はじめに
社内で実施したハンズオン形式のClean Architecture入門勉強会内容を晒します。
概要
Clean Architecture とは
「関心の分離」を目的にしたノウハウやベストプラクティス集です。
本では実例を交えたレイヤーやデータフロー、クラス図などでの図解されています。
以下クリーンアーキテクチャの図が有名です。
*The Clean Architecture - The Clean Code Blog by Robert C. Martin(Uncle Bob)より引用
本の副題 アーキテクチャのルールはどれも同じである にもある通り、作者がいろいろなシステムを構築した経験で気づいたルールや、先人が残した知恵(原則など)を元に、システム開発でうまくいくプラクティスを理解/納得できるように歴史から紐解かれています。
Clean Architecture の目的
「関心の分離」を目的にしていて、以下のようなアーキテクチャと同じ目的を持っています。
- ヘキサゴナルアーキテクチャ
- オニオンアーキテクチャ
- DCIアーキテクチャ
- BCE
「関心の分離」を目的にしていますが、そのメリットを見てみましょう。
- フレームワーク非依存
- テスト可能
- UI非依存
- データベース非依存
- 外部エージェント非依存
噛み砕くと、
- 時代ごとに進化していくフレームワークを入れ替え可能なツール(手段)として用いることでフレームワークへの依存をなくす。
- それぞれのレイヤーごとにテストしやすくなる。
- ビジネスルールを変更することなくウェブからアプリなどへ置き換えることができる。
- ビジネスルールを変更することなくmysqlからredis、dynamoやインメモリ、その他データベースを置き換えることができる。
- それらフレームワーク、UI、データベースがなんであるか知らなくても実装できる。(知らないように実装しないといけない)
フレームワークもデータベースもUIも手段であって目的ではなく、本質にフォーカスすることができます。
外側を知らなくていいメリットはいろいろあり、年数がたつごとに古くなるツールを置き換えることが可能になったり、
技術選定を遅らせたり、知見がないために選定した技術では実現できないことが分かって戻りが発生した場合など、最小の労力で変更ができます。
この記事で学ぶ範囲
クリーンアーキテクチャの中心的な原則で一番重要な SOLIDの原則 の内の1つ 依存性逆転の原則 について深掘りします。
依存方向をコントロールすることで「関心の分離」を達成し、目的でも語った得られるメリットを教授できるアーキテクチャについて学びます。
図の理解
簡単に図の表す意味を説明しておきます。
- 円の4つの層はレイヤ
- 矢印は依存方向
- 右下のクラス図は詳細な依存方向と処理の流れ
現時点ではなんとなくでも結構です。次のセクションから似たアーキテクチャを理解しながら深ぼってみます。
似たアーキテクチャ
クリーンアーキテクチャの詳細に入る前に、比較的わかりやすい似たアーキテクチャから簡単に確認してイメージしてみましょう。
ヘキサゴナルアーキテクチャ

*Hexagonal architecture - by Alistair Cockburnより引用
ポートアンドアダプターとも呼ばれるヘキサゴナルアーキテクチャはアプリケーションとそれ以外を分け、それ以外の部分をつけ外しできるようにすることをコンセプトにしたアーキテクチャです。
アプリケーションとそれ以外は、DDDのドメインとそれ以外と言い換えてもよく、part3(DDD)の具体例で見た図を思い出してもらえると分かりやすいかもしれません。
