください。
% mv outputs/* ../stable-diffusion-webui/models/Lora
作成したzundamon Loraを適用して画像生成
仮想環境から出て、Stable Diffusion WebUI のフォルダに移動し、Stable Diffusion WebUI を起動して、学習した zundamon Lora を適用した画像生成を行いましょう。
% deactivate
% cd ../stable-diffusion-webui
% ./webui.sh
zundamon(1).txtの内容を利用して、次の設定とプロンプトで生成します。
| 設定項目 | 設定内容 |
|---|---|
| Sampling Method | Euler a |
| Sampling steps | 20 |
| Width | 768 |
| Height | 768 |
| CFG Scale | 7 |
| Prompt | zundamon, 1girl, one eye closed, shorts, solo, green footwear, sailor collar, full body, black socks, socks, white background, short sleeves, shirt, smile, v, simple background, green sailor collar, looking at viewer, shoes, white shirt, arm up, green shorts, open mouth, school uniform, standing, personification |
| Negative Prompt | bad quality, worst quality |
さらに Lora タブからzundamon.safetensorsを選んで生成してみてください。うまくずんだもんの画像が生成されるはずです。Lora を適用していない場合と比較してください。また、zundamon-000002.safetensorsは学習途中の2ステップ時のLora、zundamon-000004.safetensorsは4ステップ時のLoraとなっているので、こちらも試してみて、どのように学習されるのか確認してみてください。ただし、なんとなくですが Geforce 3060 で作成した Lora に比べるとあまりうまく学習できていないような気がしないでもないです。

CTRL+C で Stable Diffusion WebUI を終了し、sdフォルダに戻ります。
% cd ..
Stable Matrixを利用する場合
『パッケージを追加』の『Training』の『Show All Packages』に kohya_ss の GUI 版があるのですが、ミスがあるようで起動しません。kohya_ss のインストールフォルダ(Stable Matrix のインストールフォルダのPackages/kohya_ssフォルダ)で、次のコマンドを実行して
% pip install gradio toml easygui transformers
% pip install --pre torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/nightly/cpu
http://127.0.0.1:7860/を開けばおそらく動きます(起動するのを確認しただけで学習できるかは未検証です)。
Core MLによるNeural Engineを活用した画像生成
ここまでは Metal Performance Shader を利用した GPU による画像生成を行ってきました。ここからは AI 向けプロセッサの Neural Engine を活用可能な Core ML を使って画像生成していきます。
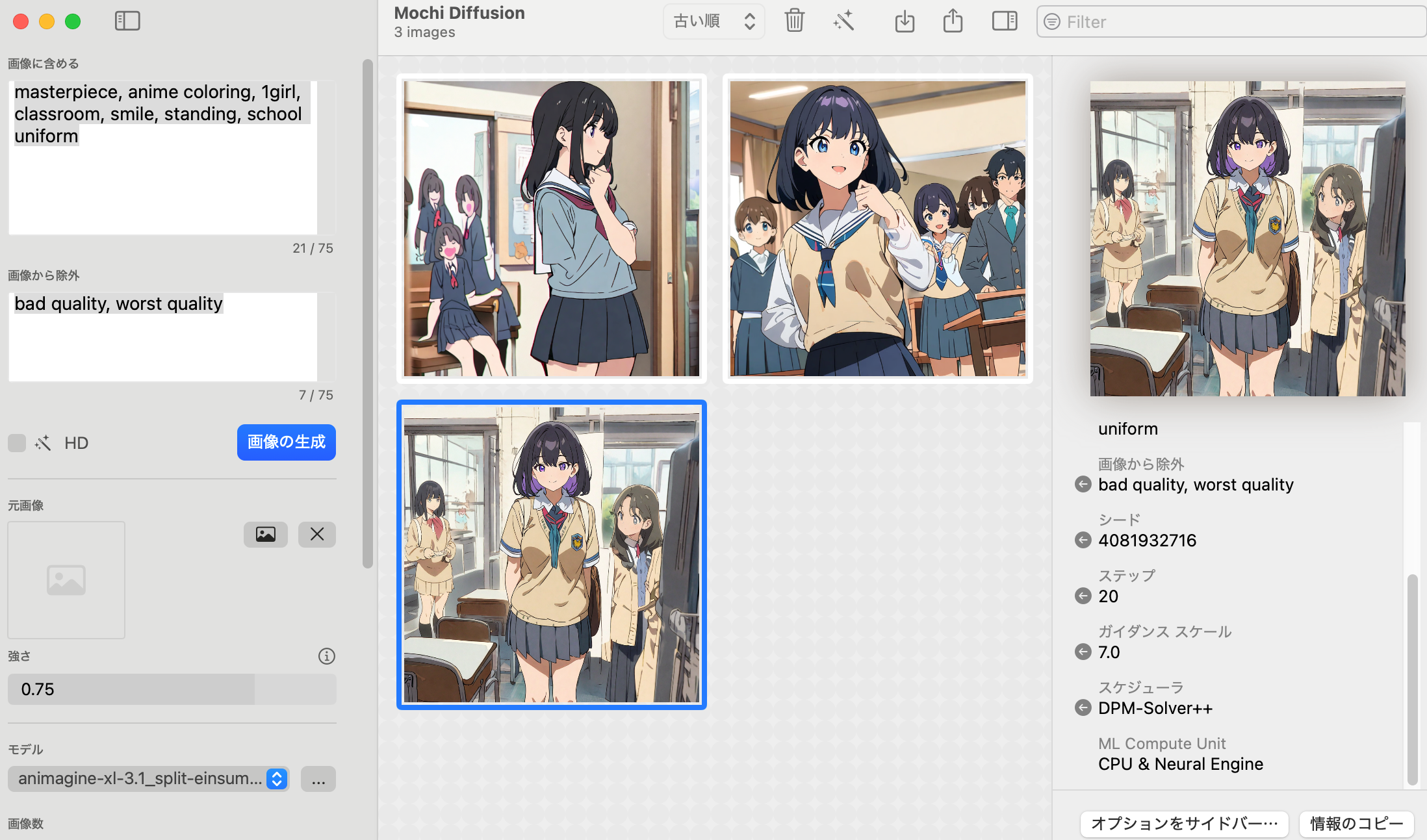
Mochi Diffusionでの画像生成
最初に GUI アプリケーションのMochi Diffusionを試してみます。
Mochi Diffusion のサイトの右の Releases の v5.2 を押してMochiDiffusion_v5.2.dmgをダウンロードしてください。Finder でダウンロードを開き、ダウンロードしたMochiDiffusion_v5.2.dmgをダブルクリックして、開かれたウィンドウの Mochi Diffusion のアイコンを右の Applications にドラッグしてください。
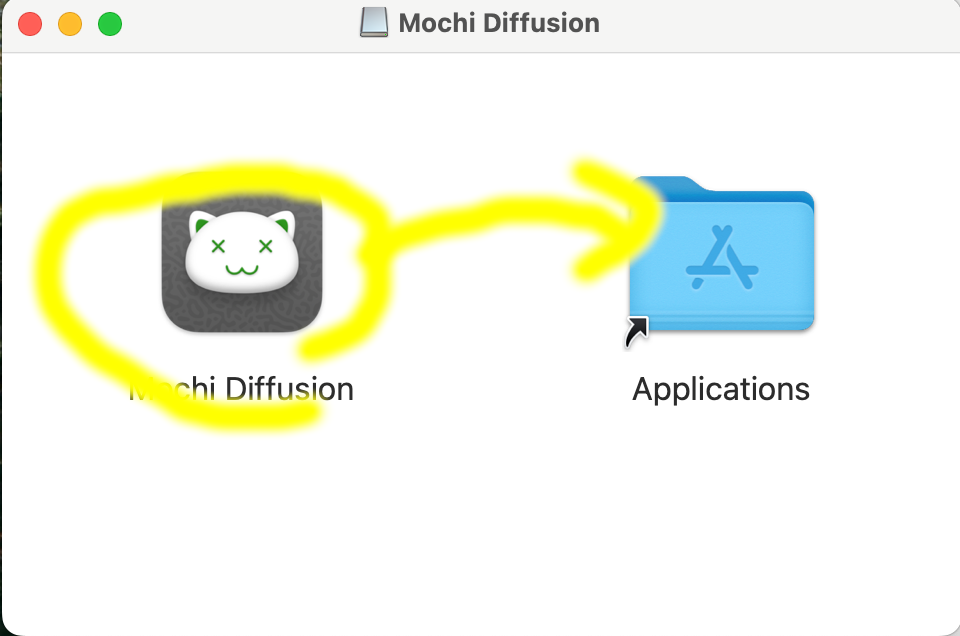
Dock の LaunchPad から Mochi Diffusionを起動します。最初に起動した際『開いてもよろしいですか?』と聞いてくるので開いてください。
Core ML では専用のモデルが必要です。Community modelsにさまざなまモデルが置かれているので、coreml-animagine-xl-3.1のsplit-einsum形式のモデルから1024x1024サイズ用と768x768サイズ用のものをダウンロードしてください。
Safari標準ではダウンロードした zip ファイルは自動的に展開されるので、Finder で ホームフォルダのMochiDiffusionフォルダ内にModelsフォルダを作り、その中にモデルをフォルダごと移動させてください。
