はじめに
入力変数とその応答値からなるデータが複数与えられていた場合、その関連性を調査するために回帰分析をするということがよくある。回帰分析とは、複数のデータからそれらが満たすであろう関係性を推定して単純な曲線(曲面)式で表すというものである。今回は、その回帰分析のなかで最も基礎となるデータを一次関数で近似する線形単回帰分析を最急降下法を用いることで実現する。具体的には、同じ入力変数における近似曲線(今回は直線)上にある点と応答値の偏差より2乗誤差を求め、その値を最急降下法により最小化することで、最適な近似曲線(今回は直線)のパラメータを推定する。
以下、簡単に結果を述べる。線形回帰曲線のパラメータを推定するために、以下のような2乗誤差と曲線のパラメータの関係性をグラフ化した。
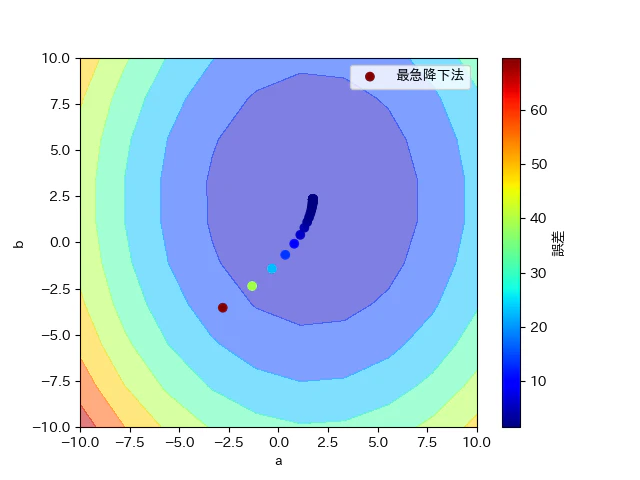
このグラフより、試行回数を増やすほど、最小値付近を推移することが最急降下法により可能であることが分かる。
そして、上記のようにして求めたパラメータから近似曲線を求めると以下のようになった。
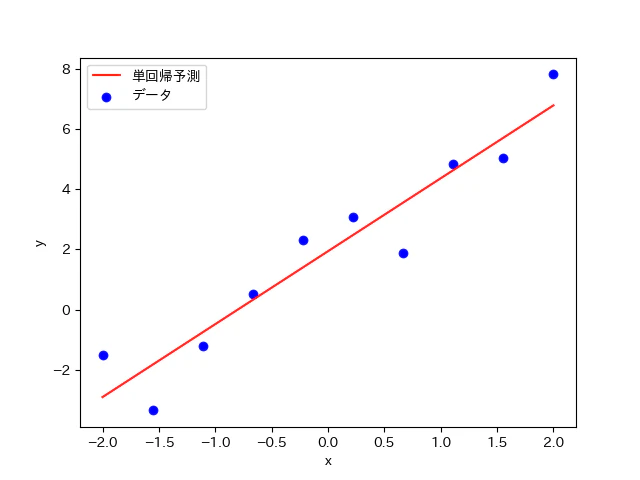
データセット
データセットとしては、y=2x+2をベースとして、np.random.normalを用いて、平均0,分散1となるような乱数を加算した10点を用いた。
(プログラムについては後述する)

原理
単回帰分析
単回帰分析のアルゴリズムについて完結に述べる。
$m$個の点$(x_1,y_1),(x_2,y_2),\cdot\cdot\cdot(x_m,x_m)$が存在してそれの近似曲線を構築したいとする。
近似曲線を$y=f(x)=ax+b$という直線として考えると、$x=x_i$のときの実際の値と予測の値には2乗偏差$err(i)=(y_i-f(x_i))^2$が生じる。したがって、以下の誤差についての損失関数を最小化させることができれば、最適な近似関数を求めることができるはずである。
Error(a,b)=\frac{1}{m}\Sigma^{m}_{i=1} err(i)=\frac{1}{m}\Sigma^{m}_{i=1}(y_i-f(x_i))^2=\frac{1}{m}\Sigma^{m}_{i=1}(y_i-ax_i-b)^2
上記の$Error(a,b)$は$a,b$の2変数関数なので、本来は偏微分を行うことで最小値を求める。以下、参考までに偏微分を用いた解法を示す。
参考:偏微分を用いた解法
$\frac{\delta }{\delta a}Error(a,b)=0$かつ$\frac{\delta}{\delta b}Error(a,b)=0$を同時に満たす$(a,b)$を求める。
\frac{\delta }{\delta a}Error(a,b)=\frac{2}{m}\Sigma^{m}_{i=1}x_i(y_i-ax_i-b)=\frac{2}{m}(\Sigma^{m}_{i=1}x_iy_i-a\Sigma^{m}_{i=1}x_i^2-b\Sigma^{m}_{i=1}x_i)=0
一方で、
\frac{\delta }{\delta b}Error(a,b)=\frac{-2}{m}\Sigma^{m}_{i=1}(y_i-ax_i-b)=\frac{-2}{m}(\Sigma^{m}_{i=1} y_i -a\Sigma^{m}_{i=1} x_i-b\Sigma^{m}_{i=1}1)=0
したがって、以下のような式を得ることができる。
\begin{pmatrix}
\Sigma^{m}_{i=1}x_i^2 & \Sigma^{m}_{i=1}x_i \\
\Sigma^{m}_{i=1}x_i & m \\
\end{pmatrix}
\begin{pmatrix}
a \\
b \\
\end{pmatrix}
