databricksのdata enginner associate試験について模擬試験問題が公開されており、それらの解説
- 45問全問あり
- 現在問30まで
もありますが、問題の解説のみであり、そもそもどういうことが問われているかについてのチャート式風参考書を作成しました。
各項目について 基本事項の解説→問題→チャートと解答 とチャート式参考書風としています。
特別付録「うんこVACUUMドリル」つき
注:
- と頑張ったところで日本語の試験問題が始まったのよね。でも参考になると思うので公開します。
- 筆者環境がAzureなので解説のリンク先はAzureですがAWSでもほぼ同じはずです。
- 筆者はdata engineer associateに合格しています
Databricks Lakehouse Platform / Data Lakehouse
基本事項:データレイクハウスとは、データレイクの柔軟性、コスト効率、スケーラビリティと、データウェアハウスのデータ管理とACIDトランザクションを組み合わせた、新しいオープンデータ管理アーキテクチャ。
これにより、すべてのデータでビジネスインテリジェンス(BI)と機械学習(ML)が可能になる。
- データウェアハウスは、データの整合性とパフォーマンスを重視しているが、データレイクよりも柔軟性とコスト効率が低い傾向があります。
- データレイクは、データの柔軟性とスケーラビリティを重視していますが、データウェアハウスよりもデータの整合性とパフォーマンスが低い傾向があります。
- データレイクハウスは、これらの長所を組み合わせることで、データの分析と活用をより効率的に行うことができる。
- 具体的には、データレイクハウスは以下のメリットがあります。
- データの柔軟性とスケーラビリティ
- データの整合性とパフォーマンス
- コスト効率
- データレイクハウスは、データの分析と活用をより効率的に行うための強力なツール
- バッチ処理・分析とストリーミング処理・分析の両方が可能
Question 1
Which of the following describes a benefit of a data lakehouse that is unavailable in a traditional data warehouse?
- A. A data lakehouse provides a relational system of data management.
- B. A data lakehouse captures snapshots of data for version control purposes.
- C. A data lakehouse couples storage and compute for complete control.
- D. A data lakehouse utilizes proprietary storage formats for data.
- E. A data lakehouse enables both batch and streaming analytics.
解答
- チャート:構造化データ・非構造化データに対応。バッチ・ストリーミング分析に対応。大容量高速処理を低コストにて。などの基本事項は覚えておく。
- 解答:A. リレーショナルだけに限っていない。B. バージョンコントロール目的ではない。C. 計算リソースは他のクラウドと連携している。D. オープンなフォーマットを用いている。
- E.
Databricks Lakehouse Platform / control plane & computing plane
基本事項:全てdatabricks上で操作するので分かりにくいがcontrol/computingの領域が分かれている(セキュリティやコスト面で優れているよとの意図)
| control plane | computing plane |
|---|---|
| databricksによって管理されている場所 | データが処理される場所(customer's cloud account) |
|
|
Question 2
Which of the following locations hosts the driver and worker nodes of a
Databricks-managed cluster?
- A. Data plane
- B. Control plane
- C. Databricks Filesystem
- D. JDBC data source
- E. Databricks web application
解答
- チャート:control(管理)とcomputing(計算とデータリソース)に分ける
- 解答:wokerなので計算リソースであり、Data planeにある
- A.
Databricks Lakehouse Platform / Data Lakehouse
【再掲】
基本事項:データレイクハウスとは、データレイクの柔軟性、コスト効率、スケーラビリティと、データウェアハウスのデータ管理とACIDトランザクションを組み合わせた、新しいオープンデータ管理アーキテクチャ
これにより、すべてのデータでビジネスインテリジェンス(BI)と機械学習(ML)が可能になる
- データウェアハウスは、データの整合性とパフォーマンスを重視しているが、データレイクよりも柔軟性とコスト効率が低い傾向がある
- データレイクは、データの柔軟性とスケーラビリティを重視していますが、データウェアハウスよりもデータの整合性とパフォーマンスが低い傾向がある
- データレイクハウスは、これらの長所を組み合わせることで、データの分析と活用をより効率的に行うことができる
- 具体的には、データレイクハウスは以下のメリットがあります。
- データの柔軟性とスケーラビリティ
- データの整合性とパフォーマンス
- コスト効率
- データレイクハウスは、データの分析と活用をより効率的に行うための強力なツール
- 具体的には、データレイクハウスは以下のメリットがあります。
Question 3
A data architect is designing a data model that works for both video-based machine learning workloads and highly audited batch ETL/ELT workloads.
Which of the following describes how using a data lakehouse can help the data architect meet the needs of both workloads?
- A. A data lakehouse requires very little data modeling.
- B. A data lakehouse combines compute and storage for simple governance.
- C. A data lakehouse provides autoscaling for compute clusters.
- D. A data lakehouse stores unstructured data and is ACID-compliant.
- E. A data lakehouse fully exists in the cloud.
解答
- チャート: Data Lakehouseの特徴。構造・非構造データにもACID対応していること
- 解答: A. こういうことはない。B., C., E. 題意と直接関係ない。D. 非構造データかつACIDによりビデオデータの機械学習に対応できる。
- D.
Databricks Lakehouse Platform / Cluster
Azure Databricks で使用できるコンピューティングの種類は次のとおり
| Compute(クラスター)の種類 | 特徴 | 起動停止 |
|---|---|---|
| All-Purpose Compute | 対話型ノートブックを使って共同作業でデータを分析するため | UI、CLI、または REST API を使って作成、終了、再起動できる |
| ジョブコンピューティング | 高速で堅牢な自動ジョブを実行するために使用する | ジョブスケジューラによって、新しいコンピューティングでジョブを実行するときにジョブコンピューティングが作成される。 そのコンピューティングは、ジョブが完了すると終了する。再起動はできない |
| インスタンスプール | アイドル状態ですぐに使用できるインスタンスを含むコンピューティングであり、起動と自動スケールの時間を短縮するために使用する | UI、CLI、または REST API を使って作成できる |
| サーバーレスSQLウェアハウス | SQLエディターまたは対話型ノートブックでデータオブジェクトに対してSQL コマンドを実行するために使われるオンデマンドのエラスティックコンピューティング | UI、CLI、または REST API を使って作成できる |
| クラシックSQLウェアハウス | SQLエディターまたは対話型ノートブックでデータオブジェクトに対してSQLコマンドを実行するために使われるプロビジョニング済みコンピューティング | UI、CLI、または REST API を使って作成できまる |
備考:Compute、Clusterはどちらもほぼ同じ意味で使われている。WarehouseはSQL実行のリソースとして使われる。
Question 4
Which of the following describes a scenario in which a data engineer will want to use a Job cluster instead of an all-purpose cluster?
- A. An ad-hoc analytics report needs to be developed while minimizing compute costs.
- B. A data team needs to collaborate on the development of a machine learning model.
- C. An automated workflow needs to be run every 30 minutes.
- D. A Databricks SQL query needs to be scheduled for upward reporting.
- E. A data engineer needs to manually investigate a production error.
解答
- チャート: all-purpose clusterをJob Clusterに置き換える理由なので、自動ジョブに関連する
- 解答: A. アドホック分析ならばall-purpose clusterが良い。B. 機械学習か否かは直接関係なく共同で開発するならばどちらかというとall-purpose cluster。D. SQLウェアハウス。E. これも自動化の逆なのでall-purpose cluster。C. 定時の自動化ジョブなのでJob Clusterが適している。
- C.
Data Governance / Catalog Explorer
基本事項:Data ExplorerはCatalog Explorerに名称変更しており、データ、スキーマ(DB)、テーブル、モデル、関数等を管理するUIツールである。下記の機能を有している
- アクセス許可の管理
- 所有者を管理する
- モデルを調査する
- エンティティ関係図を表示する
- AI によって生成されたコメントをテーブルに追加する
- マークダウン コメントを使用したカタログ エクスプローラーでのデータのドキュメント化
Question 5
A data engineer has created a Delta table as part of a data pipeline. Downstream data analysts now need SELECT permission on the Delta table. Assuming the data engineer is the Delta table owner, which part of the Databricks Lakehouse Platform can the data engineer use to grant the data analysts the appropriate access?
- A. Repos
- B. Jobs
- C. Data Explorer
- D. Databricks Filesystem
- E. Dashboards
解答
- チャート:データベースの権限設定はCatalog Explorer(Data Explorer)にて行う。
- 解答: A. バージョン管理。B. ジョブ管理。D. ファイルシステム。E. データ可視化のダッシュボード。C. 古い資料ではData Explorerとなっているが現在はCatalog Explorerとなっており試験でも後者のはずなので要注意。
- C.
Databricks Lakehouse Platform / Notebook
基本事項:Azure Databricks では、ノートブックは、データ サイエンスと機械学習ワークフローを作成し、同僚とコラボレーションするための主要なツールです
- Python、SQL、Scala、R を使用してコードを開発する。
- 任意のライブラリを使用して環境をカスタマイズする。
- 定期的にスケジュールされたジョブを作成して、マルチノートブック ワークフローを含むタスクを自動的に実行する。
- テーブルとボリュームを参照してアクセスする。
- 結果とノートブックを .html または .ipynb 形式でエクスポートする。
- Git ベースのリポジトリを使用して、関連付けられているファイルと依存関係を含むノートブックを保存する。
- ダッシュボードを作成して共有する。
- Delta Live Tables パイプラインを開くか実行する。
Question 6
Two junior data engineers are authoring separate parts of a single data pipeline notebook. They are working on separate Git branches so they can pair program on the same notebook simultaneously. A senior data engineer experienced in Databricks suggests there is a better alternative for this type of collaboration.
Which of the following supports the senior data engineer’s claim?
- A. Databricks Notebooks support automatic change-tracking and versioning
- B. Databricks Notebooks support real-time coauthoring on a single notebook
- C. Databricks Notebooks support commenting and notification comments
- D. Databricks Notebooks support the use of multiple languages in the same notebook
- E. Databricks Notebooks support the creation of interactive data visualizations
解答
- チャート:Notebookを用いると共同編集ができる。
- 解答:A. Reposの機能であり直接関係ない。C. も別の機能。D., E. はNotebookの機能だが直接関係ない。
- B.
