はじめに
今回はAWSさんが用意しているAmazon Personalizeのハンズオンを行ってみたので、そのまとめです
Amazon Personalize
公式曰く
Amazon Personalize は、アプリケーションを使用するユーザー向けに個別化したレコメンデーションを簡単に追加できる、開発者向けの機械学習サービスです。
使用例としては
ユーザーの嗜好や行動に基づくレコメンデーションの提供、結果のパーソナライズによる再ランク付け、E メールや通知のコンテンツのパーソナライズなどに使用できます。
とのこと。
現在鋭意製作中のプラットフォームアプリケーションで、楽曲レコメンドやアーティストレコメンドをおこないたいという要望に対して非常にマッチしているような感じでした。
ハンズオン
いきなり感想
感想をまずいうと、本当に簡単にできました!
行ったハンズオンでの作業では
- csvの1カラムを消す
- csvをS3に保存
- Amazon Personalizeでデータセットとしてcsvのpathを入力
- 勝手に読み込む
- Solutionを選んでモデル生成スタート
- 40分ほどまてば学習が終わる
- キャンペーン(レコメンドAPI)を作成し、レコメンドさせたいユーザIDを選んで結果が返ってくる
恐ろしく単純で、ぽちぽちクリックして寝て待てばAPIまでも自動で生成してくれる素晴らしいサービスだと思います。
やったハンズオン資料
https://pages.awscloud.com/event_JAPAN_Hands-on-Amazon-Personalize-Forecast-2019.html?trk=aws_introduction_page
Forcastのハンズオンもあったのですが、今回はPersonalizeのみやりました。
時間があればForcastもやってみたいと思います。
所要時間はモデル学習待ち時間とか含めて、3時間程度でした
使ったデータ
使ったデータは有名な映画データセット
https://grouplens.org/datasets/movielens/
csvの中身的には、9700 本の映画に対する 600 ユーザーの評価履歴があり行数は10万行くらい
10万サンプルのデータを使って学習するという認識です。
"rating.csv"というのを使っておりさらに学習ではレーティング部分は削除しています。
なので、特徴としてはUSER_ID, ITEM_ID(映画のID), TIMESTAMPだけで、USER_IDがみている映画データしかないです。なので、Amazon Personalizeの中の学習部分は"映画をみた"、"みなてない"という2値の誤差を計算しながら最適なレコメンデーションをおこなっていると思います。(推測なので全然違う可能性もあります)
手順
ハンズオンにすべて載っているので再掲するのはおこがましいので、
Personalizeの部分だけスクショ取っておきます。
S3で適当なバケットをつくり、rating.csvをおきバケットポリシーをPersonalizeがアクセスできるように設定しているというのが前提条件
1. create dataet group
データセットをAmazon Personalizeに登録します。
Personalizeのコンソールに行き、create_dataset_groupをクリックするとこんな画面に

大事なのはスキーマで、schema definitionと今回のcsvの形を合わせる必要があります。
スキーマと違うcsvを読み込むとどうなるかは試していないですが、データが正しくPersonalizeにとりこめないと思われます。なのでcsvのヘッダーを用意しているのかと
ここで注意しておきたいのは、 データ取り込みにもお金がかかるということ
"データ取り込み 0.05 USD/GB"
今回のハンズオンで取り込んだcsvで取り込み終了したのがおおよそ2, 30分くらいでした
2. create solution
取り込み終わったら実際に学習設定に入っていきます。
Dashbordの"create solution"のstartボタンを押すと設定画面に入っていきます。
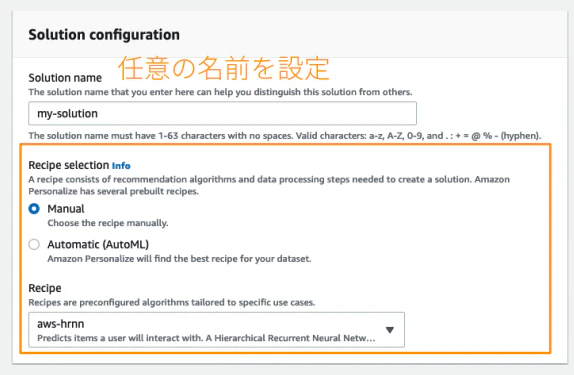
cf: https://pages.awscloud.com/rs/112-TZM-766/images/201912-AmazonPersonalizeHandson.pdf
この画面で実際にモデルの設定をしていきます。
Amazon Personalizeには事前に定義されているレシピが2020年2月現在では3つ存在しており、それぞれ
- USER_PERSONALIZATION: ユーザーがやり取りするアイテムを予測する(今回の例は映画)
- PERSONALIZED_RANKING: ユーザーがやり取りするアイテムを予測しかつランキングも出してくれる(おすすめランキングみたいなもの)
- RELATED_ITEMS: 指定されたアイテムに類似したアイテムをかえす(ある映画に似ている映画)
