概要
例えば、こういった観測値があったとします。
# --- ライブラリパッケージ読み込み ---
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
plt.rcParams['font.family'] = 'Yu Mincho'
# --- データ作成 ---
n = 40 # データサイズ
ndX = np.linspace(0.0, 4, n) # X
ndY = 0.5*ndX + np.random.normal(0,0.1, n) # Yのトレンド部分
# Yの変動部分
ndY[5:13] += 1 # 5~13を上に1ずらす
ndY[25:35] -= 3 # 25~35を下に3ずらす
# Yの外れ値
ndY[5] = -2
ndY[10] = 10
# --- グラフ表示 ---
fig = plt.figure(facecolor='w', figsize=(8,4))
ax = fig.add_subplot(111)
ax.plot(ndX, ndY, marker='o')
ax.set(ylim=(-3,11.))
plt.show()
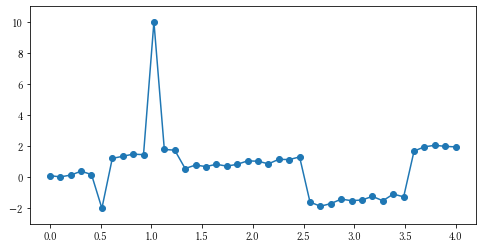
ここに、ベースラインを引くのはどうしたらいいでしょうか。
単に回帰直線を計算させると、
# 回帰分析によるトレンド線描画
res1 = np.polyfit(ndX, ndY, 1) # 直線(1次)の回帰
ndF = np.poly1d(res1)(ndX) # a * ndX + b
# グラフ表示
fig = plt.figure(facecolor='w', figsize=(8,4))
ax = fig.add_subplot(111)
ax.plot(ndX, ndY, marker='o')
ax.plot(ndX, ndF, color='orange')
ax.set(ylim=(-3,11))
plt.show()
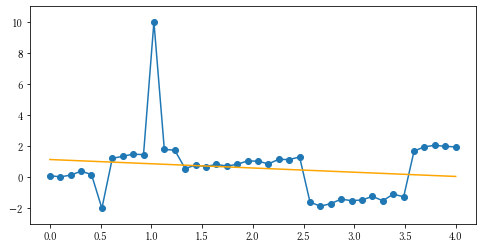
となってしまいます。
そんなときに役立つコードをつくったのでご紹介します。
コード(前半)
まず、ベースラインに該当する点を選び出す必要があります。
調べると画像の上の直線を求める方法として「ハフ法」というものがありました。
同じ色の点の座標を2点ずつ抜き出して切片と傾きを計算し、
その組み合わせが一番多いものを直線として採用するという方法です。
というわけで、切片と傾きを10倍して整数部だけ取り出し、組み合わせて文字列にしました。
この文字列の投票で獲得票数が一番多いものを「ベースライン付近の直線」として採用することにします。
# --- ハフ法っぽいやり方で、切片と傾きを求める ---
L = 1 # 精度(小数点以下の有効桁数)
N = len(ndX) # サイズの把握
cols = ['a','b', 'x0','y0', 'x1','y1'] # 列名
dfPair = pd.DataFrame(np.zeros([N*(N-1)//2, len(cols)]), columns=cols) # 記録用
k = 0 # カウンタ
# 全ての2点の組み合わせについて、切片と傾きを計算
for i in range(len(ndX)-1):
# 1点目
x0 = ndX[i]
y0 = ndY[i]
for j in range(i+1, len(ndX)):
# 2点目
x1 = ndX[j]
y1 = ndY[j]
# 計算
a = (y1-y0)/(x1-x0) # 傾き
b = y0 - a*x0 # 切片
# 記録
dfPair.loc[k,:] = {'x0':x0, 'y0':y0, 'x1':x1, 'y1':y1, 'a':a, 'b':b}
k += 1 # カウントアップ
# --- 切片と傾きを組み合わせて文字列にする ---
R = 10**L
dfPair['combo'] = (dfPair['a']*R).astype('int16').astype('str') + \
'_' + (dfPair['b']*R).astype('int16').astype('str')
# 切片と傾きの組み合わせの文字列で、最も多いものを選ぶ
dicCombo = dfPair['combo'].value_counts().to_dict()
topCombo = list(dicCombo.keys())[0]
a,b = [int(x)/R for x in topCombo.split('_')]
# 計算に採用した線の切片と傾きとその獲得票数
print('切片と傾き:',(a,b) , '、 獲得票数:', dicCombo[topCombo])
コード(後半)
さて、前半で求めた「切片と傾き」は四捨五入で丸めたざっくりしたものです。
そこで、勝った「切片と傾き」に投票したペアの点たちに注目します。
彼らは真の「切片と傾き」からなる直線の、すぐそばにいる点のはずです。
そこで、その座標を取り出し、重複を除去して、これらだけで回帰直線を計算します。
# 線に使われた点を抜き出す
dfPoint0 = dfPair.loc[dfPair['combo'] == topCombo, ['x0','y0']]
dfPoint0.columns = ['x','y'] # 1点目の座標
dfPoint1 = dfPair.loc[dfPair['combo'] == topCombo, ['x1','y1']]
dfPoint1.columns = ['x','y'] # 2点目の座標
dfPoint = pd.concat([dfPoint0,dfPoint1]) # 1点目と2点目の座標を縦につなげる
dfPoint.drop_duplicates(inplace=True) # 重複除去
# 回帰分析によるトレンド線描画
res2 = np.polyfit(dfPoint.x, dfPoint.y, 1) # 直線(1次)の回帰
ndF2 = np.poly1d(res2)(dfPoint.x.values) # a * ndX + b
# グラフ表示
fig = plt.figure(facecolor='w', figsize=(8,4))
ax = fig.add_subplot(111)
ax.plot(ndX, ndY, marker='o')
ax.plot(ndX2, ndF2, color='orange')
ax.set(ylim=(-2.5,3.5))
plt.show()
print('切片と傾き:', res2, '、 使用した点の数:',dfPoint.shape[0])
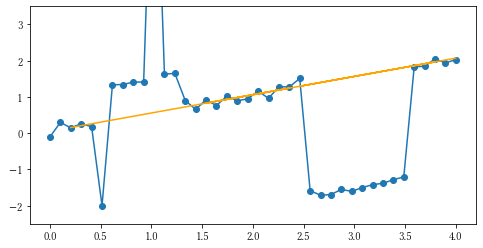
ご覧の通り、ベースラインを引くことができました。
付記
え、「なんだか強引だ」ですか。
そうですね。
ハフ法で直線を引くのは洗練されたライブラリがあるでしょうし、ベースライン付近の点を抽出するのは、多次元空間に投影してクラスタリングした方が正確かと思います。
しかし、pandasやnumpyというありものでお手軽に計算できるという利点はあるかと思います。
では、また。