Databricks Lakehouse Platform / Repos, Git, CI/CD
基本事項:ReposとCI/CDツールを連携させることで、コード変更時にCI/CDパイプラインをトリガーし、自動化されたビルド、テスト、デプロイを実現できる
具体的な手順は以下の通り
- Gitリポジトリにコードをプッシュ
- Databricks ReposがGitリポジトリの変更を検知
- Databricks ReposがCI/CDツール(例:Azure DevOps、CircleCI、Jenkins等)にプッシュイベントを通知
- CI/CDツールが自動的にビルド、テスト、デプロイのパイプラインを実行
このようにDatabricks ReposはGitリポジトリの変更を監視し、CI/CDツールとの連携によりパイプラインのトリガーを行うことで、継続的なインテグレーションとデプロイを実現できる
【参考】
基本事項:ReposはGitと連携して下記ができる
- リモート Git リポジトリを複製、プッシュ、プルする。
- マージ、リベース、競合の解決などを含む、開発作業用のブランチを作成および管理します(削除はない)。
- ノートブック (IPYNB ノートブックを含む) を作成し、それらのノートブックと他のファイルを編集します。
- コミット時の相違点を視覚的に比較し、マージの競合を解決します。
Gitの基本事項が問われることもある
| コマンド | 操作 |
|---|---|
| Push | ローカルの変更をリモートに反映させる |
| Pull | リモートの変更をローカルに反映 |
| Clone | リモートの内容をそのままローカルにコピーする |
| Merge | ブランチ間の変更をマージする |
| Commit | ローカル内で変更を反映、履歴に残す |
Question 7
Which of the following describes how Databricks Repos can help facilitate CI/CD workflows on the Databricks Lakehouse Platform?
- A. Databricks Repos can facilitate the pull request, review, and approval process before merging branches
- B. Databricks Repos can merge changes from a secondary Git branch into a main Git branch
- C. Databricks Repos can be used to design, develop, and trigger Git automation pipelines
- D. Databricks Repos can store the single-source-of-truth Git repository
- E. Databricks Repos can commit or push code changes to trigger a CI/CD process
解答
- チャート:
- 解答: A. ブランチをマージする前にプルリクエスト、レビュー、承認のワークフローを容易にするが、これ自体がCI/CDワークフローを説明するものではない。B. Reposは、セカンダリブランチからメインブランチへの変更をマージすることはできず、Gitの機能を使う必要がある。C. Reposは、Gitの自動化パイプラインを直接設計、開発、トリガーすることはできない。D. Reposは、単一のソース付与のGitリポジトリを保存することはできるが、CI/CDワークフローを説明するものではない。E. ReposとCI/CDツールを連携させることで、コード変更をコミットまたはプッシュした時にCI/CDパイプラインをトリガーできる。つまり、コード変更がCI/CDプロセスを開始するきっかけになる。
- E.
Databricks Lakehouse Platform / Delta Lake
基本事項:Delta Lake は、Databricks上のレイクハウスにテーブルの基盤を提供する、最適化されたストレージレイヤー
- Delta Lake は、ACID トランザクションとスケーラブルなメタデータ処理のためのファイルベースのトランザクションログを使用して Parquet データファイルを拡張するオープンソースソフトウェア
- Delta Lake は Apache Spark API と完全に互換性があり、構造化ストリーミングとの緊密な統合のために開発されたため、データの1つのコピーをバッチ操作とストリーミング操作の両方に簡単に使用でき、大規模な増分処理を提供できる
Question 8
Which of the following statements describes Delta Lake?
- A. Delta Lake is an open source analytics engine used for big data workloads.
- B. Delta Lake is an open format storage layer that delivers reliability, security, and performance.
- C. Delta Lake is an open source platform to help manage the complete machine learning lifecycle.
- D. Delta Lake is an open source data storage format for distributed data.
- E. Delta Lake is an open format storage layer that processes data
解答
- チャート:
- 解答: A. 分析エンジンとしているが異なる。C. 機械学習のライフサイクル管理ではない。D. データフォマットではない。E. Delta Lakeはデータの処理よりも、データの保管、管理、整合性の保証。
- B.
ELT with Spark SQL and Python / CREATE TABLE
基本事項:CREATE TABLE構文を覚える
- CREATE TABLE 列と型指定 が基本
- 既存のテーブルがあり置き換える場合は CREATE OR REPLACE TABLE 列と型指定 となる
- 既存のテーブルがない場合のみテーブル作成する場合は IF NOT EXISTS を用いる
- 別テーブルの内容を用いてテーブルを作る場合は CREATE TABLE 列指定 AS SELECT ... となる
- ソースファイルを指定する場合は USING を用いる
{ { [CREATE OR] REPLACE TABLE | CREATE [EXTERNAL] TABLE [ IF NOT EXISTS ] }
table_name
[ table_specification ]
[ USING data_source ]
[ table_clauses ]
[ AS query ] }
Question 9
A data architect has determined that a table of the following format is necessary:
| id | birthDate | avgRating |
|---|---|---|
| a1 | 1990-01-06 | 5.5 |
| a2 | 1974-11-21 | 7.1 |
| … | … | … |
Which of the following code blocks uses SQL DDL commands to create an empty Delta table in the above format regardless of whether a table already exists with this name?
A. CREATE OR REPLACE TABLE table_name AS
SELECT
id STRING,
birthDate DATE,
avgRating FLOAT
USING DELTA
B. CREATE OR REPLACE TABLE table_name (
id STRING,
birthDate DATE,
avgRating FLOAT
)
C. CREATE TABLE IF NOT EXISTS table_name (
id STRING,
birthDate DATE,
avgRating FLOAT
)
D. CREATE TABLE table_name AS
SELECT
id STRING,
birthDate DATE,
avgRating FLOAT
E. CREATE OR REPLACE TABLE table_name WITH COLUMNS (
id STRING,
birthDate DATE,
avgRating FLOAT
) USING DELTA
解答
- チャート:基本構文なので覚える。既存テーブルの有無を問題文からチェック。
- 解答:A. USINGはデータソース指定なので USING DELTAとはしない。C. では逆に既存のテーブルがある場合はテーブル作成しない。D. これは別のテーブルの内容からテーブルを作成する命令であり、かつ文が間違っている(FROMがない)。E. WITH COLUMS のような命令はない。B. が型指定も含めて正しい。
- B.
ELT with Spark SQL and Python / SQL
基本事項:SQLの基本は下記の4つ(他にJOINでの結合やGROUP BYでの集計やORDERによるソートがあるが略)。
| 操作 | 命令 |
|---|---|
| 選択 | SELECT field_name, … FROM table_name [WHERE 選択条件]; |
| 削除 | DELTE FROM table_name [WHERE 選択条件]; |
| 編集 | UPDATE table_name SET filed_name = ‘value’, … [WHERE 選択条件]; |
| 挿入 | INSERT INTO table_name VALUES (‘field_name’ = ‘value’, …); |
注:[...] は必要に応じて付与。Pythonと異なりイコール条件は = (==ではない)
Question 10
Which of the following SQL keywords can be used to append new rows to an existing Delta table?
- A. UPDATE
- B. COPY
- C. INSERT INTO
- D. DELETE
- E. UNION
解答
- チャート:row(レコード)のappend(挿入)はINSERT INTO。
- 解答:A. はレコードの編集。B. はテーブル間のコピー操作。D. はレコードの削除。E. はテーブル結合の演算子。
- C.
ELT with Spark SQL and Python / クエリ最適化
- data skipping
- 不要なデータの読み込みを回避することによりクエリのパフォーマンスを向上させる
- データファイルのメタデータを利用して、クエリに関連ないデータブロックをスキップする
- Z-ordering
- 関連情報を同じファイルセットに併置する手法
- この併置は、Delta Lake on Azure Databricks のデータのスキップアルゴリズムで自動的に使用される
- この動作により、Delta Lake on Azure Databricks が読み取る必要があるデータの量が大幅に削減される
- Zオーダーデータには、順序付けする列を ZORDER BY 句で指定する
- Bin-packing(コンパクション)
- 小さなファイル群を大きなファイルにまとめることで、テーブルから読み込みを行うクエリーのスピードを改善することができる
- OPTIMIZEコマンドを実行することでコンパクションを起動することができる
Question 11
A data engineering team needs to query a Delta table to extract rows that all meet the same condition. However, the team has noticed that the query is running slowly. The team has already tuned the size of the data files. Upon investigating, the team has concluded that the rows meeting the condition are sparsely located throughout each of the data files.
Based on the scenario, which of the following optimization techniques could speed up the query?
- A. Data skipping
- B. Z-Ordering
- C. Bin-packing
- D. Write as a Parquet file
- E. Tuning the file size
解答
- チャート: 条件を満たす行がデータファイル全体に散在している時の最適化対応とは
- 解説: A. 不要なデータをスキップするので異なる。C. 小さなファイル群等の記述はない。D. Delta Tableは全てParquetファイルとなる。E. ファイルサイズとは直接関係ない。
- B.
ELT with Spark SQL and Python / CREATE DATABASE
基本事項:データベース作成の基本構文
- CREATE SCHEMA と CREATE DATABASE は同じ
CREATE SCHEMA [ IF NOT EXISTS ] schema_name
[ COMMENT schema_comment ]
[ LOCATION schema_directory | MANAGED LOCATION location_path ]
[ WITH DBPROPERTIES ( { property_name = property_value } [ , ... ] ) ]
- schema_name
- 作成するスキーマの名前。
- IF NOT EXISTS
- 指定した名前のスキーマが存在しない場合は、作成します。 同じ名前のスキーマが既に存在する場合は、何も行いません。
- LOCATION schema_directory
- LOCATIONは、Unity Catalog ではサポートされていません。 Unity Catalog でスキーマの保存場所を指定する場合は、MANAGED LOCATION を使用します。
Question 12
A data engineer needs to create a database called customer360 at the location /customer/customer360. The data engineer is unsure if one of their colleagues has already created the database.
