まとめ
AlexNet以来、精度=レイヤ数という風潮があったが、本当にレイヤ数を増やすだけで精度は上げられるのか?という疑問を解消してくれる論文。
レイヤ数を増やしすぎると、ある段階でそれより浅いモデルの方が精度が良いという、「劣化」と呼ばれる現象が発生してしまうことがわかった。
こちらを解決するために、こちらの論文では新たにResidual Learning といったアプローチで学習をすることを提案している。このResidual LearningのキーとなるSkip Connectionを導入することで劣化問題が解決でき、CNNやPooling層のみで構成されているVGGなどの他モデルと比べ精度が向上した。
Residual Learning

・論文
・コード
本編
1. Abstract,Introduction
レイヤを11~19層と複数モデルを作り精度を調べたVGGの論文、「Very Deep Convolutional Networks for Large-Scale Image Recognition」で、19層のモデルの精度が一番高いことから、精度を上げるのであればレイヤ数を増やすことが大事であるとがわかる。
レイヤ数と精度の関係を表した表(VGG論文より)


ただここで、"Is learning better networks as easy as stacking more layers?"、レイヤ数をひたすら増やせばいいのか?という疑問が生じる。
今まであった勾配消失・爆発は Heの初期値や、Batch Normalizationなどである程度は対応できているが、新たにモデル劣化という問題が発生した。
モデル劣化とは
ディープなモデルに対しレイヤを増やしても、精度がある程度の形で飽和してしまう上に、学習の精度の劣化が急激に進んでしまうという現象のこと。
モデル劣化は、過学習が原因で起きることではなく、レイヤ数が既に最適であるモデルに対しレイヤを加えた場合、学習時の損失が大きくなってしまうという現象から来るものである。
"通常"CNNの学習時の誤差グラフ