=
\begin{pmatrix}
\Sigma^{m}_{i=1}x_iy_i \\
\Sigma^{m}_{i=1}y_i \\
\end{pmatrix}
この方程式より$(a,b)$を求めることができて、この方程式はクラメルの公式を用いることで陽的に解くことができる。
まず、
\begin{vmatrix}
\Sigma^{m}_{i=1}x_i^2 & \Sigma^{m}_{i=1}x_i \\
\Sigma^{m}_{i=1}x_i & m \\
\end{vmatrix}
=m(\Sigma^{m}_{i=1}x_i^2)-( \Sigma^{m}_{i=1}x_i)^2=m^2\{\frac{1}{m}\Sigma^{m}_{i=1}x_i^2-\frac{1}{m^2}(\Sigma^{m}_{i=1}x_i^2)\}=m^2S_x
一方で、
\begin{vmatrix}
\Sigma^{m}_{i=1}x_iy_i & \Sigma^{m}_{i=1}x_i \\
\Sigma^{m}_{i=1}y_i & m \\
\end{vmatrix}
=m(\Sigma^{m}_{i=1}x_iy_i)-( \Sigma^{m}_{i=1}x_i \Sigma^{m}_{i=1}y_i)=m^2\{\frac{1}{m}\Sigma^{m}_{i=1}x_iy_i-(\frac{1}{m}\Sigma^{m}_{i=1}x_i)( \frac{1}{m}\Sigma^{m}_{i=1}y_i)\}=\bar{xy}-\bar{x}\bar{y}=S_{xy}
したがって、
a=\frac{\begin{vmatrix}
\Sigma^{m}_{i=1}x_iy_i & \Sigma^{m}_{i=1}x_i \\
\Sigma^{m}_{i=1}y_i & m \\
\end{vmatrix}}{\begin{vmatrix}
\Sigma^{m}_{i=1}x_i^2 & \Sigma^{m}_{i=1}x_i \\
\Sigma^{m}_{i=1}x_i & m \\
\end{vmatrix}}=\frac{S_{xy}}{S_{xx}}
一方で、
b=\frac{\begin{vmatrix}
\Sigma^{m}_{i=1}x_i^2 & \Sigma^{m}_{i=1}x_iy_i \\
\Sigma^{m}_{i=1}x_i & \Sigma^{m}_{i=1}y_i \\
\end{vmatrix}}{\begin{vmatrix}
\Sigma^{m}_{i=1}x_i^2 & \Sigma^{m}_{i=1}x_i \\
\Sigma^{m}_{i=1}x_i & m \\
\end{vmatrix}}
=\frac{\Sigma^{m}_{i=1}x_i^2 \Sigma^{m}_{i=1}y_i-\Sigma^{m}_{i=1}x_iy_i \Sigma^{m}_{i=1}x_i}{m\Sigma^{m}_{i=1}x_i^2-(\Sigma^{m}_{i=1}x_i)^2}=\frac{\Sigma^{m}_{i=1}x_i^2 m\bar{y}-\Sigma^{m}_{i=1}x_iy_i\bar{x}m }{m\Sigma^{m}_{i=1}x_i^2-(\Sigma^{m}_{i=1}x_i)^2}
=\frac{(\Sigma^{m}_{i=1}x_i^2 m-(\Sigma^{m}_{i=1}x_i^2)^2)\bar{y}+(m\bar{x})^2- \bar{y}\Sigma^{m}_{i=1}x_iy_i\bar{x}m }{m\Sigma^{m}_{i=1}x_i^2-(\Sigma^{m}_{i=1}x_i)^2}
