本記事の内容
本記事は筆者がDynamoDBのテーブル設計をする上で学んだ、知っておくべき事や注意点をまとめたものです。
DynamoDBのテーブル設計に悩んでいる方にとって参考になればと思います。
DynamoDBについて
DynamoDBとは
Amazon DynamoDBはフルマネージドなサーバレスのkey-value NoSQLデータベースです。
NoSQLデータベースは非リレーショナルなデータベースを指す言葉です。
その中でもkey-valueデータベースは、キーと値をもつシンプルな方法をとっています。
RDBとの比較
DynamoDBとRDBは特徴が異なるため、目的に沿って取捨選択する必要があります。
大きく以下のような違いがあります。
| RDB | DynamoDB |
|---|---|
| データを柔軟に取得可能 | 限られた条件下でデータを効率的に取得可能 |
| 平均的にクエリのコストが高め | 条件外だとコストが高い |
| アクセスパターンを考慮しせずに設計可能 | アクセスパターンに沿って設計する必要がある |
| 高い整合性 | RDBに比べると整合性は低い |
DynamoDBの基本情報
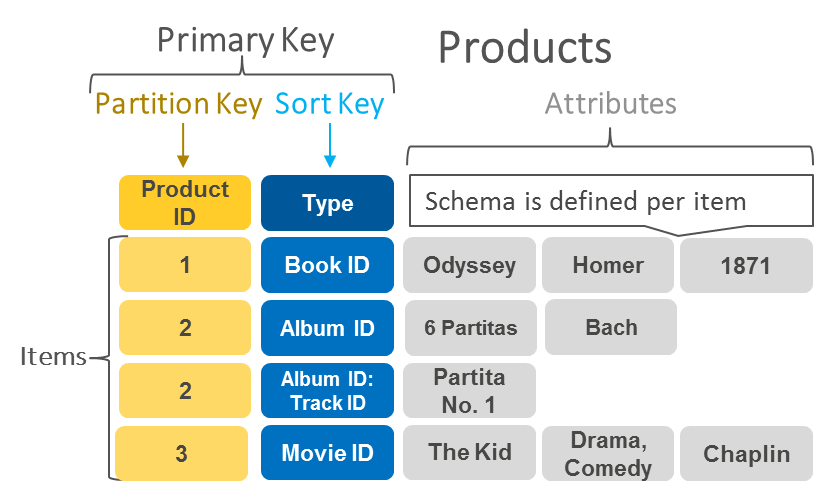
PrimaryKey(主キー)について
Primary Keyは、テーブルの各アイテムを一意に識別するためのキーです。Partition Key単体キーもしくはPartition Key + Sort Keyの複合キーで構成されます。
Primary Keyは一意である必要があるため、単体キーではPartition Key、複合キーではPartition Key + Sort Keyの組み合わせで一意でなければいけません。
複合キーではPartition Keyが重複していても問題ありませんが、Partition Keyごとにデータの領域を分けているため、重複するアイテムが増加するとパフォーマンスも悪化します。複合キーであっても、重複するアイテムが多くなるような設計は避け、Partition Keyのみで一意になるようにする場合が多いです。
クエリの条件について
DynamoDBは下記のような条件に沿わない場合、フルスキャンが発生してしまうため、アクセスパターンに沿ってテーブルを設計する必要があります。
- 必ず
Partition Keyは全文一致で指定する必要がある -
Sort Keyは全文一致、前方一致での検索などが可能
ソートキーの条件では、次の比較演算子の 1 つを使用する必要があります。
- a = b — 属性 a が値 b と等しい場合、true
- a < b — a が b 未満の場合、true
- a <= b — a が b 以下である場合、true
- a > b — a が b より大きい場合、true
- a >= b — a が b 以上である場合、true
- a BETWEEN b AND c — a が b 以上で、c 以下である場合、true。
次の関数もサポートされます。
- begins_with (a, substr) — 属性の値 a が特定のサブ文字列から始まる場合、true。
GSIとLSI
さすがに一つのPartition KeyとSort Keyだけでフルスキャンを回避したテーブル設計をするのは難しい場合が多いので、セカンダリインデックを利用します。セカンダリインデックスでは既存とは別のPartition Key, Sort Keyを設定することができます。DynamoDBではGlobal Secondary IndexとLocal Secondary Indexの2種類のセカンダリインデックスが存在します。
