自然言語処理概要
WordNetについて触れる前に自然言語処理について簡単に触れておきます。
自然言語処理において機械に文章を理解させるためには、主に以下のように形態素解析、構文解析、意味解析、文脈解析の段階的なタスクが必要になります。
形態素解析
情報の注記の無い自然言語のテキストデータから、対象言語の文法や、辞書と呼ばれる単語の品詞等の情報にもとづき、形態素(言語で意味を持つ最小単位)の列に分割し判別する作業です。
例えば「お待ちしております」を形態素解析すると以下のようになります。
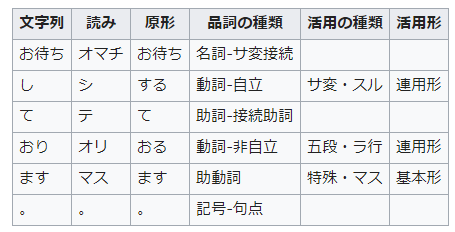
参考:wikipedia
代表的な形態素解析ツールとしてMeCabがあります。
構文解析
自然言語であれば形態素に切分け、関係を図式化するなどして明確にする手続きです。
例えば「美しい水車小屋の乙女」という文章があった時に以下のような2つの構文が考えられます。


参考:wikipedia
周りの形態素の情報を元にどのような繋がりがあるかを分析していきます。
代表的な分析ツールとしてCabochaなどがあります。
意味解析
機械に知識を与えるための手続きです。例えば以下の文章があったとします。
「高い富士山と海が美しい」
人間であれば高いがどの単語にかかっているのかがすぐにわかります。
「高い富士山」はあっても、「高い海」がないということは感覚的に判断ができます。しかしながら機械は何も知識を持っていませんので「高い海」がおかしいことを判断できません。
WordNetとは
シソーラスの1種。単語の上位 / 下位関係、部分 / 全体関係、同義関係、類義関係などによって単語を分類し、体系づけた類語辞典。それぞれの単語がどのような関係にあるかを体系づけたものであり、上述の意味解析などの際に使用されます。
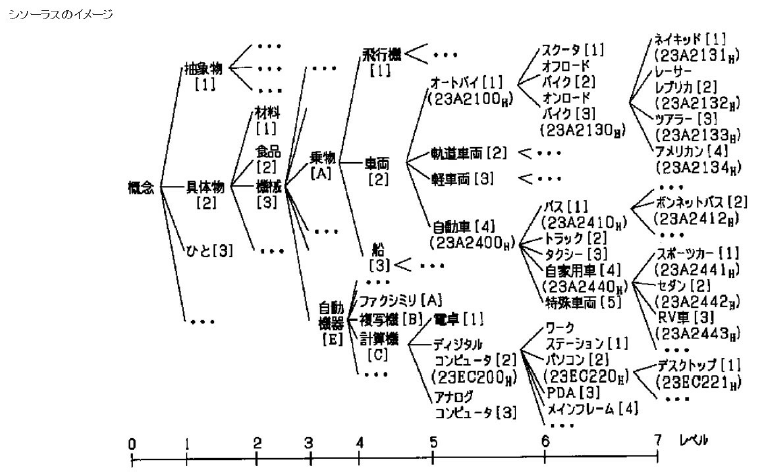
例えば「オンロードバイク」ですと、「オンロードバイク」を包含する上位概念が「オートバイ」や「車両」であり、下位概念として「ネイキッド」「アメリカン」といったバイクの種類が表されます。なお「バイク」と並列に記述されている「スクーター」「オフロードバイク」などが類似語とみなすことができます。
利用
これらはプログラムで扱えるようにまとめられたものが既に存在しており、以下よりダウンロードすることができます。 sqliteで公開されており、sqlを使って読み込みが可能です。
-
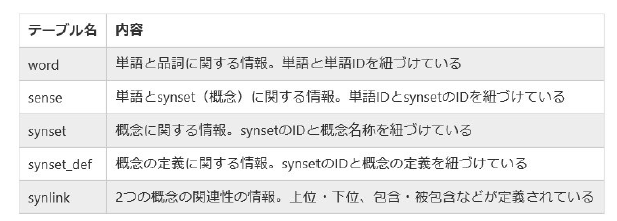
tableおよびカラム一覧
pos_def ('pos', lang', def')
link_def ('link', lang','def')
synset_def ('synset', 'lang', 'def', sid')
synset_ex ('synset', 'lang', 'def', 'sid')
synset ('synset', 'pos', 'name', 'src')
synlink ('synset1', synset2', 'link', 'src')
ancestor ('synset1', 'synset2', 'hops')
sense ('synset' ,'wordid','lang', 'rank', 'lexid','freq','src')
word ('wordid','lang', 'lemma', 'pron', 'pos')
variant ('varid','wordid','lang', 'lemma','vartype')
xlink ('synset', 'resource','xref', 'misc', 'confidence')
プログラム
確認1 : 各テーブルのカラムを確認する
- ソース
import sqlite3
conn = sqlite3.connect("wnjpn.db")
def chk_table():
print("")
print("###word table info")
cur = conn.execute("select count(*) from word")
for row in cur:
print("word num:" +str(row[0]))
cur = conn.execute("select name from sqlite_master where type='table'")
for row in cur:
print("=======================================")
print(row[0])
cur = conn.execute("PRAGMA TABLE_INFO("+row[0]+")")
for row in cur:
print(row)
if __name__=="__main__":
chk_table()
- 結果1
### word table info
word num:249121
=======================================
pos_def
(0, 'pos', 'text', 0, None, 0)
(1, 'lang', 'text', 0, None, 0)
(2, 'def', 'text', 0, None, 0)
