こちらは「Applibot Advent Calendar 2022」24日目の記事になります。
はじめに
C#ではforとforeachで速度差があることをご存じでしょうか。
この2つで内部挙動に差があることはよく耳にすると思います。
しかし、その違いを知る機会は少ないと思います。
なので、社会人になり本格的にC#を触るようになったこともあり、この機会に調べてみました。
間違っている箇所があれば指摘していただけるとありがたいです。
検証内容は配列、List、IReadOnlyListのそれぞれで下の2つ差分で検証しています。
- forとforeachの違い
- ループ対象の変数をローカルにコピーした場合
また、配列のみ加算対象がメンバ変数の時の差も調べています。
先に結果を載せておきます。
それぞれで一番速度が速かったものです。
- 配列はforeach
- Listはローカルコピーでfor
- IReadOnlyはローカルコピーでfor
これを覚えてくだされば大丈夫です。(だたし、環境が違う場合は要検証)
環境
- Windows10
- VisualStudio 2022
- Intel(R) Core(TM) i7-10875H
- C# 10.0 + .Net 6.0
- BenchmarkDotNet 0.13.2
出力データ
BenchmarkDotNet=v0.13.2, OS=Windows 10 (10.0.19045.2251)
Intel Core i7-10875H CPU 2.30GHz, 1 CPU, 16 logical and 8 physical cores
.NET SDK=7.0.100
[Host] : .NET 6.0.11 (6.0.1122.52304), X64 RyuJIT AVX2
.NET 6.0 : .NET 6.0.11 (6.0.1122.52304), X64 RyuJIT AVX2
.NET 7.0 : .NET 7.0.0 (7.0.22.51805), X64 RyuJIT AVX2
| Method | Mean | Error | StdDev | Allocated |
|---|---|---|---|---|
| ArrayFor | 14.032 μs | 0.2708 μs | 0.2533 μs | - |
| LocalArrayFor | 13.216 μs | 0.2589 μs | 0.2542 μs | - |
| ArrayForFieldValue | 34.746 μs | 0.6916 μs | 0.9696 μs | - |
| ArrayForEachFieldlValue | 34.770 μs | 0.3062 μs | 0.2557 μs | - |
| ArrayForEach | 9.648 μs | 0.1779 μs | 0.1664 μs | - |
| ListFor | 15.352 μs | 0.2841 μs | 0.2658 μs | - |
| LocalListFor | 15.350 μs | 0.2931 μs | 0.3375 μs | - |
| ListForEach | 20.116 μs | 0.3503 μs | 0.3106 μs | - |
| ReadOnlyListFor | 100.029 μs | 1.9233 μs | 2.2149 μs | - |
| LocalReadOnlyListFor | 98.124 μs | 1.0369 μs | 0.9192 μs | - |
| ReadOnlyListForEach | 153.840 μs | 2.3202 μs | 2.1704 μs | 40 B |
検証
コード全文
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Jobs;
using BenchmarkDotNet.Running;
using System;
using System.Collections.Generic;
BenchmarkRunner.Run<ArrayTest>();
[HtmlExporter]
[MemoryDiagnoser]
[MinColumn, MaxColumn]
public class ArrayTest
{
public int[] _array;
public List<int> _list;
public IReadOnlyList<int> _readonlyList;
private int _sum1;
private int _sum2;
public ArrayTest()
{
_array = Enumerable.Range(0, 20000).ToArray();
_list = _array.ToList();
_readonlyList = _list;
}
[Benchmark]
public int ArrayFor()
{
var buf = 0;
for (int i = 0; i < _array.Length; i++)
{
buf += _array[i];
}
return buf;
}
[Benchmark]
public int LocalArrayFor()
{
var buf = 0;
var array = _array;
for (int i = 0; i < array.Length; i++)
{
buf += array[i];
}
return buf;
}
[Benchmark]