Which of the following commands should the data engineer run to complete this task?
- A. CREATE DATABASE customer360 LOCATION '/customer/customer360';
- B. CREATE DATABASE IF NOT EXISTS customer360;
- C. CREATE DATABASE IF NOT EXISTS customer360 LOCATION '/customer/customer360';
- D. CREATE DATABASE IF NOT EXISTS customer360 DELTA LOCATION '/customer/customer360';
- E. CREATE DATABASE customer360 DELTA LOCATION '/customer/customer360';
解答
- チャート:基本構文の確認。既存のデータベースの有無を確認するかどうか。ロケーションの指定が正しいかどうか。
- 解答:A., E. 既存のデータベース有無を確認していない。B. LOCATIONの指定がない。D. DELTA LOCATIONという指定はない。
- C.
ELT with Spark SQL and Python / Managed TABLE
A
- マネージドテーブル
- マネージドテーブルは、Unity Catalog にテーブルを作成する際の既定の方法
- Unity Catalog で、これらのテーブルのライフサイクルとファイルレイアウトを管理
- マネージドテーブルは、スキーマとカタログの構成方法に応じて、メタストア、カタログ、またはスキーマレベルで "マネージドストレージ" に保存される
- マネージドテーブルでは、常に Delta テーブル形式を使用
- マネージドテーブルをドロップすると、基になるデータがクラウドテナントから30日以内に削除される
- マネージドテーブルは、Unity Catalog にテーブルを作成する際の既定の方法
- 外部テーブル
- 外部テーブルは、メタストア、カタログ、またはスキーマに対して指定されたマネージドストレージの場所の外部にデータが格納されているテーブル
- 外部テーブルは、Azure Databricks クラスターまたは Databricks SQL ウェアハウスの外部のデータに直接アクセスする必要がある場合にのみ使用
- 外部テーブルで DROP TABLE を実行しても、Unity Catalog では基になるデータは削除されない
- テーブルをドロップするには、その所有者である必要がある。
- 外部テーブルに対する権限を管理し、マネージドテーブルと同じ方法でクエリ内で使用できる
- SQL を使用して外部テーブルを作成するには、CREATE TABLE ステートメントで LOCATION パスを指定する
- 外部テーブルでは次のファイル形式を使用できる
- DELTA, CSV, JSON, AVRO, PARQUET, ORC, TEXT
- 外部テーブルでは次のファイル形式を使用できる
- 外部テーブルの基になるクラウドストレージへのアクセスを管理するために、ストレージ資格情報と外部の場所を設定する必要がある
- 外部テーブルは、メタストア、カタログ、またはスキーマに対して指定されたマネージドストレージの場所の外部にデータが格納されているテーブル
CREATE TABLEの項も参照
https://qiita.com/drafts/0dbdf3941ebcd3769815/edit#elt-with-spark-sql-and-python--create-table
Question 13
A junior data engineer needs to create a Spark SQL table my_table for which Spark manages both the data and the metadata. The metadata and data should also be stored in the Databricks Filesystem (DBFS).
Which of the following commands should a senior data engineer share with the junior data engineer to complete this task?
- A. CREATE TABLE my_table (id STRING, value STRING) USING org.apache.spark.sql.parquet OPTIONS (PATH "storage-path");
- B. CREATE MANAGED TABLE my_table (id STRING, value STRING) USING org.apache.spark.sql.parquet OPTIONS (PATH "storage-path");
- C. CREATE MANAGED TABLE my_table (id STRING, value STRING);
- D. CREATE TABLE my_table (id STRING, value STRING) USING DBFS;
- E. CREATE TABLE my_table (id STRING, value STRING);
解答
- チャート:CREATE TABLEの基本構文とマネージドテーブルと外部テーブルの違いをおさえる。外部テーブルを指定しない限り、マネージドテーブルとしてDELTA TABLEを作成し、DBFSにメタデータとデータが保存される。
- 解答:A. このような指定は不要。B., C. MANAGED という指定は不要。D. USINGは外部ファイルを読み込む時に必要な指定。
- E.
ELT with Spark SQL and Python / VIEW
基本事項:計算結果を再利用するときに、TABLEを作るとリソースを食う、再度クエリを投げると計算時間がかかる、これを解決するために一時的な計算結果表がVIEW。
自分だけで使うか、セッション違い、ワークスペース違いの他者に共有するかでVIEWに違いがある。
| VIEWの種類 | 機能 |
|---|---|
| TEMPORARY VIEW | そのセッションのみで有効。セッションが切れれば消える |
| GLOBAL TEMPORARY VIEW | 他のセッションからもアクセスできる。同上 |
| VIEW | 永続的(明示的に削除しない限り残る)なビュー |
Question 14
A data engineer wants to create a relational object by pulling data from two tables. The relational object must be used by other data engineers in other sessions. In order to save on storage costs, the data engineer wants to avoid copying and storing physical data.
Which of the following relational objects should the data engineer create?
- A. View
- B. Temporary view
- C. Delta Table
- D. Database
- E. Spark SQL Table
解答
- チャート:物理データのコピーを避けたいならばいずれかのVIEW。そのセッションのみか他のセッションでも使うか。永続的かどうか。
- 解答: B. そのセッションでしか使えない。C., D., E Veiwではない。他のセッションでも使うとあり、ViewかGlobal Temporary Viewが該当するが選択肢にあるのはViewのみ。
- A.
ELT with Spark SQL and Python / キャッシュ
基本事項:Parquetデータファイル(Delta Lake テーブルを含む)にすると自動でディスクキャッシュとなり、読み取り高速化、キャッシュ自動更新がなされる
- ディスクキャッシュは、Apache Sparkキャッシュとは異なる
- ほとんどの操作で自動ディスクキャッシュを推奨
- ディスクキャッシュが有効な場合、リモートソースから取り込む必要があるデータは自動的にキャッシュに追加される
- ディスクキャッシュには、リモートデータのローカルコピーが格納される
- サブクエリの結果は保存されない
- Sparkキャッシュには、サブクエリデータの結果およびParquet以外の形式 (CSV、JSON、ORC など) で保存されているデータを保存できる
- ただ、手動での更新が必要
注意:Deltaキャッシュはディスクキャッシュに名称変更されている
Question 15
A data engineering team has created a series of tables using Parquet data stored in an external system. The team is noticing that after appending new rows to the data in the external system, their queries within Databricks are not returning the new rows. They identify the caching of the previous data as the cause of this issue.
Which of the following approaches will ensure that the data returned by queries is always up-to-date?
- A. The tables should be converted to the Delta format
- B. The tables should be stored in a cloud-based external system
- C. The tables should be refreshed in the writing cluster before the next query is run
- D. The tables should be altered to include metadata to not cache
- E. The tables should be updated before the next query is run
解答
- チャート: ディスクキャッシュの使用方法
- 解答: B. キャッシュと直接関係ない。C. 手動実行が必要。D. キャッシュしないのは逆方向。E. キャッシュと直接関係ない。A. Delta formatつまりParquetファイルにすることによりディスクキャッシュが有効になる。
- A.
ELT with Spark SQL and Python / CREATE TABLE
基本事項:テーブルを作成するSQL文。列を定義する場合と、他のテーブルのデータを用いて新しいテーブルを作成する構文がある(CTASと略される)。
コメント付与はどうするか等が問われる。またはCTASの場合ははぜ列を定義しなく良いかも問われることがある(もとのテーブルの定義を使うから)
- 基本は列を定義する
CREATE TABLE table_name (field1 as integer, …);- コメント付与の場合
CREATE TABLE table_name (field1 as integer, …) COMMENT “some comments”;
- コメント付与の場合
- CTASの場合
CREATE TABLE table_name2 AS SELECT * FROM table_name1;- コメント付与の場合
CREATE TABLE table_name2 COMMENT “some comments” AS SELECT * FROM table_name2;
- コメント付与の場合
Question 16
A table customerLocations exists with the following schema:
id STRING,
date STRING,
city STRING,
country STRING
A senior data engineer wants to create a new table from this table using the following
command:
CREATE TABLE customersPerCountry AS
SELECT country,
COUNT(*) AS customers
FROM customerLocations
GROUP BY country;
A junior data engineer asks why the schema is not being declared for the new table.
Which of the following responses explains why declaring the schema is not necessary?
- A. CREATE TABLE AS SELECT statements adopt schema details from the source table and query.
- B. CREATE TABLE AS SELECT statements infer the schema by scanning the data.
- C. CREATE TABLE AS SELECT statements result in tables where schemas are optional.
- D. CREATE TABLE AS SELECT statements assign all columns the type STRING.
- E. CREATE TABLE AS SELECT statements result in tables that do not support schemas.
解答
- チャート:CTASでなぜスキーマの定義が不要かを問う例。元のテーブルのスキーマの定義を用いるから。
- 解答:B. データのスキャンをするわけではない。C., E.スキーマはオプション、不要ではなく必須。D. 全てを文字列型にするということはない。A. ソースとなるテーブルやクエリのスキーマを使うから。
- A.
ELT with Spark SQL and Python / 履歴管理
基本事項:Deltaテーブルの履歴管理とタイムトラベル機能
- Deltaテーブルを変更する操作を行うたびに、テーブルの新しいバージョンが作成される
- 履歴情報を使用し、タイムトラベルを使用することで、下記ができる
- 特定の時点での操作を監査
- テーブルをロールバック
- テーブルに対してクエリを実行
Question 17
A data engineer is overwriting data in a table by deleting the table and recreating the table. Another data engineer suggests that this is inefficient and the table should simply be overwritten instead.
Which of the following reasons to overwrite the table instead of deleting and recreating the table is incorrect?
- A. Overwriting a table is efficient because no files need to be deleted.
