LDAトピック分類について
- LDA = latent dirichelet allocation (潜在的ディレクトリ配分法)
LDAでは文章中の各単語は隠れたトピック(話題、カテゴリー)に属しており、そのトピックから何らかの確率分布に従って文章が生成されていると仮定して、その所属しているトピックを推測する。
-
論文 http://www.jmlr.org/papers/volume3/blei03a/blei03a.pdf
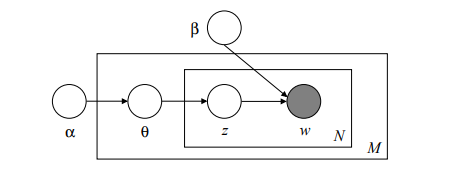
- alpha; :トピックを得るためのパラメーター
- beta; :トピック内の単語を得るためのパラメーター
- theta; :多項分布パラメーター
- w :word(単語)
- z :topic(トピック)
今回はこのLDAを使用して、文章がトピックごとに分類できるかを確認する。
データセット
20 Newsgroupsを使用して検証
- 約20000文書、20カテゴリのデータセット
- カテゴリは以下20種類
comp.graphics
comp.os.ms-windows.misc
comp.sys.ibm.pc.hardware
comp.sys.mac.hardware
comp.windows.x
rec.autos
rec.motorcycles
rec.sport.baseball
rec.sport.hockey
sci.crypt
sci.electronics
sci.med
sci.space
talk.politics.misc
talk.politics.guns
talk.politics.mideast
talk.religion.misc
alt.atheism
misc.forsale
soc.religion.christian
-
今回は以下の4種類を使用
- 'rec.sport.baseball': 野球
- 'rec.sport.hockey': ホッケー
- 'comp.sys.mac.hardware': macコンピュータ
- 'comp.windows.x': windowsコンピュータ
学習
from sklearn.datasets import fetch_20newsgroups
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.decomposition import LatentDirichletAllocation
import mglearn
import numpy as np
# data
categories = ['rec.sport.baseball', 'rec.sport.hockey', \
'comp.sys.mac.hardware', 'comp.windows.x']
twenty_train = fetch_20newsgroups(subset='train',categories=categories, \
shuffle=True, random_state=42)
twenty_test = fetch_20newsgroups(subset='test',categories=categories, \
shuffle=True, random_state=42)
tfidf_vec = TfidfVectorizer(lowercase=True, stop_words='english', \
max_df = 0.1, min_df = 5).fit(twenty_train.data)
X_train = tfidf_vec.transform(twenty_train.data)
X_test = tfidf_vec.transform(twenty_test.data)
feature_names = tfidf_vec.get_feature_names()
# print(feature_names[1000:1050])
# print()
# train
topic_num=4
lda =LatentDirichletAllocation(n_components=topic_num, max_iter=50, \
learning_method='batch', random_state=0, n_jobs=-1)
lda.fit(X_train)
確認の状況を以下で確認
sorting = np.argsort(lda.components_, axis=1)[:, ::-1]
mglearn.tools.print_topics(topics=range(topic_num),
feature_names=np.array(feature_names),
topics_per_chunk=topic_num,
sorting=sorting,n_words=10)
topic 0 topic 1 topic 2 topic 3
-------- -------- -------- --------
nhl window mac wpi
toronto mit apple nada
teams motif drive kth
league uk monitor hcf
player server quadra jhunix
roger windows se jhu
pittsburgh program scsi unm
cmu widget card admiral
runs ac simms liu
fan file centris carina
- topic1 :windowsコンピュータ
- topic2 :macコンピュータ
- topic0: 野球orホッケー、期待通りに分類できず
- topic3: コンピュータ関連?期待通りに分類できず
topic1,topic2は学習段階できれいに分類できたと考えられる。
推論
推論用のデータはwikipediaのappleの英語記事を拝借した。wikipediaの記事の一部をtext11,text12に設定。
text11="an American multinational technology company headquartered in Cupertino, "+ \
"California, that designs, develops, and sells consumer electronics,"+ \
"computer software, and online services."
text12="The company's hardware products include the iPhone smartphone,"+ \
"the iPad tablet computer, the Mac personal computer,"+ \
"the iPod portable media player, the Apple Watch smartwatch,"+ \
"the Apple TV digital media player, and the HomePod smart speaker."
以下で推論を実行
# predict
test1=[text11,text12]
X_test1 = tfidf_vec.transform(test1)
lda_test1 = lda.transform(X_test1)
for i,lda in enumerate(lda_test1):
print("### ",i)
topicid=[i for i, x in enumerate(lda) if x == max(lda)]
print(text11)
print(lda," >>> topic",topicid)
print("")
結果
### 0
an American multinational technology company headquartered in Cupertino, California, that designs, develops, and sells consumer electronics,computer software, and online services.
[0.06391161 0.06149079 0.81545564 0.05914196] >>> topic [2]
### 1
an American multinational technology company headquartered in Cupertino, California, that designs, develops, and sells consumer electronics,computer software, and online services.
[0.34345051 0.05899806 0.54454404 0.05300738] >>> topic [2]
MAC(apple)に関するいずれの文章も、topic2(macコンピュータ)に属する可能性が高いと推論され、正しく分類できたといえる。