Section1:強化学習
強化学習とは
- 長期的に報酬を最大化できるように環境のなかで行動を選択できるエージェントを作ることを目標とする機械学習の一分野
- 行動の結果として与えられる利益(報酬)をもとに、行動を決定する原理を改善していく仕組み
強化学習のイメージ

強化学習の応用例
マーケティングの場合
- 環境
- 会社の販売促進部
- エージェント
- プロフィールと購入履歴に基づいて、キャンペーンメールを送る顧客を決めるソフトウェア
- 行動
- 顧客ごとに送信、非送信のふたつの行動を選ぶ
- 報酬
- キャンペーンのコストという負の報酬とキャンペーンで生み出されると推測される売上という正の報酬を受ける
探索と利用のトレードオフ
例1
- 環境について事前に完璧な知識があれば、最適な行動を予測し決定することは可能
- どのような顧客にキャンペーンメールを送信すると、どのような行動を行うのかが既知である状況
- 強化学習の場合、上記仮定は成り立たないとする。不完全な知識を元に行動しながら、データを収集。最適な行動を見つけていく
例2
- 過去のデータで、ベストとされる行動のみを常に取り続ければ他にもっとベストな行動を見つけることはできない
- 探索が足りない状態
- 未知の行動のみを常に取り続ければ、過去の経験が活かせない
- 利用が足りない状態
上記2つはトレードオフの関係性
強化学習の差分
- 強化学習と通常の教師あり、教師なし学習とは目標が違う
- 教師なし/あり学習では、データに含まれるパターンを見つけ出すおよびそのデータから予測することが目標
- 強化学習では、優れた方策を見つけることが目標
価値関数
- 価値を表す関数としては、状態価値関数と行動価値関数の2種類がある
- ある状態の価値に注目する場合
- 状態価値関数
- 状態価値を組み合わせた価値に注目する場合は
- 行動価値関数
- ある状態の価値に注目する場合
方策関数
- 方策ベースの強化学習手法において、ある状態でどのような行動を採るのかの確率を与える関数のこと
方策勾配法
- デル化して最適化する手法
\theta^{(t+1)} = \theta^{(t)} + \epsilon \nabla J(\theta)
-
$J$は方策の良さを表す
- 定義する必要がある
-
定義方法は2つある
- 平均報酬
- 割引報酬和
-
上記の定義に対応して、行動価値関数$Q(s,a)$の定義を行い。方策勾配定理が成り立つ

参考
強化学習 (Reinforcement Learning) とは、機械学習の一種であり、コンピューター エージェントが動的環境と、繰り返し試行錯誤のやりとりを重ねることによってタスクを実行できるようになる手法です。この学習手法により、エージェントは、タスクの報酬を最大化する一連の意思決定を行うことができます。人間が介入したり、タスクを達成するために明示的にプログラムしたりする必要はありません
Section2:AlphaGo
PolicyNet(方策関数)
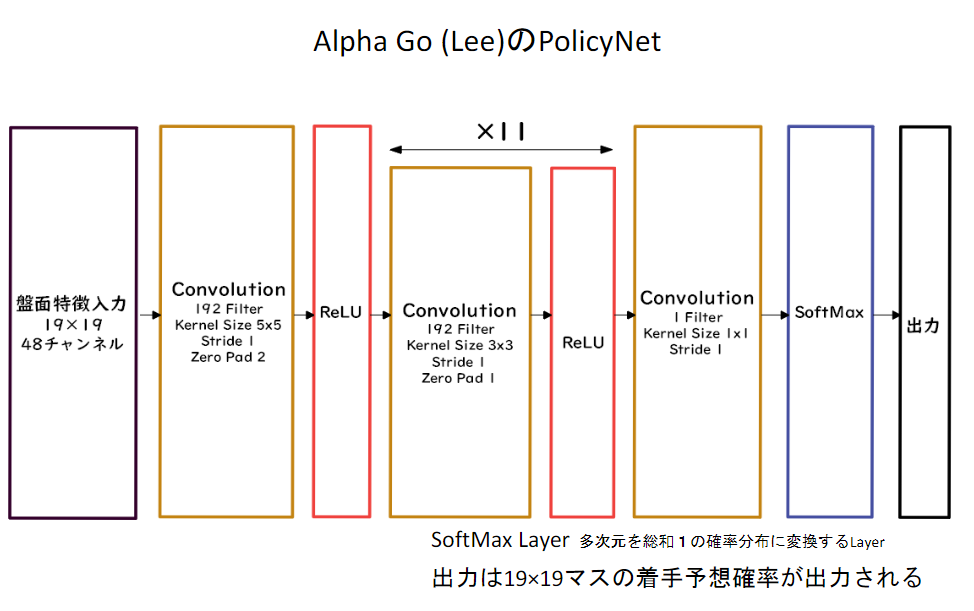
ValueNet(価値関数)