ヘキサゴナルアーキテクチャはゲーム機で例えられることが多いです。
- ゲーム機(アプリケーション)
- 純正や非純正、アケコン、ガンコンなどの
コントローラー - いろいろなカセット、
ソフト - 液晶、プラズマ、有機ELなど各
ディスプレイ - HDD、クラウド、メモリーカードなどの
記憶装置
- 純正や非純正、アケコン、ガンコンなどの
ゲーム機をアプリケーションに見立て、全てポートとアダプターで繋ぐと拡張可能であることがイメージしやすいと思います。
ゲーム機は(ディスプレイで言えばHDMIなどの)インターフェースに依存していて、将来どういうデバイスが作られるかなど、外側のことを知らずに作られています。
ゲーム機(アプリケーション)は、使われる側で外側に依存しておらず、コントローラーやソフトやディスプレイや記憶装置はゲーム機に依存していることがわかると思います。
クリーンアーキテクチャの図をもう一度見てみましょう。依存方向を表す矢印は常に内側に向いています。
ヘキサゴナルも同様に、内側のアプリケーションにしか依存方向を伸ばさない、内側にしか依存してはいけないというクリーンアーキテクチャと共通する考え方です。
フレームワークやデータベースも同様、ポートとアダプターというインターフェースに依存した作りにすることで拡張/付け替え可能なアーキテクチャで、 依存性逆転の法則をベースに「関心の分離」を実現 しています。
ちなみに六角形に特別な意味はなく、あやゆる方向にポートとアダプターを追加して拡張できるという表現のようです。
オニオンアーキテクチャ
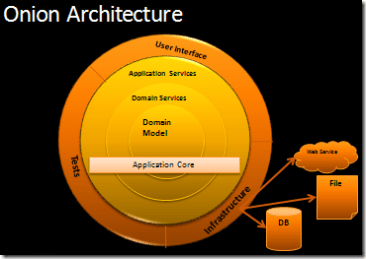
*The Onion Architecture : part 1 - by Jeffrey Palermoより引用
オニオンアーキテクチャはDDDで提唱されている考え方を図で表したアーキテクチャです。
クリーンアーキテクチャの図に近づいてきました。
オニオンアーキテクチャはDDDの章で学んだ用語が出てくるので理解しやすくなっているかと思います。
以下を依存される中心、アプリケーションコアとして、
- アプリケーションサービス
- ドメインサービス
- ドメインモデル
またそれ以外の以下を外側に配置しています。
- ユーザーインターフェース
- インフラストラクチャ
- テスト
ヘキサゴナルより実践的な例で、詳細に層を分けられています。
ヘキサゴナルと同様に、 ユーザーインターフェース (WebかアプリかCLIか) や インフラストラクチャ (mysqlかredisか、はたまたECSかServerlessか) や テスト (jestかrspecか、はたまたunitかe2eか) はアプリケーションの関心の外であり、拡張/付け替え可能なアーキテクチャで、こちらも 依存性逆転の法則をベースに「関心の分離」を実現 しています。
クリーンアーキテクチャは?
*The Clean Architecture - The Clean Code Blog by Robert C. Martin(Uncle Bob)より引用
上記2つのアーキテクチャは共に 依存性逆転の法則をベースに「関心の分離」を実現 しています。クリーンアーキテクチャも同様です。
違いは層の名前や細かい具体例の有無です。クリーンアーキテクチャは細かいレイヤやクラス図などが詳細に書かれています。
クリーンアーキテクチャについて
個人的に、クリーンアーキテクチャの理解を難しくしている一因だと思う勘違いしやすいことを先に説明しておきます。
・4つの円だけ?
