Infographics: Operation Costs in CPU Clock Cycles - IT Hare on Soft.ware
http://ithare.com/infographics-operation-costs-in-cpu-clock-cycles/
より。
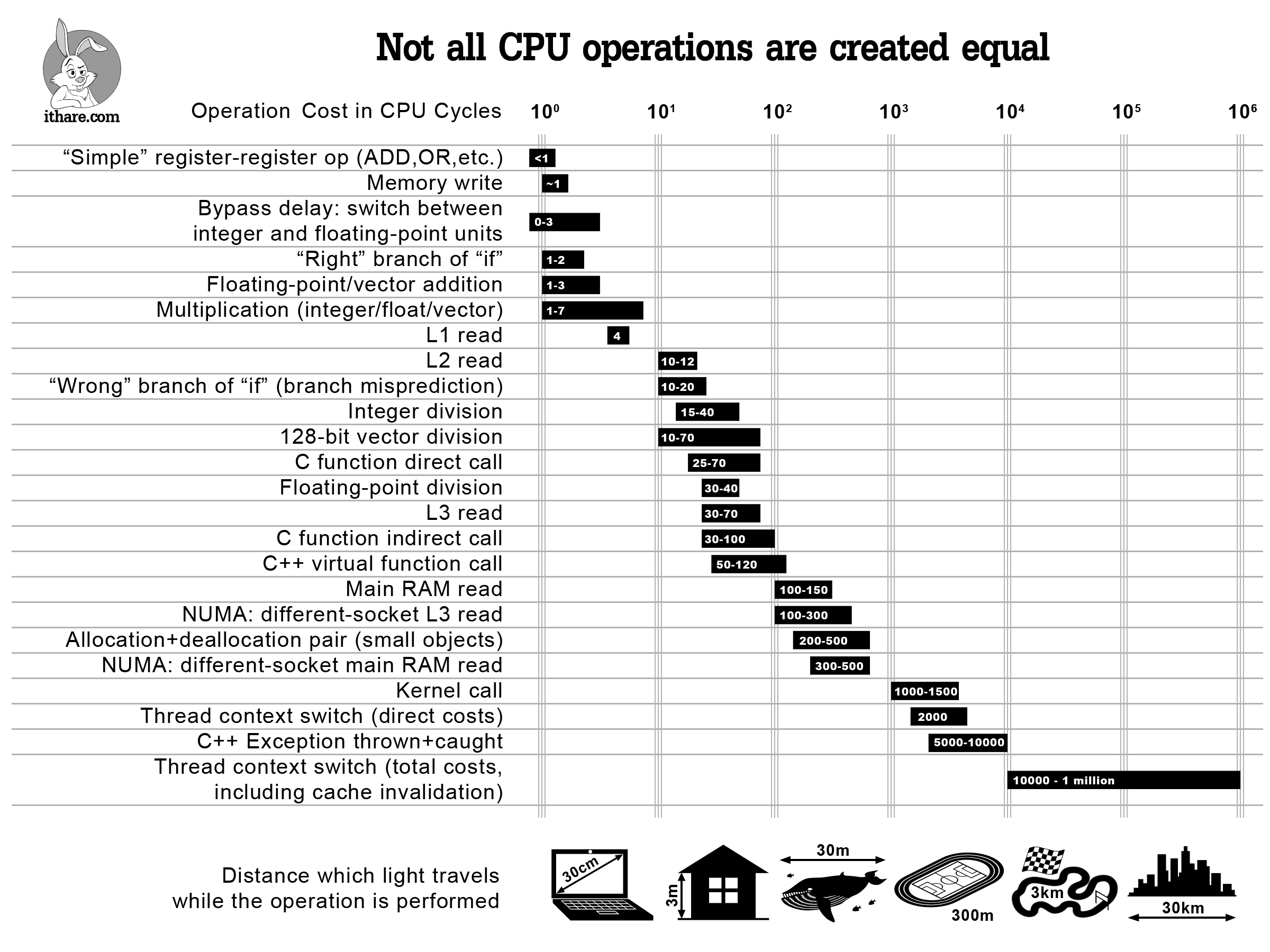
対象アーキテクチャはx86/x64。データは末尾のReferenceにある論文などから取ったのだろう。その中でも最高のリファレンスと言われている[Agner4]は293ページの巨大な一覧表だ。
http://www.agner.org/optimize/instruction_tables.pdf
- C++の例外のコストは大きい。昔の家庭用ゲームでは例外は使わないとされていたのもむべなるかな
- メモリの書き込みは完了する前に次の命令へ進めるから1クロックで済むというのは恥ずかしながら知らなかった
- コンテキストスイッチもやはりコスト大。システムコールは必ずコンテキストスイッチを伴うものだと思っていたけどKernel callとThread context switchがほぼ同コストになっているのはどういうことだろう
- RAM読み込みは予想通りに遅い
- 関数呼び出しもそれなりにかかるので昔は再帰が遅いと言われていたのもわかる
- 分岐予測失敗(branch misprediction)のペナルティはもっと大きいのかと思っていた
- 整数の割り算がすごく遅い(足し算、引き算に比べると。掛け算と比べても遅い)
こんなデータも。出典はGoogleの Jeff Dean が発表した資料らしい。
https://gist.github.com/jboner/2841832
L1 cache reference 0.5 ns
Branch mispredict 5 ns
L2 cache reference 7 ns 14x L1 cache
Mutex lock/unlock 25 ns
Main memory reference 100 ns 20x L2 cache, 200x L1 cache
Compress 1K bytes with Zippy 3,000 ns 3 us
Send 1K bytes over 1 Gbps network 10,000 ns 10 us
Read 4K randomly from SSD* 150,000 ns 150 us ~1GB/sec SSD
Read 1 MB sequentially from memory 250,000 ns 250 us
Round trip within same datacenter 500,000 ns 500 us
Read 1 MB sequentially from SSD* 1,000,000 ns 1,000 us 1 ms ~1GB/sec SSD, 4X memory
Disk seek 10,000,000 ns 10,000 us 10 ms 20x datacenter roundtrip
Read 1 MB sequentially from disk 20,000,000 ns 20,000 us 20 ms 80x memory, 20X SSD
Send packet CA->Netherlands->CA 150,000,000 ns 150,000 us 150 ms