Alpha Go の学習
1. 教師あり学習によるRollOutPolicyとPolicyNetの学習
- KGS Go Server(ネット囲碁対局サイト)の棋譜データから3000万局面分の教師を用意し、教師と同じ着手を予測できるよう学習を行った。* * 具体的には、教師が着手した手を1とし残りを0とした19×19次元の配列を教師とし、それを分類問題として学習した。
- この学習で作成したPolicyNetは57%ほどの精度である。
2. 強化学習によるPolicyNetの学習
- 現状のPolicyNetとPolicyPoolからランダムに選択されたPolicyNetと対局シミュレーションを行い、その結果を用いて方策勾配法で学習を行った。
- PolicyPoolとは、PolicyNetの強化学習の過程を500Iteraionごとに記録し保存しておいたものである。
- 現状のPolicyNet同士の対局ではなく、PolicyPoolに保存されているものとの対局を使用する理由は、対局に幅を持たせて過学習を防ごうというのが主である。
- この学習をminibatch size 128で1万回行った。
3. 強化学習によるValueNetの学習
- PolicyNetを使用して対局シミュレーションを行い、その結果の勝敗を教師として学習した。
- 教師データ作成の手順は
- まずSL PolicyNet(教師あり学習で作成したPolicyNet)でN手まで打つ
- N+1手目の手をランダムに選択し、その手で進めた局面をS(N+1)とする
- S(N+1)からRLPolicyNet(強化学習で作成したPolicyNet)で終局まで打ち、その勝敗報酬をRとする。
- S(N+1)とRを教師データ対とし、損失関数を平均二乗誤差とし、回帰問題として学習した。
- この学習をminibatch size 32で5000万回行ったN手までとN+1手からのPolicyNetを別々にしてある理由は、過学習を防ぐためであると論文では説明されている
モンテカルロ木探索
- コンピュータ囲碁ソフトでは現在もっとも有効とされている探索法
- 他のボードゲームではminmax探索やその派生形のαβ探索を使うことが多いが、盤面の価値や勝率予想値が必要となる
- しかし囲碁では盤面の価値や勝率予想値を出すのが困難であるとされてきた
- そこで!盤面評価値に頼らず末端評価値、つまり勝敗のみを使って探索を行うことができないか、という発想で生まれた探索法
- 囲碁の場合、他のボードゲームと違い最大手数はマスの数でほぼ限定されるため、末端局面に到達しやすい
- 具体的には、現局面から末端局面までPlayOutと呼ばれるランダムシミュレーションを多数回行い、その勝敗を集計して着手の優劣を決定する
- また、該当手のシミュレーション回数が一定数を超えたら、その手を着手したあとの局面をシミュレーション開始局面とするよう、探索木を成長させる
- この探索木の成長を行うというのがモンテカルロ木探索の優れているところである
- モンテカルロ木探索はこの木の成長を行うことによって、一定条件下において探索結果は最善手を返すということが理論的に証明されている。
Alpha Go (Lee) のモンテカルロ木探索
- Alpha Goのモンテカルロ木探索は選択、評価、バックアップ、成長という4つのステップで構成される

- 選択
- Root局面にて着手選択方策$\pi = Q(s,a+cP(s,a) \frac{\sqrt{\sum_b N(s,b)}}{1+N(s,a)} )$に従って手を選択する
- cは定数、$P(s,a)$はPolicyNetによる選択確率、$N(s,a)$はその手が探索中に選ばれた数、$ΣN(s,b)$は現局面の全合法手が選ばれた数の合計である
- $Q(s,a)$が現状の勝敗期待値$cP(s,a) \frac{\sqrt{\sum_b N(s,b)}}{1+N(s,a)}$がバイアス項となり、基本的には勝敗期待値のより高い手を選択するが、選択数が少ない手には高いバイアスがかかり、選択されやすくなる
- また、従来のモンテカルロ木探索では$P(s,a)$がバイアス項にそもそもないものや、人間が手作業で作ったヒューリスティックな方策評価が使われていたが、これにPolicyNetを使用するとしたのがAlphaGoの特徴のひとつである。
- この選択、着手をLeafノードに到達するまで行う。
- 評価
- 着手選択方策によって選ばれた手で進めた局面saがLeafノードであればその局面saをValueNetで評価する
- また、局面saを開始局面とした末端局面までのシミレーションを行い、勝敗値を出す。
- このときのシミレーション時にはRollOut方策を使用する
- バックアップ
- 評価フェイズで評価した値を積算
- 局面saでのValueNetの評価の積算値$Wv$、RollOutでの勝敗値での積算値$Wr$が積算され、$N(s,a)$と$ΣN(s,b)$が1加算
- それらの値から勝敗期待値が再計算される
- これをRoot局面までさかのぼって更新する。
- $Q(s,a) =(1-\lambda \frac{Wv}{N(s,a)} + \lambda \frac{Wr}{N(s,a)}) $とし、$λ$は$0≦λ≦1の$定数である
- AlphaGoLeeでは0.5が使用されている
- 成長
- 選択、評価、バックアップを繰り返し一定回数選択された手があったら、その手で進めた局面の合法手ノードを展開し、探索木を成長させる
AlphaGo(Lee) とAlphaGoZeroの違い
- 教師あり学習を一切行わず、強化学習のみで作成
- 特徴入力からヒューリスティックな要素を排除し、石の配置のみにした
- PolicyNetとValueNetを1つのネットワークに統合した
- Residual Net(後述)を導入した5、モンテカルロ木探索からRollOutシミュレーションをなくした
AlphaGo ZeroのPolicyValueNet