=\bar{y}-\frac{-(m\bar{x})^2\bar{y}+m\bar{x}\Sigma^{m}_{i=1}x_iy_i}{m\Sigma^{m}_{i=1}x_i^2-(\Sigma^{m}_{i=1}x_i)^2}=\bar{y}-\frac{-m^2 \bar{x}\bar{y}+m \Sigma^{m}_{i=1}x_iy_i}{m\Sigma^{m}_{i=1}x_i^2-(\Sigma^{m}_{i=1}x_i)^2}=\bar{y}-a\bar{x}
まとめると、
(a,b)=(\frac{S_{xy}}{S_{xx}},\bar{y}-a\bar{x})
ただし、$x$の分散$S_{xx}=\bar{x^2}-(\bar{x})^2$とx,yの共分散$S_{xy}=\bar{xy}-\bar{x}\bar{y}$を用いた。(導出方法は、参考文献を参照して欲しい。)
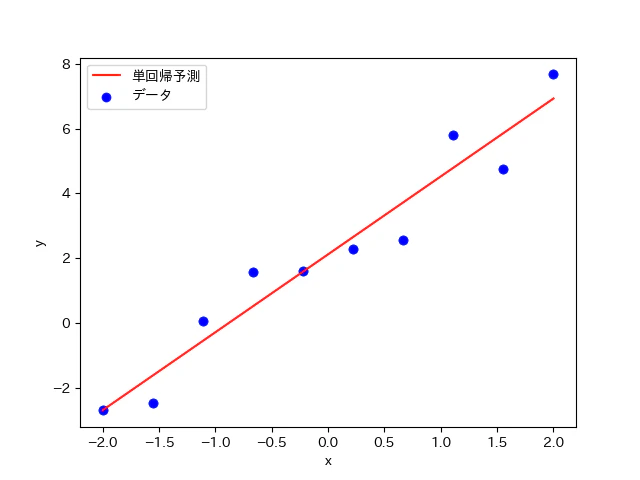
理論式のプログラム
さて、前座として、上記の$(a,b)$を用いて以下のようなプログラムを作成した。
import numpy as np
import matplotlib.pyplot as plt
import japanize_matplotlib
import math
num=10
x=np.linspace(-2,2,num)
y=(2*x+2)+np.random.normal(0,1,num)
plt.scatter(x,y)
#a,bベクトルの共分散を求める関数
def S(a,b):
sum = 0
A=0
B=0
for i in range(len(a)):
#a,bベクトルの要素の平均値A,B
A += a[i]/len(a)
B += b[i]/len(a)
c= a[i]*b[i]/len(a)
sum += c
return (sum)-A*B
#線形単回帰の理論式
a=S(x,y)/S(x,x)
b=np.mean(y)-a*np.mean(x)
plt.scatter(x,y,label="データ",color="blue")
plt.plot(x,a*x+b,label="単回帰予測",color="red")
plt.legend()
plt.xlabel("x")
plt.ylabel("y")
plt.savefig("線形回帰予測_理論式.png")
plt.show()
最急降下法を用いた線形単回帰分析
今回は$Error(a,b)$の最小値を求めるのに以下のような最急降下法を用いた。というのは、近似する関数が変われば(例えば、一次関数から二次関数)上記の$(a,b)$の解は使えなくなってしまい柔軟性がないからである。
また、二乗偏差を最小化するというシンプルなアルゴリズムを追求したいという面から、以下のような最急降下法を用いた。(いずれも、偏微分を用いて損失関数の最小値を求めているという点は変わらないが。)
発展的な内容になるが、ある位置$x$における実際の値と近似モデルによる推定値の分布が平均0の正規分布に従っているという仮定を用いても近似曲線を推定することができる。
おおまかなイメージとしては、全ての応答値とそれに対応する推定値の偏差の大きさが0に近いほど大きくなる確率密度関数を用いて、それを最大化させるという手法である。
ご存じのとおり、確率密度関数は0から1になり、確率の積の法則を多用するという考えから対数を評価として使うことが多い。
最急降下法
解空間の最小値を取る極値が一つ解空間の谷が一つの場合に有効な最小値の推定手法である。$(a,b)$に初期値を与え、以下のような式を用いて$(a,b)$を更新していく。つまり、$(a_k,b_k)$を算出する。
a_{k+1}=a_{k}-\alpha(\frac{\delta }{\delta a_{i}}Error(a_{k},b_{k}))