- B. Overwriting a table results in a clean table history for logging and audit purposes.
- C. Overwriting a table maintains the old version of the table for Time Travel.
- D. Overwriting a table is an atomic operation and will not leave the table in an unfinished state.
- E. Overwriting a table allows for concurrent queries to be completed while in progress.
解答
- チャート: テーブル上書き時の履歴について
- 解答: A. テーブル上書きはファイルを削除する必要がなく効率的。C. 上書きしたテーブルはTime Travel機能で元に戻せる。D. テーブル上書きはatomic操作であり、処理途中の状態に陥ることはない。E. テーブル上書き中も並行してクエリを実行可能である。は全て正しく、B. テーブルを上書きすると、ログ記録および監査目的のためのクリーンなテーブル履歴が得られる、が誤り。テーブル操作の履歴は残るのでクリーンな履歴ということはない。
- B.
ELT with Spark SQL and Python / SQL
基本事項:DISTINCT 重複する結果を削除したら、テーブル参照から一致する行をすべて選択する
SELECT DISTINCT fild_names, ...
FROM table_reference
WHEREほか略
【参考】
基本事項:Delta Tableのデータ挿入・編集系コマンド。挿入か編集か条件による操作か外部ファイルを読み込むかに着目
- INSERT INTO
- 指定した値を挿入する
- 例
INSERT INTO students VALUES ('Amy Smith', '123 Park Ave, San Jose', 111111);
- UPDATE
- WHEREで条件を指定して値を編集(書き換える)
- 例
UPDATE events SET ignored = DEFAULT WHERE eventType = 'unknown'
- MERGE INTO
- 条件により、更新・挿入・削除を指定する(重複を排除した挿入ができる)
- 例
MERGE INTO target USING source ON target.key = source.key WHEN MATCHED THEN DELETE
- COPY INTO
- 外部ファイルをテーブルに外部ファイルを読み込む
- 例
COPY INTO my_json_data FROM 'abfss://container@storageAccount.dfs.core.windows.net/base/path' FILEFORMAT = JSON FILES = ('f1.json', 'f2.json', 'f3.json', 'f4.json', 'f5.json')
Question 18
Which of the following commands will return records from an existing Delta table my_table where duplicates have been removed?
- A. DROP DUPLICATES FROM my_table;
- B. SELECT * FROM my_table WHERE duplicate = False;
- C. SELECT DISTINCT * FROM my_table;
- D. MERGE INTO my_table a USING new_records b ON a.id = b.id WHEN NOT MATCHED THEN INSERT *;
- E. MERGE INTO my_table a USING new_records b;
解答
- チャート: 冗長を除く命令とは - 解答: A., B. こういう命令はない。D., E. - C.ELT with Spark SQL and Python / SQL join
基本事項:テーブル結合の種類。
- キー項目を指定して判断
| 命令句 | 意味 |
|---|---|
| LEFT JOIN | 左にあるもので結合 |
| FULL OUTER JOIN | 全部(重複は除く) |
| INNER JOIN | 両者にあるもので結合 |
| RIGHT JOIN | 右にあるもので結合 |
| CROSS JOIN | 互いのテーブルの全ての掛け合わせ |
- 行全体で判断
| 命令句 | 意味 |
|---|---|
| UNION | 重複なしの和集合 |
| UNION ALL | 重複ありの和集合 |
| INTERSECT | 積集合 |
| EXCEPT | 引き算のイメージ |

Question 19
A data engineer wants to horizontally combine two tables as a part of a query. They want to use a shared column as a key column, and they only want the query result to contain rows whose value in the key column is present in both tables.
Which of the following SQL commands can they use to accomplish this task?
- A. INNER JOIN
- B. OUTER JOIN
- C. LEFT JOIN
- D. MERGE
- E. UNION
解答
- チャート:キーを使うか、レコード全体か。どちらかのキー・レコードを優先するかどうか。
- 解答:B. 異なる。C. 左側のテーブルのキーにあるもののみ。D. 命令が異なる。E. キーではなくレコード全体による。
- A.
ELT with Spark SQL and Python / SQL高階関数
- filter
- 配列をフィルタ処理する
> SELECT filter(array(1, 2, 3), x -> x % 2 == 1); [1,3] > SELECT filter(array(0, 2, 3), (x, i) -> x > i); [2,3]
- 配列をフィルタ処理する
- flatten
- 入れ子の配列を1つの配列にする
> SELECT flatten(array(array(1, 2), array(3, 4))); [1,2,3,4]
- 入れ子の配列を1つの配列にする
- explode
- 配列の要素、またはマップのキーと値で構成される行のセットを返す
> SELECT explode(array(10, 20)) AS elem, 'Spark'; 10 Spark 20 Spark > SELECT explode(map(1, 'a', 2, 'b')) AS (num, val), 'Spark'; 1 a Spark 2 b Spark
- 配列の要素、またはマップのキーと値で構成される行のセットを返す
- redece
- 配列内の要素を集計する
> SELECT reduce(array(1, 2, 3), 0, (acc, x) -> acc + x); 6 > SELECT reduce(array(1, 2, 3), 0, (acc, x) -> acc + x, acc -> acc * 10); 60
- 配列内の要素を集計する
- slice
- 配列内の指定した要素を返す
> SELECT slice(array(1, 2, 3, 4), 2, 2); [2,3] > SELECT slice(array(1, 2, 3, 4), -2, 2); [3,4]
- 配列内の指定した要素を返す
Question 20
A junior data engineer has ingested a JSON file into a table raw_table with the following
schema:
cart_id STRING,
items ARRAY<item_id:STRING>
The junior data engineer would like to unnest the items column in raw_table to result in a new table with the following schema:
cart_id STRING,
item_id STRING
Which of the following commands should the junior data engineer run to complete this task?
- A. SELECT cart_id, filter(items) AS item_id FROM raw_table;
- B. SELECT cart_id, flatten(items) AS item_id FROM raw_table;
- C. SELECT cart_id, reduce(items) AS item_id FROM raw_table;
- D. SELECT cart_id, explode(items) AS item_id FROM raw_table;
- E. SELECT cart_id, slice(items) AS item_id FROM raw_table;
解答
- チャート:対応する値のリストを返すからexplode
- 解答:A. フィルタ処理。B. 入れ子配列を1つの配列に。C. 集計処理。E. 指定した要素を返す。D. 値のリストを返すので正解。
- D.
ELT with Spark SQL and Python / SQL 配列の要素
基本事項:角かっこを使用して、配列の要素のインデックスを指定。ドットを使用してサブフィールドを抽出
- [] 角かっこを使用して、配列の要素のインデックスを指定。インデックスは0始まり
SELECT raw:store.fruit[0], raw:store.fruit[1] FROM store_data - . ドットを使用してサブフィールドを抽出
SELECT raw:store.book[*].isbn FROM store_data
Question 21
A data engineer has ingested a JSON file into a table raw_table with the following schema:
transaction_id STRING,
payload ARRAY<customer_id:STRING, date:TIMESTAMP, store_id:STRING>
The data engineer wants to efficiently extract the date of each transaction into a table with the following schema:
transaction_id STRING,
date TIMESTAMP
Which of the following commands should the data engineer run to complete this task?
- A. SELECT transaction_id, explode(payload) FROM raw_table;
- B. SELECT transaction_id, payload.date FROM raw_table;
- C. SELECT transaction_id, date FROM raw_table;
- D. SELECT transaction_id, payload[date] FROM raw_table;
- E. SELECT transaction_id, date from payload FROM raw_table;
解答
- チャート:配列形式データを扱う書式を覚える。[] か .
- 解答:
- B.
ELT with Spark SQL and Python / パラメータ化したSQL
基本事項:PySparkでパラメータ化されたクエリを作成・実行すると再利用や自動化に役立つ
- PySparkカスタム文字列フォーマット
query = """ SELECT id1, SUM(v1) AS v1 FROM h20_1e9 WHERE id1 = {id1_val} GROUP BY id1 """ spark.sql(query, id1_val="id016").show() - パラメータマーカー
query = "SELECT item, sum(amount) from some_purchases group by item having item = :item" spark.sql( query, args={"item": "socks"}, ).show()
Question 22
A data analyst has provided a data engineering team with the following Spark SQL query:
SELECT district,
avg(sales)
FROM store_sales_20220101
GROUP BY district;
The data analyst would like the data engineering team to run this query every day. The date at the end of the table name (20220101) should automatically be replaced with the current date each time the query is run.
Which of the following approaches could be used by the data engineering team to efficiently automate this process?
- A. They could wrap the query using PySpark and use Python’s string variable system to automatically update the table name.
- B. They could manually replace the date within the table name with the current day’s date.
- C. They could request that the data analyst rewrites the query to be run less frequently.
- D. They could replace the string-formatted date in the table with a timestamp-formatted date.
- E. They could pass the table into PySpark and develop a robustly tested module on the existing query.
解答
- チャート: PySparkでパラメータ化されたクエリを作成
- 解答: B. 手動変更では自動化ではない。C. 毎日の実施が必要なのに更新頻度を下げては逆の対応。D. 日付の方を変えることは自動実行とは関係ない。E. 自動実行とは関係ない。テーブル名をPythonでパラメータ化してPySparkに渡すのが適切な対応。
- A.
ELT with Spark SQL and Python / PySpark SQL
基本事項:PySparkでのSQLテーブル操作の基本
| 関数 | 操作 |
|---|---|
| createTable | テーブルを作成する(データフレームを直接取り扱うものではない) |
| write.save | データフレームをファイルとして保存する |
| saveAsTable | データフレームをテーブルとして保存する |
| createOrReplaceTempView | データフレームをglobal temporary viewとして作成か(すでに同じ名前であれば)置換えする(Sparkのセッションがある時だけに存在) |
Question 23
A data engineer has ingested data from an external source into a PySpark DataFrame raw_df. They need to briefly make this data available in SQL for a data analyst to perform a quality assurance check on the data.
