はじめに
本記事では、Azure AI Document Intelligence(以降:Document Intelligence)をご紹介します。
Document Intelligenceは文書内のテキスト、表、画像を認識し、それらの構造をメタデータとして提供するサービスです。
PDFファイルなどから単に文字起こしするだけでなく、テキストの階層構造や表、画像の座標情報といった文書のメタデータも出力できることから、社内ナレッジの利活用をより高度に促進することができます。
Document Intelligenceの機能
Document Intelligenceは2つの機能を持っています。

文書解析(文字起こし)
PDFファイルを入力すると、ファイル内のテキスト、表、画像を認識して各データの内容や構造、位置情報などをjson形式で返します。
実際にDocument Intelligenceに入力したPDFファイルと出力結果の例が以下です。
(※出力結果の行数が多いため大項目以下は非表示)

出力結果(json)の中で特に重要なものを解説します。
テキスト情報:Content
PDFファイル内のテキストを文字起こしした結果が格納されています。
オプションによって、出力するテキストをMarkdown形式にするか選択できます。
# Document Intelligence を使ってみよう!
## はじめに
Document Intelligence を使えば単純な文字起こしだけでなく、文書構造も理解してメタデータも出
力してくれるよ!
## できること
具体的には、文書の見出しと本文を見分けて Markdown 形式で出力ができます。
このとき、表情報も一緒に Markdown 化して出力してくれます。
<table>
<tr>
<th>項目</th>
<th>詳細</th>
</tr>
<tr>
<td>対応ファイル形式</td>
<td>PDF、JPEG、JPG、PNG、BMP、TIFF、 HEIF. DOCX. XLSX. PPTX. HTML</td>
</tr>
<tr>
<td>課金体系</td>
<td>入力したページ数に応じた従量課金</td>
</tr>
</table>
<figure>
6
5
4
3
2
1
0
分類 1
分類 2
分類 3
分類 4
系列 1
系列 2
■系列 3
</figure>
出力結果をみると、見出しと本文が区別されており、見出し同士の階層構造も正確にとらえられています。
表はtableタグで表現されているため、セル結合されているような表でも正確に表構造をとらえることができます。
また、画像内から抽出した文字情報はfigureタグ内に記述されており、不要な場合は容易に削除することができます。
表情報:tables
表のメタ情報はtablesタグから取得できます。
Markdownに整形された表情報はすでにcontentタグ内に含まれているため、セル単位で個別に処理を行いたい場合に役立ちます。
