この記事では,「Seerの紹介」と「Seerによる動画予測」について執筆します.
参考文献
この記事は以下の情報を参考にして執筆しました.
Seerとは?
以下の論文で発表された「言語指示による動画予測モデル」です.
Seerは,ロボットに未来を予測する能力を持たせるために,事前に学習された"text-to-image (T2I) stable diffusion"を時間軸に沿って膨らませた(サンプル効率と計算効率の良い)モデルです.
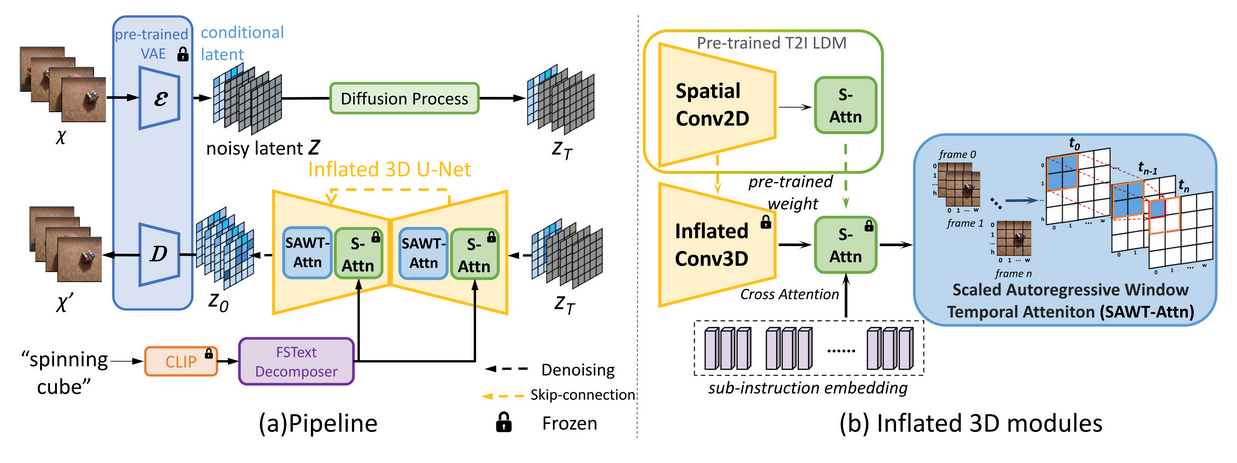
図:手法(出典:Seer)
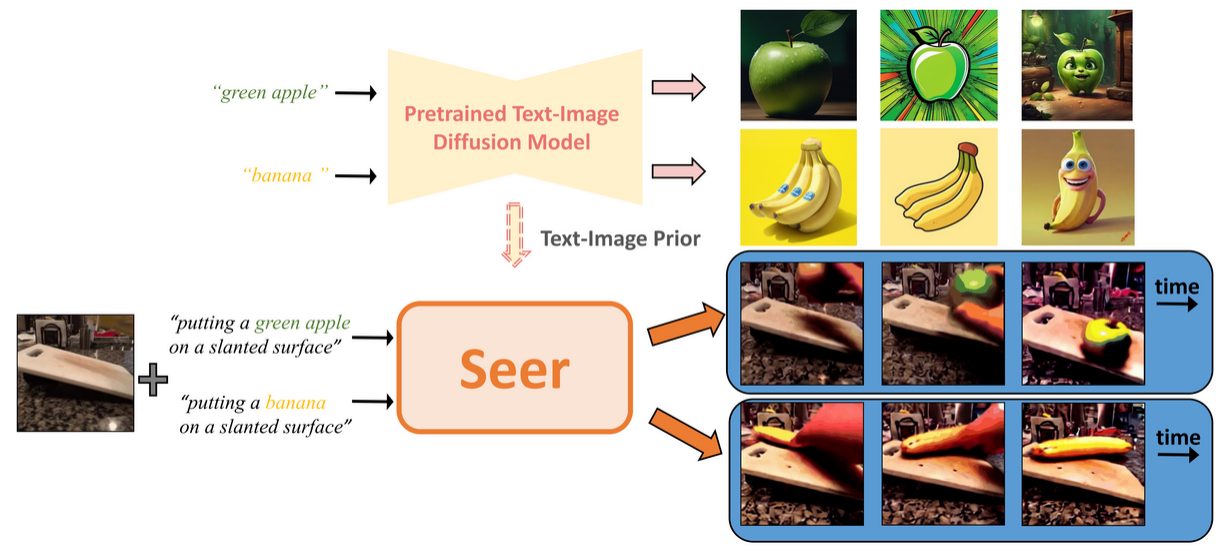
図:結果(出典:Seer)
Seerを用いた動画予測
以下のコードを用いて実際に動画予測を行ってみました.Google Colab(GPU: T4)で実行しました.
ライブラリのインストール
!pip install einops accelerate diffusers[torch]==0.11.1 rotary-embedding-torch==0.1.5 xformers
!pip install hydra-core --upgrade
学習済みモデルのダウンロードと移動
学習済みモデルは,以下の2つです.
- pytorch_model.bin
- pytorch_model_1.bin
学習済みモデルのダウンロード
!wget https://huggingface.co/xianfang/SeerVideo/resolve/main/sthv2bridge_seer/learned_sdunet-steps-80000/pytorch_model.bin
!wget https://huggingface.co/xianfang/SeerVideo/resolve/main/sthv2bridge_seer/learned_sdunet-steps-80000/pytorch_model_1.bin
学習済みモデルの移動
!mkdir -p ./outputs/sthv2_seer/learned_sdunet-steps-80000
!mv pytorch_model.bin ./outputs/sthv2_seer/learned_sdunet-steps-80000
!mv pytorch_model_1.bin ./outputs/sthv2_seer/learned_sdunet-steps-80000
"./configs/inference_base.yaml"の編集
- saved_global_step: 200000 # saved global steps of checkpoint folder
+ saved_global_step: 80000 # saved global steps of checkpoint folder
推論
!python inference_img.py --config="./configs/inference_base.yaml" --image_path="./src/figs/book.jpg" --input_text_prompts="close book"
推論結果
入力
- 画像

- プロンプト
# 本を閉じる
input_text_prompts = "close book"
出力
- Video Clip(GIF動画)

- 連続画像

まとめ
この記事では,「Seerの紹介」と「Seerによる動画予測」について執筆しました.