=======================================
link_def
(0, 'link', 'text', 0, None, 0)
(1, 'lang', 'text', 0, None, 0)
(2, 'def', 'text', 0, None, 0)
=======================================
synset_def
(0, 'synset', 'text', 0, None, 0)
(1, 'lang', 'text', 0, None, 0)
(2, 'def', 'text', 0, None, 0)
(3, 'sid', 'text', 0, None, 0)
=======================================
synset_ex
(0, 'synset', 'text', 0, None, 0)
(1, 'lang', 'text', 0, None, 0)
(2, 'def', 'text', 0, None, 0)
(3, 'sid', 'text', 0, None, 0)
=======================================
synset
(0, 'synset', 'text', 0, None, 0)
(1, 'pos', 'text', 0, None, 0)
(2, 'name', 'text', 0, None, 0)
(3, 'src', 'text', 0, None, 0)
=======================================
synlink
(0, 'synset1', 'text', 0, None, 0)
(1, 'synset2', 'text', 0, None, 0)
(2, 'link', 'text', 0, None, 0)
(3, 'src', 'text', 0, None, 0)
=======================================
ancestor
(0, 'synset1', 'text', 0, None, 0)
(1, 'synset2', 'text', 0, None, 0)
(2, 'hops', 'int', 0, None, 0)
=======================================
sense
(0, 'synset', 'text', 0, None, 0)
(1, 'wordid', 'integer', 0, None, 0)
(2, 'lang', 'text', 0, None, 0)
(3, 'rank', 'text', 0, None, 0)
(4, 'lexid', 'integer', 0, None, 0)
(5, 'freq', 'integer', 0, None, 0)
(6, 'src', 'text', 0, None, 0)
=======================================
word
(0, 'wordid', 'integer', 0, None, 1)
(1, 'lang', 'text', 0, None, 0)
(2, 'lemma', 'text', 0, None, 0)
(3, 'pron', 'text', 0, None, 0)
(4, 'pos', 'text', 0, None, 0)
=======================================
variant
(0, 'varid', 'integer', 0, None, 1)
(1, 'wordid', 'integer', 0, None, 0)
(2, 'lang', 'text', 0, None, 0)
(3, 'lemma', 'text', 0, None, 0)
(4, 'vartype', 'text', 0, None, 0)
=======================================
xlink
(0, 'synset', 'text', 0, None, 0)
(1, 'resource', 'text', 0, None, 0)
(2, 'xref', 'text', 0, None, 0)
(3, 'misc', 'text', 0, None, 0)
(4, 'confidence', 'text', 0, None, 0)
確認2 : 登録されている単語(日本語)を確認する
- ソース
import sqlite3
conn = sqlite3.connect("wnjpn.db")
def chk_word():
#cur = conn.execute("select * from word limit 240000")
cur = conn.execute("select * from word where lang='jpn' limit 240000")
for row in cur:
print(row)
if __name__=="__main__":
chk_word()
- 結果2
一部のみ表示
(249100, 'jpn', 'スープ皿', None, 'n')
(249101, 'jpn', '引延す', None, 'v')
