IDもnameもわからない場合はxpathを使います。
日記がてら実際の写真も交えてメモします。キャプチャみただけで懐かしくなります。
一番よく使うのが
タグ名+クラス名
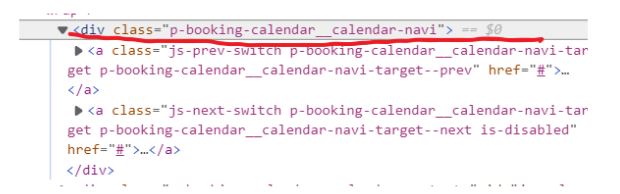
例:divタグのクラス名がp-booking-calendar__calendar-navi
もちろん divタグでクラス名がp-booking-calendar__calendar-naviの要素が一つしかないものとします。
driver.find_element_by_xpath("//div[@class='p-booking-calendar__calendar-navi']")
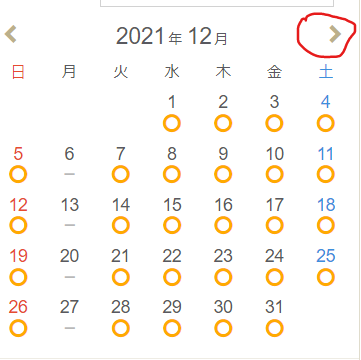
実際の画面はこちら
カレンダーの次へボタンを押したかったのです。
実際のソースはこち
特定の文字列の次にある要素
containsとfollowing-siblingを使う
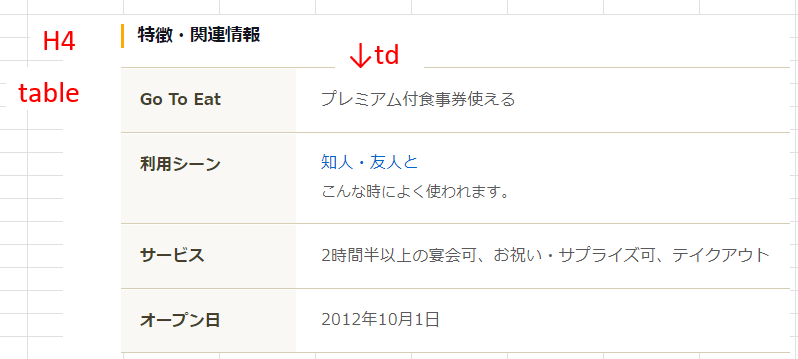
例:h4文字列の次にあるテーブル。そのテーブルのtdタグの値をすべてほしい
〇番目のtdタグかわかるようにforでループしています。
h4の文字列は特徴・関連情報
# まずh4で文字列が特徴・関連情報
# その次にある(兄弟要素)tableを取得
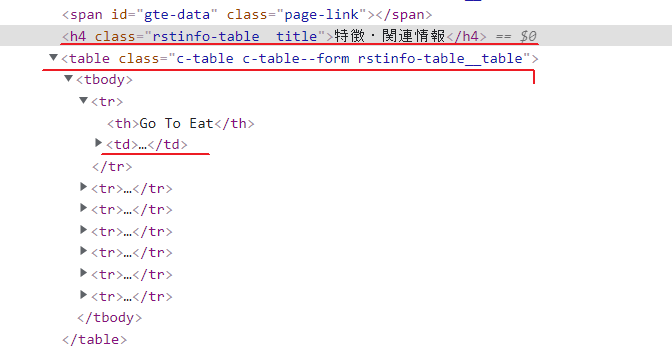
tabletag = driver.find_element_by_xpath("//h4[contains(text(),'特徴・関連情報')]/following-sibling::table[1]")
# tabletagの中からtdタグを全部取得
tdtags = tabletag.find_elements_by_tag_name("td")
# tdタグの中身を全部出力してみる
for i in range(0,len(tdtags)):
print(tdtags[i].text)
・実際の画面
・実際のソース
th見出しの次にあるtdの文字列
containsとfollowing-sibling
例:tdタグにあるオープン日だけを取得したい
hpurl = tabletag.find_element_by_xpath("//th[contains(text(),'オープン日')]/following-sibling::td[1]").text
・実際の画面
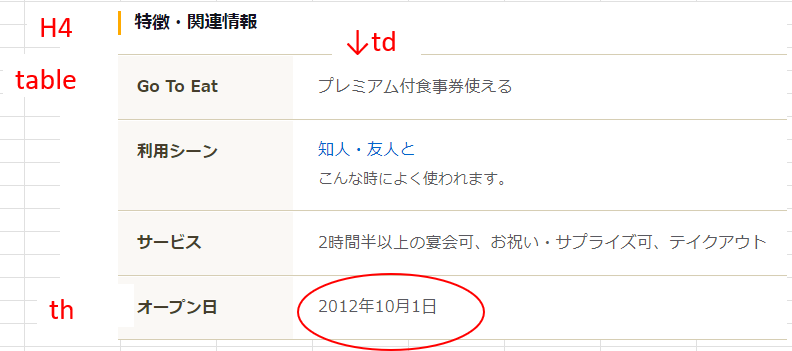
・実際のソース
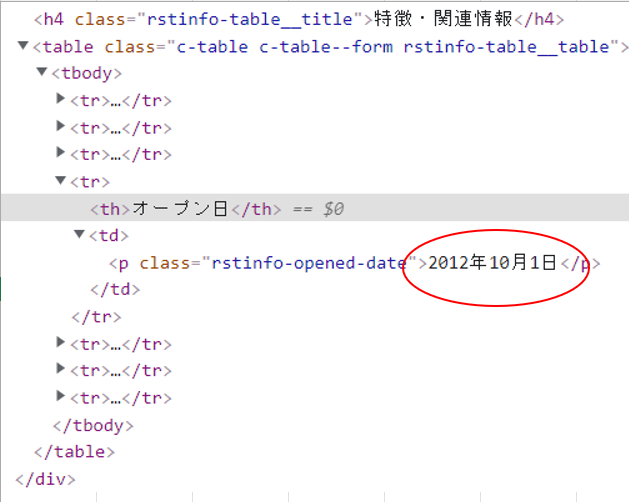
複数のtableに同じthタグが複数ある(thタグの文字列だけで取得できない)
Xpathの//と/を使い分ける
例:これが一番困る。上の例だと thタグのオープン日が複数のテーブルにある場合
この場合まずテーブルを指定して、そのテーブルからthタグにあるオープン日をみつける
具体的には
・特徴・関連情報を含むh4タグを見つける
・その次にあるテーブルを見つける
・テーブルの中から文字列が「オープン日」を含むthタグを見つける
・その次にあるtdタグを指定する
※ポイント
・table[1]の次は//です。table→tbody→trの記述を省略するため
aaa = driver.find_element_by_xpath("//h4[contains(text(),'特徴・関連情報')]/following-sibling::table[1]//th[contains(text(),'コース')]/following-sibling::td[1]")
print(aaa.text)
・実際の画面
・実際のソース
その他順次追記予定
ブラウザの拡張機能からxpathを取得すればその時は速攻ですが、
数日後に「動きません」と悲しい結果になるので。
なるべく自分でxpathを作成するように勉強中です。