Word2Vecとは
- 簡単に言うと単語を入力すると、類似単語を出力することができる仕組み。
- 論文 Efficient Estimation of Word Representations in
Vector SpaceUI (2013,Tomas Mikolov,Google Inc) - 単語をベクトル表現化することで、単語同士に距離を持たせる
- modelは2種類、skip-gram,cbow
skip-gram
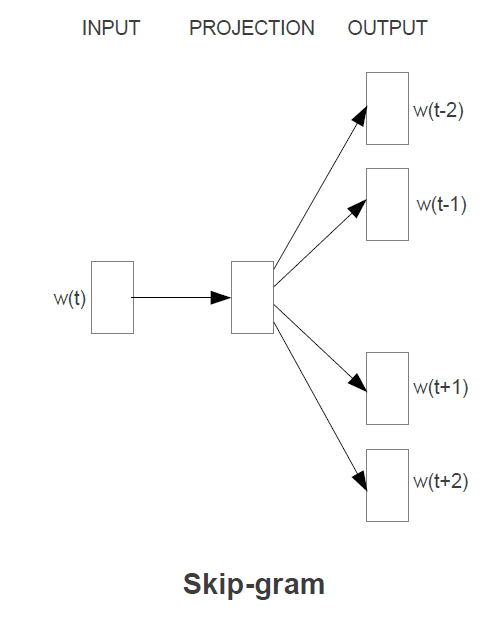
- 1つの単語から複数の単語を予測する
- 学習時間:⼤
- 論⽂ではcbowより若⼲精度良
cbow
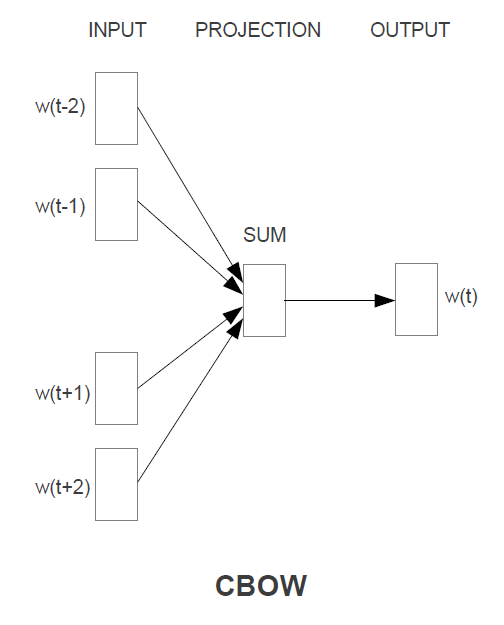
- 複数単語から1つの単語を予測するモデル
- 学習時間:少
実装
使用するライブラリおよびデータは以下
- MeCab
- gensim
- wikiデータ
準備
- MeCabインストール
# MeCabインストール
$sudo apt install mecab
# 辞書をインストール
$sudo apt install mecab-ipadic-utf8
# pythonのライブラリインストール
$pip install mecab-python3
# configファイルのインストール
$sudo apt install libmecab-dev
- gensimインストール
$ pip install gensim
- wiki記事のダウンロード
$ curl https://dumps.wikimedia.org/jawiki/latest/jawiki-latest-pages-articles.xml.bz2 -o jawiki-latest-pages-articles.xml.bz2
-
wiki記事の整形
以下よりwikiextractorをダウンロードしておく
$ python setup.py install
$ python WikiExtractor.py jawiki-latest-pages-articles.xml.bz2
$ find text/ | grep wiki | awk '{system("cat "$0" >> wiki.txt")}'
$ mecab -Owakati wiki.txt -o wiki_wakati.txt
$ nkf -w --overwrite wiki_wakati.txt
学習
from gensim.models import word2vec
import logging
logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level=logging.INFO)
sentences = word2vec.Text8Corpus('./wiki_wakati.txt')
model = word2vec.Word2Vec(sentences, size=200, min_count=20, window=15)
model.save("./wiki.model")
推論
- 推論する際にpositiveに指定した単語と類似の単語を抽出することが可能。
- またpositiveを複数指定すれば、療法の単語に近い単語が抽出できる。
- positiveとnegativeを指定することで、単語の意味の引き算をすることが可能。
推論1
from gensim.models import word2vec
model = word2vec.Word2Vec.load("./wiki.model")
results = model.wv.most_similar(positive=['講義'])
for result in results:
print(result)
結果1
('授業', 0.7282282114028931)
('講話', 0.6820641756057739)
('講演', 0.6787524819374084)
('講読', 0.6742540597915649)
('レクチャー', 0.6424188017845154)
('講座', 0.6407526731491089)
('フィールドワーク', 0.6059380769729614)
('聴講', 0.5993057489395142)
('進講', 0.5855057239532471)
('勉強', 0.5780803561210632)
「講義」と類似の単語が抽出された
推論2
from gensim.models import word2vec
model = word2vec.Word2Vec.load("../../dataset/w2v_wiki/wiki.model")
results = model.wv.most_similar(positive=['メジャー',"野球"])
for result in results:
print(result)
結果2
('大リーグ', 0.6116142272949219)
('NPB', 0.6107013821601868)
('MLB', 0.6046764254570007)
('バスケットボール', 0.5617710947990417)
('イーグルス', 0.5606954097747803)
('イチロー', 0.5525334477424622)
('球界', 0.5518677830696106)
('CFL', 0.5486886501312256)
('アメリカンフットボール', 0.5478270053863525)
('レッドストッキングス', 0.5468316078186035)
「メジャー」「野球」両方に関係のある単語が取得できている
- 参考:「メジャー」のみの時の結果
('マイナー', 0.706134557723999)
('プロ', 0.5638894438743591)
('ルーキー', 0.5499024987220764)
('ブルージェイズ', 0.5397061109542847)
('モントリオール・エクスポズ', 0.5390951633453369)
('MLB', 0.536774754524231)
('オリオールズ', 0.5358902812004089)
('エクスポズ', 0.5329082608222961)
('アストロズ', 0.5280351042747498)
('一軍', 0.5272071361541748)
- 参考:「野球」のみの時の結果
('ヤクルト', 0.7376969456672668)
('日本ハム', 0.716887354850769)
('千葉ロッテ', 0.6957686543464661)
('ロッテ', 0.6921555995941162)
('阪神タイガース', 0.6906307935714722)
('オリックス', 0.6852249503135681)
('広島東洋カープ', 0.6677668690681458)
('横浜ベイスターズ', 0.6603774428367615)
('中日', 0.6575911045074463)
('パ・リーグ', 0.6330403685569763)
推論3
from gensim.models import word2vec
model = word2vec.Word2Vec.load("../../dataset/w2v_wiki/wiki.model")
results = model.wv.most_similar(positive=['東京',"ロンドン"],negative=["日本"])
for result in results:
print(result)
結果3
('ケンジントン', 0.5750640034675598)
('ニューヨーク', 0.563010573387146)
('サザーク', 0.5527547001838684)
('ブライトン', 0.5462611317634583)
('ハムステッド', 0.5348111987113953)
('バーミンガム', 0.5297024846076965)
('パリ', 0.5293666124343872)
('イズリントン', 0.5272073745727539)
('ダブリン', 0.5166401863098145)
('ストラトフォード', 0.5041124820709229)
「東京」、「ロンドン」に関係する単語から「日本」に関係する単語が差し引かれた