〇〇100本ノックが素敵なのでそれにならってR100本ノックを書こうと思ったのだが日和って35本とした。
でも、これくらい出来たらRのスタートしては十分なのではないかと思う。
補足
演算子と数字や変数はくっつけても空白を開けても同じ意味だがみやすさのために空白を入れている人が多い
5 + a
5+a
文字列はダブルクォーテーションでもシングルクォーテーションでもよいようだ
私はPerl出身なので変数を展開するダブルクォーテーションと展開しないシングルクォーテーションを分けてしまい、純粋な文字列のときはシングルクォーテーションにしがちだけどRの人は純粋な文字列のときもダブルクォーテーションが多いようだ
ここでもダブルクォーテーションに合わせます
基本操作(001-012)
001 Hello World!
Hello World! と出力
> print ("Hello, World!")
[1] "Hello, World!"
002 四則演算
123.1 + 5 =
99.9 - 10.0 =
9 * 9 =
5 ÷ 3 =
12 ÷ 5 の余り
> 123.1 + 5
[1] 128.1
> 99.9 - 10
[1] 89.9
> 9 * 9
[1] 81
> 5 / 3
[1] 1.666667
> 12 %% 5
[1] 2
003 変数の使用
aに5を代入し、bに12を代入してa + b
> a<-5
> b<-12
> a + b
[1] 17
004 変数と型
文字列として入力された数字を数字(numeric)型に変換。その前後で型を確認。
> a<-"123"
> a
[1] "123"
> class(a)
[1] "character"
> a2<-as.numeric(a)
> a2
[1] 123
> class(a2)
[1] "numeric"
文字列として入力された日付を日付(Date)型に変換。その前後で型を確認。
> d<-"2018-12-31"
> d
[1] "2018-12-31"
> class(d)
[1] "character"
> d2<-as.Date(d)
> d2
[1] "2018-12-31"
> class(d2)
[1] "Date"
factor型を文字列に変換
注:見た目は文字列だが選択肢やレベルのように決められた文字列を指定・使用する場合にはfactor型とすると便利な場合がある。逆にfactor型のままだと取り扱いに困り文字列型に変換する必要が出てくる場合がある。
> f<-factor(c("Tokyo", "Osaka", "Okinawa"))
> f
[1] Tokyo Osaka Okinawa
Levels: Okinawa Osaka Tokyo
> class(f)
[1] "factor"
> f2<-as.character(f)
> f2
[1] "Tokyo" "Osaka" "Okinawa"
> class(f2)
[1] "character"
005 連番
1から20を示す。また偶数を20まで示す。
> 1:20
[1] 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
> seq(1, 20)
[1] 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
> seq(2, 20, 2)
[1] 2 4 6 8 10 12 14 16 18 20
006 現在使用しているオブジェクトの一覧表示とオブジェクトの削除
オブジェクトを一覧表示し、そのうち"a"を削除する
> ls()
[1] "a" "b"
> rm(a)
> ls()
[1] "b"
003 で作成したオブジェクトが表示され、"a"が削除されたのが分かる。
007 ベクトル型、マトリックス型、データフレーム型、リスト型の作成と型の確認
- ベクトル型
1-20をaに代入。1, 3, 9をa2に代入。"Tokyo", "Osaka", "Okinawa"をa3に代入。
> a<-seq(1, 20)
> a
[1] 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
> a2<-c(1, 3, 9)
> a2
[1] 1 3 9
> a3<-c("Tokyo", "Osaka", "OKinawa")
> a3
[1] "Tokyo" "Osaka" "OKinawa"
- マトリクス型
下記の行列を作成
\left(
