この記事はfreeeデータに関わる人たち アドベントカレンダーの7日目です。
データカタログを探索・発見できるOSS 「Amundsen」を使ってみたので紹介したいと思います。
データカタログとは
データカタログは広い意味がありますが、今回は、いわゆるビジネスデータカタログと呼ばれるものとして使います。簡単に言ってしまえば、ビジネス利用を目的とした企業内で保有するデータの辞書のようなものです。テーブルの定義だったりカラムの定義の説明などがまとまっています。
Amundsenとは
Amundsen is a data discovery and metadata engine for improving the productivity of data analysts, data scientists and engineers when interacting with data.
Amundsenはデータに関わるデータアナリスト、データサイエンティスト、エンジニアの生産性を上げるデータ探索ができるメタデータエンジンです。Amundsenは次の図のようにマイクロサービス化されています。
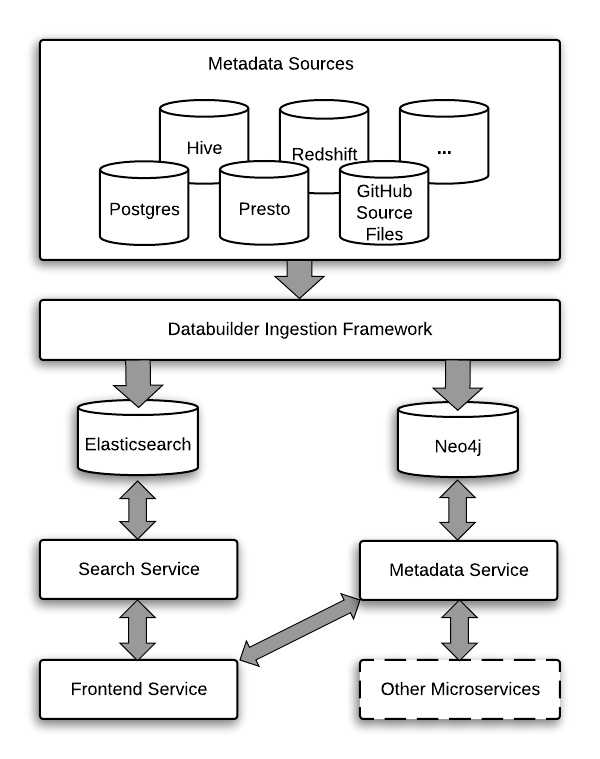
Metadata Sources(データベースなど)からメタデータ(テーブルやスキーマ情報)を取得し、Neo4jとElasticsearchに入れます。その情報をもとにAmudsenの検索エンジンUI(Frontend Service)から情報を確認できます。
ローカルでAmundsen 立ち上げる
dockerが用意されているので簡単にローカルで立ち上げることができます。
amundsenのgithubにインストールのやり方が丁寧に書いてあるのでそちらで確認してみてください
$ git clone --recursive git@github.com:amundsen-io/amundsen.git
$ cd (cloneしたamundsenのディレクトリ)
$ docker-compose -f docker-amundsen.yml up
dataを抽出して、Amundsenに反映
データのスキーマ情報を取ってきてAmundsenに反映させるFramework(amundsenbuilder)が用意されているので、これを使ってデータベースから簡単にデータを取ってこれます。
builderに必要なパッケージをインストールします。
$ cd (amundsenbuilderのディレクトリ)
$ python3 -m venv venv
$ source venv/bin/activate
$ pip3 install -r requirements.txt
$ python3 setup.py install
exampleのスクリプトが用意されているのでこれを実行します。
sample_data_loaderではサンプルのcsvファイルからデータをamundsenにロードします。
$ python3 example/scripts/sample_data_loader.py