一旦 Mochi Diffusion を閉じてもう一度起動すればモデルを選択できます。『animagine-xl-3.1_split-einsum_6bit_768x768』を選択して、『画像に含める』に『masterpiece, anime coloring, 1girl, classroom, smile, standing, school uniform』、『画像から除外』はそのまま『bad quality, worst quality」として、『画像の生成』を押してください。
初回実行時はモデルのロード時間がかかるのでだいぶ時間がかかります。2回目以降は20秒ぐらいで生成されるはずです。1024x1024の方も試してください。2回目以降は40秒ぐらいで生成されます。どちらも Stable Diffusion WebUI の半分以下で生成でき、画像の品質も問題なさそうです。
coremltoolsでの画像生成
coremltoolsは Core ML 経由で Neural Engineを利用したさまざまな画像生成ツールです。coremltools の詳しい解説は公式文書を見てください。
インストール
公式文書のインストール方法に従ってインストールします。フォルダ以下にgitでインストールします。
% git clone https://github.com/apple/ml-stable-diffusion.git
ml-stable-diffusionフォルダに移動します。
% cd ml-stable-diffusion
venvで仮想環境を作り、有効にして(プロンプトに(coreml)が付きます)、pipで必要なモジュールをインストールします。
% python3.10 -m venv coreml
% . coreml/bin/activate
% pip install -r requirements.txt
% pip install --pre torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/nightly/cpu
coremltoolsでの画像生成
MochiDiffusionフォルダのModelsフォルダ以下に入っている Core ML 用モデルで画像生成してみましょう。今までと同じ設定をコマンドオプションで指定します。
| オプション指定 | 設定項目 | 内容 |
|---|---|---|
| --prompt "masterpiece, anime coloring, 1girl, classroom, smile, standing, school uniform" | プロンプト | masterpiece, anime coloring, 1girl, classroom, smile, standing, school uniform |
| --negative-prompt "bad quality, worst quality" | ネガティブプロンプト | bad quality, worst quality |
| --num-inference-steps 20 | ステップ数 | 20 |
| --guidance-scale 7 | CFG | 7 |
| --scheduler EulerAncestralDiscrete | サンプラー | EulerAncestralDiscrete(Euler-a) |
| --compute-unit CPU_AND_NE | 使用プロセッサ | CPUとNeural Engine |
| -o images | 生成画像出力フォルダ | images |
% python3 -m python_coreml_stable_diffusion.pipeline --compute-unit CPU_AND_NE -o images -i ../../MochiDiffusion/Models/animagine-xl-3.1_split-einsum_6bit_768x768/ --model-version cagliostrolab/animagine-xl-3.1 --prompt "masterpiece, anime coloring, 1girl, classroom, smile, standing, school uniform" --negative-prompt "bad quality, worst quality" --num-inference-steps 20 --scheduler EulerAncestralDiscrete --guidance-scale 7
最初にhuggingface から Core ML 用でない普通のモデルもダウンロードするようなので時間がかかります(~/.cache/huggingface/hubフォルダ以下にダウンロードされます)。画像生成速度はモデルのロード時間が別にかかりますが画像生成本体の実行時間は14秒です。生成画像はimagesフォルダに保存されます。画像の品質も特におかしくないと思います(Unetの読み込み時にメモリ不足によるエラーが発生する場合があるようです。その場合はブラウザ等余計なものを閉じてからもう一度実行してください)。
1024x1024の画像も生成してみます。