Residual Network
- ネットワークにショートカット構造を追加して、勾配の爆発、消失を抑える効果を狙ったもの
- Residula Networkを使うことにより、100層を超えるネットワークでの安定した学習が可能となった
- 基本構造はConvolution→BatchNorm→ReLU→Convolution→BatchNorm→Add→ReLUのBlockを1単位にして積み重ねる形となる
- また、Resisual Networkを使うことにより層数の違うNetworkのアンサンブル効果が得られているという説もある
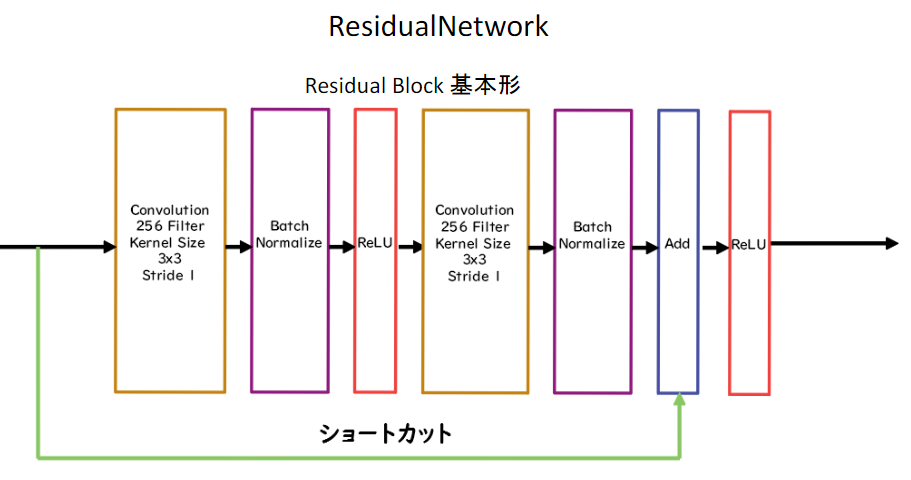
Residual Blockの工夫
Bottleneck
- 1×1KernelのConvolutionを利用し、1層目で次元削減を行って3層目で次元を復元する3層構造にし、2層のものと比べて計算量はほぼ同じだが1層増やせるメリットがある、としたもの
PreActivation
- ResidualBlockの並びをBatchNorm→ReLU→Convolution→BatchNorm→ReLU→Convolution→Addとすることにより性能が上昇したとするもの
Network構造の工夫
WideResNet
- ConvolutionのFilter数をk倍にしたResNet。1倍→k倍xブロック→2*k倍yブロックと段階的に幅を増やしていくのが一般的。Filter数を増やすことにより、浅い層数でも深い層数のものと同等以上の精度となり、またGPUをより効率的に使用できるため学習も早い
PyramidNet
- WideResNetで幅が広がった直後の層に過度の負担がかかり精度を落とす原因となっているとし、段階的にではなく、各層でFilter数を増やしていくResNet
Alpha Go Zeroの学習法
自己対局による教師データの作成、学習、ネットワークの更新の3ステップで構成される
自己対局による教師データの作成
- 現状のネットワークでモンテカルロ木探索を用いて自己対局を行う。
- まず30手までランダムで打ち、そこから探索を行い勝敗を決定する。
- 自己対局中の各局面での着手選択確率分布と勝敗を記録する。
- 教師データの形は(局面、着手選択確率分布、勝敗)が1セットとなる。
学習
- 自己対局で作成した教師データを使い学習を行う。
- NetworkのPolicy部分の教師に着手選択確率分布を用い、Value部分の教師に勝敗を用いる。
- 損失関数はPolicy部分はCrossEntropy、Value部分は平均二乗誤差
ネットワークの更新
- 学習後、現状のネットワークと学習後のネットワークとで対局テストを行い、学習後のネットワークの勝率が高かった場合、学習後のネットワークを現状のネットワークとする
参考
Section3:軽量化・高速化技術
分散深層学習
- 深層学習は多くのデータを使用したり、パラメータ調整のために多くの時間を使用したりするため、高速な計算が求められる。
- 複数の計算資源(ワーカー)を使用し、並列的にニューラルネットを構成することで、効率の良い学習を行いたい。
- データ並列化、モデル並列化、GPUによる高速技術は不可欠である。
データ並列
- 親モデルを各ワーカーに子モデルとしてコピー
- データを分割し、各ワーカーごとに計算させる

同期化
- データ並列化は各モデルのパラメータの合わせ方で、同期型か非同期型か決まる

- 同期型のパラメータ更新の流れ
- 各ワーカーが計算が終わるのを待ち、全ワーカーの勾配が出たところで勾配の平均を計算し、親モデルのパラメータを更新する
非同期型

- 非同期型のパラメータ更新の流れ
- 各ワーカーはお互いの計算を待たず、各子モデルごとに更新を行う。
- 学習が終わった子モデルはパラメータサーバにPushされる。
- 新たに学習を始める時は、パラメータサーバからPopしたモデルに対して学習していく。
同期型と非同期型の比較
- 処理のスピードは、お互いのワーカーの計算を待たない非同期型の方が早い。
- 非同期型は最新のモデルのパラメータを利用できないので、学習が不安定になりやすい。
- Stale Gradient Problem
- 現在は同期型の方が精度が良いことが多いので、主流となっている
モデル並列
- 親モデルを各ワーカーに分割し、それぞれのモデルを学習させる。全てのデータで学習が終わった後で、一つのモデルに復元。
- モデルが大きい時はモデル並列化を、データが大きい時はデータ並列化をすると良い

- モデルのパラメータ数が多いほど、スピードアップの効率も向上する

GPU
GPGPU
- 元々の使用目的であるグラフィック以外の用途で使用されるGPUの総称
CPU
- 高性能なコアが少数
- 複雑で連続的な処理が得意
GPU
- 比較的低性能なコアが多数
- 簡単な並列処理が得意
- ニューラルネットの学習は単純な行列演算が多いので、高速化が可能
GPGPU開発環境
CUDA
- GPU上で並列コンピューティングを行うためのプラットフォーム
- NVIDIA社が開発しているGPUのみで使用可能
- Deep Learning用に提供されているので、使いやすい
OpenCL
- オープンな並列コンピューティングのプラットフォーム
- NVIDIA社以外の会社(Intel, AMD, ARMなど)のGPUからでも使用可能
- Deep Learning用の計算に特化しているわけではない
Deep Learningフレームワーク(Tensorflow, Pytorch)内で実装されているので、使用する際は指定すれば良い
モデルの軽量化
- モデルの精度を維持しつつパラメータや演算回数を低減する手法の総称
- 高メモリ負荷・高い演算性能が求められる
- 通常は低メモリ・低演算性能での利用が必要とされるIotなど
モデルの軽量化の利用
-
モデルの軽量化はモバイル, IoT 機器において有用な手法
-
モバイル端末やIoT はパソコンに比べ性能が大きく劣る
- 主に計算速度と搭載されているメモリ
-
モデルの軽量化は計算の高速化と省メモリ化を行うためモバイル,IoT 機器と相性が良い手法になる
-
代表的な手法として下記の3 つがある
- 量子化
- 蒸留
- プルーニング
量子化
- ネットワークが大きくなると大量のパラメータが必要なり学習や推論に多くのメモリと演算処理が必要
- 通常のパラメータの64 bit 浮動小数点を32 bit など下位の精度に落とすことでメモリと演算処理の削減を行う
メリット
- 計算の高速化
- 倍精度演算(64 bit)と単精度演算(32 bit)は演算性能が大きく違うため、量子化により精度を落とすことによりより多くの計算をすることができる。
- 省メモリ化
- ニューロンの重みを浮動小数点のbit数を少なくし、有効桁数を下げることでニューロンのメモリサイズを小さくすることができ、多くのメモリを消費するモデルのメモリ使用量を抑えることができる
デメリット
- 精度の低下
- ニューロンが表現できる少数の有効桁が小さくなる
- つまりモデルの表現力が低下する
蒸留
- 精度の高いモデルはニューロンの規模が大きなモデルになっている
- そのため推論に多くのメモリと演算処理が必要
- 規模の大きなモデルの知識を使い軽量なモデル作成を行う
モデルの簡素化
- 学習済みの精度の高いモデルの知識を軽量なモデルへ継承させる

