はじめに
このシリーズでは Amazon EKSで機械学習を行っていきたいと思います
シリーズ目次
EKSで機械学習 #1 準備編
EKSで機械学習 #2 クラスター作成編
EKSで機械学習 #3 Managed Worker Node作成編
EKSで機械学習 #4 GPU Managed Worker Node作成編(この記事)
この記事の目的
前回作成したのはnon-GPU用のManaged Worker Nodeでしたが、
今回は同じ手順で、GPUを搭載したManaged Worker Nodeを作っていきましょう。
EKSの管理コンソールから、Managed Worker Node を作成する
Worker Node用のIAM roleを作成する
手順はほとんど同じです。Managed Woker Node名は「gpu-managed-1」にするので、前回と同じで
IAM role名が「eks-gpu-managed-1-worker-role」なるものを作ります。
(スクショは省きました)
Managed Worker Node の作成
名前は gpu-managed-1
IAM roleは、先ほど作成した eks-gpu-managed-1-worker-role
ssh keyは、なんでもOK(sshを行う予定はないので)
タグやラベルは特に指定しない。
クラスターの詳細を開いて、「ノードグループを追加」で追加します
計算構成はGPUを使うので変更。ディスクサイズも変更
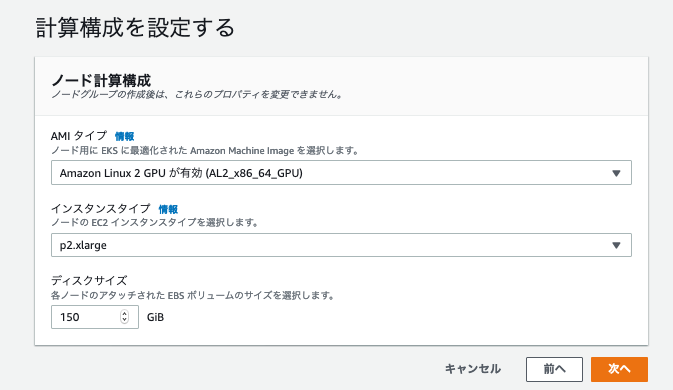
スケーリングの構成は、最小サイズを1, 希望のサイズを1、最大サイズを3に変更
こんな感じで、k get node が表示されたらOK.
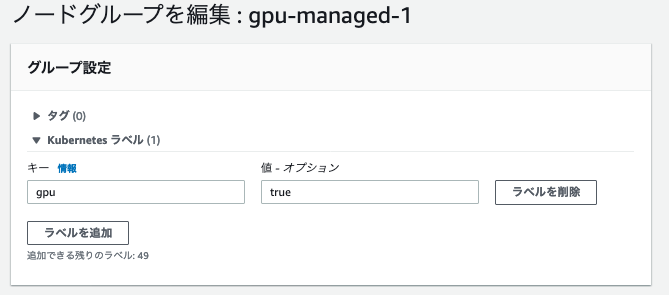
次に、Managed Worker Nodeの設定で、gpu: true をラベルを追加する。
これは、EKSがGPUを認識できるように、nvidiaのdaemonsetを使うけど、そのdaemonsetはGPUノードでのみ動かしたいため。
以下のyamlを実行して、nvidiaのdaemonsetを動かす
https://github.com/NVIDIA/k8s-device-plugin
ここから変更箇所は、nodeselectorの部分を追加。見たときによって、docker imageのバージョンは変わっているかも
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: nvidia-device-plugin-daemonset
namespace: kube-system
spec:
selector:
matchLabels:
name: nvidia-device-plugin-ds
updateStrategy:
type: RollingUpdate
template:
metadata:
# This annotation is deprecated. Kept here for backward compatibility
# See https://kubernetes.io/docs/tasks/administer-cluster/guaranteed-scheduling-critical-addon-pods/
annotations:
scheduler.alpha.kubernetes.io/critical-pod: ""
labels:
name: nvidia-device-plugin-ds
spec:
tolerations:
# This toleration is deprecated. Kept here for backward compatibility
# See https://kubernetes.io/docs/tasks/administer-cluster/guaranteed-scheduling-critical-addon-pods/
- key: CriticalAddonsOnly
operator: Exists
- key: nvidia.com/gpu
operator: Exists
effect: NoSchedule
# Mark this pod as a critical add-on; when enabled, the critical add-on
# scheduler reserves resources for critical add-on pods so that they can
# be rescheduled after a failure.
# See https://kubernetes.io/docs/tasks/administer-cluster/guaranteed-scheduling-critical-addon-pods/
priorityClassName: "system-node-critical"
containers:
- image: nvidia/k8s-device-plugin:1.0.0-beta4
name: nvidia-device-plugin-ctr
securityContext:
allowPrivilegeEscalation: false
capabilities:
drop: ["ALL"]
volumeMounts:
- name: device-plugin
mountPath: /var/lib/kubelet/device-plugins
nodeSelector:
gpu: "true"
volumes:
- name: device-plugin
hostPath:
path: /var/lib/kubelet/device-plugins
k apply -f nvidia-device-plugin.yml
daemonset.apps/nvidia-device-plugin-daemonset created
# nvidia-device-plugin-daemonset がデプロイされたことを確認する
k get pod -A
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system aws-node-b6778 1/1 Running 0 13m
kube-system aws-node-mz9z5 1/1 Running 0 18h
kube-system coredns-84549585c-4zf68 1/1 Running 0 18h
kube-system coredns-84549585c-gmsgg 1/1 Running 0 18h
kube-system kube-proxy-9hnrf 1/1 Running 0 13m
kube-system kube-proxy-qj27l 1/1 Running 0 18h
kube-system nvidia-device-plugin-daemonset-n4v64 1/1 Running 0 11s
動作確認
動作確認用のpodを動かしてみます。以下のymlを用意
apiVersion: v1
kind: Pod
metadata:
name: gpu-pod
spec:
containers:
- name: digits-container
image: nvidia/digits:6.0
resources:
limits:
nvidia.com/gpu: 1 # requesting 1 GPUs
applyして、podがrunningになることを確認します
(image pullにちょっと時間がかかりました)
k apply -f gpu-test.yml
pod/gpu-pod created
k get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
gpu-pod 1/1 Running 0 111s 192.168.153.3 ip-192-168-134-74.us-west-2.compute.internal <none> <none>
これでGPU Managed Worker Nodeの作成は完了です。
最後に後片付け
k delete -f gpu-test.yml
まとめ
今回は、GPUY Managed Worker Nodeの作成を行いました。
次回は、Cluster AutoScalerをセットアップしていきます。