\begin{array}{ccc}
5 & 2 & 0 \\
4 & 1 & 6
\end{array}
\right)
> b1<-matrix(c(5, 2, 0, 4, 1, 6), byrow = T, nrow = 2)
> b1
[,1] [,2] [,3]
[1,] 5 2 0
[2,] 4 1 6
引数byrow = Fとすると数字が縦に並び異なる行列となる
> b2<-matrix(c(5, 2, 0, 4, 1, 6), byrow = F, nrow = 2)
> b2
[,1] [,2] [,3]
[1,] 5 0 1
[2,] 2 4 6
>
- データフレーム型
下記のデータを保持するデータフレームを作成
| A | N |
|---|---|
| Tokyo | 1000 |
| Osaka | 2000 |
| Okinawa | 300 |
> c<-data.frame(A = c("Tokyo", "Osaka", "OKinawa"), N = c(1000, 2000, 3000))
> c
A N
1 Tokyo 1000
2 Osaka 2000
3 Okinawa 300
- リスト型
Chiyoda, Sinjuku, Nakano
Namba
Naha
など異なるデータ数のリストを作成する
> d<-list()
> d[[1]]<-"Chiyoda"
> d[[1]][[2]]<-"Shinjuku"
> d[[1]][[3]]<-"Nakano"
> d[[2]]<-"Namba"
> d[[3]]<-"Haha"
> d
[[1]]
[1] "Chiyoda" "Shinjuku" "Nakano"
[[2]]
[1] "Namba"
[[3]]
[1] "Haha"
008 型変換と型の確認
マトリックス型をデータフレーム型に変換する。その前後で型を確認する
> b1
[,1] [,2] [,3]
[1,] 5 2 0
[2,] 4 1 6
> class(b1)
[1] "matrix"
> b1.df<-as.data.frame(b1)
> b1.df
V1 V2 V3
1 5 2 0
2 4 1 6
> class(b1.df)
[1] "data.frame"
009 マトリックス型とデータフレーム型の行結合、列結合
下記のデータを保持するデータフレームの行を結合
下記例はデータフレーム型だがマトリックス型でも同じ
c.1
| A | N |
|---|---|
| Tokyo | 1000 |
| Osaka | 2000 |
| Okinawa | 300 |
c.2
| A | N |
|---|---|
| Hokkaido | 1500 |
| Hukuoka | 5000 |
> c.1<-data.frame(A = c("Tokyo", "Osaka", "OKinawa"), N = c(1000, 2000, 3000))
> c.2<-data.frame(A = c("Hokkaido", "Hukuoka"), N = c(1500, 5000))
> c<-rbind(c.1, c.2)
> c
A N
1 Tokyo 1000
2 Osaka 2000
3 OKinawa 3000
4 Hokkaido 1500
5 Hukuoka 5000
cにID列のデータフレームc.0を付与し連番を振る
c.0
| ID |
|---|
| 1 |
| 2 |
| 3 |
| 4 |
| 5 |
> c.0<-data.frame(ID = 1:5)
> cbind(c.0, c)
ID A N
1 1 Tokyo 1000
2 2 Osaka 2000
3 3 OKinawa 3000
4 4 Hokkaido 1500
5 5 Hukuoka 5000
010 乱数の発生1
サイコロのように1~6の整数を10回発生させる
> sample(1:6, 10, replace = T)
[1] 2 2 5 3 5 3 5 6 3 5
上記でよいが乱数なので毎回異なる値となる。乱数だけど毎回同じ結果としたい場合などは乱数の種を固定する
> set.seed(1)
> sample(1:6, 10, replace = T)
[1] 2 3 4 6 2 6 6 4 4 1
> set.seed(1)
> sample(1:6, 10, replace = T)
[1] 2 3 4 6 2 6 6 4 4 1
何度実行しても同じ結果となる(set.seed(1)の1の値を変えれば変わる)。