glueからカタログを取ってくるスクリプトもあります(sample_glue_loader.py)。何も変更なしに実行するとglueにあるものを全部取ってきてしまうのでfilterで取ってくるglue data catalogのNameでfilterできるように変更します。
https://github.com/amundsen-io/amundsendatabuilder/blob/master/example/scripts/sample_glue_loader.py#L33
def create_glue_extractor_job(filter_key: []):
# ~~省略~~
'extractor.glue.{}'.format(GlueExtractor.FILTER_KEY): filter_key,
# ~~省略~~
if __name__ == "__main__":
filter = [{
'Key': 'Name',
'Value': 'accounts',
}] # glueのaccountsでfilter
glue_job = create_glue_extractor_job(filter)
glue_job.launch()
es_job = create_es_publisher_job()
es_job.launch()
filterの形式はKey, Valueのdict keyを持つobjectのリストを渡します。boto3のsearch_tablesを使っているので'Key'と'Value'は必須です。
実行する際にawsのglueにアクセスできるcredential(aws_access_key_id, aws_secret_access_key, tokenなど)を発行しておく必要があります。
$ python3 example/scripts/sample_glue_loader.py
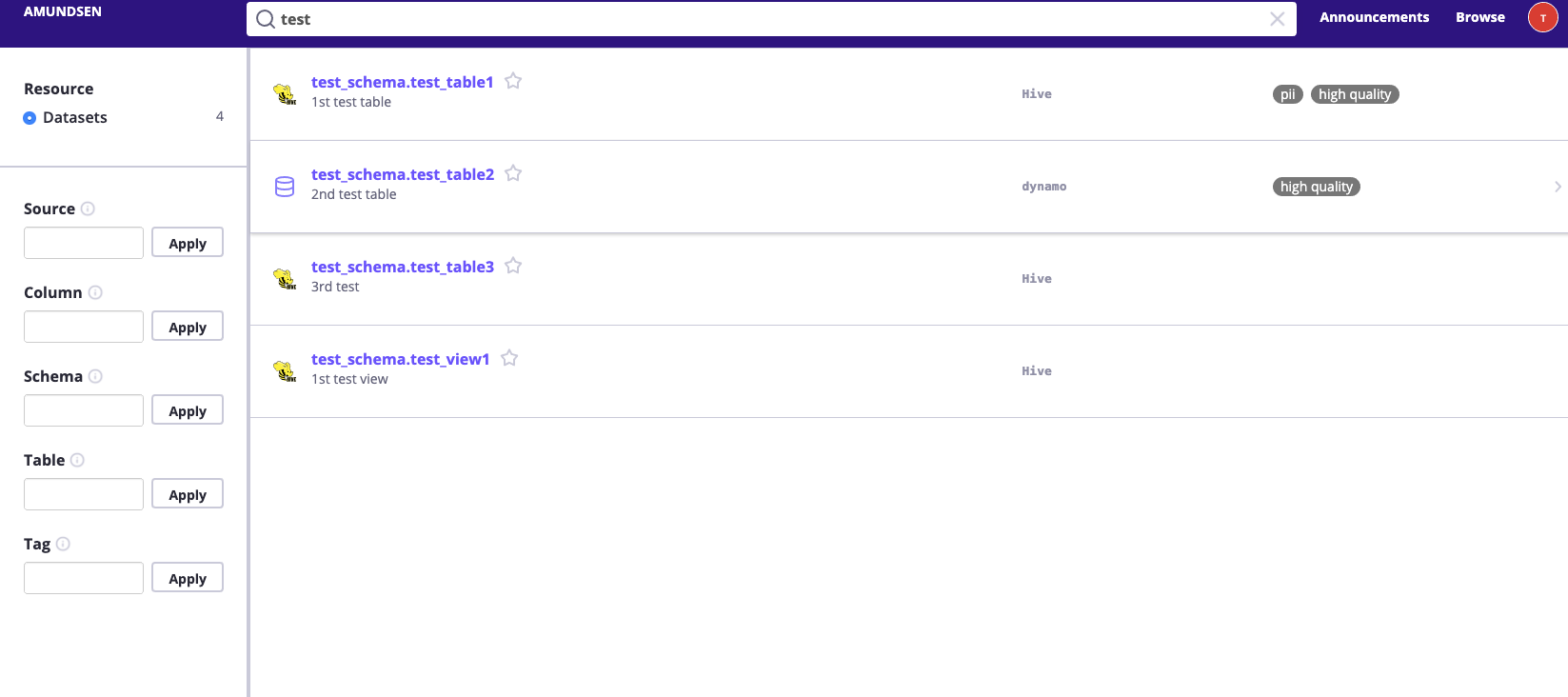
処理が終わったらlocalhost:5000でamundsenにアクセスし、データカタログが入っていることを確認します。
(下の図は実際に取ってきたデータではなくAmundsenのgithubのものです。)
使ってみて良い点
- UIがシンプルで見やすい
- UI上でdescriptionの編集ができる
- データのextractがdatabuilder使うと便利
- Athena, Bigquery, Glueなどの様々なデータソースから簡単に連携できる
残念な点・今後への期待
- tagが日本語対応してない
- descriptionの検索はできない
- 誰でもdescriptionの編集ができてしまう
- Userごとに編集権限を変えるといったことができない
- テーブル指定で編集できないように設定できる機能はあるがconfigにテーブルを一つずつ定義する必要がある
AmundsenはOSSで、見た感じ割と活発にcommitされているのでどんどん便利な機能が追加されていくと思います。
以上Amundsenについて紹介しました。