円は概要を示したものである。したがって、この4つ以外にも必要なものはあるだろう。この4つ以外は認めないというルールはない。
ただし、依存性のルールは常に適用される。ソースコードの依存性は常に内側に向けるべきだ。
内側に近づけば、抽象度と方針のレベルは高まる。円の最も外側は、最下位レベルの具体的な詳細で構成される。
内側に近づくと、ソフトウェアは抽象化され、上位レベルの方針をカプセル化するようになる。円の最も内側は、最も一般的で、最上位レベルのものになる。
- Clean Architecture 達人に学ぶソフトウェアの構造と設計 22章 クリーンアーキテクチャ 202Pより引用
噛み砕くと
- 図は例で、層の数や内容が重要というわけではない
- 依存の方向は常に内側(ユースケースやエンティティ、DDDでいうドメイン)に向ける必要がある
依存性は常に内側に向けるべき 理由や後半の以下について、安定依存の原則(SDP) から紐解いてみます。
内側に近づけば、抽象度と方針のレベルは高まる。円の最も外側は、最下位レベルの具体的な詳細で構成される。
内側に近づくと、ソフトウェアは抽象化され、上位レベルの方針をカプセル化するようになる。円の最も内側は、最も一般的で、最上位レベルのものになる。
安定依存の原則(SDP)
安定度の高い方向に依存する という原則です。
逆に言えば 自分より不安定なコンポーネントに依存してはならない ということになります。
依存とは
安定度の高い方向に依存 の依存とは
例えば
レイヤードアーキテクチャ(4層アーキテクチャ)における
プレゼンテーションはアプリケーションに依存(利用)し知っていて、
アプリケーションはドメインに依存(利用)し知っています。
MVCにおける
ViewはControllerが持っている変数やメソッドを知っていて依存していて、
ControllerはModelが持っているプロパティやメソッドを知っていて依存しています。
安定度とは
安定度の高い方向に依存 の安定度とは
高いほど依存(利用)されていて、低いほど利用されていない度合いです。
安定度の高いコンポーネント
ドメインやモデルは多数から利用されていて安定度の高いコンポーネントだと言えます。
安定度の高い方向に依存 した方が良い理由は、
多数のコードから依存(利用)される側のドメインやモデルは、本質的な価値を提供する「上位レベル」のコンポーネントなので、
外側であるプレゼンテーションやControllerやViewの変更の影響を受けないようにしようという理由です。
安定度の低いコンポーネント
逆に依存(利用)する側のプレゼンテーションやViewは変更しやすく置き換えやすいことがわかるかと思います。
本質的な価値ではない「下位レベル」のコンポーネントは、変更しやすく置き換えやすいように依存(利用)する側として定義することができます。
変更しやすく置き換えやすいコンポーネントは柔軟性が高くなります。
安定度と柔軟性のバランス配分
安定度の高い方向に依存 した方が良い理由を以下記事からもう少し深ぼってみます。
上記記事の安定度と柔軟性のバランス配分の話にもある通り、
外側ほど柔軟性を高く(安定度は低い) 作り、柔軟に変更できるようにする必要があり、
内側ほど安定度が高く(柔軟性は低い) 作り、外側の変更に影響を受けないようにする必要がある、と書かれています。
しかし、普通に作るとUsecase層がInfrastructure層に依存して、Infrastructure層が安定度が高くなってしまいます。
Infrastructure層がUsecase層に依存する方向にしたい、それを実現するために依存方向をコントロールするのが、依存性逆転の原則で、クリーンアーキテクチャの中核になる原則です。
柔軟性について
内側に求められるのが安定度だとわかりましたが、外側に求められる柔軟性について、
柔軟に変更できることの大切さについて柔軟性が悪くなる例を元に説明してみます。
ユーザー登録と更新フォームの例
外側への柔軟性が必要な例やメリットとしてDBはリポジトリパターンで入れ替え可能だという説明はあらゆる記事で解説されているので、
ここではUIであるフロントエンドの ユーザー登録フォーム と ユーザー情報更新フォーム で説明してみようと思います。
名前、ふりがな、メールアドレスなどのフォームを表示/編集できる必要があるフォームです。
登録も更新も全く同じなので、以下のような共通コンポーネントを作ることができます。
<UserForm
user={user} // 登録時は空
onSubmit={(user: User) => {}}
/>
後に以下のような要件が出てくるケースはよくあります。
- ユーザー登録時に利用規約に同意する必要があるが、更新時フォームでは表示する必要はない
- ユーザー登録時にパスワードが自動登録されるので、更新フォームで表示/編集できるようにする
- 登録時の項目の多さでユーザーが離脱することがわかったので、登録時の必須項目は少なくしたい
- ユーザー登録時と更新時のデザインを変えたい
簡単な要件であれば良いのですが、パラメータを受け取ったり受け取ったuserが空かなどを元に、内部に条件分岐を持って対応できたとします。
また、後に以下の要件がでてくるケースがあります。
- 管理者がユーザーの情報を更新する場合もあるので管理ページでも使う
- 管理者は一部の項目のみ編集できる
コンポーネント内部に条件分岐が溜まって複雑化していき、
年数が経つ頃には変更しにくい触りたくないコンポーネントになっているでしょう。
何が間違っていたのか、どういう対策をしたら良いのか次のセクションで説明します。
SOLID原則 単一責任の原則(SRP)
単一責任の原則 は1つの責任のみを果たすように設計するべきという考え方です。
上記例では ユーザー登録 と ユーザー情報更新 で偶然同じ項目を持っていたものの、ユースケースは別物です。
単一責任の原則 から答えを出すと、先ほどのコンポーネントは2つ以上の責任を持つことになるのでコンポーネントを分けることができます。
ただ、初めからは気づきにくいことでもあるので、システムは変わるものだと捉えて、要件に合わせて分割するなどの決断が求められます。
<UserRegisterForm
onSubmit={(user: User) => {}}
/>
<UserUpdateForm
user={user}
onSubmit={(user: User) => {}}
/>
<AdminUserUpdateForm
user={user}
onSubmit={(user: User) => {}}
/>
DRY原則への違反?