% python3 -m python_coreml_stable_diffusion.pipeline --compute-unit CPU_AND_NE -o images -i ../../MochiDiffusion/Models/animagine-xl-3.1_split-einsum_6bit_1024x1024/ --model-version cagliostrolab/animagine-xl-3.1 --prompt "masterpiece, anime coloring, 1girl, classroom, smile, standing, school uniform" --negative-prompt "bad quality, worst quality" --num-inference-steps 20 --scheduler EulerAncestralDiscrete --guidance-scale 7
こちらは何かおかしいです。画像生成速度はモデルのロードはUNetのロードに時間がかかり10分以上、画像生成本体が13分47秒です。追試していたらうまく動かなくなりメモリ不足エラーが出るようになりました。
とりあえず、768x768で生成できているので次に行きます。coremltools の仮想環境から出て、ComfyUIフォルダに戻ってComfyUIの仮想環境を有効にします。
% deactivate
% cd ../ComfyUI
% . ComfyUI/bin/activate
ComfyUI-CoreMLSuiteを利用したComfyUIでの画像生成
ComfyUI には機能を拡張できるさまざまなカスタムノードがあります。Core ML を利用できるカスタムノードComfyUI-CoreMLSuiteを利用して画像生成しましょう。
ComfyUI-CoreMLSuite では UNet のみが Core ML で動作し、CLIP と VAE は GPU(mps)で動作します。
それぞれ、CLIP がプロンプトを処理してUnetに渡し、Kサンプラーが UNet を利用して CLIP で処理されたプロンプトに従い潜在空間で画像を生成し、VAEがKサンプラーで生成された潜在空間での画像を通常画像にデコードすることで、プロンプトに対応する画像が生成されます。
インストール
公式サイトの記述に従い、ComfyUI のカスタムノードのフォルダ(custom_nodes)に移動し、gitでインストールします。
% cd custom_nodes
% git clone https://github.com/aszc-dev/ComfyUI-CoreMLSuite.git
pipで必要なモジュールをインストールします。
% cd ComfyUI-CoreMLSuite
% pip install -r requirements.txt
ComfyUIフォルダに戻り、MochiDiffusion のModelsフォルダからモデルのシンボリックリンクを張りComfyUI で使えるようにします。Core MLで動くのは UNet のみなので、UNet のモデルのみリンクを張ります。
% cd ../..
% ln -s ~/MochiDiffusion/Models/animagine-xl-3.1_split-einsum_6bit_768x768/Unet.mlmodelc models/unet/animagine-xl-3.1_split-einsum_6bit_768x768.mlmodelc
% ln -s ~/MochiDiffusion/Models/animagine-xl-3.1_split-einsum_6bit_1024x1024/Unet.mlmodelc models/unet/animagine-xl-3.1_split-einsum_6bit_1024x1024.mlmodelc
ComfyUI を起動して、https://127.0.0.1:8188を開きます。
% python3 main.py
ComfyUI-CoreMLSuiteでの画像生成
公式サイトの使い方を参考に次のワークフローを作成します。
ワークフローのテンプレートを参照の画像生成を押して標準の画像生成ワークフローを出します。
『Add Node』の『Core ML Suite』の『Load Core ML UNet』と『Core ML Adapter(Experimental)』を追加します『Load Core ML UNet』の『右のcoreml_model』を『Core ML Adapter(Experimental)』の『左のcoreml_model』につなぎ、『Core ML Adapter(Experimental)』の『右のモデル』を『Kサンプラー』の『左のモデル』につないでください。
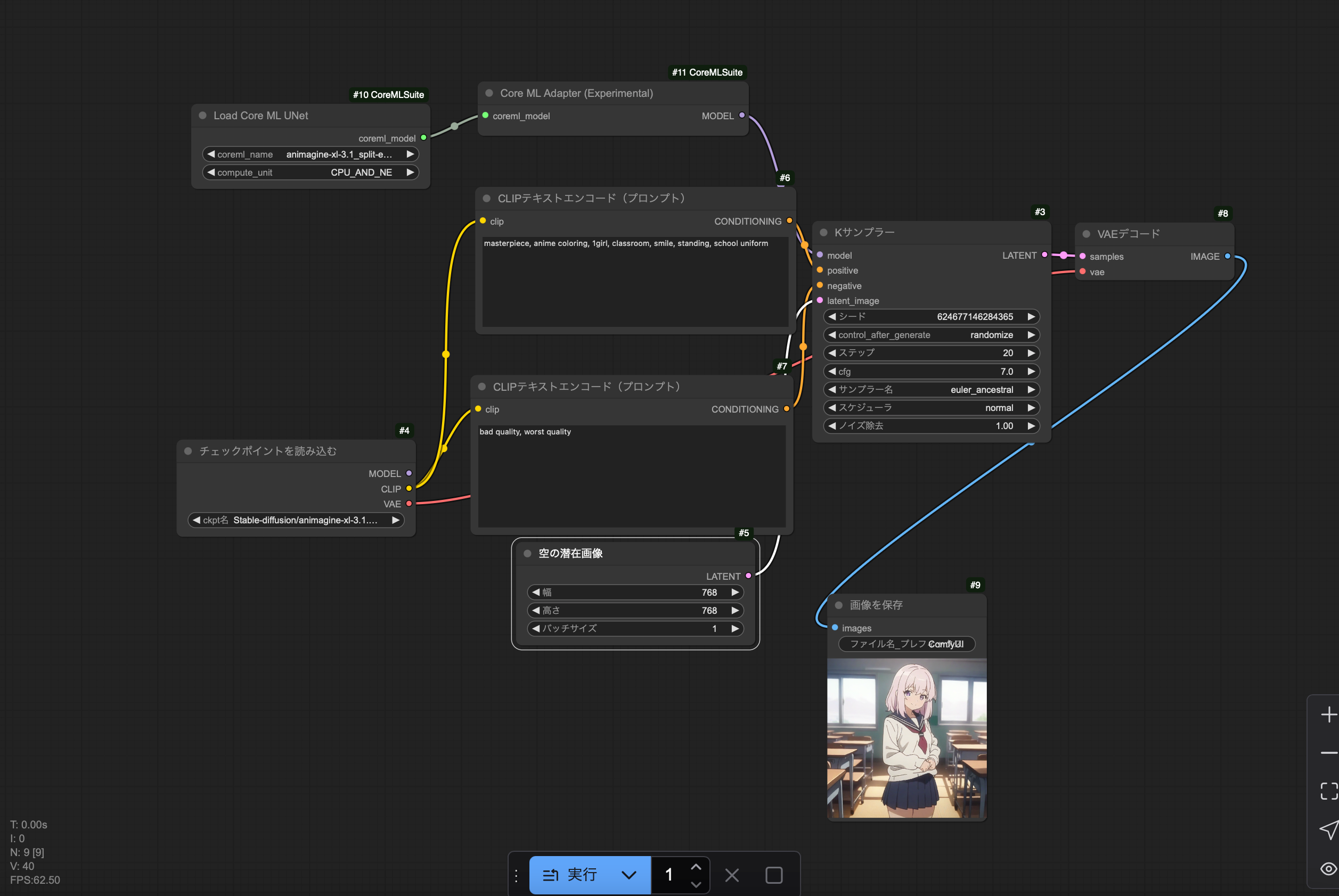
各ノードは次のように設定してください。
| ノード名 | 設定項目 | 設定内容 |
|---|---|---|
| Load Core ML UNet | coremlname | animagine-xl-3.1_split-einsum_6bit_768x768.mlmodelc |
| チェックポイントを読み込む | ckpt名 | Stable-Diffusion/animagine-xl-3.1.safetensors |