public int ArrayForFieldValue()
{
var array = _array;
for (int i = 0; i < array.Length; i++)
{
_sum1 += array[i];
}
return _sum1;
}
[Benchmark]
public int ArrayForEachFieldlValue()
{
var array = _array;
foreach (int value in array)
{
_sum2 += value;
}
return _sum2;
}
[Benchmark]
public int ArrayForEach()
{
var buf = 0;
foreach (int value in _array)
{
buf += value;
}
return buf;
}
[Benchmark]
public int ListFor()
{
var buf = 0;
for (int i = 0; i < _list.Count; i++)
{
buf += _list[i];
}
return buf;
}
[Benchmark]
public int LocalListFor()
{
var buf = 0;
var list = _list;
for (int i = 0; i < list.Count; i++)
{
buf += list[i];
}
return buf;
}
[Benchmark]
public int ListForEach()
{
var buf = 0;
foreach (int value in _list)
{
buf += value;
}
return buf;
}
[Benchmark]
public int ReadOnlyListFor()
{
var buf = 0;
for (int i = 0; i < _readonlyList.Count; i++)
{
buf += _readonlyList[i];
}
return buf;
}
[Benchmark]
public int LocalReadOnlyListFor()
{
var buf = 0;
var readolnlyList = _readonlyList;
for (int i = 0; i < _readonlyList.Count; i++)
{
buf += readolnlyList[i];
}
return buf;
}
[Benchmark]
public int ReadOnlyListForEach()
{
var buf = 0;
foreach (int value in _readonlyList)
{
buf += value;
}
return buf;
}
}
ILはSharpLabで比較
SharpLab
アセンブラはLINQPad、x64のものを載せています。
自分が気になった物をピックアップして考察していきます。
配列をローカルにコピーした時の比較
| Method | Mean | Error | StdDev | Allocated |
|---|---|---|---|---|
| ArrayFor | 14.032 μs | 0.2708 μs | 0.2533 μs | - |
| LocalArrayFor | 13.216 μs | 0.2589 μs | 0.2542 μs | - |
public int ArrayFor()
{
var buf = 0;
for (int i = 0; i < _array.Length; i++)
{
buf += _array[i];
}
return buf;
}
public int LocalArrayFor()
{
var buf = 0;
var array = _array;
for (int i = 0; i < array.Length; i++)
{
buf += array[i];
}
return buf;
}
ローカルにコピーした方(LocalArrayFor)が早いです。
これはループ毎に配列を取得しに行く命令とfor文の境界値チェックの差になります。
メンバ変数の場合ループ毎に配列の中身を取得しに行く必要があります。
ローカル変数の場合はずっと同じ個所を参照すればよいので、これを短縮できます。
境界値チェックとは
C#のループ文では配列外を参照していないか判定を行っています。これが境界値チェックです。
このチェックは配列外へ参照する可能性が無い場合に無くすことができます。
ローカル変数の場合は関数内の使用が保証されます。
しかし、メンバ変数の場合マルチスレッドで書き換わる可能性があります。
よってローカル変数を使うことで、境界値チェックが無くなるということです。
アセンブラで比較部分が省略されていることが確認できます。
該当アセンブラ
ArrayFor
L0000 sub rsp, 0x28
L0004 xor eax, eax
L0006 xor edx, edx
L0008 mov rcx, [rcx+8]
L000c cmp dword ptr [rcx+8], 0
L0010 jle short L0038
L0012 nop [rax]
L0019 nop [rax]
L0020 mov r8, rcx
L0023 cmp edx, [r8+8]
L0027 jae short L003d
L0029 movsxd r9, edx
L002c add eax, [r8+r9*4+0x10]