56層の方が全体的に大きいことが分かる。
ここで、レイヤを増やす際、モデルのあるレイヤで学習した内容をそのままコピーするIdentity Mapping (恒等写像)レイヤにすることで、最低限コピーになるので、新たに作った深いモデルが、浅いモデルに比べ損失が増えるようなことはなくなる。
$H(x)$: 学習して欲しい関数
$F(x)$: 2層目のレイヤから出力される関数
今までは、$F(x)$→$H(x)$に近づける作業をしていた。
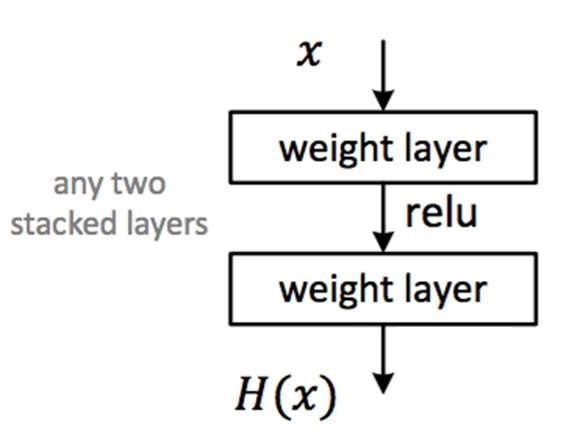
そこを、skip connectionでは$F(x) + x$→$H(x)$になるように近づける。
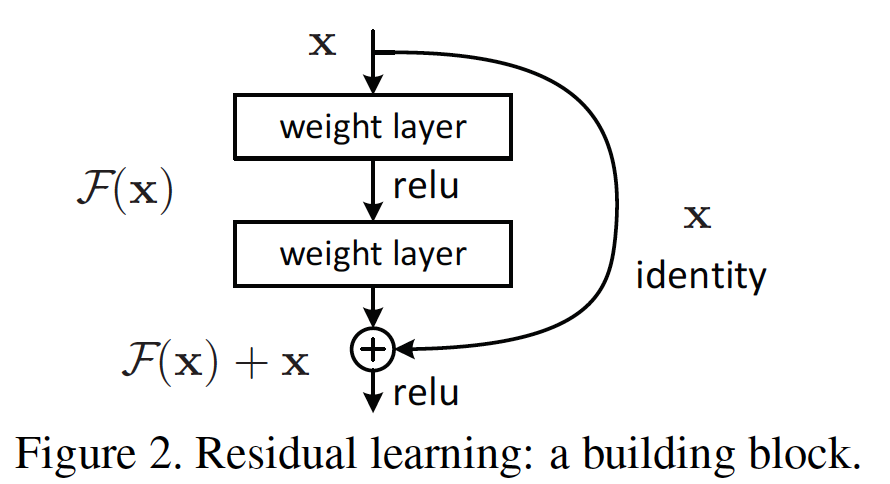
これは$F(x) = H(x) - x$になるように学習を進めていると同義。
つまり、何層か前で既に最適であった場合、$H(x) = x$、すなわち$F(x)=0$となりそれ以降の層では何も伝達せずただ0のみを伝達する。これを実現するのが、Skip Connectionになり、1+レイヤを恒等写像で結ぶことで実現可能。
Skip Connectionを加えることで、レイヤを増やしても学習損失は上がることは無く、素直に精度が上がっていくようになった。
また、学習データはImageNetだけでなく、CIFAR-10でも行うことでデータセット固有の傾向でないことも確認している。
2. Related Work
Skip Connectionに関連する過去の事例を紹介している。省略。
補足: 写像と射影
定義
写像
・写像
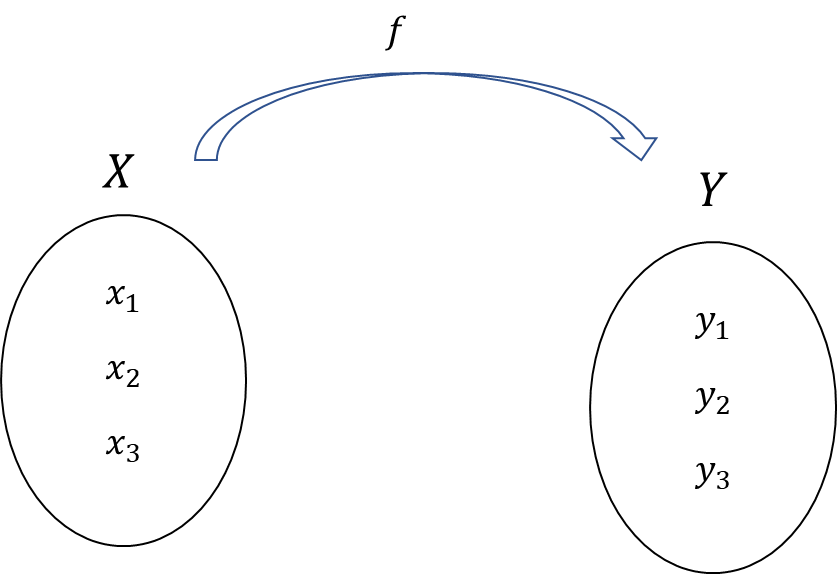
ある集合$X$と$Y$があった時、ある規則$f$(関数でも良い)で$X$のそれぞれの要素を$Y$のそれぞれの要素に対応させることを写像と呼ぶ。
・単射

