Pytorchなら同じGPUで2倍早い学習ができるっていったんだよ!

DNNを学習・推論するにはGPUはほぼ必須ですが高いですよね。。
できるだけ安いGPUでも早く学習が終わると助かりますが近年のDNNは巨大化する一方。。
そこでFP16などの技術で高速化すると同じGPUでも2倍早く学習が終わります!
このような技術を使うことで2倍性能のいいGPUを使うのと同義になるのでお財布に優しいですね。。もちろん仕事で使う場合はコストが下がるのでありがたいです。
できらぁ!と言ってしまったので頑張っていきましょう。
(追記:実験では主にRTX2080tiを使用しました。)
tldr;
Pytorchのモデル、tensorをFP16化することで学習と推論を高速化。
またnvidia社のapexライブラリでもかんたんにFP16化。
推論高速化ツールのTensorRTも試し、推論を高速化。
CIFAR10と物体検出でベンチマーク。
- 画像認識では2倍高速化できました。
- 推論に限ればTensorRTでは4~10倍くらい高速化できました。しかしデバッグ大変です。
- 物体検出は高速化できませんでしたが、メモリ使用量を半分にできるのはありがたいです。
FP16ってなんだっけ
昔の記事でも触れましたが、FP16の復習です。
ほぼコピペしちゃいますが。。
コンピュータ内の数字の表現
FP16とは俗にいう”半精度”と呼ばれる浮動小数点における数字の表現方法です。
コンピュータの内部では数字は2進数で保存されており、例えば"3"という数字は:
0011 # 0*8+0*4+1*2+1*1 = 3
といった形で保存されています。
これは一般的な4bitの整数表現(4bit Int)という形ですね。
このビット数を増やしていくと表現できる整数が広がっていきます。
floatって?
それでは負や小数などを表現するためにどうしたら良いのでしょうか。
一般的に使われるのが浮動小数点(float)と呼ばれる方式です。
例えばオレオレ7bit表現で上位3bitが小数(exponent)、下位4bitが整数(mantissa)のような表現を考えてみましょう。
011+0011 # 1e-3*(0*8+0*4+1*2+1*1) = 0.003
と小数を表現できました。この6bit表現でも1e-7~0.7まで表現できダイナミックレンジはとても広いです。
DNNの学習では小さい微分結果をネットワークに伝搬させる必要があるためfloatの対応は必須です。推論ではそこそこ整数表現だけでも上手くいきます。
最後にMSBに正負を見分けるビットをつければ-1e-7~0.7まで表現できる8bitなんちゃってfloatの出来上がりです。
1(正)+011(小数)+0011(正数) # +1e-3*(0*8+0*4+1*2+1*1) = 0.003
fp16やbfloat16って?
最初の話に戻りますが5bの小数+10bitの整数を備えた表現方法がFP16です。
Half-precision IEEE floating pointとも言われ、ちゃんと規格化されています。

一方でDNNの学習にはExponentは重要なものの、整数の表現幅はあまり寄与しません。
そこでgoogleなどはbfloat16というexpoentを3bit増やした表現をTPUに取り入れております。
従来のFP16よりも安定して(FP32に近い挙動で)学習が行われるらしいです。
nVidiaGPUにも対応が待たれますね。。
FP16学習はDNNにどう関係するの?
-
メモリの節約
まずDNN学習時はGPUメモリ上にactivationやweightを保存し無くてはなりません。
FP32方式でそれらのパラメータを保存するよりも、FP16で保存することで必要なメモリ量を半分にへらすことが出来ます。 -
演算の高速化
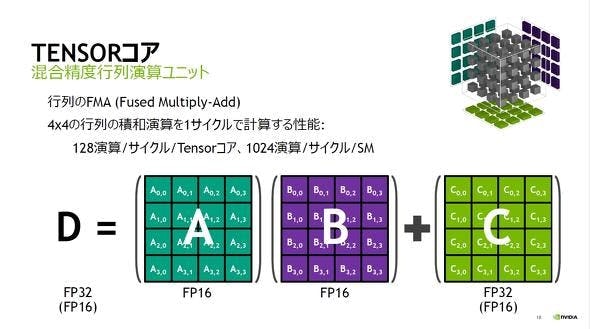
次世代GPUはFP16を使うと演算速度が大幅に向上するTensorCoreが搭載されてます(専用回路みたいなものです)。
そのためFP16で学習することでFP32時に対し数十倍の演算速度向上が期待できます!
