TL;DR: そもそも単純に比べんな。ナイフとノコギリがどっちがいいかなんて一概には言えないだろう?
Twitterに書いたら思ったより反応されてるので、もうちょっと解説も兼ねて書いておきます。
なお、この話はtweetにもある通り某所で発表したやつの公開版です。前にも観たって方は内緒にしておいてください。
あと、若干、個人的な偏見を含んでいるかもしれませんが、そのあたりは頑張ってフィルターかけてください。
CUDA
GeForceやTeslaといった、NVIDIA社のGPUでGPGPUしたい人がまず使うプログラミング環境。実質的にGPGPU界の頂点であり最強であることは否定できません。 ただし、NVIDIAがベンダーロックしていて、標準化はされていません(一応、CUDAのモデルはロイヤリティーフリーで使っても良い)。
CUDA Cという独自拡張されたC言語で、デバイスとホストを同じ.cuファイルに書いて、nvccという特殊コンパイラに与えると、CPU側のコードとGPU側のコードに分離してビルドしてくれます。
使いやすさ(周辺ライブラリや利用者の多さを含む)とNVIDIA社GPUへの最適化具合が長所ですが、逆に欠点はNVIDIA社のGPUにしか使えないことです。 あと、並列数の指定が「n並列」じゃなくて「nスレッドのブロックをm個でトータルnm並列」というのが個人的には気に食わないです。
中間表現はPTXと呼ばれているこれもNVIDIA独自のものが使われています。最下層のアセンブリも当然独自でSASSなどが使われます。
OpenCL
「異種混合環境での並列プログラミングのオープンな標準規格」、つまりGPGPUには特化していません。
規格自体はKhronosが策定しており、Intel, AMD, ARMが推しています。一応NVIDIAでも動きますが、現状、やる気のなさがヒシヒシと伝わってくるので、NVIDIA社のGPUでOpenCLを書くのは特殊な事情がないならお勧めしません。
デバイス側をOpenCL Cという独自拡張されたC言語(※OpenCL2.2からはOpenCL C++という特殊なC++14で書けるようになります)でホストとは別に書いて実行時に文字列で渡して、ホスト側でオンラインコンパイルします。ホスト側は普通のgccやclangなどのコンパイラが使えます。
長所は、標準規格であり使える環境が多い点ですが、やはりCUDAには利用者数もライブラリ群の整備状況も負けてるので、取っ付きやすさという意味ではCUDAに負けます。とは言っても、昨今のGPUは倍精度演算はNVIDIAよりAMDの方が速かったりして、倍精度が必要な物理計算等でAMDのGPUが使いたかったらOpenCL一択です。
(とは言うものの今の世界、だいたいメモリのread性能に律速するので、倍精度演算性能そのものはそれほど重要でないことも多い)
中間表現は、OpenCL2.1になってSPIR-Vに統一されました。それ以前は拡張機能のSPIR 1.2/2.0を使うか、(OpenCLとは独立した別の)標準規格であるHSAILか、各ベンダー独自の中間表現もあります。
アセンブリはさすがにベンダー独自です(AMDの場合はGCN-ISAなど)。
OpenGL Compute Shader
OpenCLと同じくKhronosが作成しているグラフィックス用規格のOpenGL、そのバージョン4.3からCompute Shaderという特殊なシェーダーが入りました。
普通のVertexやFragmentと同列にComputeができるようになっています。なのでGLSLで書きます。
長所は、OpenGLしか使えない3DCG屋さんには取っ付きやすいことと、グラフィックスと連携が取りやすい所です。短所は、それほど盛り上がってない点です(CUDAやOpenCL等と比較して)。
DirectX DirectCompute
DirectX 11から入ったGPGPU向けのAPIです。
DirectXの機能の一部なので、HLSLで書きます。
長所は、DirectXしか使えない3DCG屋さんには(略。短所は、それほど(略。あと、Windowsしか使えないのが欠点ですが逆にXboxでも使えるっぽいです。
C++ AMP
正式名称はC++ Accelerated Massive Parallelism。Microsoftが提唱した、C++を拡張したGPGPU用規格です。