- 知識の継承により軽量でありながら複雑なモデルに匹敵する
- 精度のモデルを得ることが期待できる
メリット
- 下記のグラフはCifar 10 データセットで学習を行ったレイヤー数と精度のグラフになる
- back propagation は通常の学習
- Knowledge Distillation は先に説明した蒸留手法
- Hint Taraing は蒸留は引用論文で提案された蒸留手法
- 図から蒸留によって少ない学習回数でより精度の良いモデルを作成することができている

プルーニング
- ネットワークが大きくなると大量のパラメータがすべてのニューロンの計算が精度に寄与しているわけではない
- モデルの精度に寄与が少ないニューロンを削減することでモデルの軽量化、高速化が見込まれる
計算の高速化
- 寄与の少ないニューロンの削減を行いモデルの圧縮を行うことで高速化に計算を行うことができる

ニューロンの削減
- ニューロンの削減の手法は重みが閾値以下の場合ニューロンを削減し、再学習を行う
- 下記の例は重みが0.1 以下のニューロンを削減した

まとめ
量子化
- 重みの精度を下げることにより計算の高速化と省メモリ化を行う技術
蒸留
- 複雑で精度の良い教師モデルから軽量な生徒モデルを効率よく学習を行う技術
プルーニング
- 寄与の少ないニューロンをモデルから削減し高速化と省メモリ化を行う技術
確認テストがないので代わりに考察

* 処理の量が少ないと、比例するようにして時間も少なくなっている
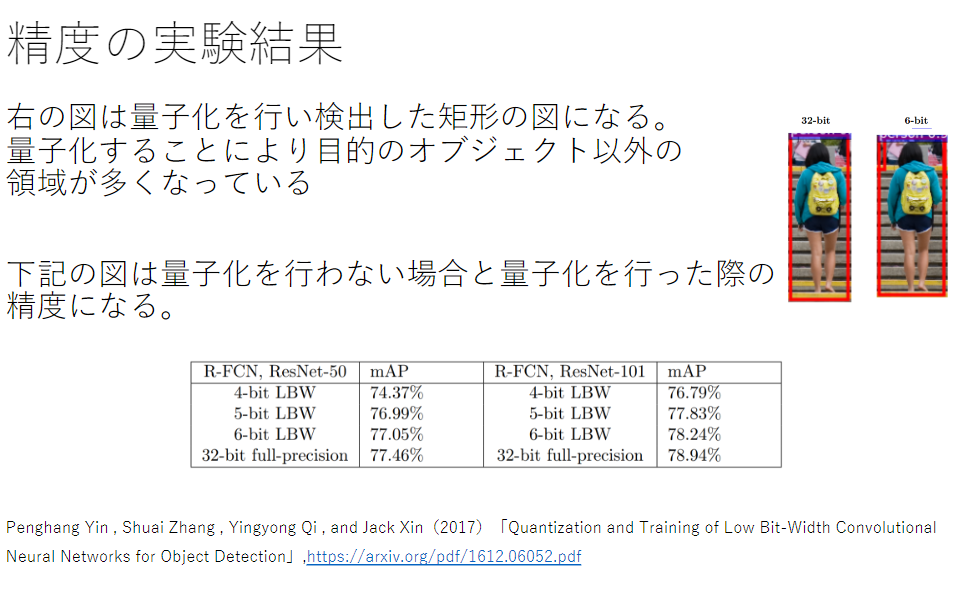
- 精度はあまり変わらないことが分かる
参考
Section4:応用モデル
MobileNet
- 一般的な畳み込みレイヤーは計算量が多い
- MobileNetは組み合わせで軽量化を実現
Depthwise Convolution
-
仕組み
- 入力マップのチャネルごとに畳み込みを実施
- 出力マップをそれらと結合(入力マップのチャネル数と同じになる)
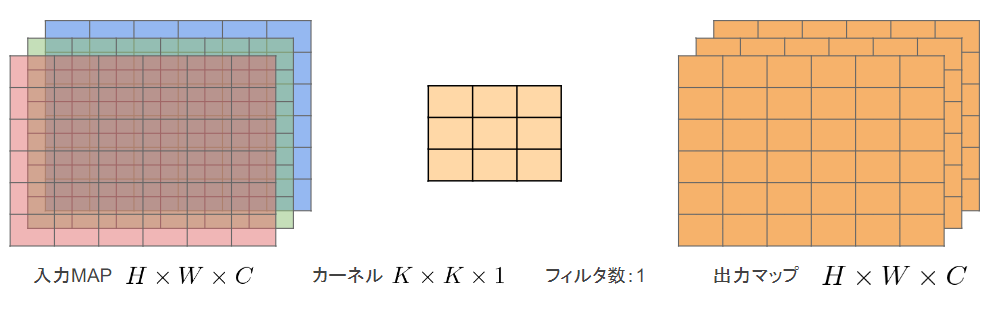
-
通常の畳み込みカーネルは全ての層にかかっていることを考えると計算量が大幅に削減可能
-
各層ごとの畳み込みなので層間の関係性は全く考慮されない。通常はPW畳み込みとセットで使うことで解決