Which of the following commands should the data engineer run to make this data available in SQL for only the remainder of the Spark session?
- A. raw_df.createOrReplaceTempView("raw_df")
- B. raw_df.createTable("raw_df")
- C. raw_df.write.save("raw_df")
- D. raw_df.saveAsTable("raw_df")
- E. There is no way to share data between PySpark and SQL.
解答
- チャート:データフレームを扱う操作かつセッション内のみで永続的でないのは?
- 解答: B. データフレームを扱う操作ではない。C. ファイルへの書き出し。D. 永続的なテーブルを作成。E. 様々な関数が存在する。A. そのセッションでのみ存在するVIEWを作成する。
- A.
ELT with Spark SQL and Python / Python SQL
基本事項:SQL文内で用いるPythonのf書式
databricksに直接関係なくdatabricks内で用いるPython文法が問われることがありその一つ。
基本的な書式は、文字列変数str1, str2があり、それを " and " でつなげたい場合
f'{str1} and {str2}'
と書く。
Question 24
A data engineer needs to dynamically create a table name string using three Python variables: region, store, and year. An example of a table name is below when region = "nyc", store = "100", and year = "2021":
nyc100_sales_2021
Which of the following commands should the data engineer use to construct the table name in Python?
- A. "{region}+{store}+_sales_+{year}"
- B. f"{region}+{store}+_sales_+{year}"
- C. "{region}{store}_sales_{year}"
- D. f"{region}{store}_sales_{year}"
- E. {region}+{store}+"_sales_"+{year}
解答
- チャート: f"{str1} and {str2}"
- 解答: A., C. fがなく、変数認識されずこのままの文字列となる。E. {regin}+{sgtreo}+ の箇所が文字列でもなく、文法に合った足し算でもなくエラーとなる。B., D. はf書式に則っているがそれぞれ
- B. nyc+100+sales_+2021
- ""内で文字列結合に + は不要でそのまま '+' 文字として表される
- D. nyc100_sales_2021
- よって正解は D.
- B. nyc+100+sales_+2021
Incremental Data Processing / spark.readStream.table()
基本事項:単にsparkの書式なので覚えるしかないが、これが出たら確実に答えは1つなので、覚えよう
- バッチ読み込み spark.read / ストリーミング読み込み spark.readStream
- テーブルから読み込み .table(“hoge”) / ファイルパスから読み込み .load(“/hoge1/hoge2”)
| バッチ | ストリーミング | |
|---|---|---|
| テーブル hoge | spark.read.table(“hoge”) | spark.readStream.table(“hoge”) |
| ファイルパス /hoge1/hoge2 | spark.read.load(“/hoge1/hoge2”) | spark.readStream.load(“hoge”) |
Question 25
A data engineer has developed a code block to perform a streaming read on a data source.
The code block is below:
(spark
.read
.schema(schema)
.format("cloudFiles")
.option("cloudFiles.format", "json")
.load(dataSource)
)
The code block is returning an error.
Which of the following changes should be made to the code block to configure the block to successfully perform a streaming read?
- A. The .read line should be replaced with .readStream.
- B. A new .stream line should be added after the .read line.
- C. The .format("cloudFiles") line should be replaced with .format("stream").
- D. A new .stream line should be added after the spark line.
- E. A new .stream line should be added after the .load(dataSource) line.
解答
- チャート: 問題文から、データソースからのストリーミング読み込み、であり基本構文から。
- 解答: B., C., D., E. ".read"はバッチ処理なのでそれを残して何か追加や置換えをしてもだめ。A. ".read"を".readStream"に置き換えるとストリーミング処理となる。
- A.
Incremental Data Processing / trigger
基本事項:Apache Spark 構造化ストリーミングは、データを段階的に処理する。バッチ処理のトリガー間隔を制御し、準リアルタイムの処理として実施できる
- デフォルト500ms
- 間隔の変更は
- trigger(processingTime=”時間”)
- 時間は OO seconds/minutes 等
- trigger(processingTime=”時間”)
- 一度だけの実行ならば
- trigger(once=True)
Question 26
A data engineer has configured a Structured Streaming job to read from a table, manipulate the data, and then perform a streaming write into a new table.
The code block used by the data engineer is below:
(spark.table("sales")
.withColumn("avg_price", col("sales") / col("units"))
.writeStream
.option("checkpointLocation", checkpointPath)
.outputMode("complete")
._____
.table("new_sales")
)
If the data engineer only wants the query to execute a single micro-batch to process all of the available data, which of the following lines of code should the data engineer use to fill in the blank?
- A. trigger(once=True)
- B. trigger(continuous="once")
- C. processingTime("once")
- D. trigger(processingTime="once")
- E. processingTime(1)
解答
- チャート:一度だけの実行ならばtrigger(onde=True)
- 解答:B., C., E. は構文が異なる。D. はprocessingTimeは間隔指定の場合。
- A.
Incremental Data Processing / Auto Loader
基本事項:Apache Sparkのストーリーミング処理において、クラウドストレージに到着した新しいデータファイルを段階的かつ効率的に処理する。
書式
spark.readStream.format(fileFormat).load(directory)
以下の利点がある
- スケーラビリティ
- 自動ローダーでは、数十億のファイルを効率的に検出できる
- パフォーマンス
- 自動ローダーを使用してファイルを検出するコストは、ファイルが格納されている可能性のあるディレクトリの数ではなく、取り込まれているファイルの数に応じて増減する
過去に処理されたファイルはスキップされ、重複読み込みを防ぎ効率的な読み込みを実現
- 自動ローダーを使用してファイルを検出するコストは、ファイルが格納されている可能性のあるディレクトリの数ではなく、取り込まれているファイルの数に応じて増減する
- スキーマの推論と展開のサポート
- 自動ローダーでは、スキーマドリフトを検出し、スキーマの変更が発生した場合に通知して、通知されなかった場合は無視または失われていたはずのデータを保護できる
- コスト
- 自動ローダーでは、ネイティブ クラウド API を使用して、ストレージに存在するファイルの一覧を取得し、ファイル検出のコストを大幅に削減
Question 27
A data engineer is designing a data pipeline. The source system generates files in a shared directory that is also used by other processes. As a result, the files should be kept as is and will accumulate in the directory. The data engineer needs to identify which files are new since the previous run in the pipeline, and set up the pipeline to only ingest those new files with each run.
Which of the following tools can the data engineer use to solve this problem?
- A. Databricks SQL
- B. Delta Lake
- C. Unity Catalog
- D. Data Explorer
- E. Auto Loader
解答
- チャート: 問題文より、パイプラインの前回の実行以降に新しいファイルを特定し、パイプラインの実行ごとにそれらの新しいファイルのみを取り込む、というところからAuto Loader。
- 解答: A. SQL自体にはこの機能はない。B. 同じくDelta Lake自体にはこの機能はない。C. テーブルデータとメタデータの管理機能。D. DBやテーブルの管理機能。
- E.
Incremental Data Processing / Auto Loader 書式
基本事項:基本書式を覚える。
- 基本書式
df = spark.readStream.format("cloudFiles") \ .option("cloudFiles.format", <format>) \ .schema(schema) \ .load("<base-path>/*/files") - schemaLocationを用いる場合
spark.readStream.format("cloudFiles") \ .option("cloudFiles.format", "json") \ .option("cloudFiles.schemaLocation", "<path-to-schema-location>") \ .load("<path-to-source-data>") \
Question 28
A data engineering team is in the process of converting their existing data pipeline to utilize Auto Loader for incremental processing in the ingestion of JSON files. One data engineer comes across the following code block in the Auto Loader documentation:
(streaming_df = spark.readStream.format("cloudFiles")
.option("cloudFiles.format", "json")
.option("cloudFiles.schemaLocation", schemaLocation)
.load(sourcePath))
Assuming that schemaLocation and sourcePath have been set correctly, which of the following changes does the data engineer need to make to convert this code block to use Auto Loader to ingest the data?
- A. The data engineer needs to change the format("cloudFiles") line to format("autoLoader").
- B. There is no change required. Databricks automatically uses Auto Loader for streaming reads.
- C. There is no change required. The inclusion of format("cloudFiles") enables the use of Auto Loader.
- D. The data engineer needs to add the .autoLoader line before the .load(sourcePath) line.
- E. There is no change required. The data engineer needs to ask their administrator to turn on Auto Loader
解答
- チャート: 基本書式を覚えるしかない。
- 解答: A. format("autoLoader")という指定はない。B. Auto Loaderの指定をしないと自動では実施しない。D. .autoLoaderという指定はない。E. 管理者の操作ではない。C. schemaLocationを用いるときの書式通りとなっている。
- C.
Incremental Data Processing / medarion
基本事項:データ加工は、生データ-Bronds-Silver-Gold-アプリで活用となっており、これをメダリオンアーキテクチャーと呼ぶ
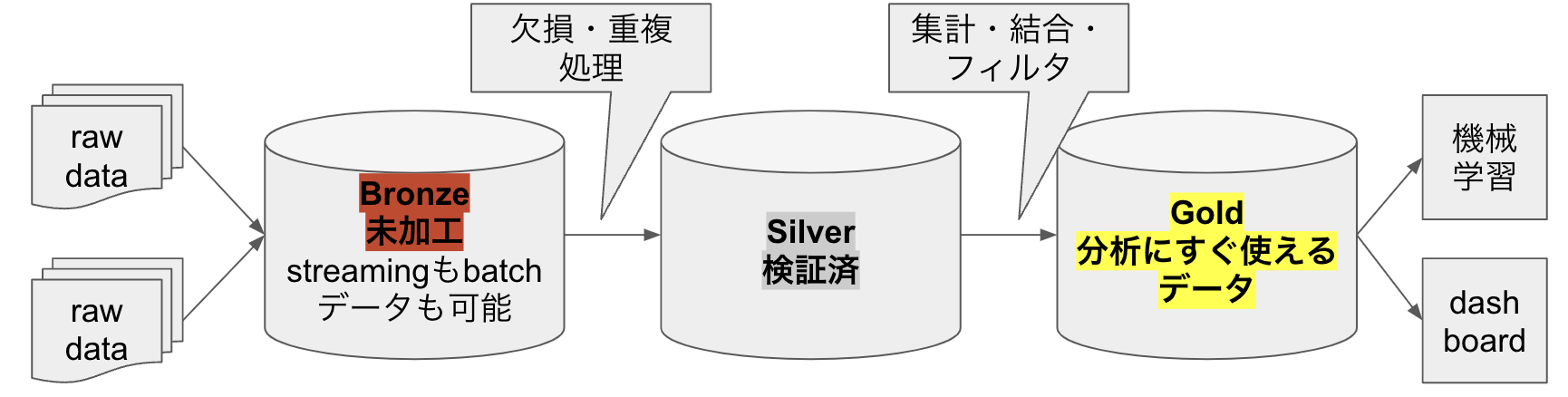
- BronzeからSilverの工程では欠損・重複を取り除くほかに、タイムスタンプを整えたり、最低限の集計をすることもある。
Question 29
Which of the following data workloads will utilize a Bronze table as its source?
