LambdaとRDSで爆死してみる
- 2019/12/05 Update
こちらにRDS Proxyが発表されましたので、この投稿の内容はアンチパターンではなくなる可能性があります。
内容
LambdaとRDSは相性が悪い(というより、一緒に使うべきではない)というのはよく聞く話です。百聞は一見にしかずということで、爆死してみました
- 2019/07/19 Update
こちらに続編を書きました
事前情報
なぜ相性が悪いかはこちらを。
http://keisuke69.hatenablog.jp/entry/2017/06/21/121501
https://qiita.com/teradonburi/items/86400ea82a65699672ad
やってみる(概要)
- s3へのファイルPUTをトリガーにLambdaを起動させ。RDSのテーブルに「バケット名」と「ファイル名(key)」をInsertします
- この検証では、100万ファイルをEC2上に作成して、s3 syncでs3上にコピーすることで大量のLambdaの起動を再現しています
やってみる(流れ)
- RDS作成
- テスト用DBとテーブル作成
- Lambda作成とトリガー作成
- 事前準備
- aws s3 syncで100万ファイルをs3へコピー
- 結果確認
RDS(Aurora Mysql)作成
プライベートサブネット内に作成します。
mysqlでもposgresでもなんでもいいですが、普段使っているAurora Mysqlにしました。
インスタンスタイプはt2.mediumです。
テスト用DBとテーブル作成
DB自体作成してない場合はここで作成します。「demodb」としています。
テーブル名は「test_tb」としていますが、スキーマ定義は適当です。
mysql> CREATE DATABASE demodb;
mysql> USE demodb;
mysql> CREATE TABLE `test_tb`(
`bucket` VARCHAR(128) NOT NULL,
`key` VARCHAR(128) NOT NULL);
Lambda作成とトリガー設定
python2.7で以下の通り書きました。メモリ割り当てはやや大きく、Timeoutは1分にしています。
s3のイベントタイプは後述する「s3-test-qiita」バケット内の「Object Created(All)」としています。
(テスト用のs3バケットを作って、そこへのputをトリガーにLambdaを起動するようにします)
あとは、LambdaをVPC内に起動するように設定。
pymysqlは標準で入っていないので、pipで入れて、パッケージ化しています。
本題とは関係ないですが、cloud9でやるとホント楽。
# -*- coding: utf-8 -*-
import sys
import logging
import pymysql
import json
import boto3
# rds settings
rds_host = "xxxxxx"
name = "xxxx"
password = "xxxxxx"
db_name = "xxxx"
logger = logging.getLogger()
logger.setLevel(logging.INFO)
try:
conn = pymysql.connect(rds_host, user=name, passwd=password, db=db_name, connect_timeout=5)
except:
logger.error("ERROR: Unexpected error: Could not connect to MySql instance.")
sys.exit()
logger.info("SUCCESS: Connection to RDS mysql instance succeeded")
def lambda_handler(event, context):
bucket = event['Records'][0]['s3']['bucket']['name']
key = event['Records'][0]['s3']['object']['key']
with conn.cursor() as cur:
cur.execute('insert test_tb values (%s, %s)', (bucket, key))
conn.commit()
事前準備
s3バケット「s3-test-qiita」作成(作ってない場合は)
Lambdaのトリガーにs3 putを設定(やってない場合は)
EC2に大量のダミーファイル作成。↓で100万のダミーファイルが作れるけど、多すぎ?