- LSI
- 昔からあるセカンダリインデックス
- 1テーブル5個まで作成可能
- あとから作成は不可能
- 強力な整合性のある読み込みが可能
- GSI
- 後発のセカンダリインデックス
- 1テーブル20個まで作成可能
- あとからでも作成可能
- 結果整合性のある読み込みが可能
基本的にはGSIのほうが使い勝手がいいため、GSIの方を利用することをおすすめします。
DynamoDBのテーブル設計について
Primary Key
Partition Key
-
Partition Keyが分散するように設計する- 一意になるようにuuidなどを設定するとよい
- 要件に合うのであれば重複してもよい
- 重複する数が定まっており多くない場合など
Sort Key
-
~の間や~以下、~以上の条件で検索する必要のある値を格納する - 複合ソートキーを活用する
- 例えば地域情報を
愛知県#名古屋市#中村区のように[都道府県]#[市]#[区]の形式で複数の値を一つの属性として保存する- 全文一致か前方一致に限るので注意(それ以外はフルスキャンが発生する)
- OK
-
愛知県名古屋市西区の地域情報を取得する -
愛知県北名古屋市に属する地域情報を取得する
-
- NG
-
豊田市の地域情報を取得する
-
- OK
- 全文一致か前方一致に限るので注意(それ以外はフルスキャンが発生する)
- 例えば地域情報を
GSI
スパースなインデックス
セカンダリインデックスを作成する際にPartition Key,Sort Keyに指定した属性を持たないアイテムは除外されます。これを利用することで、例えばランキング上位のプレイヤーを取得したい要件があった際に、上位プレイヤーにのみに属性を与えてセカンダリインデックスを作成することで、効率的にアイテムを取得することが可能です。
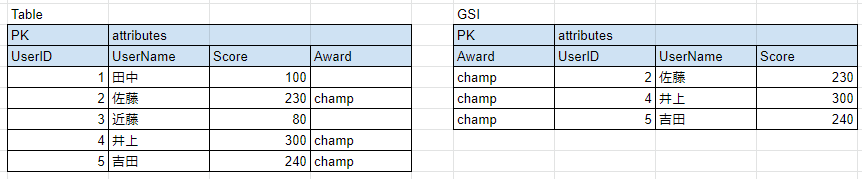
多重定義
セカンダリインデックスを別の属性ごとに作成する分費用がかかります。そこで、同じ属性に異なるデータを入れて複数のクエリに対応する多重定義を利用します。例えばイベント情報をDynamoDBで管理している場合に、下記のようなテーブル設計を行います。
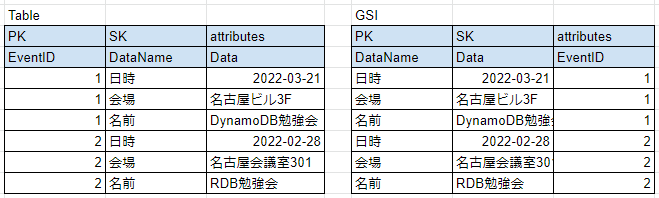
この状態であるイベント(EventID)の各情報(日時・会場・名前)を取得することができます。そして、もともとSort Keyだった部分をPartition Key、data属性をSort KeyとしてGSIを作成します。そうすることで複数のクエリに対応することができます。今回の場合では下記のような条件に対応することができます。
- ある日に行われるイベント(EventID)を取得する
- ある期間中に行われるイベント(EventID)を取得する
- ある会場で開かれるイベント(EventID)を取得する
- イベント名からイベント(EventID)を取得する
終わりに
DynamoDBのテーブル設計でしっておくべき情報を紹介させていただきました。実際にDynamoDBを触ってみることで深く理解できると思いますのでぜひチャレンジシてみてください。他にもAWSの公式情報としていろんな情報がのっていますのでそちらも見ておくことをおすすめします。