- A. A job that aggregates cleaned data to create standard summary statistics
- B. A job that queries aggregated data to publish key insights into a dashboard
- C. A job that ingests raw data from a streaming source into the Lakehouse
- D. A job that develops a feature set for a machine learning application
- E. A job that enriches data by parsing its timestamps into a human-readable format
解答
- チャート:Bonzeテーブルをソースとして用いるのは?でBronzeからSilverの欠損・重複処理の工程。
- 解答:A. 集計されたクリーンなデータではない。B. 集計されたデータではない。C. 生データをBronzeに入れる工程。D. 機械学習用の特徴量セットを作るのはGoldから。E. 生データままのBronzeに最低限の処理を施すのでこれが正解。
- E.
Question 30
Which of the following data workloads will utilize a Silver table as its source?
A. A job that enriches data by parsing its timestamps into a human-readable format
B. A job that queries aggregated data that already feeds into a dashboard
C. A job that ingests raw data from a streaming source into the Lakehouse
D. A job that aggregates cleaned data to create standard summary statistics
E. A job that cleans data by removing malformatted records
解答
- チャート:Silverテーブルをソースとして用いるのは?・・・
- 解答:A. 全問通り、Bronzeテーブルをソースとした工程。B. Goldテーブルをソースとした工程。C. 生データからBronzeへの工程。E. BronzeからSilver。D. 整形されたデータを必要な集計をする工程でこれにあたる。
- D.
Question 31
Which of the following Structured Streaming queries is performing a hop from a Bronze table to a Silver table?
- A. (spark.table("sales")
.groupBy("store")
.agg(sum("sales"))
.writeStream
.option("checkpointLocation", checkpointPath)
.outputMode("complete")
.table("aggregatedSales")
)
- B. (spark.table("sales")
.agg(sum("sales"),
sum("units"))
.writeStream
.option("checkpointLocation", checkpointPath)
.outputMode("complete")
.table("aggregatedSales")
)
- C. (spark.table("sales")
.withColumn("avgPrice", col("sales") / col("units"))
.writeStream
.option("checkpointLocation", checkpointPath)
.outputMode("append")
.table("cleanedSales")
)
- D. (spark.readStream.load(rawSalesLocation)
.writeStream
.option("checkpointLocation", checkpointPath)
.outputMode("append")
.table("uncleanedSales")
)
- E. (spark.read.load(rawSalesLocation)
.writeStream
.option("checkpointLocation", checkpointPath)
.outputMode("append")
.table("uncleanedSales")
)
解答
- チャート:BrozeからSilverの欠損・重複などを取り除く工程。コードの入力・処理・出力を読み取る。
- 解答:A., B. 集計をしている。SilverからGoldの工程。D., E. 生データを読み取りuncleandSalesと未整形のテーブルに保存しているので生データからBronzeへの工程。C. 最低限の集計をしてcleanedSalesと整形ずみのテーブルとしている。
- C.
Production Pipelines / Pipelineの特徴
基本事項:パイプラインは、Delta Live Tablesでデータ処理ワークフローの構成と実行に使用されるメインユニット。
- パイプライン内には、Python または SQL のソースファイル内で宣言される、具体化されたビューやストリーミングテーブルが含まれる。
- Delta Live Tables には、それらのテーブル間の依存関係を推測し、正しい順序で更新処理が行われるようにする機能がある。
- 個々のデータセットについて、Delta Live Tables は現在の状態と望ましい状態を比較し、効率的な処理方法によってデータセットの作成または更新を進める。
Question 32
Which of the following benefits does Delta Live Tables provide for ELT pipelines over standard data pipelines that utilize Spark and Delta Lake on Databricks?
- A. The ability to declare and maintain data table dependencies
- B. The ability to write pipelines in Python and/or SQL
- C. The ability to access previous versions of data tables
- D. The ability to automatically scale compute resources
- E. The ability to perform batch and streaming queries
解答
- チャート: パイプラインの基本事項を押さえる。
- 解答: B. Delta Lake以外のパイプラインでもこれは可能。C. バージョン管理機能はない。D. リソース管理はしない。E. 微妙だが、Delta Lake以外のパイプラインでもこれは可能。A. テーブル間の依存関係に対応した処理が可能が正しい。
- A.
Production Pipelines / Pipelineの特徴2
重要事項:ジョブページでパイプラインを作成する
- ジョブで複数のタスクを調整して、データ処理ワークフローを実装する。
- Delta Live Tables パイプラインをジョブに含めるには、ジョブの作成時にパイプラインタスクを使用する。
Question 33
A data engineer has three notebooks in an ELT pipeline. The notebooks need to be executed in a specific order for the pipeline to complete successfully. The data engineer would like to use Delta Live Tables to manage this process.
Which of the following steps must the data engineer take as part of implementing this pipeline using Delta Live Tables?
- A. They need to create a Delta Live Tables pipeline from the Data page.
- B. They need to create a Delta Live Tables pipeline from the Jobs page.
- C. They need to create a Delta Live tables pipeline from the Compute page.
- D. They need to refactor their notebook to use Python and the dlt library.
- E. They need to refactor their notebook to use SQL and CREATE LIVE TABLE keyword.
解答
- チャート: パイプラインはジョブページで作成する。
- 解答: A. Dataページではない。C. Computeページではない。D., E. Notebookではない。
- B.
Incremental Data Processing / LIVE TABLE
基本事項:LIVE TABLE作成の文法について覚えるしかない
- jsonファイルを読み込む場合
CREATE OR REFRESH LIVE TABLE taxi_raw AS SELECT * FROM json.`/databricks-datasets/nyctaxi/sample/json/` - 他のテーブルから作成する場合
CREATE OR REFRESH LIVE TABLE filtered_data AS SELECT ... FROM LIVE.taxi_raw - "OR REFRESH" は既存のLIVE TABLEがあれば置き換えの意味で既存テーブルがなければこの指定は不要
Question 34
A data engineer has written the following query:
SELECT *
FROM json.`/path/to/json/file.json`;
The data engineer asks a colleague for help to convert this query for use in a Delta Live Tables (DLT) pipeline. The query should create the first table in the DLT pipeline.
Which of the following describes the change the colleague needs to make to the query?
- A. They need to add a COMMENT line at the beginning of the query.
- B. They need to add a CREATE LIVE TABLE table_name AS line at the beginning of the query.
- C. They need to add a live. prefix prior to json. in the FROM line.
- D. They need to add a CREATE DELTA LIVE TABLE table_name AS line at the beginning of the query.
- E. They need to add the cloud_files(...) wrapper to the JSON file path
解答
- チャート: Delta Live Tableを作成するための基本構文。
- 解答: A. COMMENTは関係ない。C. "live."という指定はない。D. "CREATE DELTA LIVE TABLE"という指定はない。E. AutoLoaderを用いる場合は"cloud_files()"の指定をするが、そもそもCREATE LIVE TABLEの指定がないのでだめ。
- B.
Incremental Data Processing / Constraint
基本事項:テーブルのデータの品質を高めるために制約を設け、それに合わないデータは保持する、削除する、処理を失敗させる。それぞれログに残す
CONSTRAINT table_name EXPECT 条件 [ VIOLATION DROP ROW | VIOLATION FAIL ]
| 命令 | 操作 |
|---|---|
| EXPECTのみ | 不正なレコードを保持する |
| VIOLATION DROP ROW | 不正なレコードを削除する |
| VIOLATION FAIL | 不正なレコードで処理を失敗させる |
Question 35
A dataset has been defined using Delta Live Tables and includes an expectations clause:
CONSTRAINT valid_timestamp EXPECT (timestamp > '2020-01-01')
What is the expected behavior when a batch of data containing data that violates these constraints is processed?
- A. Records that violate the expectation are added to the target dataset and recorded as invalid in the event log.
- B. Records that violate the expectation are dropped from the target dataset and recorded as invalid in the event log.
- C. Records that violate the expectation cause the job to fail.
- D. Records that violate the expectation are added to the target dataset and flagged as invalid in a field added to the target dataset.
- E. Records that violate the expectation are dropped from the target dataset and loaded into a quarantine table.
解答
- チャート: EXPECTのみの時の挙動
- 解答: B. "VIOLATION DROP ROW"。C. "VIOLATION FAIL"。D. データセットにフラグ付与はしない。E. quarantineテーブルへの挿入などはない。A. データはテーブルに保持し、異常な旨をイベントログに残す、が正解。
- A.