例えば、kindタグを使用すると、表のヘッダーかどうかを判断するできるため、レンダリング時にヘッダーだけスタイルを変えることができます。

画像情報:figures
画像のメタ情報はfiguresタグから取得できます。
Document Intelligenceは認識した画像そのものを提供することはありません。そのため、認識した画像をPDFファイルから切り抜きたい場合は、画像の位置情報を利用してトリミングする処理を用意する必要があります。

polygonタグ内の数値はいずれもインチ単位で記述されています。
画像をトリミングする際は最終的にピクセル座標に変換する必要があり、その過程でページ全体に対する相対位置の情報が欲しくなると思います。
このとき、ページ全体のサイズ(インチ単位)はpageタグに含まれているため確認してみてください。
文書分類
PDFファイルを入力すると、カスタムモデルを使ってユーザ定義のクラスに文書分類することができます。
本記事では論文、条例、webページの3クラスを作成し、入力したPDFファイルがどの文書クラスに最も近しいか推論させます。
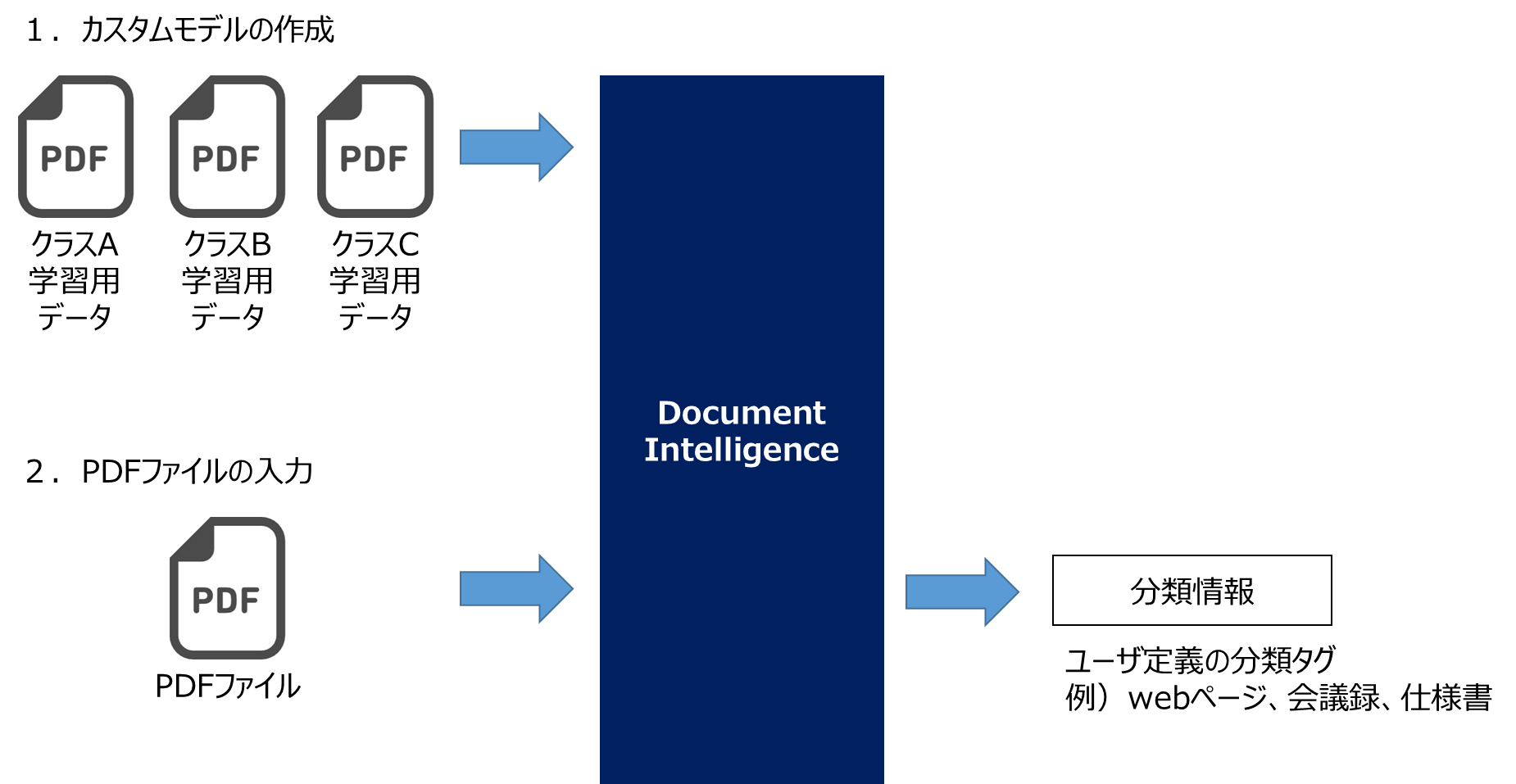
1.カスタムモデルの作成
カスタムモデルの作成には、各クラスごとに学習データが5ファイルずつ必要になります。
今回は論文、条例、webページの3クラス作成するので、最低でも15ファイル用意します。