L0031 inc edx
L0033 cmp [rcx+8], edx // ここが比較部分
L0036 jg short L0020 // ここが比較部分
L0038 add rsp, 0x28
L003c ret
L003d call 0x00007ff80accf540
L0042 int3
LocalArrayFor
L0000 xor eax, eax
L0002 mov rdx, [rcx+8]
L0006 xor ecx, ecx
L0008 mov r8d, [rdx+8]
L000c test r8d, r8d
L000f jle short L0020
L0011 movsxd r9, ecx
L0014 add eax, [rdx+r9*4+0x10]
L0019 inc ecx
L001b cmp r8d, ecx
L001e jg short L0011
L0020 ret
配列のforとforeachの比較
| Method | Mean | Error | StdDev | Allocated |
|---|---|---|---|---|
| LocalArrayFor | 13.216 μs | 0.2589 μs | 0.2542 μs | - |
| ArrayForEach | 9.648 μs | 0.1779 μs | 0.1664 μs | - |
public int LocalArrayFor()
{
var buf = 0;
var array = _array;
for (int i = 0; i < array.Length; i++)
{
buf += array[i];
}
return buf;
}
public int ArrayForEach()
{
var buf = 0;
foreach (int i in _array)
{
buf += i;
}
return buf;
}
foreachの方が早いです。
違う点は加算の仕方になります。
LocalArrayForは配列の要素をそのまま加算している、ArrayForEachは配列の要素を専用の変数にコピーして、その変数を使って加算している点です。
つまり、ArrayForEachは加算前専用の変数が必要になります。
変数を確保する分少しだけ遅くなっているということです。
また、LocalArrayForEach関数を作って比較するべきと思いましたが、ArrayForEachと同じILだったためそのまま比較しています。
foreachは配列の場合、for文と同等な速度になると思っていたのでこの結果は予想外でした。
おまけ
.NET 7.0では速度が改善されています。
| Method | Mean | Error | StdDev | Allocated |
|---|---|---|---|---|
| LocalArrayFor | 7.915 μs | 0.1551 μs | 0.1451 μs | - |
| ArrayForEach | 7.864 μs | 0.1531 μs | 0.1503 μs | - |
.NET 7.0でループの最適化があったようですが、今回とは関係がなさそうです。
for文のアセンブラを比較してみたところ、.Net 7.0ではmovでコピーしており、.Net 6.0ではmovsxdで符号拡張コピーしていたのでそこの差でしょうか。
LocalArrayForの.NET 6.0と.NET 7.0アセンブラ
.NET 6.0
L0000 xor eax, eax
L0002 mov rdx, [rcx+8]
L0006 xor ecx, ecx
L0008 mov r8d, [rdx+8]
L000c test r8d, r8d
L000f jle short L0020
L0011 movsxd r9, ecx // ここが変更点
L0014 add eax, [rdx+r9*4+0x10]
L0019 inc ecx
L001b cmp r8d, ecx
L001e jg short L0011
L0020 ret
.NET 7.0
L0000 xor eax, eax
L0002 mov rdx, [rcx+8]
L0006 xor ecx, ecx
L0008 mov r8d, [rdx+8]
L000c test r8d, r8d
L000f jle short L0020
L0011 mov r9d, ecx // ここが変更点
L0014 add eax, [rdx+r9*4+0x10]
L0019 inc ecx
L001b cmp r8d, ecx
L001e jg short L0011
L0020 ret
配列のforで加算対象がメンバ変数の場合の比較
| Method | Mean | Error | StdDev | Allocated |
|---|---|---|---|---|
| LocalArrayFor | 13.216 μs | 0.2589 μs | 0.2542 μs | - |
| ArrayForFieldValue | 34.746 μs | 0.6916 μs | 0.9696 μs | - |
public int LocalArrayFor()
{
var buf = 0;
var array = _array;
for (int i = 0; i < array.Length; i++)
{
buf += array[i];
}
return buf;
}
public int ArrayForFieldValue()