Production Pipelines / Production/Development; Continuous/Triggered
基本事項:Delta Live Tables は、信頼性、保守性、テスト可能性に優れたデータ処理パイプラインを構築するための宣言型フレームワーク
| モード | 内容 |
|---|---|
| Production mode | ジョブ終了後即座(5分後)にクラスターが終了する |
| Development mode | ジョブ終了後2時間クラスターが稼働し続ける |
- 一見するとProductionの方がクラスターが稼働し続けた方が良さそうだが、必要なジョブが終了したらクラスターは不要。Development時の方が試行錯誤でジョブを立てたり終わらせたりするのでクラスターが動いていた方が良い
| モード | 内容 |
|---|---|
| Continuous | 常にアクティブなジョブを実行かつ1つの起動があることを保証。ジョブが正常・異常に関わらず終了した場合は自動的に次のジョブが起動する(逆に2つ以上は起動しない) |
| Triggered | 定時にジョブを実行する。指定した時刻、あるいは毎分・時・日・週・月を指定。タイムゾーンも指定可能 |
Question 36
A Delta Live Table pipeline includes two datasets defined using STREAMING LIVE TABLE.
Three datasets are defined against Delta Lake table sources using LIVE TABLE.
The table is configured to run in Development mode using the Triggered Pipeline Mode.
Assuming previously unprocessed data exists and all definitions are valid, what is the expected outcome after clicking Start to update the pipeline?
- A. All datasets will be updated once and the pipeline will shut down. The compute resources will be terminated.
- B. All datasets will be updated at set intervals until the pipeline is shut down. The compute resources will be deployed for the update and terminated when the pipeline is stopped.
- C. All datasets will be updated at set intervals until the pipeline is shut down. The compute resources will persist after the pipeline is stopped to allow for additional testing.
- D. All datasets will be updated once and the pipeline will shut down. The compute resources will persist to allow for additional testing.
- E. All datasets will be updated continuously and the pipeline will not shut down. The compute resources will persist with the pipeline.
解答
- チャート: Development mode かつ Triggered Pipeline Mode での挙動について。必要な時にジョブを実行し、クラスターは2時間は稼働し続ける。
- 解答: Devlopment modeなためジョブ終了後すぐクラスターが停止するA., B. は違う。C. はContinuous Mode。E. パイプラインが停止しないのはContinuousモード。
- D.
Production Pipelines / Job
基本事項:
- 失敗したタスクとスキップされたタスクを再実行する
- 失敗した原因を特定したら、失敗したタスクと依存タスクのサブセットのみを再実行できる
- この機能を使用すると、成功したタスクとそれに依存するタスクは再実行されないため、失敗したジョブの実行から回復するために必要な時間が短縮され、必要なリソースも削減される
- 失敗したタスクは、ジョブおよびタスクの現在の設定で再実行される
A. ジョブ全体のリトライポリシーを設定する。
B. タスクの実行を観察し、失敗の原因を特定する。
C. ジョブを複数回実行するように設定し、少なくとも1回は完了するようにする。
D. 定期的に失敗するタスクにリトライポリシーを設定する。
E. ジョブ内の各タスクにジョブクラスターを利用する。
Question 37
A data engineer has a Job with multiple tasks that runs nightly. One of the tasks unexpectedly fails during 10 percent of the runs.
Which of the following actions can the data engineer perform to ensure the Job completes each night while minimizing compute costs?
- A. They can institute a retry policy for the entire Job
- B. They can observe the task as it runs to try and determine why it is failing
- C. They can set up the Job to run multiple times ensuring that at least one will complete
- D. They can institute a retry policy for the task that periodically fails
- E. They can utilize a Jobs cluster for each of the tasks in the Job
解答
- チャート: 再実行かつ計算コストが低いものを選ぶ。
- 解答: A. リトライポリシーを設定するのではなく、失敗したタスクは、ジョブおよびタスクの現在の設定で再実行される。B. 失敗の原因特定は重要だが、これだけでは再実行されない。C. 10%失敗するので、複数回実行設定しても必ずしも1回は成功するかどうかはわからない。E. 再実行について言及がない。
- D.
Production Pipelines / Job依存関係
基本事項:既定では、ジョブタスクは依存関係が実行され、すべて成功したときに実行される
- 特定の条件が満たされた場合にのみ実行されるように Azure Databricks ジョブのタスクを構成することもできる
- タスクの依存関係の実行状態に基づいてタスクを実行するための Run if 依存関係を指定できる
- たとえば、Run if を使用して、依存関係の一部またはすべてが失敗した場合でもタスクを実行し、ジョブを失敗から復旧させて実行を継続させることができる
- If/else condition タスクは、ブール式の結果に基づいてジョブ DAG の一部を実行するために使用される
- If/else condition タスクを使用すると、ジョブに分岐ロジックを追加できる
- タスクの依存関係の実行状態に基づいてタスクを実行するための Run if 依存関係を指定できる
Question 38
A data engineer has set up two Jobs that each run nightly. The first Job starts at 12:00 AM, and it usually completes in about 20 minutes. The second Job depends on the first Job, and it starts at 12:30 AM. Sometimes, the second Job fails when the first Job does not complete by 12:30 AM.
Which of the following approaches can the data engineer use to avoid this problem?
- A. They can utilize multiple tasks in a single job with a linear dependency
- B. They can use cluster pools to help the Jobs run more efficiently
- C. They can set up a retry policy on the first Job to help it run more quickly
- D. They can limit the size of the output in the second Job so that it will not fail as easily
- E. They can set up the data to stream from the first Job to the second Job
解答
- チャート: ジョブの依存関係を指定できる。
- 解答: B. 先行ジョブの遅延については対応できない。C. 先行ジョブのリトライでは遅延に対応できない。D., E. 先行ジョブの遅延についてとは関係ない。A. 依存関係を持たせて先行ジョブの終了を待たせられる。
- A.
Production Pipelines / Jobスケジュール
基本事項:JSON形式の文字列配列を使用してパラメーターを指定する
Question 39
A data engineer has set up a notebook to automatically process using a Job. The data engineer’s manager wants to version control the schedule due to its complexity.
Which of the following approaches can the data engineer use to obtain a version-controllable configuration of the Job’s schedule?
- A. They can link the Job to notebooks that are a part of a Databricks Repo.
- B. They can submit the Job once on a Job cluster.
- C. They can download the JSON description of the Job from the Job’s page.
- D. They can submit the Job once on an all-purpose cluster.
- E. They can download the XML description of the Job from the Job’s page.
解答
- チャート: JSON形式の文字列配列を使用してパラメーターを指定する
- 解答: A., B., D. バージョン管理と直接関係ない。E. パラメータ設定はJSON形式で行われる。
- C.
Production Pipelines / SQL Warehouse
基本事項:サーバーレスSQLウェアハウスのサイズ設定方法
- サーバーレスSQLウェアハウスのクエリ待ち時間を短縮するには、次のようにする
- クエリがディスクに流出する場合(引用者注:メモリに乗り切らないためデータをローカルディスクストレージに退避させていることで「スピル」ともいう。-コメントありがとうございます。参照先も追加しました)は、Tシャツのサイズ(クラスターサイズのこと)を大きくする
- クエリが高度に並列化されている場合は、Tシャツのサイズを大きくする
- 一度に複数のクエリを実行する場合は、自動スケール用にクラスターを追加する
- コストを削減するには、ディスクに流出したり、待ち時間を大幅に増加させることなく、Tシャツのサイズを段階的に小さくする
注意:SQLエンドポイントはSQLウェアハウスに名称変更している
Question 40
A data analyst has noticed that their Databricks SQL queries are running too slowly. They claim that this issue is affecting all of their sequentially run queries. They ask the data engineering team for help. The data engineering team notices that each of the queries uses the same SQL endpoint, but the SQL endpoint is not used by any other user.
Which of the following approaches can the data engineering team use to improve the latency of the data analyst’s queries?
A. They can turn on the Serverless feature for the SQL endpoint.
B. They can increase the maximum bound of the SQL endpoint’s scaling range.
C. They can increase the cluster size of the SQL endpoint.
D. They can turn on the Auto Stop feature for the SQL endpoint.
E. They can turn on the Serverless feature for the SQL endpoint and change the Spot Instance Policy to “Reliability Optimized.”
解答
- チャート: サーバーレスSQLウェアハウスのサイズ設定方法。
- 解答: A. サーバーレスをOnにするとリソースがすぐ割り当てられるが実行速度の遅さには直接関係ない。B. スケールするが必ずしもジョブの負荷に迅速に対応するとは限らない。ジョブの負荷に波があるような場合に対応するのがB. であり、恒常的にジョブが遅い場合は馴染まない。D. 自動停止でコストを下げる目的でありジョブの遅さに対応するものではない。E. 必要な時にリソースを迅速に使いたいという目的であり題意とは異なる。
- C.
Production Pipelines / Jobスケジュール
基本事項:スケジュール機能にてCronを用いて複雑なジョブの実行指定がきる
- スケジュールを使うと、指定した時間と期間に Azure Databricks ジョブを自動的に実行できる
- ジョブを実行するスケジュールは、分単位、時間単位、日単位、週単位、月単位の期間、および時刻を指定して定義できる
- スケジュールのタイムゾーンを指定したり、スケジュールされたジョブをいつでも一時停止したりすることもできる
- クエリエディター内の下記画面で設定する
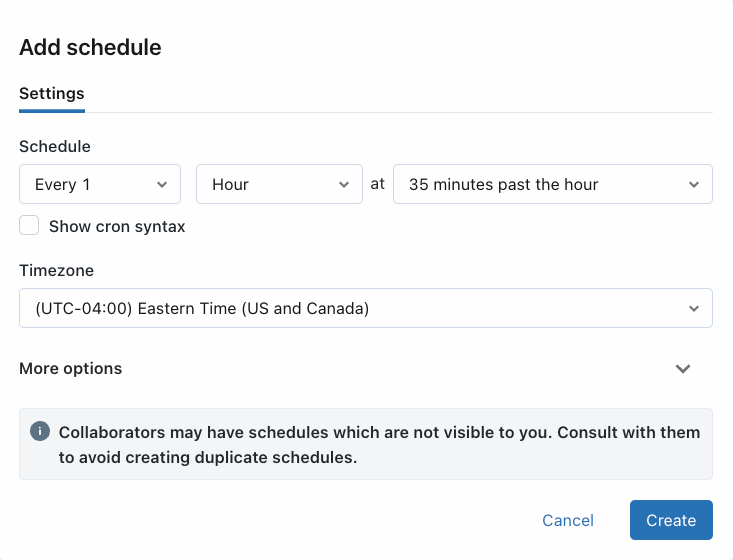
Question 41
An engineering manager uses a Databricks SQL query to monitor their team’s progress on fixes related to customer-reported bugs. The manager checks the results of the query every day, but they are manually rerunning the query each day and waiting for the results.