ただDNN動作は普通はメモリ律速(データの移動が一番時間を食う)のでTensorCoreによる速度向上の恩恵が見られるのはほとんどないと思います。FP16化でメモリ量が半分になり、データ通信時間も半分になることで学習速度が2倍早くなるのが期待値だと思って良いと思います。
Pytorchの学習でFP16を使う
本題のFP16を使ったPytorch学習に入りましょう。
- 追記 2020/11月
下記の方法は古く、現在はPytorch>=1.6で低精度学習の方法は変わってます。
を見て下さい。
1)入力、重みテンソルを手動でFP16化
1つ目のアプローチは手動でネットワークに流れるテンソルをFP16化(.half())にすることです。
pytorchでは作成したtensorはデフォルトでは32FP(float)だが、.half()と渡すことでかんたんにFP16化することができます。
hoge = torch.randn([100,100])
hoge.type() #torch.FloatTensor
hoge_fp16 = hoge.half() # FP16化
hoge_fp16().type() # torch.HalfTensor
FastAIのrepoを参考にネットワークをhalf化する関数を作ります。
class tofp16(nn.Module):
def __init__(self):
super(tofp16, self).__init__()
def forward(self, input):
return input.half()
def copy_in_params(net, params):
net_params = list(net.parameters())
for i in range(len(params)):
net_params[i].data.copy_(params[i].data)
def set_grad(params, params_with_grad):
for param, param_w_grad in zip(params, params_with_grad):
if param.grad is None:
param.grad = torch.nn.Parameter(param.data.new().resize_(*param.data.size()))
param.grad.data.copy_(param_w_grad.grad.data)
def BN_convert_float(module):
# BatchNormのみFP32フォーマットにしないと性能が出ない。
# BatchNormレイヤを検索し、このレイヤのみFP32に設定。
'''
BatchNorm layers to have parameters in single precision.
Find all layers and convert them back to float. This can't
be done with built in .apply as that function will apply
fn to all modules, parameters, and buffers. Thus we wouldn't
be able to guard the float conversion based on the module type.
'''
if isinstance(module, torch.nn.modules.batchnorm._BatchNorm):
module.float()
for child in module.children():
BN_convert_float(child)
return module
def network_to_half(network):
return nn.Sequential(tofp16(), BN_convert_float(network.half()))
とnetwork_to_halfのような関数が作れる。
学習の安定化のため、batchnormだけは32bitで行うのが味噌です。
2)ライブラリ(nvidia apex, amp)を使ったFP16化
nvidiaがpytorchで利用できるFP16用ライブラリのapexを使用するのが流行っているらしい。
インストール方法
gitcloneしてインストールするかpipでインストールできます。
$ git clone https://github.com/NVIDIA/apex
$ cd apex
$ pip install -v --no-cache-dir --global-option="--cpp_ext" --global-option="--cuda_ext" ./
or
pip install -v --no-cache-dir ./
CUDAとcppを使用したインストールの方が使用できる機能が多く、高速化が期待できるようです。
単にFP16化を試してみたいのならばpipで良いと思います。
使用方法
このライブラリは既存モデルに3行追加するだけでFP16化することができます。
基本的にはmodelとoptimizerを学習前にampでwrapします。
from apex import amp, optimizers
# Initialization
opt_level = 'O1'
model, optimizer = amp.initialize(model, optimizer, opt_level=opt_level)
そして学習時の勾配計算時に、
# Train your model
with amp.scale_loss(loss, optimizer) as scaled_loss:
scaled_loss.backward()
と記述を足すだけでオッケーです!
ね、かんたんでしょ?
opt_level="O1"としておくと、batch_normもFP32に設定してくれます。
手動で設定したい場合は、
model, optimizer = amp.initialize(model, optimizer,
opt_level=args.opt_level,
keep_batchnorm_fp32=True)
と渡せばいいみたいです。
example.pyにImagenetの例があるので、それをみて感覚をつかめばいいかなと思います。
おまけ)TensorRTを使用したJetson Nanoの推論高速化
ちょっと毛色の違う話ですが、推論の高速化についても触れます。
この実験で使ったデバイスはJetsonNanoです。一万円で買えるデバイスにも関わらずPytorchが走ります。特にメモリ周りは弱いのでFP16化によって大きな速度向上が生まれます。
CIFAR10データを推論するResnet18の推論速度はFP16化により4倍高速化できました。
またPytorchとはちょっと違うのですが、TensorRTというnvidia製のコンパイルツールを使うことでデバイスにフィットしたバイナリを作成し高速化できます。
ただpytorchモデルをONNX形式にエキスポートし、TensorRTで読むというツールチェインになるので複雑なモデルでコンパイルを通すのは至難の業です。ONNXはエラーの温床で趣味でやることではないです。。
FP16化は圧倒的に少ない労力でできるため、まずはそちらを試すのを勧めます。
SSDをTensorRT化しようかと思いましたが、挫折しました.