| 上のCLIPテキストエンコード(プロンプト) | テキスト欄 | masterpiece, anime coloring, 1girl, classroom, smile, standing, school uniform |
| 下のCLIPテキストエンコード(プロンプト) | テキスト欄 | bad quality, worst quality |
| Kサンプラー | cfg | 7 |
| Kサンプラー | サンプラー名 | euler_ancestral |
| 空の潜在画像 | 幅 | 768 |
| 空の潜在画像 | 高さ | 768 |
生成される画像のサイズについて、通常のモデルと異なり、Core ML ではモデルの潜在空間の大きさに対応したもののみ指定できます。今回は768x768対応モデルなので768x768以外を『空の潜在画像』ノードに指定してもエラーがでます。
初回はモデルのロードに時間がかかりますが、2回目以降は、プロンプトを変更しなければ、Kサンプラーでの画像生成とVAEデコードのみで済むので高速に生成されるはずです。実際34.36秒で生成されました。画像の品質も問題ないです。プロンプトを変更した場合その処理の時間が変更時に加わるだけなので、この場合でもCore ML を使わない場合より高速です。
『Load Core ML UNet』の『coremlname』に animagine-xl-3.1_split-einsum_6bit_1024x1024.mlmodel を指定し、『空の潜在画像』の『幅』を1024、『高さ』を1024にして1024x1024の画像も生成してみましょう。2回目以降は78.90秒で生成されました。まだ、高速化されましたがまだ少し遅いです。
Loraについて
ComfyUI-CoreMLSuite では Lora を Core ML モデルの直接適用することはできません。公式サイトでのワークフローは元のモデルに Lora をマージして Core ML 形式のモデルに変換して画像を生成するやり方です。手でマージしたモデルを Core ML モデルに変換しても同じなので、先ほど作成した DMD2 をマージしたモデルを Core ML に変換します。
Ctrl+C で ComfyUI を閉じ、ComfyUI の仮想環境を抜けて、ml-stable-diffusionのフォルダに移動し、ml-stable-diffusion の仮想環境を有効にします。
% deactivate
% cd ../ml-stable-diffusion
% . coreml/bin/activate
モデルの変換
素のanimagineモデルの変換
Loraマージモデルの変換の前に、素の animagine モデルを Core ML 形式に変換してみましょう。変換についてはこちらの解説記事が参考になります。また、パレットを利用した量子化(精度を落とす変わりにモデルを小さくする仕組み)などに関してはこちらのCore MLの解説記事を参考になります。
画像生成に必要なのは UNet、CLIP、VAE デコーダーですが、ComfyUI-CoreMLSuite では CLIP と VAE デコーダーは GPU(mps)で動かすので、Core ML モデルは Unet だけあればOKです。UNet、CLIP、VAEデコーダーを一括してて変換できますが(--convert-unet --convert-text-encoder --convert-vae-decoder)、UNetしかいらないので分けて変換してみます。
変換形式に関して次のように指定します。
| オプション | 設定項目 | 設定内容 |
|---|---|---|
| --xl-version | 対象モデル形式 | SDXL |
| --model-version cagliostrolab/animagine-xl-3.1 | 対象モデル | |
| -o animagine | 出力フォルダ | animagine |
| --compute-unit CPU_AND_NE | 処理装置 | CPUとNeural Engine |
| --quantize 6 | 量子化 | パレット化6bit |
| --attention-implementation SPLIT_EINSUM | attention形式 | SPLIT_EINSUM |
| --bundle-resources-for-swift-cli | 追加変換処理 | mlmodelcに変換 |
| --latent-w 96 --latent-h 96 | 潜在変数サイズ | 幅:96、高さ:96(768x768画像) |
UNet の変換は--convert-unetです。次のコマンドで UNet を変換します。
% python3 -m python_coreml_stable_diffusion.torch2coreml --convert-unet --xl-version --model-version cagliostrolab/animagine-xl-3.1 -o animagine --compute-unit CPU_AND_NE --quantize 6 --attention-implementation SPLIT_EINSUM --bundle-resources-for-swift-cli --latent-w 96 --latent-h 96
警告やエラーが出るので対応します。
...