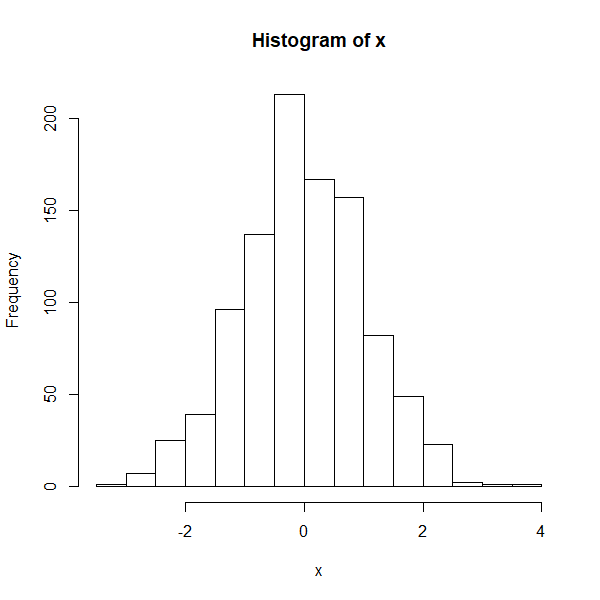
正規分布による乱数を100発生させる
> set.seed(1)
> x<-rnorm(1000)
> head(x)
[1] -0.6264538 0.1836433 -0.8356286 1.5952808 0.3295078 -0.8204684
「032 ヒストグラム」の内容を先に用いるがxのヒストグラムを描くとほぼ正規分布となっている
011 サンプルデータセット、パッケージのインストール
サンプルデータセットの一覧を取得。
パッケージ(ggplot2)のインストール、呼び出し。
> data()
> library(ggplot2)
> Error in library(ggplot2) : ‘ggplot2’ という名前のパッケージはありません
インストールされていないパッケージを呼び出そうとすると、インストールされていない旨のメッセージが出る。
> install.packages("ggplot2")
> library(ggplot2)
012 Help
サンプルデータセット(AirPassengers)のヘルプを見る。
関数(lm)のヘルプを見る。
> help(AirPassengers)
> help(lm)
プログラム基本(013-017)
013 for文
1から20までを出力
> for (i in 1:20) {
print (i)
}
[1] 1
[1] 2
[1] 3
[1] 4
[1] 5
[1] 6
[1] 7
[1] 8
[1] 9
[1] 10
[1] 11
[1] 12
[1] 13
[1] 14
[1] 15
[1] 16
[1] 17
[1] 18
[1] 19
[1] 20
014 if文
1から20までの間で3の倍数のときに"Fizz"、5の倍数のときに"Buzz"、3と5の倍数のときに"Fizz Buzz"と出力する
> for (i in 1:20) {
print (i)
if (i %% 3 == 0 && i %% 5 == 0) {
print ("Fizz Buzz")
} else if (i %% 3 == 0) {
print ("Fizz")
} else if (i %% 5 == 0) {
print ("Buzz")
}
}
[1] 1
[1] 2
[1] 3
[1] "Fizz"
[1] 4
[1] 5
[1] "Buzz"
[1] 6
[1] "Fizz"
[1] 7
[1] 8
[1] 9
[1] "Fizz"
[1] 10
[1] "Buzz"
[1] 11
[1] 12
[1] "Fizz"
[1] 13
[1] 14
[1] 15
[1] "Fizz Buzz"
[1] 16
[1] 17
[1] 18
[1] "Fizz"
[1] 19
[1] 20
[1] "Buzz"
> for (i in 1:20) {
print (i)
if (i %% 3 == 0 && i %% 5 == 0) {
print ("Fizz Buzz")
} else if (i %% 3 == 0) {
print ("Fizz")
} else if (i %% 5 == 0) {
print ("Buzz")
}
}
[1] 1
[1] 2
[1] 3
[1] "Fizz"
[1] 4
[1] 5
[1] "Buzz"
[1] 6
[1] "Fizz"
[1] 7
[1] 8
[1] 9
[1] "Fizz"
[1] 10
[1] "Buzz"
[1] 11
[1] 12
[1] "Fizz"
[1] 13
[1] 14
[1] 15
[1] "Fizz Buzz"
[1] 16
[1] 17
[1] 18
[1] "Fizz"
[1] 19
[1] 20
[1] "Buzz"
015 for文を途中終了する
014の例で"Fizz Buzz"と出力したらループを終了する
> for (i in 1:20) {
print (i)
if (i %% 3 == 0 && i %% 5 == 0) {
print ("Fizz Buzz")
break
} else if (i %% 3 == 0) {
print ("Fizz")
} else if (i %% 5 == 0) {
print ("Buzz")
}
}
[1] 1
[1] 2
[1] 3
[1] "Fizz"
[1] 4
[1] 5
[1] "Buzz"
[1] 6
[1] "Fizz"
[1] 7
[1] 8
[1] 9