Pointwise Convolution
-
仕組み
- 1 x 1 convとも呼ばれる(正確には1 x 1 x c)
- 入力マップのポイントごとに畳み込みを実施
- 出力マップ(チャネル数)はフィルタ数分だけ作成可能(任意のサイズが指定可能)

-
出力マップの計算量は$H×W×C×M$

DenseNet
- 初期の畳み込み
- Denseブロック
- 変換レイヤー
- 判別レイヤー

- 出力層に前の層の入力を足しあわせる
- 層間の情報の伝達を最大にするために全ての同特徴量サイズの層を結合する

- 特徴マップの入力に対し、下記の処理で出力を計算
- Batch正規化
- Relu関数による変換
- 3 x 3畳み込み層による処理

- 計算した出力に入力特徴マップを足し合わせる
- 入力特徴マップのチャンネル数がl x kだった場合、出力は(l+1) x kとなる
- 第l層の出力をとすると$x_1 = H_l([x_0, x_1,・・,x_{l-1}])$

growth rate
- kをネットワークのgrowth rateと呼ぶ
- kが大きくなるほど、ネットワークが大きくなるため、小さな整数に設定するのがよい
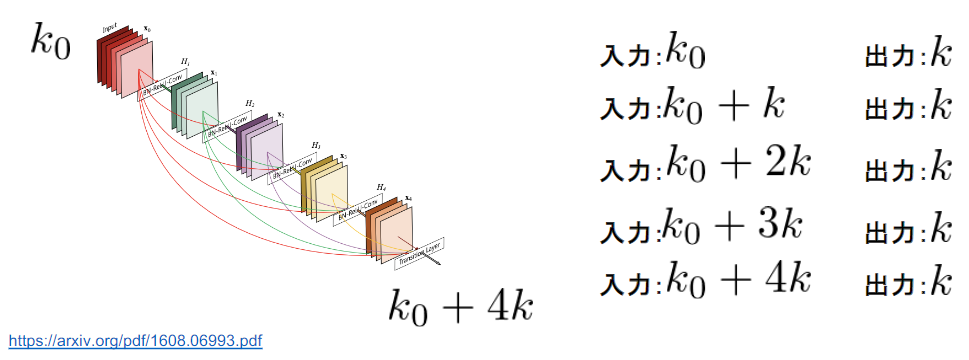
Transition Layer
- CNNでは中間層でチャネルサイズを変更し
- 特徴マップのサイズを変更し、ダウンサンプリングを行うため、Transition Layerと呼ばれる層でDence blockをつなぐ



- DenseNet内で使用されるDenseBlockと呼ばれるモジュールでは成⻑率(Growth Rate)と呼ばれるハイパーパラメータが存在する。
- DenseBlock内の各ブロック毎にk個ずつ特徴マップのチャネル数が増加していく時、kを成⻑率と呼ぶ
DenseNetとResNetの違い
- DenseBlockでは前方の各層からの出力全てが後方の層への入力として用いられる
- RessidualBlockでは前1層の入力のみ後方の層へ入力
Layer正規化/Instance正規化
いろんな正規化
Batch正規化
-
ミニバッチに含まれるsampleの同一チャネルが同一分布に従うよう正規化
-
H x W x CのsampleがN個あった場合に、N個の同一チャネルが正規化の単位
- RGBの3チャネルのsampleがN個の場合は、それぞれのチャンネルの平均と分散を求め正規化を実施(図の⻘い部分に対応)
- チャンネルごとに正規化された特徴マップを出力。
-
ミニバッチのサイズを大きく取れない場合には、効果が薄くなってしまう
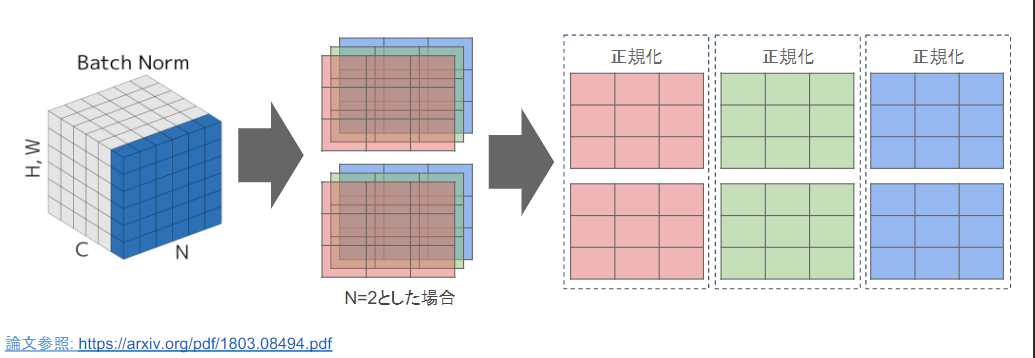
Layer正規化
- それぞれのsampleの全てのpixelsが同一分布に従うよう正規化
- N個のsampleのうち一つに注目。H x W x Cの全てのpixelが正規化の単位
- RGBの3チャネルのsampleがN個の場合は、あるsampleを取り出し、全てのチャネルの平均と分散を求め正規化を実施(図の⻘い部分に対応)
- 特徴マップごとに正規化された特徴マップを出力
- ミニバッチの数に依存しないので、上記の問題を解消できていると考えられる