scikit-learn version 1.6.0 is not supported. Minimum required version: 0.17. Maximum required version: 1.5.1. Disabling scikit-learn conversion API.
...
raise ValueError(
ValueError: The deprecation tuple ('no variant default', '0.24.0', "You are trying to load the model files of the `variant=fp16`, but no such modeling files are available.The default model files: {'vae/diffusion_pytorch_model.safetensors', 'text_encoder_2/model.safetensors', 'unet/diffusion_pytorch_model.safetensors', 'text_encoder/model.safetensors'} will be loaded instead. Make sure to not load from `variant=fp16`if such variant modeling files are not available. Doing so will lead to an error in v0.24.0 as defaulting to non-variantmodeling files is deprecated.") should be removed since diffusers' version 0.30.2 is >= 0.24.0```
scikit-learn 1.6.0が非対応となっているので、
scikit-learn 1.5.1をインストールします。
% pip install scikit-learn==1.5.1
variant=fp16という箇所がおかしいようなので、python_coreml_stable_diffusionフォルダののtorch2coreml.pyの『variant="fp16",』となっている3行を削除します。sedコマンドを利用して次のように入力してください。
% sed -e '/variant=\"fp16\",/d' python_coreml_stable_diffusion/torch2coreml.py > tmp
% mv -f tmp python_coreml_stable_diffusion/torch2coreml.py
テキストエディットで開き、メニューの編集の検索から『fp16』で探して、variant="fp16",となっている三ヶ所を削除してもかまいません。
もう一度実行します。5分以上かかりますが変換できているはずです(ストレージ容量不足のときは容量を確保してから実行しなおしてください。メモリ不足でエラーになる場合はブラウザを閉じるなどしてもう一度実行してください)。
% python3 -m python_coreml_stable_diffusion.torch2coreml --convert-unet --xl-version --model-version cagliostrolab/animagine-xl-3.1 -o animagine --compute-unit CPU_AND_NE --quantize 6 --attention-implementation SPLIT_EINSUM --bundle-resources-for-swift-cli --latent-w 96 --latent-h 96
animagineフォルダ内にStable_Diffusion_version_cagliostrolab_animagine-xl-3.1_unet.mlpackage(mlpackage形式の変換モデル)、その中のResourceフォルダ内にUnet.mlmodelc,merges.txt,vocab.jsonが生成されているはずです。Unet.mlmodelcがmlmodec形式の変換モデルです。
VAE も一応変換(--convert-vae)してみます。
% python3 -m python_coreml_stable_diffusion.torch2coreml --convert-vae --xl-version --model-version cagliostrolab/animagine-xl-3.1 --bundle-resources-for-swift-cli --compute-unit CPU_AND_NE -o animagine --attention-implementation SPLIT_EINSUM --quantize 6 latent-w 96 --latent-h 96
最後に CLIP を変換(--convert-text-encoder)してみますが、
% python3 -m python_coreml_stable_diffusion.torch2coreml --convert-text-encoder --xl-version --model-version cagliostrolab/animagine-xl-3.1 --bundle-resources-for-swift-cli --compute-unit CPU_AND_NE -o animazine --attention-implementation SPLIT_EINSUM --quantize 6 --latent-w 96 --latent-h 96
_assert_all_finite_element_wise(
File "(略)/sd/ml-stable-diffusion/venv/lib/python3.10/site-packages/sklearn/utils/validation.py", line 172, in _assert_all_finite_element_wise
raise ValueError(msg_err)
ValueError: Input X contains infinity or a value too large for dtype('float64').