Microsoftがやってるので当然Windowsで動きます(裏ではDirectComputeが動いているっぽいです)。 しかしHCC(旧名称:Kalmar)というclangベースのコンパイラを使うとLinux等でも使えます。
長所は取っ付きやすさ(手軽さ・書きやすさ)です。短所はCUDA/OpenCLほど盛り上がってない点と、WDDMのバージョン(つまりWindowsのバージョン)によっては倍精度が使えない点です。
HIP
CUDAとほぼ同じ構文でポータブルな感じにしてくれるもの。 HIP自体はフロントエンドコンパイラみたいなもので、バックエンドにnvccを使えばCUDAに、先述のHCCを使えばGCN-ISAかHSAILになります。どちらも、オーバーヘッドはありません。もし更に最適化したかったら変換後のコードを見て最適化が可能です。
CUDAソースをそのままHIP構文に変換してくれるツールも提供されています(ほぼ置換で済むっぽい)。一時期「AMDのGPUでCUDAを動かせるようにする!」と言っていたやつ、あれがこれです。
今CUDAで動いているものをAMDのGPUでも動かしたかったらこれ一択かなと思います。
長所はこのように使える範囲が広いのとオープンソースでの活発な開発ですが、なにせ最近出てきたばかり(いわゆるGPUOpenの一環)なのでまだ未知数なところがあるのが欠点です。
OpenACC
OpenMPのように#pragmaを入れるだけでGPU等アクセラレータで実行してくれる規格。NVIDIAとPGIが頑張ってます。
ディレクティブ入れるだけで速くなるという夢の様な話ですが、実際ほぼ夢です。
長所の取っ付きやすさは群を抜いていますが、なにせ細かいところがコンパイラ依存で制御がとても難しく、現時点では素人が扱うと大変という印象しかありません。 そもそも高価なPGI製のコンパイラが必要なので素人が簡単に使えるものではないのですが(※一応gcc5または6に入ってますがこれがまた使いづらいと評判)。
あと、NVIDIAが推していることから分かる通り、現時点ではNVIDIA社のGPUでしか使えません。 個人的には、後述のOpenMPがあるのでもう役目を終えたのかなと思っています。
OpenMP
OpenMP 4.0から「アクセラレーターへのオフロード」という機能が追加されました。 clang/gccいずれも現最新版では既にOpenMP 4.0をサポートし、オフロードできるようになっています。 現時点で対応しているデバイスはIntel XeonPhiおよびNVIDIA/AMDのGPUです(PTXとHSAILを選べる)。
ということで、簡単にGPUに計算を投げたかったらOpenMPを使えばよく、先述のようにOpenACCの意義はかなり薄れています。
SYCL
Khronosが策定した、OpenCLをCUDAのように単一ソースコードで書けるようにするC++規格です。 アイディアだけ発表されて長らく何の音沙汰もなかったので死んでしまったのかと思っていたのですが、OpenCL 2.1の正式発表と当時にSYCL 1.2が公表され、 この度OpenCL 2.2の候補版と同時にSYCL 2.2の候補版も発表されました。いきなりバージョンが1.2と2.2な理由のは謎です。
単一ソースで書けるようになれば嬉しいのは嬉しいのですが、先述の通り時代はSPIRやHSAILなど中間表現さえ合わせればOKということになっているので、 OpenCLはもはやただのフロントエンドと言っても良いぐらいです。SYCLはそれを更にラップするフロントエンドのフロントエンドということになっていて、どれほど価値があるのか判断がつきません。
というか、判断がつかない根本的な原因は、現時点ではOpenCLのバックエンドが存在しないことです。 triSYCLというOpenMPバックエンドな試験実装しかありません(SYCLのCLはOpenCLのCLのはずなので、OpenMPで実装してる時点で察してあげてください)。
結局どれを使えばいいの?
ということで最初のtweetと同じ図になります。
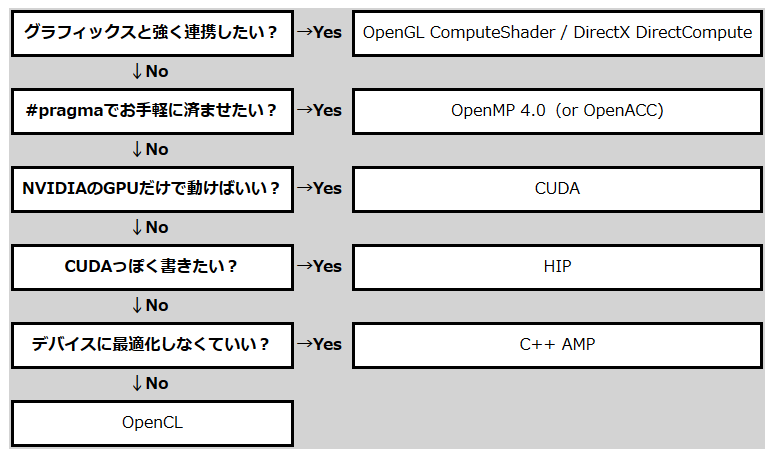
ご覧のとおり、CUDAとOpenCLは遠いところにあります。なので「CUDAとOpenCLは比べるのが間違ってる」わけです。↑の図にしたがって、自分が必要としている状況に合わせて好きなのを使ってください。
なお、私は「速いものが正義」派なので、NVIDIAのGPUならCUDA、AMDのGPUならOpenCLを使っていますし、使ってきましたし、この先も使っていくと思います。