[1] "Fizz"
[1] 10
[1] "Buzz"
[1] 11
[1] 12
[1] "Fizz"
[1] 13
[1] 14
[1] 15
[1] "Fizz Buzz"
016 関数の定義と使用
> x<-c(1, 3, 5, 2, 9)
> y<-c(0, 4, 7, 2, 8)
> d<-data.frame(x, y)
> d
x y
1 1 0
2 3 4
3 5 7
4 2 2
5 9 8
このようなデータがある時に、2列のデータフレームの1列目を2倍して2列めを2乗して足すという関数を定義し使用する。
> f<-function(d) {
> ret<-d[, 1] * 2 + d[, 2]^2
> return(ret)
> }
> f(d)
2 22 59 8 82
017 apply
前の問題のデータフレームdがある時に
行方向にsumを取る
> apply(d, 1, sum)
[1] 1 7 12 4 17
引数2つ目が1だと、3列目の関数sumを行方向に適用、2だと列方向に適用
> apply(d, 2, sum)
x y
20 21
sumなど定義済みの関数ではなく独自の関数を指定することもできる
> apply(d, 2, function(d) { return(d^2) })
x y
[1,] 1 0
[2,] 9 16
[3,] 25 49
[4,] 4 4
[5,] 81 64
これらはfor文でも実行可能だがapplyの方が実行速度が圧倒的に早い
グラフ基本編(018-019)
018 xyプロット
xに1から10、y=x^2をプロット。
最初は点で、次は曲線で。
次に、赤い点と青い線を重ね合わせて。
x<-seq(1, 10)
y<-x ^ 2
plot(x, y)
plot(x, y, type = 'l')
plot(x, y, col = 2)
lines(x, y, col = 4)
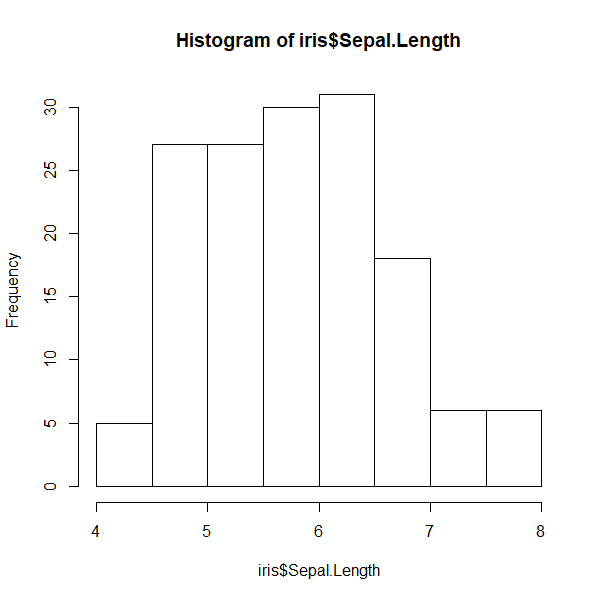
019 ヒストグラム
サンプルデータセットに入っているisisオブジェクトのSepal.Length列を用いてヒストグラムを描く。
head(iris)
hist(iris$Sepal.Length)
ファイル入出力(020)
020 ファイル書き出し、読み込み
サンプルデータセットに入っているirisオブジェクトをcsvファイルに書き出し、読み込む
確認のため冒頭行を表示する
(サンプルデータセットのまま書き込むと不要な列番号が出力されるので、書き込み時に列番号は出力しない)
> head(iris)
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
1 5.1 3.5 1.4 0.2 setosa
2 4.9 3.0 1.4 0.2 setosa
3 4.7 3.2 1.3 0.2 setosa
4 4.6 3.1 1.5 0.2 setosa
5 5.0 3.6 1.4 0.2 setosa
6 5.4 3.9 1.7 0.4 setosa
> write.csv(iris, "iris.csv", row.names = F)
> df<-read.csv("iris.csv")
> head(df)
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
1 5.1 3.5 1.4 0.2 setosa
2 4.9 3.0 1.4 0.2 setosa
3 4.7 3.2 1.3 0.2 setosa
4 4.6 3.1 1.5 0.2 setosa
5 5.0 3.6 1.4 0.2 setosa
6 5.4 3.9 1.7 0.4 setosa
文字列処理(021-023)
021 置換
a<-"He11o Wor1d!"と誤っている"1"を"l"に置換する。
> a<-"He11o Wor1d!"
> a
[1] "He11o Wor1d!"
> a2<-sub("1", "l", a)
> a2
[1] "Hel1o Wor1d!"
> a<-"He11o Wor1d!"
> a
[1] "He11o Wor1d!"
> a2<-gsub("1", "l", a)
> a2
[1] "Hello World!"
補足:sub関数だと最初にマッチした1文字しか置換しない。gsub関数だとマッチしたものすべてを置換する。
> a3<-sub("1", "l", a)
> a3
[1] "Hel1o Wor1d!"