$ mkdir s3-test
$ cd s3-test
$ time seq 1 1000000 | xargs touch
EC2からs3 syncの実行
ファイルサイズが小さいのと並列で実行してないので、毎秒200PUT程度となっており、
Lambdaが毎秒200起動される感じです。
$ cd ../
$ aws s3 sync s3-test/ s3://s3-test-qiita/files/
upload: s3-test/10279 to s3://s3-test-qiita/files/10279
upload: s3-test/102792 to s3://s3-test-qiita/files/102792
upload: s3-test/102793 to s3://s3-test-qiita/files/102793
upload: s3-test/102791 to s3://s3-test-qiita/files/102791
upload: s3-test/102794 to s3://s3-test-qiita/files/102794
RDSの状態の確認
cloudwatchでLambdaのエラー数が急上昇し、cloudwatch logsでも、「Could not connect to MySql instance」というのが頻発していますね。
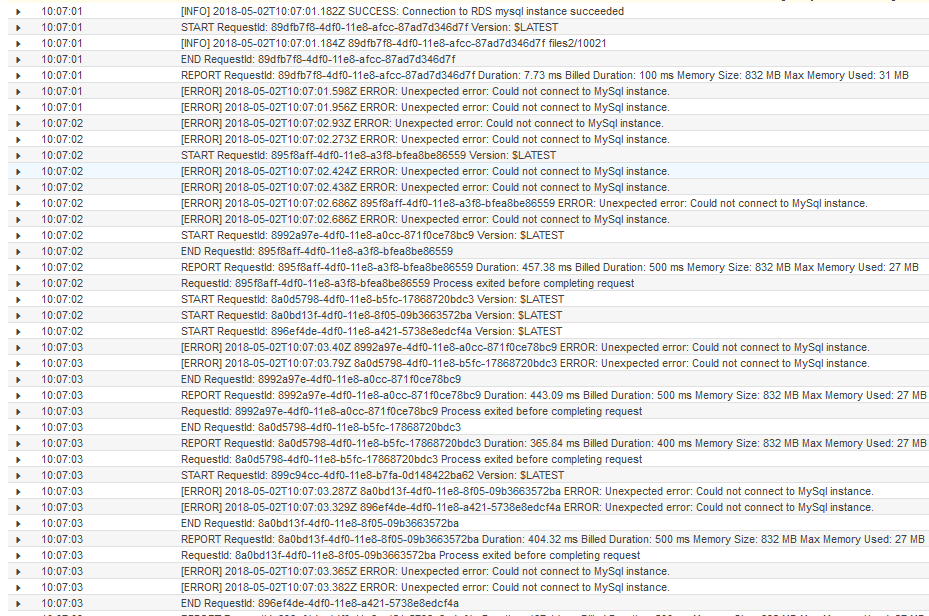
以下のエラーで、Aurora自体にも接続できなくなりました。clouewatchから見るに、だいたい45コネクション張っているようです。
インスタンスのスペックを上げれば、もう少し耐えれるかと思いますが、時限爆弾が爆発するまでの時間が少し延びだけに過ぎない、そもそもLambda + RDSはやめたほうがいいです。
ERROR 1040 (08004): Too many connections
よくある疑問
Q. 上記の場合だとLambdaの同時実行数が40くらいなるように、ハードリミットかければいいだけじゃないのですか?
A. 確かにそうですが、上記の例だとs3へのPUTをトリガーにしています。どうやってs3のPUTへハードリミットをかけますか?そもそもLambdaの同時実行数を数え切れるくらいに制限するなんてクラウドネイティブなアーキテクチャじゃないです。あと、API Gateway -> Lambda -> RDSもよくあるダメパターンですね。同じことが言えます。API Gatewayは、10,000TPS捌けるのにそれをLambda + RDSを使いたいがために数十TPSに制限するなんて。。あと、API Gatewayは30秒でタイムアウトするのに、LambdaをVPC内で起動するとColdStartで15秒くらいかかってしまうのもユーザビリティが低下する原因の1つです。軽い処理なはずなのに、API Gatewayにリクエストを送って、200が返ってくるのに、16秒かかる(うち、15秒はcold start)なんてザラです。
Q. Kinesis data streams + Lambda + RDSならOKですか?
A. Kinesus data streamなら、Lambdaの起動数 = シャードの数です。1シャードあたり、1000TPS処理できるので、10 シャード = 10 Lambdaで、10,000TPS処理できます。10 LambdaくらいならRDSへの負荷はそれほど多くないと思いますが、それでもやはり検証は必要です。でも、おすすめは、やはりKCL on EC2 or ECS.
Q. どの程度のLambda同時実行数ならRDSを使ってもOKでしょうか?
A. 基本的には使わないがいいですし、同時実行数を制限する方法やそれをモニタリングする方法を考えるのに使う時間があれば、素直にEC2/ECSでやったほうがいいですし、よりスケーラブルになると思います。