値が無限になっているか大きすぎる値が存在しているので変換できないようです。Illustriousで同じように変換するとうまく変換できるので、モデルがおかしいのか変換スクリプトがおかしいのかわかりませんが、CLIP の変換に問題があるようです。CLIP の変換モデルは使わないので次に進みます。
変換した Core ML 用の UNet が動くか動作確認しましょう。一旦仮想環境を抜けて、『myanimagine.mlmodelc』としてモデルへリンクを張ります。
% deactivate
% cd ../ComfyUI
% ln -s ~/sd/ml-stable-diffusion/animagine/Resources/Unet.mlmodelc models/unet/myanimagine.mlmodelc
ComfyUIの仮想環境を有効にしてComfyUIを起動し、ブラウザをリロードしてLoad Core ML Unetのcoremlnameにmyanimagine.mlmodelcを指定して同様に生成してみてください。35秒で生成できたので問題なさそうです。
% . ComfyUI/bin/activate
% python3 main.py
次の作業のためにターミナルで Ctrl+C を押して ComfyUI を止めて、ComfyUI の仮想環境を抜けて、ml-stable-diffusionフォルダに移動し、ml-stable-diffusionの仮想環境を有効にします。
% deactivate
% cd ../ml-stable-diffusion
% . coreml/bin/activate
DMD2をマージしたモデルをCore ML用モデルに変換
ComfyUIフォルダのmodels/checkpointsフォルダににある DMD2 をマージしたモデル 『ComfyUI_00001_.safetensors』は safetensors 形式で、coremltools の変換スクリプトではそのまま扱えないので、一旦 diffusers 形式に変換する必要があります。この記事を参考に変換していきます。
HuggingFace の diffusers ツールにあるスクリプトを利用して変換します。
スクリプトをコマンドでダウンロードします。
% wget https://raw.githubusercontent.com/huggingface/diffusers/refs/heads/main/scripts/convert_original_stable_diffusion_to_diffusers.py
次のオプション設定で diffusers 形式に変換します。
| オプション | 設定項目 | 設定内容 |
|---|---|---|
| --from_safetensors | モデルフォーマット | safetensors |
| --checkpoint_path ../ComfyUI/models/checkpoints/ComfyUI_00001_.safetensors | 変換元モデル | ComfyUI_00001_.safetensors |
| --dump_path animaginelora | 変換モデル出力先 |
animagineloraフォルダ |
% python3 convert_original_stable_diffusion_to_diffusers.py --checkpoint_path ../ComfyUI/models/checkpoints/ComfyUI_00001_.safetensors --from_safetensors --device cpu --half --dump_path animaginelora
うまく変換できたらanimagineloraフォルダにmodel_index.json,...が生成されます。
今変換したanimagineloraフォルダにある diffusers 形式のモデル『animagineloracoreml』をで先ほどと同じ設定で 768x768サイズ画像用の Core ML形式モデルを『animegineloracoreml』(-o animagineloracoreml)と1024x1024サイズ画像用の Core ML 形式モデルを『animegineloracoreml2』(`-o animagineloracoreml2`)として変換します。
% python3 -m python_coreml_stable_diffusion.torch2coreml --convert-unet --xl-version --model-version animaginelora -o animagineloracoreml --compute-unit CPU_AND_NE --quantize 6 --attention-implementation SPLIT_EINSUM --bundle-resources-for-swift-cli --latent-w 96 --latent-h 96
% python3 -m python_coreml_stable_diffusion.torch2coreml --convert-unet --xl-version --model-version animaginelora -o animagineloracoreml2 --compute-unit CPU_AND_NE --quantize 6 --attention-implementation SPLIT_EINSUM --bundle-resources-for-swift-cli --latent-w 128 --latent-h 128
仮想環境を抜けて、それぞれ『myanimaginlora.mlmodelc』と『myanimaginlora2.mlmodelc』として ComfyUI 用にモデルのリンクを張ります。
% deactivate
% cd ../ComfyUI
% ln -s ~/sd/ml-stable-diffusion/animagineloracoreml/Resources/Unet.mlmodelc models/unet/myanimaginelora.mlmodelc
% ln -s ~/sd/ml-stable-diffusion/animagineloracoreml2/Resources/Unet.mlmodelc models/unet/myanimaginelora2.mlmodelc
ComfyUI の仮想環境を有効にして ComfyUI を起動し、ブラウザをリロードしてください。
% . ComfyUI/bin/activate
% python3 main.py
『Load Core ML UNet』の『coremlname』に『myanimaginelora.mlmodelc』を指定し、『Kサンプラー』の『ステップ数』を6、『cfg』を2にして生成してみてください。1024x1024サイズ画像は『Load Core ML UNet』の『coremlname』に『myanimaginelora.mlmodelc』を指定し、『空の潜在画像』の『幅』と『高さ』に 1024 を指定して画像生成してください。
768x768は2回目以降で12.10秒で、1024x1024は26.68秒です。速度的には十分速いです。ただDMD2 利用時の画像の品質がいまいちなのは変わらないので微妙な感じです。
HunyuanVideoによる動画生成(2025/1/5追加)
画像生成に加えて、HunyuanVideoに動画生成についても説明していきます。
元々のHunyuanVideoでは544x960の129フレームを作るのに 45GB かかるようですが、メモリが16GBしかないので、精度が下がる代わりにモデルサイズを縮小する量子化が行われているGGUFというファイルフォーマットのモデルで動画生成していきます。
GGUFについてはこの辺を参考にしてください。
以後の内容は次のページを参考にしています。
- https://zenn.dev/robustonian/articles/hunyuanvideo_mac
- https://note.com/gentle_murre488/n/na792165c724a
- https://blog.comfy.org/p/running-hunyuan-with-8gb-vram-and
インストール
ComfyUIにGGUFモデルを扱えるようにするComfyUI-GGUFとHunyuanVideoを扱えるようにするComfyUI-HunyuanVideoWrapperというカスタムノードを追加します。ただ、ComfyUI-CoreMLSuiteと共存できないので、別にもう一つComfyUIをインストールします。
HunyuanVideo用ComfyUIのインストール
一旦ホームフォルダに戻り、HunyuanVideoというフォルダを作成し、ComfyUI インストールしてそのフォルダに移動します。
% mkdir HunyuanVideo
% cd HunyuanVideo
% git clone https://github.com/comfyanonymous/ComfyUI.git
% cd ComfyUI
HunyuanVideoとして仮想環境を作り、有効にして(プロンプト(HunyuanVideo)が付きます)、必要なモジュールをインストールします。
% python3.10 -m venv HunyuanVideo
% . HunyuanVideo/bin/activate
% pip install -r requirements.txt
% pip install --pre torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/nightly/cpu
custom_nodesフォルダに移動し、ComfyUI-GGUFと必要なモジュールをインストールします。
% cd custom_nodes
% git clone https://github.com/city96/ComfyUI-GGUF.git
% cd ComfyUI-GGUF
% pip install -r requirements.txt
% cd ..