{
var array = _array;
for (int i = 0; i < array.Length; i++)
{
_sum1 += array[i];
}
return _sum1;
}
加算対象がローカル変数の方(LocalArrayFor)が早いです。
違いは加算時に加算される変数を取得しているところです。
ArrayForFieldValueはメンバ変数に加算する時、メンバ変数(_sum)を取得する命令が必要なので遅くなります。
ILで加算処理を見てみると差が出ていることが分かります。
IL
LocalArrayForの加算処理
IL_000d: ldloc.0 // buf
IL_000e: ldloc.1 // array
IL_000f: ldloc.2 // i
IL_0010: ldelem.i4 // array[i]
IL_0011: add // buf + array[i]
IL_0012: stloc.0 // buf = buf + array[i]
ArrayForFieldValueの加算処理
IL_000b: ldarg.0 // _sum1のポインタ
IL_000c: ldarg.0 // _sum1のポインタ
IL_000d: ldfld int32 ArrayTest::_sum1 // _sum1
IL_0012: ldloc.0 // array
IL_0013: ldloc.1 // i
IL_0014: ldelem.i4 // array[i]
IL_0015: add // _sum1 + array[i]
IL_0016: stfld int32 ArrayTest::_sum1 // _sum1 = _sum1 + array[i]
配列で加算対象がメンバ変数の時のfor,foreachの比較
| Method | Mean | Error | StdDev | Allocated |
|---|---|---|---|---|
| ArrayForFieldValue | 34.746 μs | 0.6916 μs | 0.9696 μs | - |
| ArrayForEachFieldValue | 34.770 μs | 0.3062 μs | 0.2557 μs | - |
public int ArrayForFieldValue()
{
var array = _array;
for (int i = 0; i < array.Length; i++)
{
_sum1 += array[i];
}
return _sum1;
}
public int ArrayForEachFieldlValue()
{
var array = _array;
foreach (int value in array)
{
_sum2 += value;
}
return _sum2;
}
こちらは速度が変わりません。
ILは違うものが生成されていますが、JIT Asmは同じになっていました。
ここまでの話を考えると違う中身になりそうなので驚きでした。
Listでローカルにコピーした場合の比較
| Method | Mean | Error | StdDev | Allocated |
|---|---|---|---|---|
| ListFor | 15.352 μs | 0.2841 μs | 0.2658 μs | 15.327 μs |
| LocalListFor | 15.350 μs | 0.2931 μs | 0.3375 μs | 15.371 μs |
public int ListFor()
{
var buf = 0;
for (int i = 0; i < _list.Count; i++)
{
buf += _list[i];
}
return buf;
}
public int LocalListFor()
{
var buf = 0;
var list = _list;
for (int i = 0; i < list.Count; i++)
{
buf += list[i];
}
return buf;
}
Listのメンバ変数の配列を使っている物(ArrayFor)とローカル変数にコピーしたもの(LocalArrayFor)の比較です。
forの方が早いです。
理由は配列を取得する命令の差です。
配列と同じようにローカルにおくことで、取得しに行く命令を省略できます。
しかし境界値チェックは消えないので、配列ほど早くなっていません。
Listでfor,foreachの比較
| Method | Mean | Error | StdDev | Allocated |
|---|---|---|---|---|
| LocalListFor | 15.350 μs | 0.2931 μs | 0.3375 μs | - |
| ListForEach | 20.116 μs | 0.3503 μs | 0.3106 μs | - |
public int LocalListFor()
{
var buf = 0;
var list = _list;
for (int i = 0; i < list.Count; i++)
{
buf += list[i];
}
return buf;
}
public int ListForEach()
{
var buf = 0;
foreach (int i in _list)
{
buf += i;
}
return buf;
}
Listのforとforeachの比較です。