- 入力データや重み行列に対して以下の操作を施しても出力が変わらないことが知られている
- 入力データのスケールに関してロバスト
- 重み行列のスケールやシフトに関してロバスト
Instance正規化
- さらにchannelも同一分布に従うよう正規化
- 各sampleの各チャネルごとに正規化
- コントラクトの画像に寄与・画像のスタイル転送やテクスチャ合成タスクなどで利用


Wavenet
- Aoron van den Oord et. al., 2016らにより提案
- Alpha Goのプログラムを開発しており、2014年にGoogleに買収される
- 生の音声波形を生成する深層学習モデル
- Pixel CNN(高解像度の画像を精密に生成できる手法)を音声に応用したもの
考え方
- 時系列データに対して畳み込み(Dilated convolution)を適用する
- Dilated convolution
- 層が深くになるにつれて畳み込むリンクを話す
- 受容野を簡単に増やすことができるという利点がある
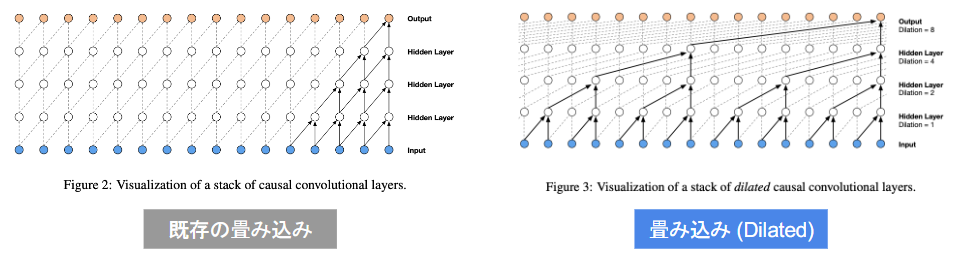
(右図ではDilated=1,2,4,8となっている)


- (あ) Dilated causal convolution
- (い) パラメータに対する需要やが広い
参考
Section5:Transformer

ちょっとニューラル機械翻訳の復習
- Encoder-Decoderモデル
- Encoder RNN
- 翻訳元の文を読み、実数値ベクトルに変換
- Decoder RNN
- 実数値ベクトルから、翻訳先の言語の文を生成
弱点
-
長さに弱い
-
翻訳元の文の内容をひとつのベクトルで表現
- 文長が長くなると表現力が足りなくなる
-
文長と翻訳精度の関係性

Attention
-
翻訳先の各単語を選択する際に翻訳元の文中の各単語の隠れ状態を利用
-
翻訳元の各単語の隠れ状態の加重平均
c_i = \sum^{T_x}_{j=1} \alpha_{ij}h_j・
- 重みはすべて足すと1
- 重みはFFNNで求める
\alpha_{ij} = \frac{exp(e_{ij})}{\sum^{T_x}_{j=1}exp(e_{ij})'} \\
e_{ij} = a(s_{i-1}, h_j)

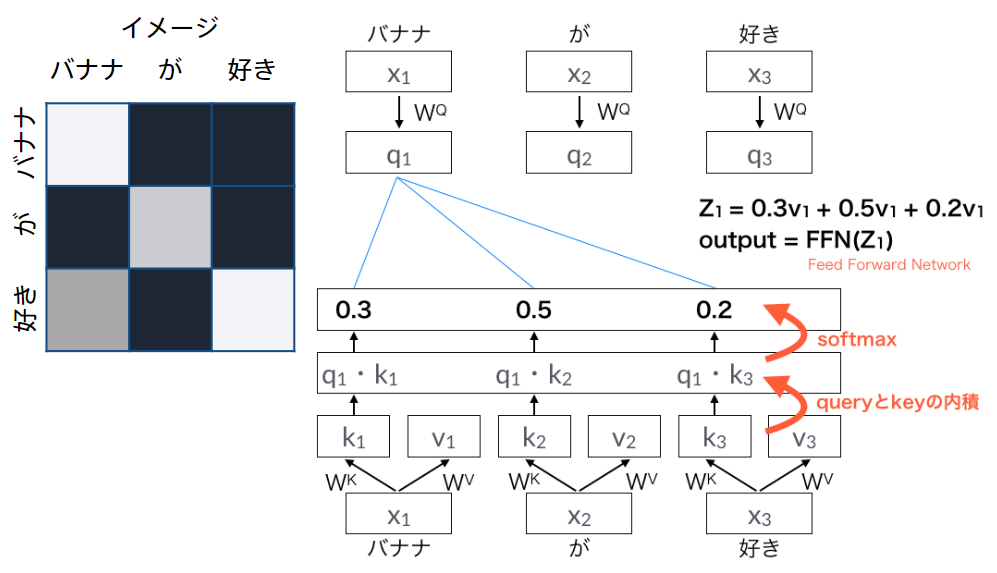
Attentionの例

Attentionの役割
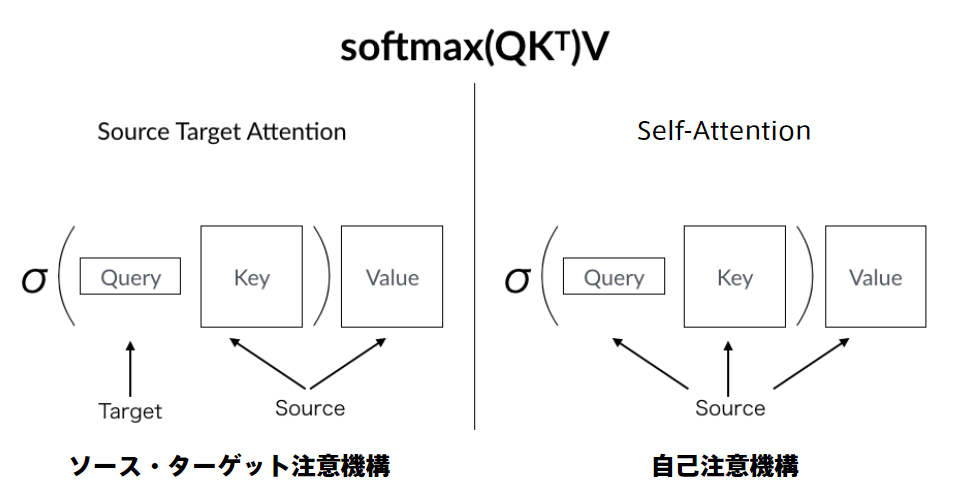
-
Attentionは辞書オブジェクト
-
query(検索クエリ)に一致するkeyを索引し、対応するvalueを取り出す操作であると見做すことができる
-
辞書オブジェクトの機能と同じである