Which of the following approaches can the manager use to ensure the results of the query are updated each day?
- A. They can schedule the query to run every 1 day from the Jobs UI.
- B. They can schedule the query to refresh every 1 day from the query’s page in Databricks SQL.
- C. They can schedule the query to run every 12 hours from the Jobs UI.
- D. They can schedule the query to refresh every 1 day from the SQL endpoint’s page in Databricks SQL.
- E. They can schedule the query to refresh every 12 hours from the SQL endpoint’s page in Databricks SQL.
解答
- チャート: スケジュール機能の指定場所
- 解答: A., C. ジョブUIではない。D., E. エンドポイントページではない。
- B.
Production Pipelines / アラート
基本事項:SQLアラートは、定期的にクエリを実行し、定義された条件を評価し、条件が満たされた場合に通知を送信する。
- 次のいずれかのオプションを使用してアラートにアクセスする
- サイドバーの[ワークスペース]をクリック
- サイドバーの[アラート]をクリック
- [マイ アラート]タブ
- [名前] には、各アラートの文字列名が表示
- [状態] には、アラートの状態が TRIGGERED、OK、UNKNOWN のいずれであるかが表示
- TRIGGERED
- 最新の実行において、ターゲットクエリの値列が、構成されている条件としきい値を満たしたことを意味する
- "猫"が1500より多いかどうかをチェックするアラートの場合、"猫"が1500を超えている間はアラートがトリガーされる
- 最新の実行において、ターゲットクエリの値列が、構成されている条件としきい値を満たしたことを意味する
- OK
- 最新のクエリの実行において、値列が構成されている条件としきい値を満たさなかったことを意味する。 これは、アラートが以前にトリガーされていないことを意味するものではない
- "猫"の値が現在は 1470 になっている場合は、アラートで OK が示される
- 最新のクエリの実行において、値列が構成されている条件としきい値を満たさなかったことを意味する。 これは、アラートが以前にトリガーされていないことを意味するものではない
- UNKNOWN
- アラートの条件を評価するのに十分なデータが Databricks SQL にないことを意味する
- アラートを作成した直後から、クエリが実行されるまでは、この状態が表示される
- アラートの条件を評価するのに十分なデータが Databricks SQL にないことを意味する
- TRIGGERED
- [最終更新日時] には、最後に更新された時刻または日付が表示
- [作成日時] には、アラートが作成された日時が表示
Question 42
A data engineering team has been using a Databricks SQL query to monitor the performance of an ELT job. The ELT job is triggered by a specific number of input records being ready to process. The Databricks SQL query returns the number of minutes since the job’s most recent runtime.
Which of the following approaches can enable the data engineering team to be notified if the ELT job has not been run in an hour?
- A. They can set up an Alert for the accompanying dashboard to notify them if the returned value is greater than 60.
- B. They can set up an Alert for the query to notify when the ELT job fails.
- C. They can set up an Alert for the accompanying dashboard to notify when it has not refreshed in 60 minutes.
- D. They can set up an Alert for the query to notify them if the returned value is greater than 60.
- E. This type of alerting is not possible in Databricks.
解答
- チャート:
- 解答: A. ダッシュボードは直接関係ない。B. ジョブの失敗をトリガーにしているが、ジョブが実施されなかった場合に通知されない。C. ジョブの実行状態とは関係ない。E. アラート機能はあるので間違い。
- D.
Production Pipelines / ダッシュボードの更新
基本事項:更新のたびに新しいデータかクエリを再実行する必要がある
- ダッシュボードを最新の情報に更新する
- ダッシュボードが古くなるのを防ぐために、ダッシュボードを更新して、関連付けられているクエリを再実行する
- ダッシュボードを手動で最新の情報に更新する
- 強制的に最新の情報に更新するには、ダッシュボードの右上にある [更新] をクリックする
- ダッシュボードのすべてのクエリが実行され、その視覚化が更新される
- 強制的に最新の情報に更新するには、ダッシュボードの右上にある [更新] をクリックする
- ダッシュボードを自動的に最新の情報に更新する
- スケジュールに基づいて自動的に最新の情報に更新されるようにダッシュボードを構成できる
Question 43
A data engineering manager has noticed that each of the queries in a Databricks SQL dashboard takes a few minutes to update when they manually click the “Refresh” button. They are curious why this might be occurring, so a team member provides a variety of reasons on why the delay might be occurring.
Which of the following reasons fails to explain why the dashboard might be taking a few minutes to update?
- A. The SQL endpoint being used by each of the queries might need a few minutes to start up.
- B. The queries attached to the dashboard might take a few minutes to run under normal circumstances.
- C. The queries attached to the dashboard might first be checking to determine if new data is available.
- D. The Job associated with updating the dashboard might be using a non-pooled endpoint.
- E. The queries attached to the dashboard might all be connected to their own, unstarted Databricks clusters.
解答
- チャート: 更新のたびに新しいデータかクエリを再実行する必要がある
- 解答: A. 正しい。B. 正しい。C. 更新時も都度クエリを実行しているので正しい。E. 正しい。D. 更新のため、ジョブの割り当てとは直接関係ない。
- D.
Data Governance / GRANT TABLE
基本事項:GRANT TABLEの基本構文を覚える
GRANT privilege_type ON TABLE table_name TO user_name
権限は下記の通り
| 権限 | 内容 |
|---|---|
| SELECT | オブジェクト(TABLE等)への読み取り権限を付与 |
| CREATE | オブジェクトを作成する権限を付与 |
| MODIFY | オブジェクトにデータを追加、削除、変更する権限を付与 |
| USAGE | 権限は付与せずに、スキーマ オブジェクトに対してアクションを実行するための権限 TABLEの読み取り等はできず存在の有無等の確認まで。API等でTABLE操作する時等に使われるらしい。問題に出ることがある |
| READ_METADATA | オブジェクトとそのメタデータを表示する権限 |
| CREATE_NAMED_FUNCTION | 既存のカタログまたはスキーマに名前付き UDF を作成する権限 |
| MODIFY_CLASSPATH | Spark クラス パスにファイルを追加する権限 |
| ALL PRIVILEGES | すべての権限を付与(上記のすべての権限) “FULL”が選択肢に出ることが多いが”FULL”はない |
【参考】
基本事項:Data ExplolerはCatalog Explolerに名称変更しており、データ、スキーマ(DB)、テーブル、モデル、関数等を管理するUIツールである。下記の機能を有している
- アクセス許可の管理
- 所有者を管理する
- モデルを調査する
- エンティティ関係図を表示する
- AI によって生成されたコメントをテーブルに追加する
- マークダウン コメントを使用したカタログ エクスプローラーでのデータのドキュメント化
Question 44
A new data engineer has started at a company. The data engineer has recently been added to the company’s Databricks workspace as new.engineer@company.com. The data engineer needs to be able to query the table sales in the database retail. The new data engineer already has been granted USAGE on the database retail.
Which of the following commands can be used to grant the appropriate permissions to the new data engineer?
- A. GRANT USAGE ON TABLE sales TO new.engineer@company.com;
- B. GRANT CREATE ON TABLE sales TO new.engineer@company.com;
- C. GRANT SELECT ON TABLE sales TO new.engineer@company.com;
- D. GRANT USAGE ON TABLE new.engineer@company.com TO sales;
- E. GRANT SELECT ON TABLE new.engineer@company.com TO sales;
解答
- チャート:GRANT構文に合っているか。クエリの権限は読み取り権限"SELECT"。
- 解答:A. のUSAGE権限はすでにあるし、クエリ権限ではない。B. は作成の権限。D., E. は構文が違う。
- C.
Question 45
A new data engineer new.engineer@company.com has been assigned to an ELT project. The new data engineer will need full privileges on the table sales to fully manage the project.
Which of the following commands can be used to grant full permissions on the table to the new data engineer?
- A. GRANT ALL PRIVILEGES ON TABLE sales TO new.engineer@company.com;
- B. GRANT USAGE ON TABLE sales TO new.engineer@company.com;
- C. GRANT ALL PRIVILEGES ON TABLE new.engineer@company.com TO
sales;
- D. GRANT SELECT ON TABLE sales TO new.engineer@company.com;
- E. GRANT SELECT CREATE MODIFY ON TABLE sales TO new.engineer@company.com;
解答
- チャート:GRANT構文に合っているか。全ての権限を与えるのは”ALL”。
- 解答:B. USAGEはアクション実行のみ, C. は読み取り権限のみ。D., E. は構文が違う。
- A.
特別付録:うんこVACUUMドリル
模擬試験問題にはありませんが、結構問われますよ
💩💩💩💩💩💩💩💩💩💩💩💩💩💩💩💩💩💩💩💩💩💩💩💩💩💩💩💩💩💩💩💩💩💩💩💩💩💩💩
💩💩💩💩💩 うんこVACCUMドリル 💩💩💩💩💩
💩💩💩💩💩💩💩💩💩💩💩💩💩💩💩💩💩💩💩💩💩💩💩💩💩💩💩💩💩💩💩💩💩💩💩💩💩💩💩
- VACUUM は、Delta によって管理されていないテーブルディレクトリのすべてのファイルと、テーブルのトランザクションログが最新状態ではなく、かつリテンション期間のしきい値より古くなっているデータファイルを削除する
- しきい値のデフォルトは7日間
💩💩💩💩💩 7日間より古いうんこはバキュームカーで吸い取ろう 💩💩💩💩💩