集合$X$の要素が全て$Y$の集合のどれかに被らず該当する場合の写像である。
・全射

集合$Y$の要素は全て、$X$の集合の要素の写像に該当する。
・全単射

全射+単射両方を満たす写像のこと。
・恒等写像
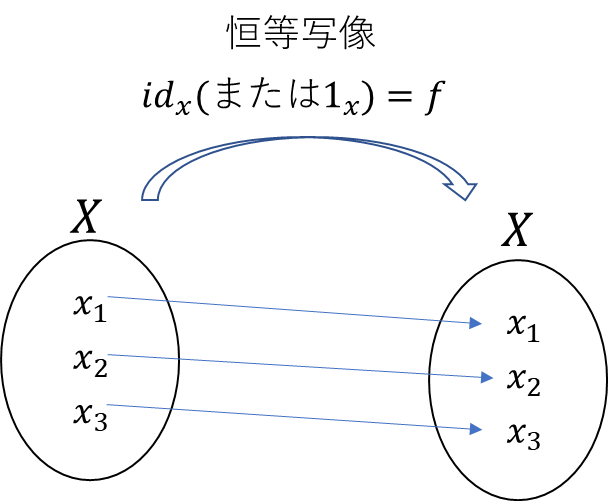
数字で言う「1」みたいな写像のこと。
射影
射影とは今ある字次元の情報を削減しつつ、別の形の情報に変換することをいう。
$y=W×x$みたいな変換のことを射影と呼ぶ。
結論
射影(Projection)≒写像(Mapping)で大体一緒と考えて良さそう。
3. Deep Residual Learning
3.1 Residual Learning
レイヤを重ねることて出てくる出力を求める関数$H(x)$に近づけるのではなく、$H(x)-x$に近づけようとするのが残差学習である。
3.2 Identity Mapping by Shortcuts
$y=F(x,{W_i})+x$ の意味は以下の通りで、$F(x,{W_i})$が学習を進める対象の"residual mapping"、残差写像である。

$F(x,{W_i})$はあくまで最終層からの出力で、例えば以前の図のように残差ブロックが2層であった場合は、$F={W_2}σ({W_1}x)$と表すことができる。※簡易のためバイアスは省略。

$H(x)$を近づけるのが$σ(F(x) + x )$ではないことに注意。
Skip Connection自体は恒等写像なので、新たにパラメータを増やすことは無い。
これは実用的な観点だけでなく、残差ブロックを採用していないプレーンなモデル(パラメータ数は一緒)と比較する際とてもしやすくなる。
$x$と$F(x)$の次元は等しい必要があるが、もしそうでない場合は新たに重み${W_s}$で線形射影することで次元を付け加える。(詳しくは後述)
また、スキップするレイヤ数は、2以上ならいくらでもいいが、レイヤ数が1、つまり$y={W_1}x+x$、であった場合はメリットが無いことがわかったそう。
3.3 Network Architectures
Residual Netモデルとプレーンなモデルを比較した際コンスタントに同じ現象が見られ、その一例を以下に示す。
比較した2つのモデル

プレーンモデル
左にあるプレーンモデルは34層の3x3畳み込み層で最後はGAP→全結合層で1000チャネルにしている。
細かい点
・Max Pooling無し
・Drop Outも無し
・Hidden FC無し(GAP後直後に1000クラス分類するため全結合する)
・FLOPs(Floating Point Operations)浮動小数点計算量=つまり計算回数が36億回
Residualモデル
右にあるResidualモデルはプレーンモデルにSkip Connectionを2層置きに加えただけで、残りは全く一緒。チャネル数が途中増えているが、その場合は2択で対応する。
(A) ある分の出力はそのまま恒等写像をし、空部分は0でPaddingをする。
→こちらはパラメータを増やす必要が無いというメリットがある。
(B) チャネル数を一致させるため、$x$を1x1の畳み込みでチャネル数分増やす。
$xとF(x)$の次元が合わず、${W_s}$で線形射影し付け加えるアプローチをする場合のイメージ図

両アプローチとも、strideは2で行う。
3.4 Implementation
Data Augmentation
・256~480の範囲で画像サイズを自由に変更するScale Augmentation
・ランダム横方向反転
した物を
・224×224にクロップ🤓
標準化/正規化
・Per-pixel mean subtraction(ピクセルごとに平均値を引く)
・Batch Nomalizationは畳み込み後、ReLUの前に入れる
過学習対策
・DropOut無し
ハイパーパラメータ
・Optimizer: SGD
・バッチサイズ: 256
・learning rate: 0.1からスタートし、飽和してきたら0.01
・iters: $60×10^4$
・momentum: 0.9
・weight decay: 0.0001
4. Experiments
4.1 ImageNet Classification
プレーンネットワークの場合
18層と34層のモデルを比べると、以下の表の左にあるように34層の方が高いValidationエラーを出してしまっている。
Top-1 Error[%]の比較