DRY原則 (Don't Repeat Your Self)とは、繰り返しを避けるという原則です。
とても重要な原則で、知っている人も多いのではないでしょうか?
繰り返しを避けるという意味で、先ほどの例で共通コンポーネントを作る方が正しいと捉える人も多いかと思います。
DRY原則の正しい意味は 知識の重複を避ける という意味で、ユースケースが別であるコードやテストなど例外がたくさん示されています。
達人プログラマーにも以下例で紹介されています。
def validate_age(value):
validate_type(value, :integer)
validate_min_integer(value, 0)
def validate_quantity(value):
validate_type(value, :integer)
validate_min_integer(value, 0)
・コードのニ重化すべてが知識のニ重化というわけではない
コードレビューの際に、これら2つの関数のコードは同じコードであるため、DRY原則に違反しているという声が上がりました。しかしその意見は間違っています。コードは同じですが、これらコードが表現している知識は異なっているのです。
これら2つの関数は、異なる2つのものごとが同じ規則を有しているということを示しているだけです。それは偶然でありニ重化ではありません。
達人プログラマー P43より引用
また、クリーンアーキテクチャ本にも
モジュールはたったひとつのアクターに対して責任を負うべきである
- Clean Architecture 達人に学ぶソフトウェアの構造と設計 7章 SRP:単一責任の原則 82Pより引用
とあるように、ユーザーや管理者など、使う人が変われば責任の種類も変わるので、コンポーネントをわけないと 単一責任の原則 に違反して複雑度が上がり、柔軟性が減る要因になってしまいます。
以下記事も参考として掲載しておきます。
-
あなたはDRY原則を誤認している?
- DRY原則を破るということは、同じ知識を2箇所以上に記述することです。
- DRYは素晴らしい考えですが、やり過ぎると密結合を生んでしまう。密結合が進むと修正時に影響範囲が増えてしまうんですね。
-
リファクタリング自爆奥義集 共通化しちゃいけない箇所を共通化
- 同じようなロジック、似ているロジックであっても、概念が違えばDRYにすべきではないのです。
-
DRYと不当な抽象化によるコストについて
- 実際のところ、私は時として抽象化よりむしろ重複の方を勧めているのです。
-
DHHはどのようにRailsのコントローラを書くのか
- 重複する方が、間違った方法で抽象化するよりずっと負担が小さくなります
*全ての原則が常に正しいということではなく、プロジェクトによって目的やその他コンテキストが変わるのでバランスを考えて使いましょう。
依存性は常に内側に向けるべき 理由
内側ほど安定度が高く、外側ほど柔軟性を高く 作る必要があることがわかったと思いますが、
話は戻って本にあるクリーンアーキテクチャの説明を再度見てみます。
円の最も外側は、最下位レベルの具体的な詳細で構成される。
というのは、外側は ユーザーインターフェース や インフラストラクチャ を指し、それらは変更しても影響を受けないよう、柔軟性高く入れ替えできるように依存する側として作るべき、ということです。
内側に近づけば、抽象度と方針のレベルは高まる。
内側に近づくと、ソフトウェアは抽象化され、上位レベルの方針をカプセル化するようになる。円の最も内側は、最も一般的で、最上位レベルのものになる。
というのは、内側は エンティティ や ユースケース DDDでいう ドメイン を指し、
安定度の高いドメインはロジックを分散させず依存される側として作るべき、ということです。
依存性は常に内側に向け、内側ほど安定度が高く外側ほど柔軟性を高く作ることは、 利口なUIアンチパターン への対策にもつながります。
クリーンアーキテクチャの図解
丸い図とデータフロー図、より詳細なクラス図があります。