Transformer
- 2017年に登場
- RNNを使わない
- 必要なのはAttentionだけ
- 当時のSOTAをはるかに少ない計算量で実現
- 英仏(3600万文)の学習を8GPUで3.5日で完了

$### Transformer Encoder
- 自己注意機構により文脈を考慮して各単語をエンコード
- 入力を全て同じにして学習的に注意箇所を決めていく
Position-Wise Feed-Forward Networks
- 位置情報を保持したまま順伝播させる
- 各Attention層の出力を決定
- 2層の全結合NN
- 線形変換→ReLu→線形変換

Scaled dot product attention
- 全単語に関するAttentionをまとめて計算する

Multi-Head attention
- 重みパラメタの異なる8個のヘッドを使用
- 8個のScaled Dot-Product Attentionの出力をConcat
- それぞれのヘッドが異なる種類の情報を収集

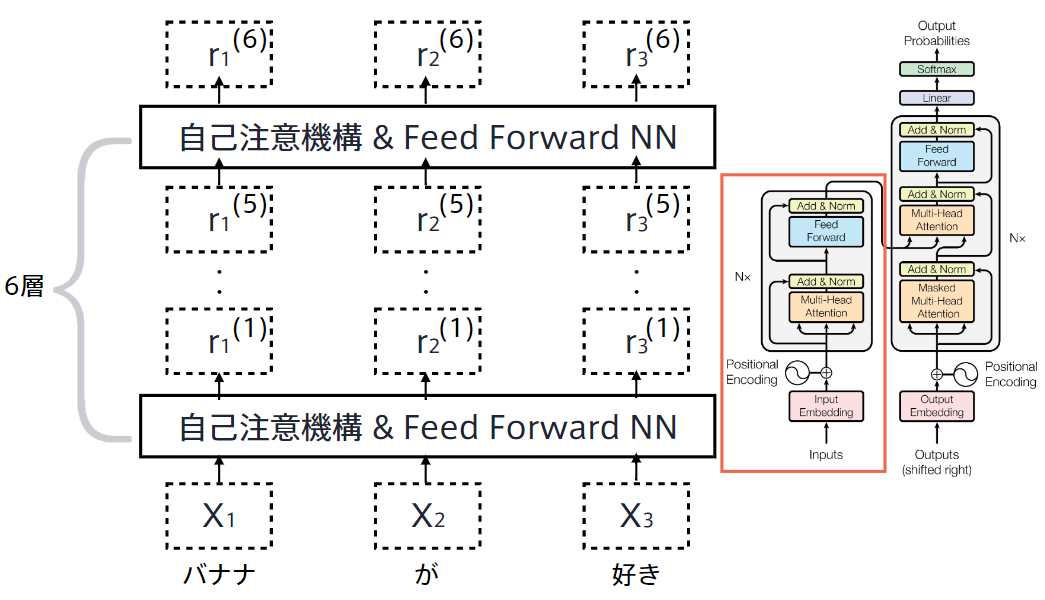
Decoder
- Encoderと同じく6層
- 各層で二種類の注意機構
- 注意機構の仕組みはEncoderとほぼ同じ
- 自己注意機構
- 生成単語列の情報を収集
- 直下の層の出力へのアテンション
- 未来の情報を見ないようにマスク
- 生成単語列の情報を収集
- Encoder-Decoder attention
- 入力文の情報を収集
- Encoderの出力へのアテンション
- 入力文の情報を収集
Add & Norm
- Add (Residual Connection)
- 入出力の差分を学習させる
- 実装上は出力に入力をそのまま加算するだけ
- 効果:学習・テストエラーの低減
- Norm (Layer Normalization)
- 各層においてバイアスを除く活性化関数への入力を平均0、分散1に正則化
- 効果:学習の高速化
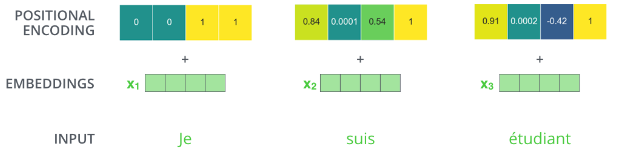
Position Encoding
-
RNNを用いないので単語列の語順情報を追加する必要がある
-
単語の位置情報をエンコード

-
posの(ソフトな)2進数表現
まとめ

Attentionの可視化
- 注意状況を確認すると言語構造を捉えていることが多い

参考
Section6:物体検知・セグメンテーション
広義の物体認識タスク
- 入力
- 画像(カラー・モノクロは問わない)
- 出力
* 分類- (画像に対し単一または複数の)クラスラベル
* 物体検知 - Bounding Box
* 意味領域分割 - (各ピクセルに対し単一の)クラスラベル
* 個体領域分割 - (各ピクセルに対し単一の)クラスラベル
- (画像に対し単一または複数の)クラスラベル