Training/Validationの損失のグラフをプロットした結果、劣化問題を観察することができた。
学習曲線
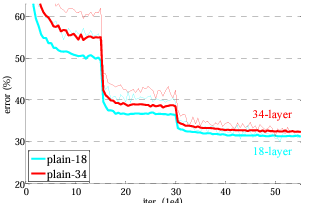
Batch Normalizationを加えているので、勾配が分散が0でない信号がForward/Backwardどちらにも送られているので、勾配消失することはない。
よってこの現象が勾配消失/爆発が原因となることは無い。
また、結果から分かるようにプレーンバージョンもそこまで精度として悪くない。
様々なモデルのエラー率[%]
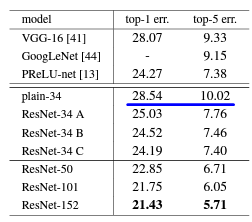
補足①
Top-1 Error
ただの正答率。
Top-5 Error
モデルが予測した上位5クラスの中に正しいクラスが入っていれば、正答として扱う。
(例) 正解ラベルが「犬」だった場合、上は誤答、下は正答として扱う。

補足②
10-Crop Testing
テスト時に行うData Augmentationの一種(TTA)。
元画像(黒枠)を4隅+真ん中で切り取ったバージョン、さらにそれぞれを水平方向にフリップしたバージョンの計10種類の画像で予測をし、最後は平均を取って最終的な回答を求める。

Residual Network
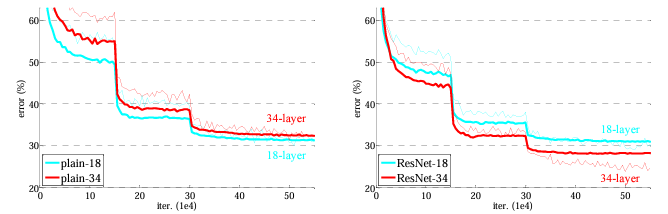
次に、18と34レイヤのResNetを評価する。プレーンバージョンにskip connectionを加えた以外は全く一緒。また今回の評価には、skip connection間のチャンネル数が一緒の場合は恒等写像、増やす場合はzero padding(3.3章-Residual Model- Aのアプローチ)で行う。よって、パラメータ数はプレーンバージョンと全く一緒になる。
その結果、以下に示すように、34レイヤモデルの方が18レイヤモデルより精度が良いと先ほどのプレーンバージョンとは逆の結果になっていて、34レイヤモデルはValidation用データによく汎化できていることがわかる。これから、Skip Connectionは劣化問題に対し有用な対策方法であることが示されている。
Top-1 Error[%]の比較

学習曲線

さらに、プレーンバージョンと比べると、以下に示すようにTop-1エラーを3.5%以上下げるなど大幅に改良が見られるので、Residual LearningがDeepなモデルに対し有能であることがわかる。
様々なモデルのエラー率[%]

また、18レイヤ間の比較をした場合、下の表のように精度はさほど変わらないが下の学習曲線のようにResNetの方が収束スピードが速い。(らしい。あんまり違いが分からないが)
Top-1 Error[%]の比較