022 文字の切り出し
上記a2="Hello World!"の3~4文字目を切り出す
> substr(a2, 3, 4)
[1] "ll"
023 文字列長
上記a2="Hello World!"の文字列長を調べる
> nchar(a2)
[1] 12
マッチ
グラフggplot2編(024-025)
024 x-yプロットと回帰曲線
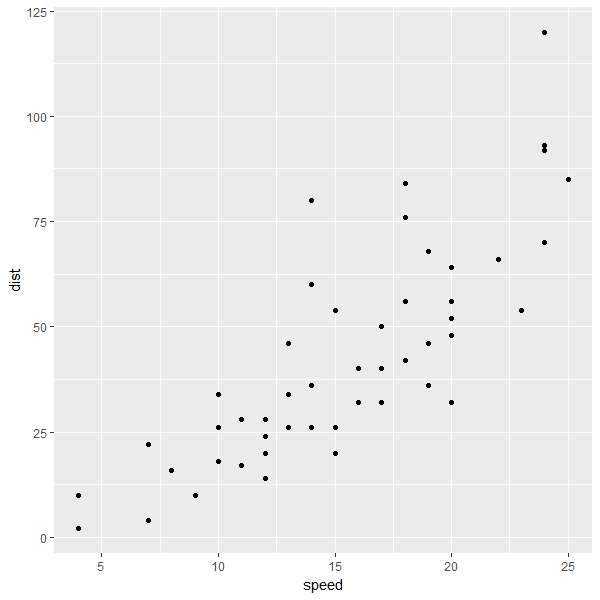
サンプルデータセットcarsをx-yプロットし、回帰曲線を追加する
library(ggplot2)
head(cars)
speed dist
1 4 2
2 4 10
3 7 4
4 7 22
5 8 16
6 9 10
> g<-ggplot(cars, aes(x = speed, y = dist))
> g<-g + geom_point()
> g
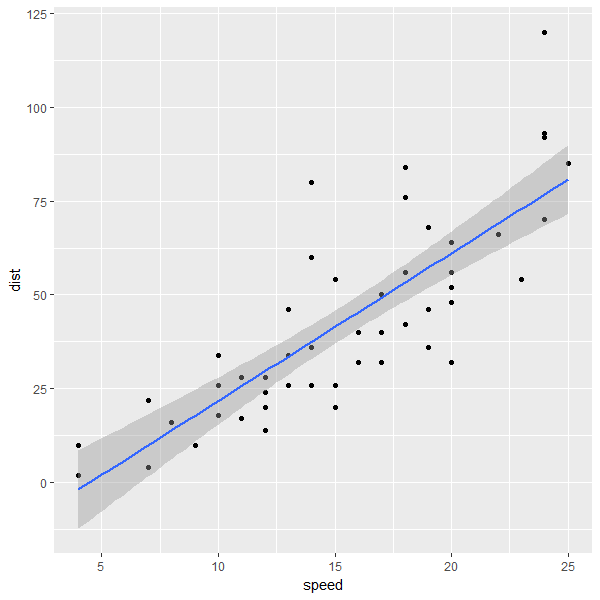
> g<-g + geom_smooth(method = "lm")
> g
025 図を並べる
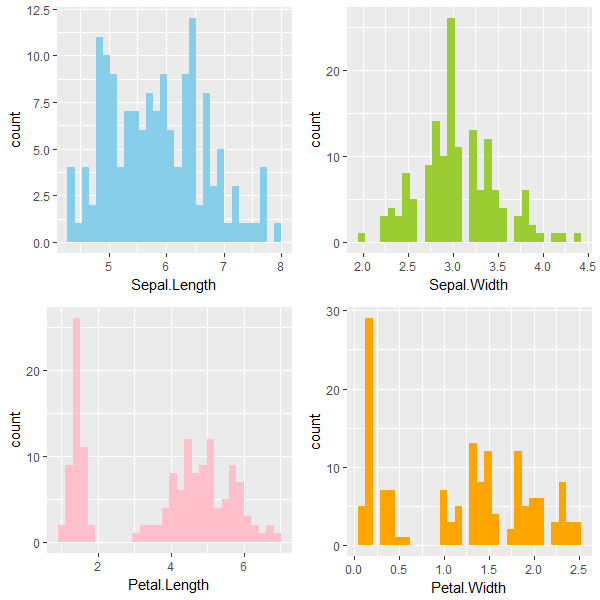
irisデータのヒストグラムを色を変えた4つの図として並べる。
> library("ggplot2")
> library("gridExtra")
> g1<-ggplot(iris, aes(x = Sepal.Length))
> g1<-g1 + geom_histogram(fill = "skyblue")
> g2<-ggplot(iris, aes(x = Sepal.Width))
> g2<-g2 + geom_histogram(fill = "yellowgreen")
> g3<-ggplot(iris, aes(x = Petal.Length))
> g3<-g3 + geom_histogram(fill = "pink")
> g4<-ggplot(iris, aes(x = Petal.Width))
> g4<-g4 + geom_histogram(fill = "orange")
> grid.arrange(g1, g2, g3, g4, ncol = 2)
`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
>
dyplr(026-028)
026 フィルタ
irisデータのうちSpeciesが"setosa"のみを抽出する
library(dplyr)
> df.1<-as.data.frame(iris %>%
filter(Species == "setosa"))
> unique(df.1$Species)
[1] setosa
Levels: setosa versicolor virginica
irisデータのうちSepal.Lengthが5.0より大きいものを抽出する
> df.2<-as.data.frame(iris %>%