ひとつづつ詳細に見てみます。
4つのレイヤが例だと話した通り、それぞれの層や役割について必ずこうしろというものではありません。具体的な説明のために私の主観が混じっている点はご了承ください。
円
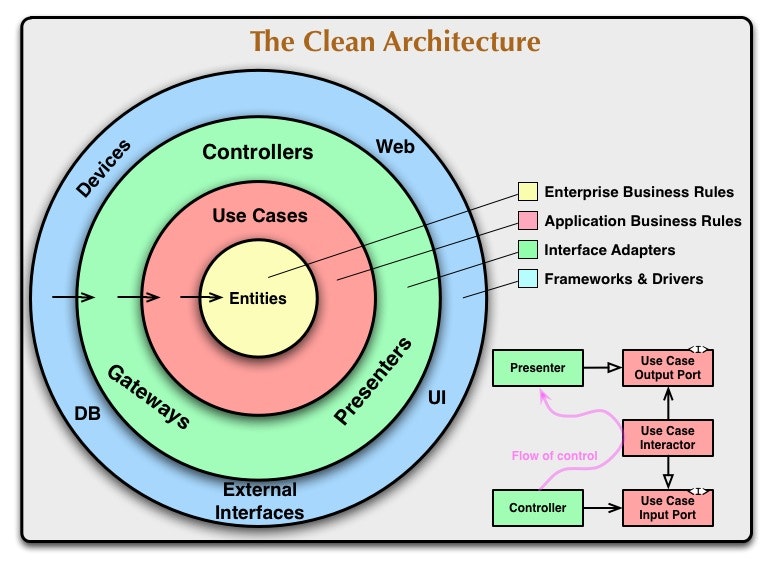
Enterprise Business Rules
中心の円が Enterprise Business Rules です。
Enterprise Business Rulesは、最重要ビジネスルール、DDDにおける値オブジェクト、エンティティ、ドメインサービスなどを定義します。
主にデータ構造に焦点を当てて実装します。
- Entiry
- DDDの値オブジェクト
- DDDのエンティティ
- DDDのドメインサービス
Application Business Rules
内側から2番目の層が Application Business Rules です。
Use Cases とあるようにアプリケーション固有のビジネスルール、DDDにおけるアプリケーションサービスなどを定義します。
この2番目の層までがドメインです。
また、外側の層が依存するインターフェースも定義します。
- UseCase
- DDDのアプリケーションサービス
- Repository Interface
- Input Port
- Output Port
Interface Adapters
内側から3番目の層が Interface Adapters です。
Webのリクエスト/レスポンスやDBに渡すためのデータ変換と永続化を定義します。
- Controller
- Presenter
- Gateway
Frameworks & Drivers
一番外側の層が Frameworks & Drivers です。
ginでレスポンスを返すなど、フレームワークやデータベースについての具体的な処理を定義します。
- DB
- Web
- UI
- Devices
- External Interfaces
データフロー
右下の小さなクラス図について説明します。
- 緑は
Interface Adaptersのクラス - 赤は
Application Business Rulesのクラス -
<I>はインターフェース - 矢印は
依存を表していてA -> Bの場合、AがBを利用している関係 - 白抜き矢印は
汎化を表していてA -> Bの場合、AがBを汎化/実装している関係 -
Flow of controllは制御の流れ
これをまとめると以下の流れで処理されることになります。
-
ControllerがUse Case Input Port<I>のメソッドを呼ぶ -
Use Case Input Port<I>を実装しているUse Case Interactorのメソッドが実行される -
Use Case InteractorがUse Case Output Port<I>のメソッドを呼ぶ -
Use Case Output Port<I>を実装しているPresenterのメソッドが実行される
なぜこういう流れにしているかというと、内側が外側に依存してしまうためです。
例えば、単純にInterfaceを使わず手続き的な流れで実装すると
-
ControllerがUse Case Interactorのメソッドを呼ぶ -
Use Case InteractorがPresenterのメソッドを呼ぶ
となり Controller -> Use Case Interactor -> Presenter の流れは達成できているものの、依存性逆転の原則に違反してしまうからです。
先ほどのInterfaceの流れを通して、処理の流れを変えずに、依存方向をコントロールしています。
詳細なクラス図
クリーンアーキテクチャ本 P204 に典型的なシナリオとして、より詳細なクラス図があります。
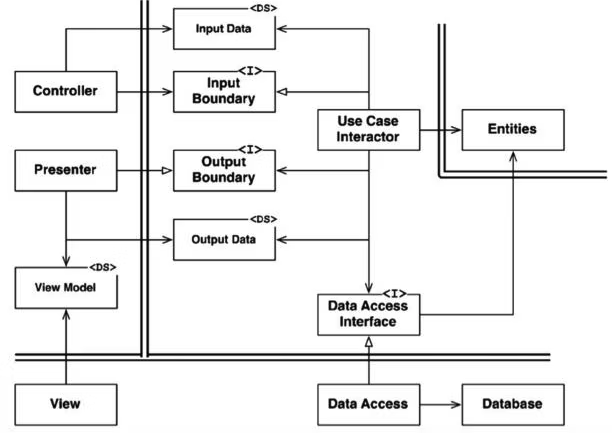
具体的な処理の流れとしては以下になります。
- ハンドラに紐づけられた