b_{k+1}=b_{k}-\beta(\frac{\delta }{\delta b_{k}}Error(a_k,b_k))
ただし$\alpha,\beta$は$(a,b)$の学習率である。
これは、以下のグラフのようにボールが坂に下り落ちる様に似ている。偏微分係数は各方向の坂の傾きと捉えることができる。

プログラム
最急降下法による2乗誤差の最小値推定プログラムと単回帰プログラムを以下に示す。
2乗誤差の曲面と最急降下法
import numpy as np
import matplotlib.pyplot as plt
import japanize_matplotlib
import math
num=10
x=np.linspace(-2,2,num)
y=(2*x+2)+np.random.normal(0,1,num)
#plt.scatter(x,y)
h=1.0*10**-5
def error(a,b):
err=0
for i in range(num):
err=err+(1/num)*(y[i]-(a*x[i]+b))**2
return err
iterations=100
#初期値
a=-5
b=-5
alpha=0.1
beta=0.1
a_pre=[]
b_pre=[]
error_pre=[]
for i in range(iterations):
d_err_a=(error(a+h,b)-error(a,b))/h
d_err_b=(error(a,b+h)-error(a,b))/h
a=a-alpha*d_err_a
b=b-beta*d_err_b
a_pre.append(a)
b_pre.append(b)
error_pre.append(error(a,b))
n=10
a_ary=np.linspace(-10,10,n)
b_ary=np.linspace(-10,10,n)
A,B=np.meshgrid(a_ary,b_ary)
Errors=np.zeros((n,n))
for i in range(n):
for k in range(n):
Errors[i][k]=error(A[i][k],B[i][k])
plt.contourf(A,B,Errors,cmap="jet",alpha=0.5)
plt.scatter(a_pre,b_pre,c=error_pre,cmap="jet",label="最急降下法")
plt.legend()
plt.colorbar(label="誤差")
plt.xlabel("a")
plt.ylabel("b")
plt.savefig("線形回帰2乗誤差と最急降下法.png")
plt.show()

このように、$(a,b)=(-5,-5)$という初期値から目標値である$(a,b)=(2,2)$に漸近していく様子が分かる。また、損失関数(誤差の2乗値)は、まるで二次関数のような放物線に似ているので最小値は一つであるということがグラフから読み取れる。このことから、最急降下法による極小値の探索により最小値を求めることが妥当であるといえる。
回帰分析
import numpy as np
import matplotlib.pyplot as plt
import japanize_matplotlib
import math
num=10
x=np.linspace(-2,2,num)
y=(2*x+2)+np.random.normal(0,1,num)
#plt.scatter(x,y)
h=1.0*10**-5
def error(a,b):
err=0
for i in range(num):
err=err+(1/num)*(y[i]-(a*x[i]+b))**2
return err
iterations=100
#初期値
a=-5
b=-5
alpha=0.1
beta=0.1
a_pre=[]