filter(Sepal.Length > 5.0))
> min(df.2$Sepal.Length)
[1] 5.1
027 グルーピング集計
irisデータのSpeciesでグルーピングし、Sepal.Lengthの平均を求める
> df.3<-as.data.frame(iris %>%
group_by(Species) %>%
summarise(Sepal.Length.mean = mean(Sepal.Length)))
> df.3
Species Sepal.Length.mean
1 setosa 5.006
2 versicolor 5.936
3 virginica 6.588
irisデータのSpeciesでグルーピングし、Sepal.Widthの最大値を求める
> df.4<-as.data.frame(iris %>%
group_by(Species) %>%
summarise(Sepal.Width.mean = max(Sepal.Width)))
> df.4
Species Sepal.Width.max
1 setosa 4.4
2 versicolor 3.4
3 virginica 3.8
028 データフレーム結合
架空データdf.a, df.bをIDで結合しdf.cを作成する。また架空データdf.cとdf.d(欠損あり)をIDで結合しdf.eを作成する。
df.a
| ID | NAME |
|---|---|
| 01 | Hokkaido |
| 13 | Tokyo |
| 27 | Osaka |
df.b
| ID | POPL |
|---|---|
| 01 | 500 |
| 13 | 1400 |
| 27 | 800 |
df.a<-data.frame(ID = c("01", "13", "27"), NAME = c("Hokkaido", "Tokyo", "Osaka"))
df.a
df.b<-data.frame(ID = c("01", "13", "27"), POPL = c(500, 1400, 900))
df.b
df.c<-as.data.frame(left_join(df.a, df.b, by = "ID"))
df.c
df.d<-data.frame(ID = c("01", "27"), specialty = c("sea food", "Okonomiyaki"))
df.d
df.e<-as.data.frame(left_join(df.c, df.d, by = "ID"))
df.e
統計分析(029-034)
029 基本統計量
サンプルデータセットirisの基本統計量(定量値:最小値、第一四分位点、中央値、平均、第三四分位点、最大値; カテゴリ値:各カテゴリのカウント数)を表示する
> summary(iris)
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