Controllerのメソッドを呼び出す -
ControllerがパラメータをInput Data<DS>形式に変換しInput Boundary<I>のメソッドに渡して呼び出す -
Input Boundary<I>を実装しているUse Case Interactorのメソッドが実行される -
Use Case InteractorはInput Data<DS>を元にData Access Interface<I>のメソッドを呼び出す -
Data Access Interface<I>を実装したData Accessがデータを返す - データを受け取った
Use Case InteractorはOutput Data<DS>形式に変換しOutput Boundary<I>のメソッドに渡して呼び出す -
Output Boundary<I>を実装しているPresenterのメソッドが実行され、データを表示する
常に依存は内側に向いていることがわかると思います。
実例
https://github.com/arakawamoriyuki/go-clean-handson/blob/main/clean-architecture にTODOリストの例をサンプル実装しています。
$ cd /path/to/go-clean-handson
$ docker compose up
$ mysql --host=127.0.0.1 --port=3306 --user=root --password=pass
mysql> create database `ca-sample` default character set utf8mb4 collate utf8mb4_bin;
$ cd /path/to/go-clean-handson/clean-architecture
$ export DATABASE_URL='mysql://root:pass@tcp(localhost:3306)/ca-sample'
$ migrate -database ${DATABASE_URL} -path migrations up
$ curl --request GET --url http://localhost:8080/api/todos/1
{"id":1,"name":"test"}
- /main.goでginのルーターのセットアップとサーバー起動を行います
- /infrastructure/router/router.goでginのルーターとハンドラ(Controller)の紐付けを行います
-
Controllerは以下手順でJSONを出力します。
- リクエスト情報を解析
-
InputPort<I>の望むInputData<DS>形式に変換 -
InputPort<I>の実装である Interactor のメソッドを呼び出し、以下手順で出力形式のデータを返す-
Repository<I>を実装した Repository のメソッドを利用して値を取得します。 - さらに
OutputPort<I>の望むOutputData<DS>形式に変換しOutputPort<I>の実装である Presenter へ渡し、出力形式に変換して返します。
-
- Interactorが返した値をJSONを出力
*クリーンアーキテクチャ本の説明の通り、Presenterで表示可能な形式に変換していますが、テンプレートエンジンの必要ないAPIサーバーな都合上、Viewの概念を取り払い、Controllerに返して値を返すように変更しています。いくつかのリポジトリを参考にしていますが、レンダリングするパターンはPresenter/Controller両方あり、contextを引数でバケツリレーしないといけなかったり、レンダリングを片方にまとめたい理由からControllerに寄せる構成にしています。
今回はただのTODOアプリで過剰すぎる例ですが、アプリケーションが複雑な要件を持つにつれ効果を発揮していきます。