学習曲線
Identity vs Projection Shortcuts
パラメータ無しの、恒等写像が有用であることを示したが、$y=F(x,{W_i})+{W_s}x$
のような線形射影をする場合なども考える。
(A) 増加するチャネル数分はZero-padding、残りは恒等写像
(B) 増加するチャネル数分は線形射影を行い、残りは恒等写像
(C) 全てのチャネルに対し線形射影
以上の3パターンを考える。
様々なモデルのエラー率[%]
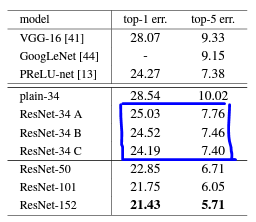
まず、いずれのパターンもプレーンバージョンよりは良いことがわかる。
またBがAより少し良く、これはzero-paddingしたチャネルはResidual Learningが行われないから($x=0$のため$H(x)=F(x)$になってしまう)であると考えている。
CはBより僅かに良いが、これはショートカットを介して行われた数多の写像によるものであると考えている。
A、B、C間で大きな差は見受けられないので、射影自体は劣化問題の解決のためにはあまり影響が無いと考えることができる。
よってモデルサイズを無駄に大きくしないようCはそれ以降使わない。
恒等写像は、次に説明するボトルネックアーキテクチャを無駄に複雑になることを防ぐために必要になる。
Deeper Bottleneck Architectures
より深いモデルを作成するにあたって、学習時間を省略するために、今まで説明していた左のようなブロックを、右のように変更する。

1x1畳み込みで次元の削減、拡張をするので、3x3の畳み込みの部分で情報が集約される。
もしこの256→256のskip connectionが恒等写像なら、演算コストはさほど変わらないらしい。
逆に、このskip connectionが射影だった場合、演算コストもモデルサイズも2倍になってしまうので(要計算)、恒等写像がとても重要になるとのこと。
・50-Layer ResNet
16ブロックあった元々の34 Layer ResNetの各ブロックに、先ほどのBottle Neck Architectureに変えるため、必然的に50 Layerとなる。次元調整の際は、B手法を使う。
参考: 34 Layer ResNet
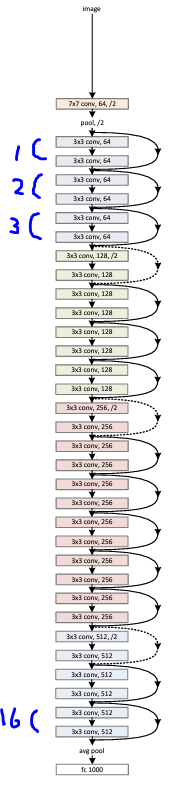
・101-Layer / 152-Layer ResNet
Bottle Neck Architectureを用い、101/152 LayerのResNetを構築。こちらも次元拡張方法は(B)を採用。
各ResNetのアーキテクチャの表

※[]の中は、各Residualブロックのアーキテクチャを示している。
結果
以下に示すように、ResNet-34から大幅な改善が見られ、また劣化の様子が無いこともわかる。

4.2 CIFAR-10 Analysis
CIFAR-10データセットを使い、さらに深い1202レイヤのモデルまでも構築した。
結果は以下。

・ResNet-110が一番良い結果となっていて、他に提案されている深いモデルより大幅にパラメータ数も少ない。
・ResNet-1202も決して悪くは無いが、これは過学習に依る物だと考えられるので今後過学習対策をして再び試す価値はあるとのこと。(流石に深すぎた。)
4.3 Object Detection on PASCAL and MS COCO
他識別タスクに対しても汎化能力が高いことを示している。
実装編
Plain Net 20 / 56
4.2章 CIFAR-10 and Analysisより、以下のような構造になっている。色が同じものは同じ畳み込み層であることを示していて、この$n$の数を変えることで、レイヤ数の違うモデルを作成している。

今回は、$n=3$及び$n=9$、つまり計20層及び56層のPlain Netを構築する。
iterationは64000回を最大としていて、32000回で学習率を変えている。
これをepoch数に変換すると、論文は1 batch 128で、1 epoch は45000枚となる。
なので最大epochは≒182、学習率の変更は≒91として良さそう。
iterationsとepochの違い
iterationは、1バッチ内のデータを全て使って勾配を計算し、その後1回アップデートすると1 iterationになる。epochはtraining用に使うで全データのことを指している。
学習率は0.1から始め、変換時に0.01に変えている。
結果