ComfyUI-HunyuanVideoWrapperと必要なモジュールをインストールし、ComfyUIフォルダに戻ります(以下のワークフローではこのカスタムノードを使用していない気がするのでこの作業は不要かもしれません(2025/1/7追記))。
% git clone https://github.com/kijai/ComfyUI-HunyuanVideoWrapper.git
% cd ComfyUI-HunyuanVideoWrapper
% pip install -r requirements.txt
% cd ../..
一旦 ComfyUI の動作確認をします。
% python3 main.py
http://127.0.0.1:8188/をブラウザで開いて正常に起動しているなら、Ctrl+C でComfyUI を終了させてください。
モデルのダウンロード
こちらよりGGUF形式のHunyuanVideoモデルのhunyuan-video-t2v-720p-Q6_K.ggufをダウンロードして、models/diffusion_modelsに保存します。
% wget -O models/diffusion_models/hunyuan-video-t2v-720p-Q6_K.gguf 'https://huggingface.co/city96/HunyuanVideo-gguf/resolve/main/hunyuan-video-t2v-720p-Q6_K.gguf?download=true'
こちらより bf16形式の VAE hunyuan_video_vae_bf16.safetensorsをダウンロードして、models/vaeに保存します。
% wget -O models/vae/hunyuan_video_vae_bf16.safetensors 'https://huggingface.co/Kijai/HunyuanVideo_comfy/resolve/main/hunyuan_video_vae_bf16.safetensors?download=true'
こちらより GGFU形式の LLM(Text Encoder) llava-llama-3-8B-v1_1-Q6_K.ggufをダウンロードして、models/text_encodersに保存します。
% wget -O models/text_encoders/llava-llama-3-8B-v1_1-Q6_K.gguf 'https://huggingface.co/city96/llava-llama-3-8b-v1_1-imat-gguf/resolve/main/llava-llama-3-8B-v1_1-Q6_K.gguf?download=true'
こちらより FLUX の Text Encoder の CLIP clip_l.safetensorsをダウンロードして、models/clipに保存します。
% wget -O models/clip/clip_l.safetensors 'https://huggingface.co/comfyanonymous/flux_text_encoders/resolve/main/clip_l.safetensors?download=true'```
動画生成
ComfyUIのサンプルより。HunyuanVideoのワークフローhunyuan_video_text_to_video.jsonをダウンロードしてください。
次のコマンドでComfyUIフォルダにダウンロードします。
% wget https://comfyanonymous.github.io/ComfyUI_examples/hunyuan_video/hunyuan_video_text_to_video.json
ComfyUI を起動し、ブラウザでhttp://127.0.0.1:8188/を開いてください。
% python3 main.py
メニューのワークフローの開くからComfyUIフォルダのhunyuan_video_text_to_video.jsonを選びアップロードを押してください(もしくはFinderでComfyUIフォルダを開きhunyuan_video_text_to_video.jsonファイルをブラウザにドラッグアンドドロップしてください)。
このワークフローを GGUF モデル用に修正します。
右クリックの Add Node の bootleg から『Unet Loader(GGUF)』を追加します。このノードで『拡散モデルを読み込む』ノードを置き換えます。『Unet Loader(GGUF)』の右のモデルを『モデルサンプリングSD3』の左のモデルにつなぎ、『Unet Loader(GGUF)』の右のモデルを『基本スケジューラー』の左のモデルにつなぎます。さらにhunyuan-videot2v-720p-Q6_K.ggufを選択してください。
次に右クリックの Add Node の bootleg から『DualCLIPLoader(GGUF)』を追加します。このノードで『デュアルCLIPを読み込む』ノードを置き換えます。『DualCLIPLoader(GGUF)』の右のCLIPを『CLIP Text Encode (Positive Prompt)』の左のクリップにつなぎ、clip_name1をclip_l.safetensors、clip_name2をllava-llama-3-8B-v1_1-Q6_K.gguf、typeをhunyuan_videoにしてください。
『VAEを読む』でhunyuan_video_vae_bf16.safetensorsを選択してください。
ComfyUIのブログより、メモリ使用量を削減するために『VAEデコード(タイル)』のタイルサイズを128に、オーバーラップを64に、temporal_sizeを32に、temporal_overlapを4にしてください。
そのままだと動画サイズが大きいので『EmptyHunyuanLatentVideo』の幅を640、高さを480、長さを25(24fpsなので1秒ちょっとの動画)にします。

プロンプトはそのままにします。
実行を押してください。1時間近くかかりますが(モデルのロード時間込み3117.73秒、動画生成本体46分19秒かかりました)、きつね娘が雪山の村を歩いている1秒ぐらいのアニメーションWebP形式の動画が生成されるはずです。

注
一般的なMP4形式の動画にしたい場合は、brewでffmpegをインストール(brew install ffmpeg)してComfyUI-VideoHelperSuiteカスタムノードをインストールして、Video Helper Suiteの『Video Combine』に必要な設定をして、『アニメーションWEBPを保存』ノードを削除して代わりに『VAEデコード(タイル)』の画像をimagesにつないでください。
Loraを使用した動画生成