b_pre=[]
error_pre=[]
for i in range(iterations):
d_err_a=(error(a+h,b)-error(a,b))/h
d_err_b=(error(a,b+h)-error(a,b))/h
a=a-alpha*d_err_a
b=b-beta*d_err_b
a_pre.append(a)
b_pre.append(b)
error_pre.append(error(a,b))
plt.scatter(x,y,label="データ",color="blue")
plt.plot(x,a*x+b,label="単回帰予測",color="red")
plt.legend()
plt.xlabel("x")
plt.ylabel("y")
plt.savefig("線形回帰予測.png")
plt.show()
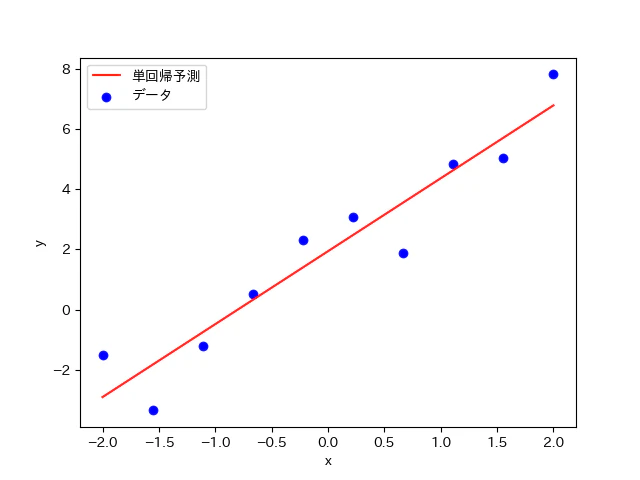
最急降下法により得られた(a,b)の最適値を用いて近似曲線(直線)を作成すると上記のようなグラフになった。上手く、近似曲線を描写することが出来ているということが視覚的に見て取れる。また、全ての点から『均等に』バランスのとれた位置に近似曲線が配置されているということも分かる。
ただし、今回の近似が上手く機能したのは、誤差が正規分布に従うという仮定をしたからである。例えば、一点だけ外れ値が存在してしまうと、極端な値の点の影響を大きく受けるため上手く近似曲線が描写できなくなる。無論、解となる曲線が線形関数で無い場合は、近似モデルを修正する必要性もある。
まとめ
今回は、最急降下法を用いて線形単回帰分析を行うことができるか考察した。結果、データのばらつき誤差(np.random.normalで再現したもの)が正規分布に従うポピュラーなものであれば十分に回帰分析を行うことが可能であるということがわかった。ただし、実際の推定の場合、今回のように線形もしくは多項式関数で表される場合は少ないと考えられるので、様々な条件に対応することができるようなアルゴリズムの汎用性を高めることが重要であると考えられる。
参考
二次式での近似
参考として二次関数の回帰予測を行ってみた。
プログラム
import numpy as np
import matplotlib.pyplot as plt
import japanize_matplotlib
import math
num=10
x=np.linspace(-2,2,num)
y=(2*x**2+x+2)+np.random.normal(0,1,num)
#plt.scatter(x,y)
h=1.0*10**-5
def error(a,b,c):
err=0
for i in range(num):
err=err+(1/num)*(y[i]-(a*x[i]**2+b*x[i]+c))**2
return err
iterations=100
#初期値
a=-5
b=-5
c=-5
alpha=0.1
beta=0.1
gamma=0.1
a_pre=[]
b_pre=[]
c_pre=[]
error_pre=[]
for i in range(iterations):
d_err_a=(error(a+h,b,c)-error(a,b,c))/h
d_err_b=(error(a,b+h,c)-error(a,b,c))/h
d_err_c=(error(a,b,c+h)-error(a,b,c))/h
a=a-alpha*d_err_a
b=b-beta*d_err_b
c=c-gamma*d_err_c
a_pre.append(a)
b_pre.append(b)
c_pre.append(c)
error_pre.append(error(a,b,c))
plt.scatter(x,y,label="データ",color="blue")