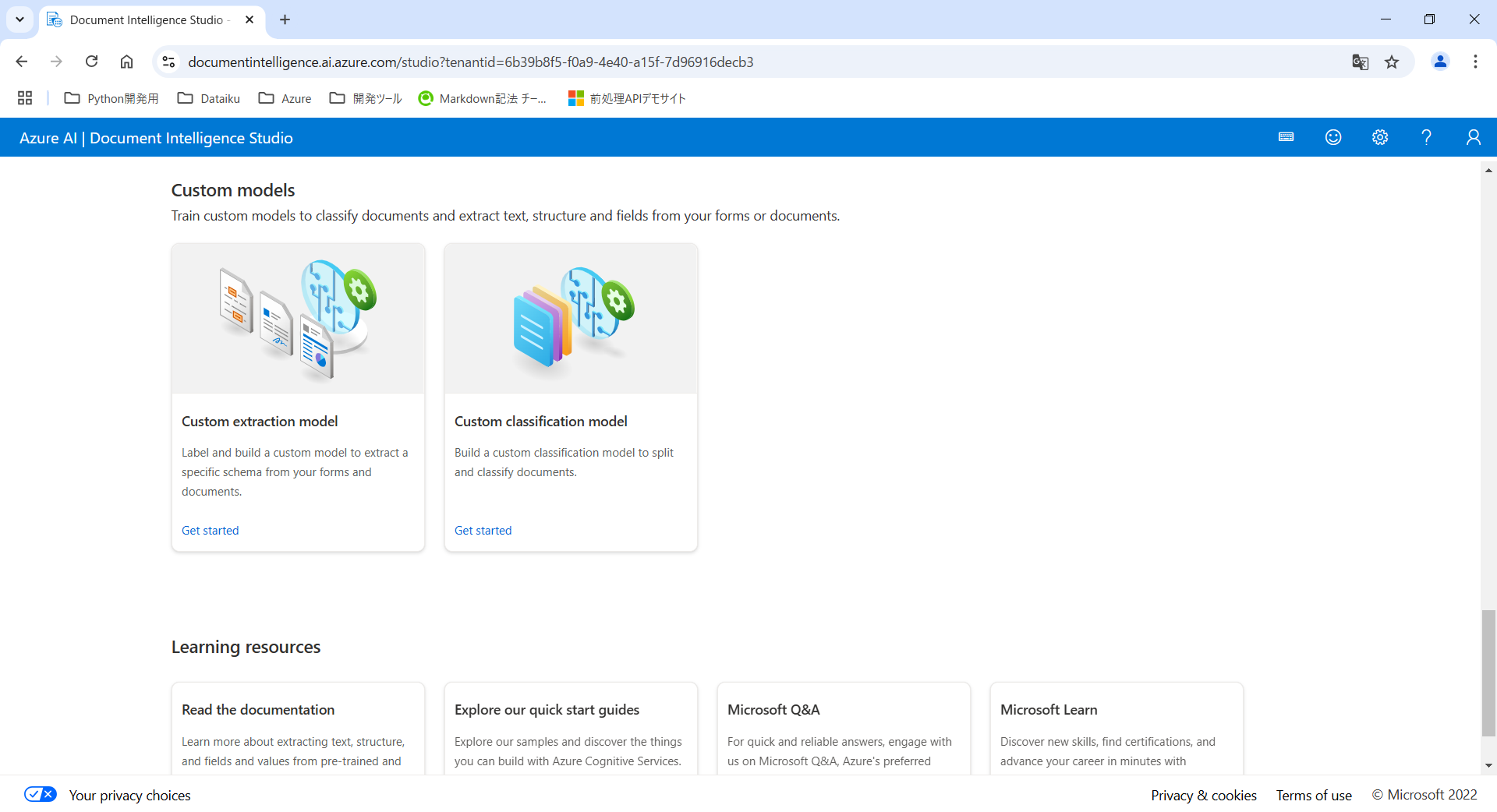
学習データが用意出来たら、Document Intelligence Studioからカスタムモデルを作成していきます。
Document Intelligence Studioの「Custom classification model」を選択してカスタムモデルの作成画面へ遷移します。
「Create a project」を押下して、新しいプロジェクトを作成します。
この時、学習データとしてBlob Storageのコンテナーを指定することができるので、あらかじめBlob Storageにアップロードしておきましょう。

プロジェクトが作成できるとカスタムモデルの学習もできるようになります。
学習用データを追加したり、クラスの再設定(画面ではtypeと表示されている)を行うことができます。

これで準備完了です。
2.PDFファイルの入力
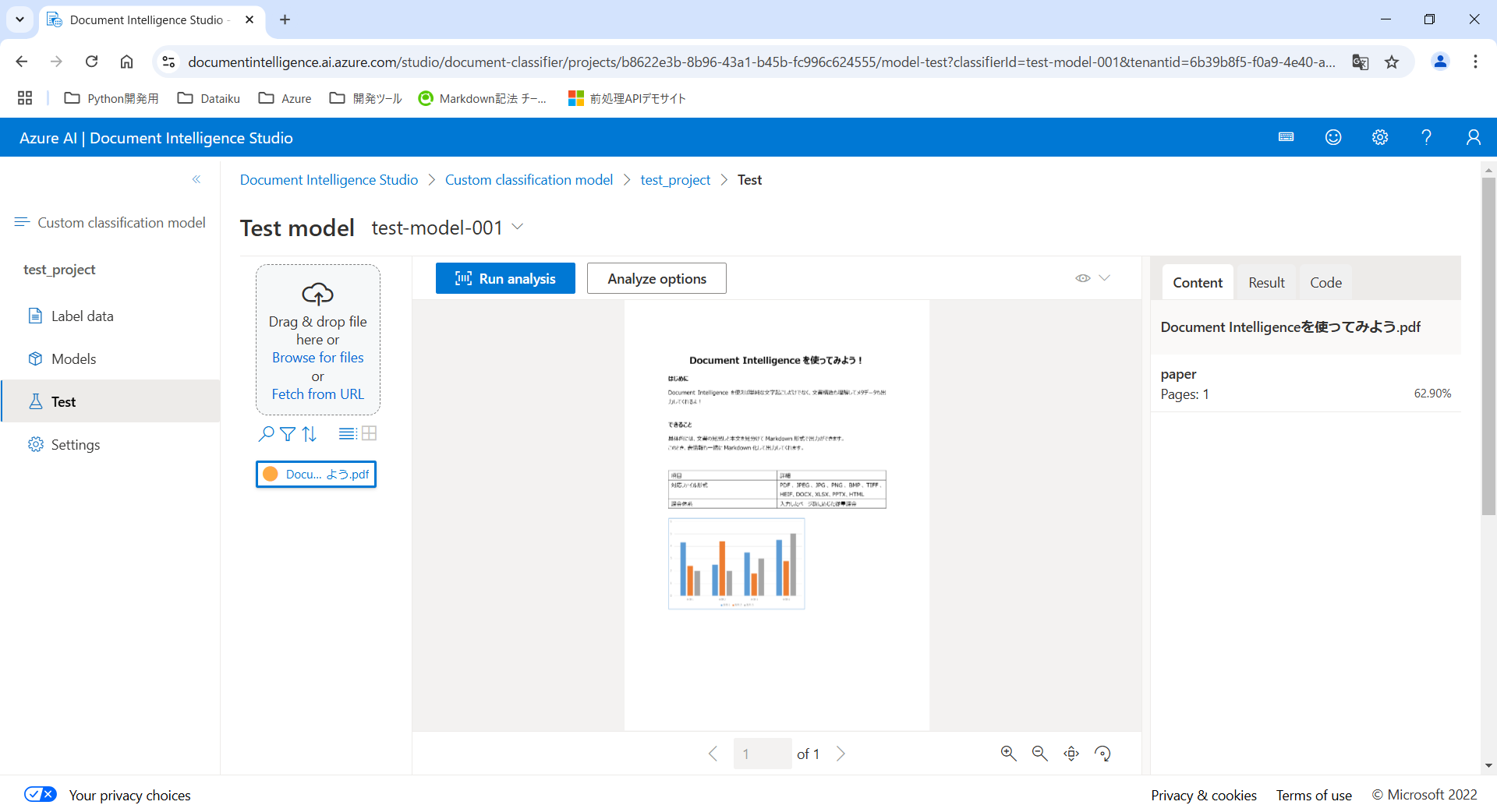
「Test」タブから学習済みのカスタムモデルに推論させることができます。
推論の結果はページごとに出力されます。(今回は1ページしかないPDFファイルだったため、結果も1つ)
画面右側のContentタブに出力されている結果を確認すると、アップロードしたPDFファイルはpaper(論文)形式と判断されたようです。