Lora を使用した動画生成も可能です。Civitaiよりのアニメ調にするLoraのHunyuan Video Lora - AnimeShotsをダウンロードして、ComfyUIフォルダのmodels/lorasフォルダに移動させてください。Civitaiのアカウントがないとダウンロードできないので、アカウントを作成しログインしてダウンロードしてください。
右クリックの Add Node の ローダーから『LoRAを読み込む』を追加します。『Unet Loader(GGUF)』の右のモデルを『LoRAを読み込む』の左のモデルにつなぎ、『LoRAを読み込む』の右のモデルを『モデルサンプリングSD3』の左のモデルにつなぎ、『LoRAを読み込む』の右のモデルを『基本スケジューラー』の左のモデルにつなぎます。『DualCLIPLoader(GGUF)』の右のCLIPを『LoRAを読み込む』の左のクリップにつなぎ『LoRAを読み込む』の右のクリップを『CLIP Text Encode (Positive Prompt)』の左のクリップにつなぎます(現在既存のLoraはText Encoderの学習していないようなのでCLIPをLora経由する必要はないかもしれません(2025/1/5追記))。lora_nameをadapter_model.safternsorsにしてください。
『CLIP Text Encode(Positive Prompt)』のプロンプトをanime girl with pink twin tails and green eyes, wearing a school uniform, holding a stack of books in a bustling library filled with sunlight streaming through tall windows.にしてください。
『EmptyHunyuanLatenVideo』の長さを49にして2秒ぐらいの動画にします。

実行を押して動画を生成してください。2時間以上かかります(全体で7516.90秒、動画生成本体1時間53分37秒)。図書室で本を抱えている女の子の2秒ぐらいの動画が生成されるはずです。

非常に時間がかかりますが、M4 Mac miniでも動画生成できました。
Geforce 3060の場合FP8が使えるので(M4 Mac miniのmpsではFP8はPyTorchがエラーを出します(2025/1/7追記))、GGUF以外にComfyUI-HunyuanVideoWrapperのカスタムノードとFP8モデルを使って動かすことも可能です。こちらの記事が参考になります。M4 Mac miniと条件を合わせるために GGUF を使用する同じワークフローで生成した場合、最初の動画はモデルのロード時間込みで603.87秒(動画生成本体は3分20秒)、2個めの動画はプロンプト処理時に1回OOM(メモリ不足エラー)が出て再度実行して506.99秒(動画生成本体は7分54秒)かかりました。
画像生成速度やLora学習速度の比較一覧
| Stable Diffusion WebUI | M4 Mac mini | Geforce 3060 |
|---|---|---|
| 512x512(20ステップ) | 23.2秒 | 4.9秒 |
| 768x768(20ステップ) | 53.8秒 | 9.6秒 |
| 1024x1024(20ステップ) | 99.97秒 | 15.7秒 |
| 768x768(sdxl_lightning,6ステップ) | 17.6秒 | 4.5秒 |
| 768x768(DMD2,6ステップ) | 18秒 | 4.5秒 |
| ComfyUI | M4 Mac mini | Geforce 3060 |
|---|---|---|
| 512x512(20ステップ) | 23.23秒 | 4.3秒 |
| 768x768(20ステップ) | 58.77秒 | 8.32秒 |
| 1024x1024(20ステップ) | 118.06秒 | 14.36秒 |
| sd-scripts | M4 Mac mini | Geforce 3060 |
|---|---|---|
| ずんだもんlora | 1時間3分58秒 | 11分41秒 |
| coremltools(すべてNeural Engine) | M4 Mac mini |
|---|---|
| 768x768(20ステップ) | 14秒 |
| 1024x1024(20ステップ) | 13分47秒(なにかおかしい) |
| ComfyUI-CoreML-Suite(UNetのみNeural Engine) | M4 Mac mini |
|---|---|
| 768x768(20ステップ) | 34.36秒 |
| 1024x1024(20ステップ) | 78.90秒 |
| 768x768(DMD2, 6ステップ) | 12.10秒 |
| 1024x1024(DMD2, 6ステップ) | 26.68秒 |
| HunyuanVideo(動画生成本体のみ) | M4 Mac mini | Geforce 3060 |
|---|---|---|
| 25フレーム(1秒強の動画) | 46分19秒 | 3分20秒 |
| Lora付き49フレーム(2秒強の動画) | 1時間53分37秒 | 7分54秒 |
まとめ
M4 Mac mini での画像生成 AI では Neural Engine を活用しても Geforce 3060 ほど高速には生成できません。DMD2 のような高速化 Lora を活用しても画像の品質がいまいちのようです。メモリが 24GB や 32GB の M4 Mac mini なら VRAM が少ないグラフィックボードより意味があるかもしれませんが、現時点では VRAM は 12GB あれば大抵の画像生成AI機能が利用可能です。M4 Mac miniでも画像生成 AIが使い物にならないレベルではないですが、画像生成 AI 目的で M4 Mac mini を買う必要はないと思います。
画像生成 AI 用にパソコンを購入するなら、吊るしの M4 Mac mini より値段は高くなるでしょうが、Ryzen 5600 以上のCPU+メモリ 32GB以上に Geforce 3060 12GB か同等以上のグラフィックボードを搭載した Windows または Linux マシンがよいかと思います。
ただ、M4 Mac mini でネットを見たり、 MS Office で事務作業したり、コンパイル等の開発環境として使用しても特に問題はなく、M4 Mac miniは通常の目的に使うパソコンとしては全く問題ない性能を持っています。手元に M4 Mac mini があるなら、別のパソコンを購入せずとも M4 Mac mini で画像生成 AI を試してみる価値は十分あると思います。
更新履歴
- 2025/3/29
- sd-scripts で正しく学習できるよう修正
- 2025/1/13
- sd-scripts での学習がうまくいっていない気がするので追記
- 2025/1/7
- ComfyUI-HunyuanVideoWrapper について追記
- 2025/1/5
- HunyuanVideoによる動画生成を追加
- 2024/12/26
- 公開