また、細部の実装は違うものの、検索するとサンプルプロジェクトを見ることができます。
それぞれ 依存性逆転の原則 を守っているものの定まった構成はなく、各のプロジェクトで必要なレイヤを必要な構成で組まれているようです。
参考にするといいと思います。
- https://github.com/bxcodec/go-clean-arch
- https://github.com/nrslib/CleanArchitecture/tree/master/CleanArchitectureSample
- https://github.com/evrone/go-clean-template
- https://zenn.dev/daiki_skm/articles/6ff48a9dc4f645
- http://psychedelicnekopunch.com/archives/1308
- https://github.com/k-takeuchi220/golang-clean-architecture-example
クリーンアーキテクチャのメリット/デメリット
メリット
- 疎結合
- 依存性逆転の原則により、依存方向がルール化され、依存や前提、罠が減る
- このコードを変更すると知らずに違う場所に影響ある、みたいなことが減る
- 関心の分離
- 無駄を削ぎ落としたイージー(簡単)ではなく、記述量は多いがわかりやすいシンプル(単純)
- イージー(簡単)なコードは記述量は少ないが、細かい挙動の調整が効かなくて拡張もしにくい
- シンプル(単純)なコードは愚直で記述量は多いが、保守・拡張がしやすく処理の見通しが良い
- 変化に強い
- 依存性逆転の原則により、DBやフレームワークの置き換えが可能
- 置き換えが可能であり、技術選定を後回しにできる
- 必要なら入れ替えられるので仮実装ができ、バックエンド、フロントエンドのような順で完成される必要がない。並行作業可能
- テスタブル
- 各層のコードの依存方向がルール化されているのでテストしやすい
- リポジトリなどをテスト用に入れ替え可能
デメリット
- コードが冗長
- シンプル(単純)なコードは愚直で記述量は多い
- 直感的でない
- 依存性逆転の原則を守る必要があり、手続き的なプログラミングが許されていない
- 簡単に手続き的プログラミングで実装し、ルール違反できてしまう
- 学習コスト高い
- 少なくともクリーンアーキテクチャへの深い理解とメンバーへの説明/共有が必要だと思う
- スキャフォールドのようなジェネレータ、テンプレを用意すると楽になりそう
まとめ
クリーンアーキテクチャを導入することによって何を達成したいのか、実装例とメリットデメリットを学びました。
実際に実装してみると、外側の変更は影響を考慮しなくてよく、内側の変更もコンパイルエラーとなって直すべき箇所がすぐわかるようになるなど色々なメリットがあったりします。
個人的には経験豊富な比較的規模の大きいプロジェクトに向いていると思いますが、逆にちゃんと理解したリーダーと、メンバーへの共有、スキャフォールドのようなジェネレータ、テンプレがしっかりしていれば、書くべきコードの場所がはっきりするシンプル(単純)なので初心者向きとの意見もあるようです。
また、4層でなくてもいいというルール上、クリーンアーキテクチャの例の構成に必ずしも従う必要はなく、依存性逆転の原則を守りつつプロジェクトにあった最低限の構成(ドメインとそれ以外など)で関心の分離と冗長さのバランスを持って構成を考えてもいいと思います。
ここまでで、アーキテクチャについての話が出た時に少しでも理解できる助けになっていれば嬉しいです。
必要なシーンが来た時に以下と相談して検討する選択肢として思い出してもらえればと思います。
- チームの規模
- メンバーのスキル
- ソリューションの複雑さ
- 時間や予算
入門ということでクリーンアーキテクチャほんの一部の紹介でしたが、紹介できていない原則やプラクティスがかなり多く、クリーンアーキテクチャを導入する/しないに関わらず参考になる話が多いので興味があれば読んでみてください。