ONNX→TensorRT化はかなりキツイため、個人で試したいならばtorch2trtというコンバータを使うことをおすすめします。画像処理系モデルならサンプルを見ながらモデルを組めばコンパイル通せます(ちょっと違う事しようとするとハマりますが..)。
このツールはONNXを介さないため、精神衛生上良いです :)
Resnet18 inference @JetsonNano
| model type | FPS |
|---|---|
| FP32 pytorch | 314 |
| FP16 pytorch | 1208 (4x) |
| FP16 TensorRT | 4716 (16x) |
TensorRT、生のPytorch推論と比べ16倍も早くなるため速度的には圧倒的ですね。たまたま3x3convの多いresnet18がスイートスポットだった気もします。
(追記)
Xavierを使った画像認識モデルとセグメンテーションモデルのINT8量子化推論もできました。最大で10倍ほど高速化することができました。
https://github.com/kentaroy47/benchmark-FP32-FP16-INT8-with-TensorRT
にハードウェアセットアップ方法や結果をまとめています。
高速化実験
CIFAR10(画像認識モデル)
CIFAR10の学習高速化は前記事でやりましたが結果がわかりやすいので再掲。
1)の入力、重みテンソルを手動でFP16化でやってみました
| Model | second/epoch | speedup? |
|---|---|---|
| Resnet18@FP32 | 15 | - |
| Resnet18@FP16 | 8 | 87% |
| Resnet50@FP32 | 58 | - |
| Resnet50@FP16 | 27 | 114% |
約2倍高速化しました。CIFAR10ではvalidation精度もほとんど変わらなかったのでデメリットも見えません。
画像認識は素直に高速化できるのでオススメです。
EfficientDetとRetinaNet(物体認識モデル)
ちょうど趣味で学習しているEfficientDetがクソ遅いのでFP16化して高速化してみましょう。
1)の入力、重みテンソルを手動でFP16化でやってみました
batchは32 imagesで実験。
物体検出はロス計算が煩雑なのでFP16化はメンドイですががんばります。。
Input resolution:300
| Model | second/10 iter | メモリ使用量 | speedup? |
|---|---|---|---|
| EfficientDetD0@FP32 | 3.2 | 7200MB | - |
| EfficientDetD0@FP16 | 6.5 | 4511MB | -100%.. |
| RetinaNet(Resnet18)@FP32 | 1.9 | 5000MB | - |
| RetinaNet(Resnet18)@FP16 | 2.3 | 2500MB | -18% |
FP16にすると逆に遅くなるという結果になりました(爆)
メモリ使用量は半分になっているのでその点は利点ありますね。
EfficientDetは変なレイヤ(DepthWiseConv)など多く、Resnet系よりもGPU効率が低いのがあるのではないかと思っています。ResnetバックボーンのRetinaNetではFP16にしても速度はあまり変わらなかったです。
2)のapexでFP16化をやってみました
Input resolution:300
| Model | second/10 iter | メモリ使用量 | speedup? |
|---|---|---|---|
| EfficientDetD0@FP32 | 3.2 | 7200MB | - |
| EfficientDetD0@FP16 | 3.6 | 4615MB | -10% |
| RetinaNet(Resnet18)@FP32 | 1.9 | 5000MB | - |
| RetinaNet(Resnet18)@FP16 | 2.1 | 2427MB | -18% |
ライブラリがしっかりしているのでFP16化時の速度もかなり良くなりました。
ただマシにはなりましたが速度改善はあまり得られず。。
Input resolution:512
| Model | second/10 iter | メモリ使用量 | speedup? |
|---|---|---|---|
| EfficientDetD0@FP32 | 6.2 | 10000MB*2 | - |
| EfficientDetD0@FP16 | 5.5 | 11200MB | 12% |
| RetinaNet(Resnet18)@FP32 | 1.9 | 5000MB | - |
| RetinaNet(Resnet18)@FP16 | 2.1 | 2427MB | -18% |
お、入力解像度を増やすと速度改善が見られました!(10%ですけど。。)
FP32ではメモリが入り切らなかったため、バッチ数を減らしておりそれが影響したのかも。
肝心の精度どうなん?というところはしばしお待ちを..
え、Pytorchで同じGPUで2倍早い学習を?(まとめ)

- **PytorchのFP16化は手軽でリターンも大きい。**メモリが入り切らないときはみんなやろう! :)
- **画像認識モデルでは学習速度を手軽に2倍高速化できる。**メモリ使用量も半減。
- 物体検出モデルは速度改善できませんでした :(。許してヒヤシンス。でもメモリ使用量を半減できるのは大きなメリット。
- TensorRTはめちゃはや。10倍くらいまで早くなるかも。でもデバッグ大変なので自作モデルを手軽に高速化する用途には向かず、リソースがかけられる業務用だと思う。
- PytorchカレンダーだからPytorch押しだけどTensorFlowでも同じような事はできる(笑)
物体検出で高速化のメリットが小さい原因究明には時間がかかりそうです。
Issueにも上がっている通りnvidia GPU、apexにおける物体検出における高速化はまだon goingなのかもしれません。