そもそもこの実験の意図は、層を重ねると精度が落ちる理由が過学習とは別の事象である劣化が起きていることを示すことにある。左の図から分かる良うに、56層モデルはTraining Errorまでも20層の物より高いので、論文通り劣化いう現象が再現できた。
ResNet 20 / 56
先ほどのPlainモデルにShortcut Connectionを実装するのだが、次元の埋め合わには、論文通りAアプローチ(恒等写像/0-Padding)を使う。
また、Skip Connectionを行う頻度としては2つのブロックごとにしている。
つまり、以下のようなアーキテクチャになる。

Aアプローチをする際、チャネルの次元に加えそもそものfeature mapのサイズが違うので、こちらはstride 2でダウンサンプリングを行う。
また、Skip Connectionを加えるタイミングは、Batch Normalizationを加えた後である。
結果
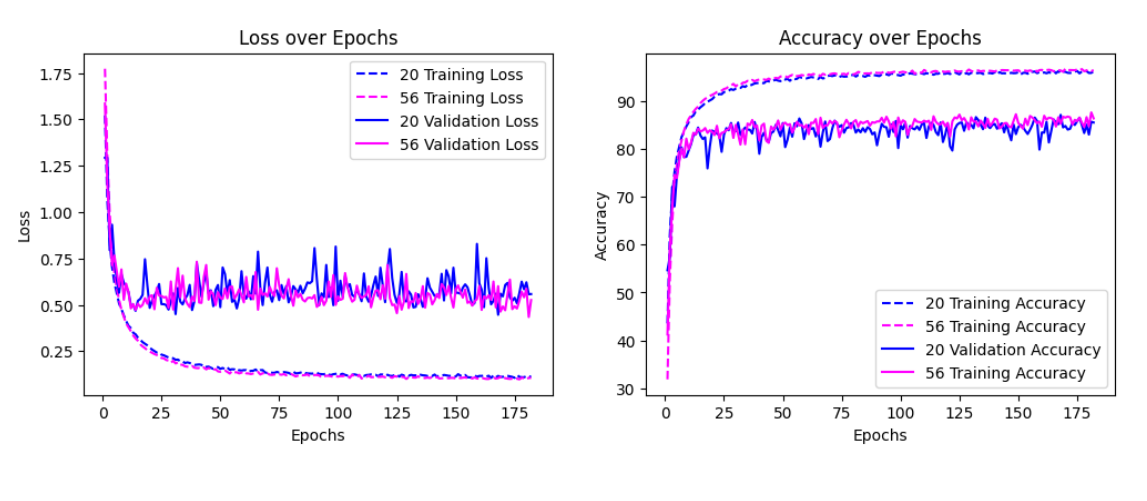
この実験を行う意図は、Residual Learning/Skip Connectionが劣化に対する対策として有効かどうかを示すものとなる。
PlainNetと比べると、20層に無駄にレイヤを足した56層モデルのTrainingデータに対するロスが悪化していない(どころか少しばかり良くなっている)ことが示せたので、目的が達成できた。
感想など
ニューラルネットワークの層を沢山重ねるとどうなるのかな...?という私の昔からの漠然な疑問に対する答えを、論文が教えてくれるという非常に有意義な経験ができたので大満足です。
また、実際に実装をすることで新たな発見もいくつもあり、次回からも実装をするモチベーションが生まれました。
具体的な発見は以下になります。
機械学習関連
・Drop Outなどの対策をしていないにも関わらず、20/56レイヤのPlain Netの方も過学習しないことに非常に驚いた。
・Batch Normalizationを加えていないと、全く学習が進まないことを体験した。
・論文とは若干違う結果になっているが、こちらはData Augmentationを省いたからであると考えられる。
Python関連
・//は、四捨五入して整数にしてくれるようの割算。
・テンソルの次元を指定する時は、[ ]ではなく ( )
・zero paddingをする際deviceを指定しない限りCPUにしか載らない。(モデルをGPUに載せている。)
:::
また、実装力不足を痛感したので、次回からはもう少し綺麗な形で書けるように頑張りたいと思います。
↓実装コード