Min. :4.300 Min. :2.000 Min. :1.000 Min. :0.100 setosa :50
1st Qu.:5.100 1st Qu.:2.800 1st Qu.:1.600 1st Qu.:0.300 versicolor:50
Median :5.800 Median :3.000 Median :4.350 Median :1.300 virginica :50
Mean :5.843 Mean :3.057 Mean :3.758 Mean :1.199
3rd Qu.:6.400 3rd Qu.:3.300 3rd Qu.:5.100 3rd Qu.:1.800
Max. :7.900 Max. :4.400 Max. :6.900 Max. :2.500
030 クラスタリング
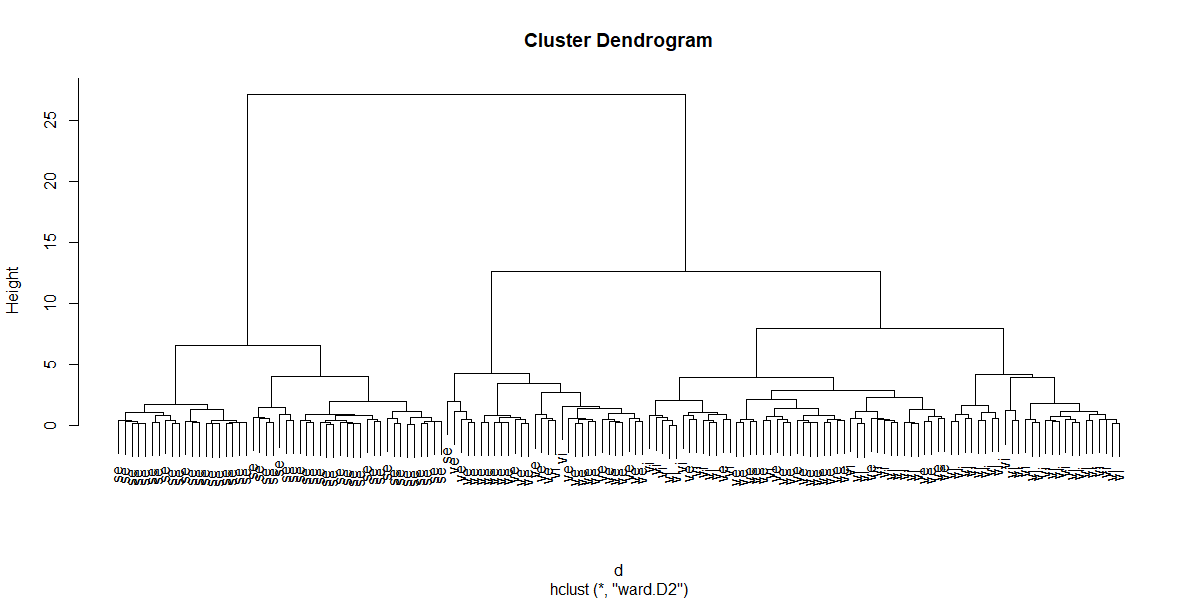
サンプルデータセットirisのクラスタリングを行う。ward.D2を用いる。デンドログラムも描く。
> d<-dist(scale(iris[, 1:4]))
> h<-hclust(d, method = "ward.D2")
> plot(h)

> 上記デンドログラムにラベル(iris[, 5])の頭2文字を付与する。
```r
> plot(h, labels = substr(iris[, 5], 1, 2))
031 主成分分析
irisデータを用いて主成分分析を行う。第二主成分までで説明力がどの程度か確認する
> pca<-prcomp(iris[, 1:4], scale. = T, center = T)
> summary(pca)
Importance of components:
PC1 PC2 PC3 PC4
Standard deviation 1.7084 0.9560 0.38309 0.14393
Proportion of Variance 0.7296 0.2285 0.03669 0.00518
Cumulative Proportion 0.7296 0.9581 0.99482 1.00000
第2主成分までで96%の説明力があることがわかる。
032 kmeans
非階層クラスタリングkmeansを実施し、084で実施した主成分分析の第二成分までのプロットにクラスタで色付けをする。
> set.seed(123456) # これは本質ではないがkmeansは乱数を用いるので答えを一致させるため乱数の種を固定している
> km<-kmeans(scale(iris[, 1:4]), 3)
通常はここまでだがirisデータにはクラス分けの答えがあるので確認する
table(iris[, 5], km$cluster)
1 2 3
setosa 0 0 50
versicolor 39 11 0
virginica 14 36 0
残念ながらiris$Speciesとkmeansの3つのクラス分けは一致していない。