forの方が早いです。
理由としては、foreachの仕組みにあります。
Listでforeachを使った場合はでtry~catchに展開されます。
そして、次の要素を取得する判定にIEnumeratorのMoveNext()が呼ばれます。
このように様々な処理が実行されるため時間がかかります。
SharpLabでListForEachをC#→C#にするとそのような実装になっていることが確認できます
C#→C#へ変換したコード
public int ListForEach()
{
int num = 0;
List<int>.Enumerator enumerator = _list.GetEnumerator();
try
{
while (enumerator.MoveNext())
{
int current = enumerator.Current;
num += current;
}
return num;
}
finally
{
((IDisposable)enumerator).Dispose();
}
}
ListとReadOnlyListのfor比較
| Method | Mean | Error | StdDev | Allocated |
|---|---|---|---|---|
| ListFor | 15.352 μs | 0.2841 μs | 0.2658 μs | - |
| ReadOnlyListFor | 100.029 μs | 1.9233 μs | 2.2149 μs | - |
public int ListFor()
{
var buf = 0;
for (int i = 0; i < _list.Count; i++)
{
buf += _list[i];
}
return buf;
}
public int ReadOnlyListFor()
{
var buf = 0;
for (int i = 0; i < _readonlyList.Count; i++)
{
buf += _readonlyList[i];
}
return buf;
}
Listのfor文(ListFor)とIReadOnlyListのfor文(ReadOnlyListFor)の比較です。
Listの方が早いです。
理由は領域確保の差です。
ReadOnlyListForのアセンブラを見てみると、領域の確保を何回も行っていることがわかります。
ListForでは要素をそのまま使っているので、領域確保分をしていません。
ListをIReadOnlyListにアップキャストしても実態は変わらないので、同じ速度になると思っていました。
ReadOnlyListForのアセンブラ
L0000 push rdi
L0001 push rsi
L0002 push rbx
L0003 sub rsp, 0x20
L0007 mov rsi, rcx
L000a xor edi, edi
L000c xor ebx, ebx
L000e mov rcx, [rsi+0x18]
L0012 mov r11, 0x7ff7abfc7000
L001c call qword ptr [0x7ff7abfc7000] // ここで領域確保
L0022 test eax, eax
L0024 jle short L0058
L0026 mov rcx, [rsi+0x18]
L002a mov edx, ebx
L002c mov r11, 0x7ff7abfc7008
L0036 call qword ptr [0x7ff7abfc7008] // ここで領域確保
L003c add edi, eax
L003e inc ebx
L0040 mov rcx, [rsi+0x18]
L0044 mov r11, 0x7ff7abfc7000
L004e call qword ptr [0x7ff7abfc7000] // ここで領域確保
L0054 cmp eax, ebx
L0056 jg short L0026
L0058 mov eax, edi
L005a add rsp, 0x20
L005e pop rbx
L005f pop rsi
L0060 pop rdi
L0061 ret
結果
配列
ArrayForEach < LocalArrayFor < ArrayFor < ArrayForFieldValue = ArrayForEachFieldlValue
List
LocalListFor < ListFor < ListForEach
ReadOnlyList
LocalReadOnlyListFor < ReadOnlyListFor < ReadOnlyListForEach
メンバ変数より、ローカル変数を使ったほうが早いことが分かりました。
そのうえで、foreachの仕様による速度差が出たという結果になりました。
まとめ
ローカルにコピーするだけでも速度が変わることが分かりました。
違う実装でも中身が同じことがあり、実装を追うのは大切だなと身に沁みました。
苦戦する箇所が多く大変でしたが、興味深い結果が多く楽しかったです。
今後はC#や.NETのバージョン、アセンブラに加えてアクセス速度やメモリ周りの知識を付けていきたいです。
内部実装に興味を持ってくれたり、見てくださった方の助けになると幸いです。
以上、「Applibot Advent Calendar 2022」24日目の記事でした。ここまで読んでくださり、ありがとうございました。
明日は@Nakamuro-unlさんです!