plt.plot(x,a*x**2+b*x+c,label="2次関数の回帰予測",color="red")
plt.legend()
plt.xlabel("x")
plt.ylabel("y")
plt.savefig("2次関数の回帰予測.png")
plt.show()

このように、最急降下法を用いて誤差関数(損失関数)を最小化するアルゴリズムは汎用的であるということが分かる。
重回帰
最後に、上記のアルゴリズムの次元を拡張して、3次元の重回帰にも挑戦する。
以下のようなプログラムを書いた。
import numpy as np
import matplotlib.pyplot as plt
import japanize_matplotlib
import math
n=10
rng = np.random.default_rng()
L=2.0
x1=rng.uniform(-L, L, n)
x2=rng.uniform(-L, L, n)
y=5*x1+4*x2+3+np.random.randn(n)
#生データ(プロット)の表示
# plt.scatter(x1,x2,c=y)
# plt.show()
#微分の微小区間の定義
h=1.0*10**-5
#誤差関数の定義
def error(a,b,c):
err_vec=a*x1+b*x2+c-y
err_2=err_vec@err_vec
return err_2
iterations=100
#初期値
a=1
b=1
c=1
#最急降下法
#学習率
alpha=0.02
beta=0.02
gamma=0.02
a_pre=[]
b_pre=[]
c_pre=[]
error_pre=[]
i_ary=[]
for i in range(iterations):
i_ary.append(i+1)
d_err_a=(error(a+h,b,c)-error(a,b,c))/h
d_err_b=(error(a,b+h,c)-error(a,b,c))/h
d_err_c=(error(a,b,c+h)-error(a,b,c))/h
a=a-alpha*d_err_a
b=b-beta*d_err_b
c=b-gamma*d_err_c
a_pre.append(a)
b_pre.append(b)
c_pre.append(c)
error_pre.append(error(a,b,c))
#誤差関数と積算回数の関係
#plt.plot(i_ary,error_pre)
#plt.savefig("誤差関数と積算回数の関係.png")
#plt.show()
x=np.linspace(-L,L,100)
y_1=np.linspace(-L,L,100)
X,Y=np.meshgrid(x,y_1)
Z=a*X+b*Y+c
plt.contourf(X,Y,Z,cmap="jet",alpha=0.5)
plt.scatter(x1,x2,c=y,cmap="jet")
plt.colorbar(label="重回帰応答面")
plt.xlabel("x1")
plt.ylabel("x2")
plt.savefig("最急降下法による重回帰.png")
plt.show()
これを実行すると以下のようなグラフが出力される。

このように、上手く近似曲面を描写することができていることが分かる。
一方で、コメントアウトを外すと以下のような、グラフが出力される。

横軸が計算の積算回数(最急降下法の実行ステップ回数)で縦軸が損失関数(誤差関数)である。
このように、積算回数を増やすほど、損失関数の値が低下していることが分かる。このことから、近似精度は積算回数が向上するにつれて良くなることが分かる。
参考文献
線形単回帰と最小二乗法について
分散の公式
共分散の公式