それぞれのレシピに対して、レコメンデーション方法があります。
- USER_PERSONALIZATION
- HRNN: 階層的再帰型ニューラルネットワークでITEMに触ったか触らなかったかのデータ
- HRNN-meta: ITEMの特徴とかのメタデータを加味したHRNN
- HRNN-colddata: HRNN-metaとの違いは"新しいアイテムのパーソナライズされた探索"も含まれる
- Popularity-Count: データセットないでのアイテムの人気度を計算して出す
今回はUSER_PERSONALIZATIONのHRNN(階層的再帰型ニューラルネットワーク)を用いました。 - PERSONALIZED_RANKING
- Personalized-Ranking: ランキングをつけてくれるHRNN
- RELATED_ITEMS
- SIMS: ユーザー履歴内のアイテムの共起を計算して出してくれる(協調フィルタリング)
基本はAmazonが発表したHRNNがPersonalizeの全てになっていると思います。
RNNの資料に関しては前に発表したことがあるので載せておきます。
https://www.slideshare.net/aratahonda1/rnnlstm
今回はUSER_PERSONALIZATIONのHRNNを用いました。
学習方法はどうやらBPTTを使っているらしい(スライドにBPTTも載っています)
なので、設定するハイパーパラメータ(自分たちが手で入力するもの)は
- hidden_dimension : NNの隠れ層の階層数
- bptt: bpttがどのくらいの学習ステップまでを一度に計算するか
- recency_mask: アイテムのTIMESTAMPを加味するか(例えば一番最近みた映画に重み付けするなど)
の三つです。RNN自体が時系列をNNで表現したものなので、時間ステップという概念がないとここら辺ん設定できないかもしれません。
本当にわからない人はHPO(HyperParameterOptimazer?)をTrueにしてハイパーパラメータを範囲指定して一番いい結果だけを返してくれるものがあるのでそれに頼るといいかもです。
もっというと、うえのレシピも何を選んだらいいかわからない人はauto MLをつかうとそれさえも自動でやってくれます。
あとはポチポチすると学習スタートし、1時間ほどかかりました。
10万サンプルで40分程度だったのでそれ以上のデータを投入するともっとかかるかもしれません。
(あとはハンズオン通りにおこなったのでハイパラは決め打ちです)
3. create campaign
学習が終わると、Dashbordにいきcreate campaignボタンを押します。
これで2でつくったHRNNモデルを組み込んだレコメンデーションAPIを自動で作ってくれます。
2でつくったソリューションIDを選んでcreateボタンを押すだけでレコメンデーションAPIも作ってくれるとは...恐ろしいくらい簡単ですね
作成した時間はおおよそ10分くらいです。
設定的には特にないですが、一回のAPIを叩くと何件返して欲しいかなど(defaultで25件)くらいですかね。
あとはuser_idを入れてみて映画のIDを返すかの確認です。
試したこと
-
何回かレコメンドしてみる
user_id = 1をいれてレコメンドを何回かしてみるということをしてみました。
結果的にレコメンデーションの結果は全く変わらなかったです。
ただし、user_id = 2をいれて返ってくるレコメンデーション結果はuser_id = 1の時の結果と違うことは確認できました。
このことから、ソリューションを回したタイミングでもうユーザへのレコメンデーションの結果は決まっており、それを更新するとレコメンデーション結果が変わると思われます。
なので、使い方としてはバッチ推論ジョブをつかって、DBかなにかで登録しているユーザIDでレコメンデーションを行い、その推論結果をS3に保存しておいて、「今日のおすすめ」みたいな感じで出すという形の方がリアルタイム推論APIを使うよりコスト的にはいいのかなと思いました。(間違ってたらごめんなさい -
存在しないユーザIDをうってみる
user_idは600がマックスなので123456とか存在しないuser_idでレコメンデーションしてみました。
結果的には、何かしらのレコメンデーション結果は返ってきましたが、さらに23455とか適当に打っても123456のレコメンデーション結果と変わらなかったです。
このことから学習データに存在しないユーザデータ、つまり新規ユーザに対しては同じ何かしらのレコメンデーション結果が返ってくるということがわかりました。
おわりに
大事なのはこのレコメンデーションの妥当性を検証するためのKPIを作る必要があるということだけは最後に書いておきます。
非常に作りやすいレコメンデーションシステムで全く触ったことない人でも簡単に作れるのでレコメンデーションを入れるハードルは低くなると思いました。