おまけ:ReadOnlyListForEachのアロケーションについて
| Method | Mean | Error | StdDev | Allocated |
|---|---|---|---|---|
| ReadOnlyListForEach | 153.840 μs | 2.3202 μs | 2.1704 μs | 40 B |
プロジェクトでListをIReadOnlyListにキャストして渡したいという話が出たことがあったのでこの機会にまとめます。
Listの内部実装を把握しないと突き当たる問題だと思います。
IEnumerableを実装しているものでforeachを使った場合、GetEnumerator()が呼ばれるようになっています。
ここでListのGetEnumerator()の実装を見てみます。
referencesource.microsoft.com/#mscorlib/system/collections/generic/list.cs,569
public Enumerator GetEnumerator() {
return new Enumerator(this);
}
/// <internalonly/>
IEnumerator<T> IEnumerable<T>.GetEnumerator() {
return new Enumerator(this);
}
GetEnumerator()の戻り値となっているEnumeratorはList内部で定義されているstructになります。
該当箇所は下記のコードになります。
referencesource.microsoft.com/#mscorlib/system/collections/generic/list.cs,9c3d580a8b7a8fe8,references
public struct Enumerator : IEnumerator<T>, System.Collections.IEnumerator
このことを念頭に入れて考えてみます。
今回の場合はListをIReadOnlyListにキャストしているので、IEnumerable.GetEnumerator()が呼ばれます。
IEnumerable.GetEnumerator()は戻りの型はinterfaceのIEnumerator(参照型)であるのに対し、内部の処理でstructのEnumerator(値型)を返しています。
ここで暗黙的にキャストが発生しボックス化が行われGCが発生することになります。
この結果IReadOnlyListでforeach使った際の速度が遅くなっているのです。
おまけ2:Unityでの計測
環境
- Unity2021.3.14
- エディター実行
結果
- 配列はforeach
- Listはfor
- IReadOnlyListもFor
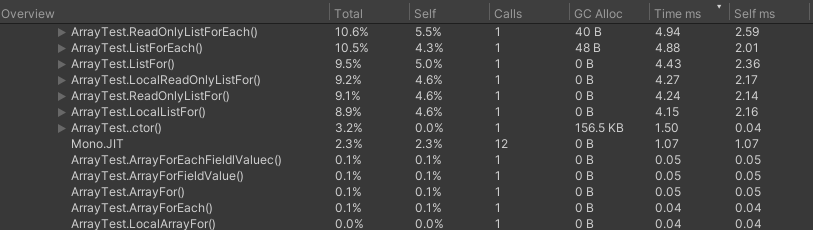
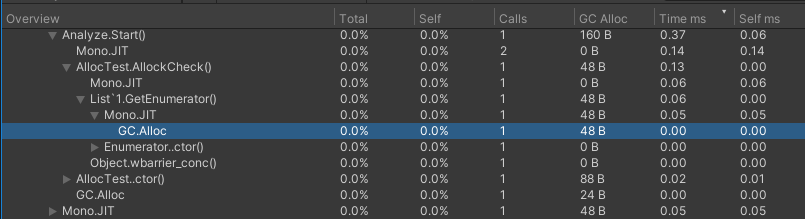
なぜかListForEachでGCが発生してるけど、原因は不明でした。
下記の最小コードでも発生してるから、unityの仕様っぽいですね
Updateでは発生せず最初の1回のみ発生するので、List.GetEnumerator内部の初期化で何かやっていそうです。
public class Analyze : MonoBehaviour
{
public List<int>_list = new List<int>
{
1,2, 3, 4,
};
void Start()
{
AllockCheck();
}
public void AllockCheck()
{
_list.GetEnumerator();
}
}
参考
【C#】Listと配列でforとforeachのアクセス速度比較 - PG日誌
BenchmarkDotNetを使ってみる。 - Qiita
【C#】ループの最適化手法 ①配列編 ~境界値チェックと専用命令と~ - Qiita
【Unity C#】 IReadOnlyListとアロケーション - すぎしーのXRと3DCG
(C#) 配列の for の JIT 最適化処理 - ネコのために鐘は鳴る