分類問題における評価指標の復習


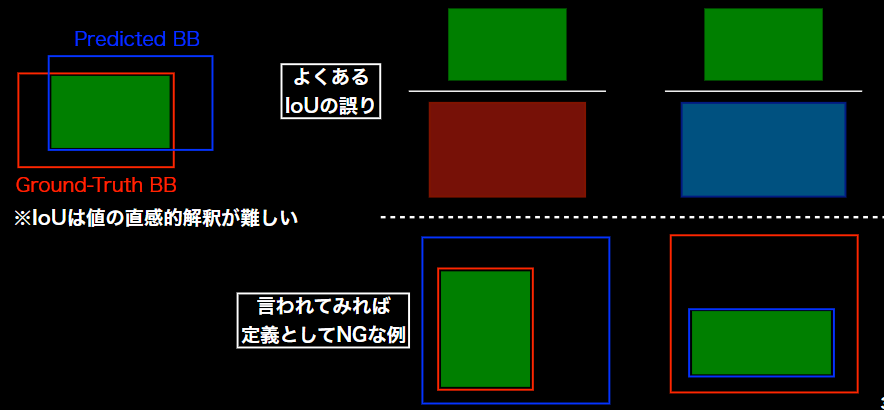
IoU:Intersection over Union
- Union32Motivation
- 物体検出においてはクラスラベルだけでなく, 物体位置の予測精度も評価したい

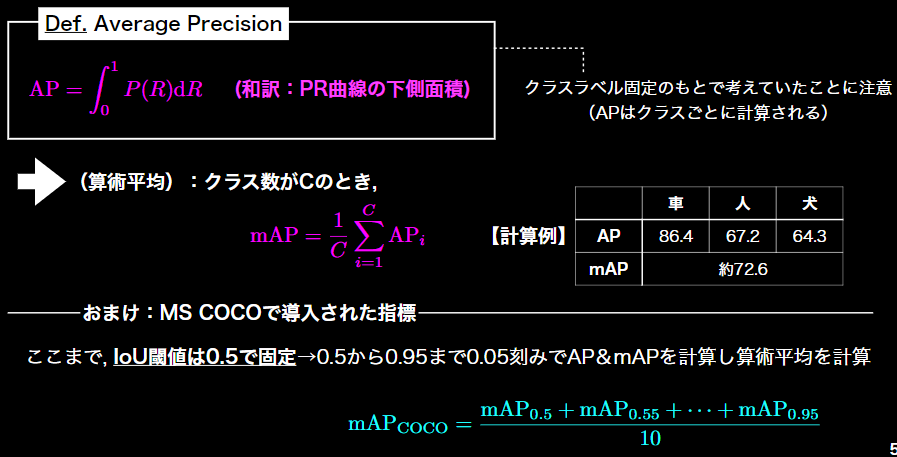
AP:Average Precision

mAP:mean Average Precision
FPS:Flames per Second
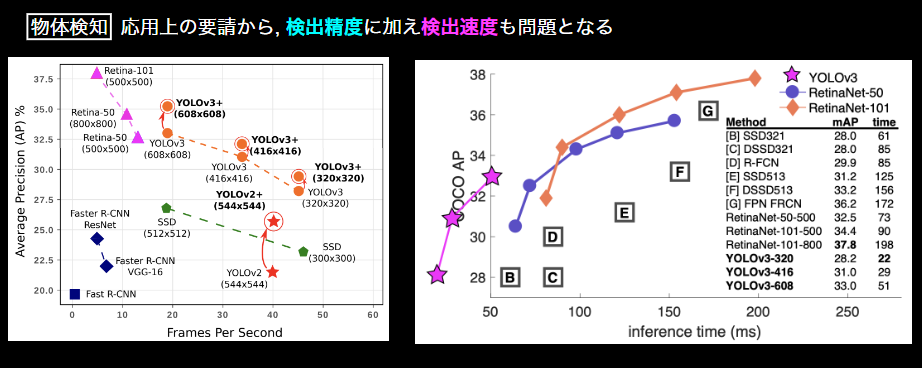
マイルストーン
- 深層学習以降の物体検知
2012: AlexNetの登場を皮切りに, 時代はSIFTからDCNNへ

SSD: Single Shot Detector

SSDのネットワークアーキテクチャ

特徴マップからの出力

SSDのデフォルトボックス数

- VOCデータセットではクラス数20に背景クラスが考慮され, #Class = 21となることに注意
- $4×(21+4)×38×38 + 4×(21+4)×3×3 + 4×(21+4)×1×1$
- $6×(21+4)×19×19 + 6×(21+4)×10×10 + 6×(21+4)×5×5$
- $=8,732 × (21+4)$
工夫
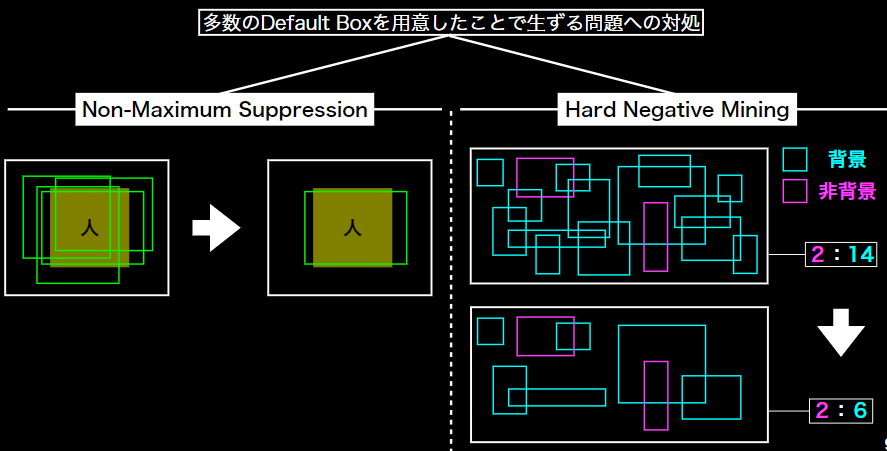
- RCNNでも既に用いられており初出の処理ではない
- 他にも, 原著論文では学習上の工夫としてDefault Boxのアスペクト比の選び方やData
Augmentationについても触れられている
参考