kmeans結果で色付したプロットをする。
plot(pca$x, col = km$cluster)
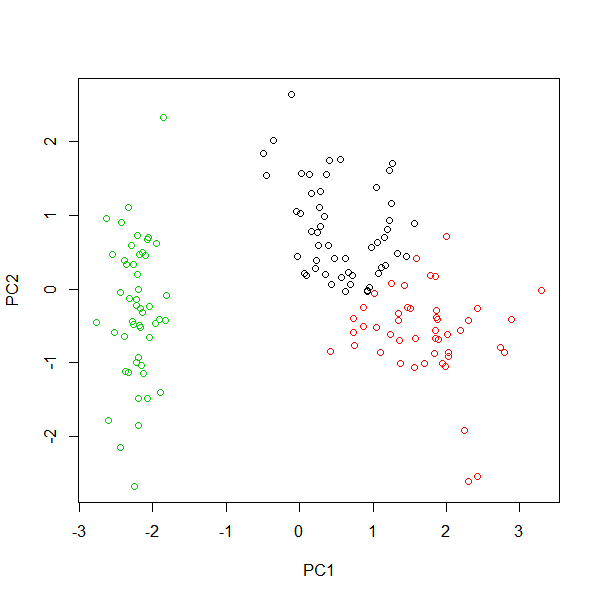
答えのSpeciesで色付けすると下記である。
plot(pca$x, col = iris$Species)
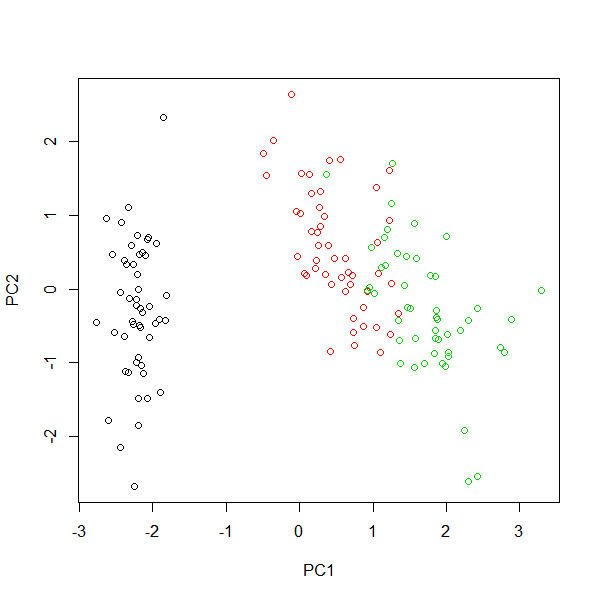
色の順番が異なるので色は本質ではないが右側のプロットが混在しているようである。
033 2群の検定
irisデータの先頭100行(Species=setosa, versicolor)を用いて、Speciesにより、Petal.Lengthの平均値に差があるかをt検定(ウェルチ)する。
> df<-iris[1:100, ]
> t.test(df$Petal.Length ~ df$Species)
Welch Two Sample t-test
data: df$Petal.Length by df$Species
t = -39.493, df = 62.14, p-value < 2.2e-16
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
-2.939618 -2.656382
sample estimates:
mean in group setosa mean in group versicolor
1.462 4.260
p値が2.2e-16なので、2群の平均値に差がないという帰無仮説は危険率pで棄却される。つまり差があると言ってよい。
参考まで箱ひげ図を書くと下記の通り。
boxplot(df$Species, df$Petal.Length)
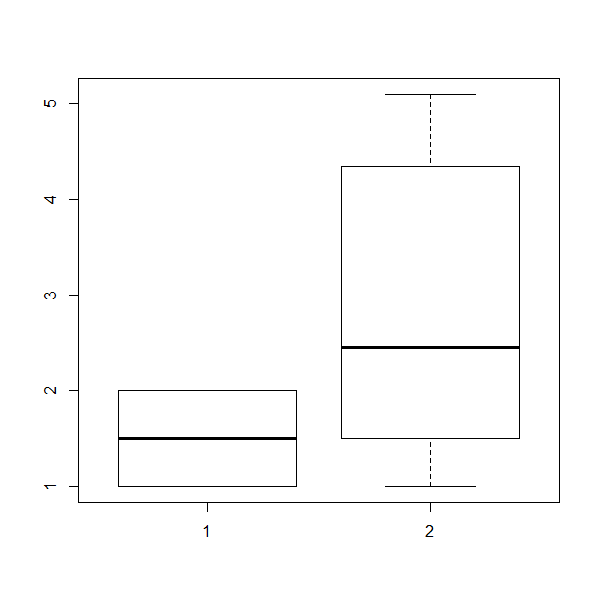
034 3群の検定
irisデータのSpeciesの3群間でPetal.Lengthに差があるかをクラスカルウォリス検定する。
> kruskal.test(iris$Species ~ iris$Petal.Length)
Kruskal-Wallis rank sum test
data: iris$Species by iris$Petal.Length
Kruskal-Wallis chi-squared = 142, df = 42, p-value = 8.813e-13
p値が8.81e-13なので、3群の中央値に差がないという帰無仮説は危険率pで棄却される。つまり、いずれかの群は差がある(3群とも差があることは保証しておらず、少なくとも1群は差があるということ)
misc(035)
035 情報を得る
rは1文字なので検索に掛かりにくい。また、関数を知っていてその意味を調べたいなら検索をすればいいが、こういうことをしたい(特に図)場合にどう検索したらいいかわかりにくい。そんなこと。
- R Search
参考にさせていただいた
別の100本ノック
- テキストマイニング関連
- GUI開発関連