(249102, 'jpn', '渋色', None, 'n')
(249103, 'jpn', '断書き', None, 'n')
(249104, 'jpn', 'オールボルグ', None, 'n')
(249105, 'jpn', 'うしろ側', None, 'n')
(249106, 'jpn', '取繕', None, 'n')
(249107, 'jpn', '利便', None, 'n')
(249108, 'jpn', '利便', None, 'a')
(249109, 'jpn', 'ヴァイラス', None, 'n')
(249110, 'jpn', '古めかしい', None, 'a')
(249111, 'jpn', '懇切', None, 'n')
(249112, 'jpn', '懇切', None, 'a')
(249113, 'jpn', '超文面', None, 'n')
(249114, 'jpn', '性病', None, 'n')
(249115, 'jpn', 'まゆ墨', None, 'n')
(249116, 'jpn', 'ヘムライン', None, 'n')
(249117, 'jpn', '非近交系', None, 'a')
(249118, 'jpn', '科学機器', None, 'n')
(249119, 'jpn', '後ずさる', None, 'v')
(249120, 'jpn', '引繰り返す', None, 'v')
(249121, 'jpn', '意志', None, 'n')
確認3 : 類義語を抽出する
- ソース
import sqlite3
conn = sqlite3.connect("wnjpn.db")
def main(word):
print("")
print("")
print("## 入力: 【",word,"】")
print("")
# 単語がWordnetに存在するか確認
cur = conn.execute("select wordid from word where lemma='%s'" % word)
word_id = 99999999
for row in cur:
word_id = row[0]
if word_id==99999999:
print("「%s」is not exist" % word)
return
#概念を取得
cur = conn.execute("select synset from sense where wordid='%s'" % word_id)
synsets = []
for row in cur:
synsets.append(row[0])
print(synsets)
#概念に含まれる単語の表示
for synset in synsets:
cur1 = conn.execute("select name from synset where synset='%s'" % synset)
for row1 in cur1:
print("## 概念: %s" %(row1[0]))
cur2 = conn.execute("select def from synset_def where (synset='%s' and lang='jpn')" % synset)
for row2 in cur2:
print("## 意味: %s" %(row2[0]))
cur3 = conn.execute("select wordid from sense where (synset='%s' and wordid!=%s)" % (synset,word_id))
for i,row3 in enumerate(cur3):
target_word_id = row3[0]
cur3_1 = conn.execute("select lemma from word where wordid=%s" % target_word_id)
for row3_1 in cur3_1:
print("類義語"+str(i+1)+": %s" % (row3_1[0]))
print()
if __name__=="__main__":
word="自動車"
main(word)
- 結果3
## 入力: 【 自動車 】
['03791235-n', '02958343-n']
## 概念: motor_vehicle
## 意味: レールの上を走らない自動推進式の車輪のついた乗物
類義語1: motor_vehicle
類義語2: automotive_vehicle
類義語3: モータービークル
## 概念: auto
## 意味: 4輪の自動車
## 意味: 通常、内燃エンジンによって推進する
類義語1: auto
類義語2: motorcar
類義語3: machine
類義語4: car
類義語5: automobile
類義語6: 四輪車
類義語7: オートモービル
類義語8: 車
類義語9: 乗用車
類義語10: オートモビル
類義語11: モーターカー
類似語抽出の流れとして「自動車」を入力したらまず、自動車の上位概念である「motor_vehicle」「auto」をたどり、その配下にある単語を抽出することで、「自動車」と並列関係にある単語を取り出しています。