本記事のめあて
-
データサイエンティスト スキルチェックリストver.5 の各項目について自分の理解を整理するためですが、皆さんにも役立つと思い公開します
- 項目があるだけだと「あーできるわかる」となりがちですが実務は違いますよね
- 必須項目を順次実施していきます
- ChatGPTも使いましたが誤りがありやはり人間が書かないとというところ。誤りがあればコメントなどでお願いします
- ご参照
チェックリストに対応した書籍リストを作成しましたよ
数学的基礎
線形代数基礎
★ ベクトルの内積に関する計算方法を理解し、線形式をベクトルの内積で表現できる
ベクトルは縦に要素を並べるのが基本
内積の定義
\mathbf{a}, \mathbf{b}二つのベクトルがあった場合に
\mathbf{a}=
\begin{bmatrix}
a_1 \\
a_2 \\
\vdots \\
a_n \\
\end{bmatrix}
\mathbf{b}=
\begin{bmatrix}
b_1 \\
b_2 \\
\vdots \\
b_n \\
\end{bmatrix}
\begin{align}
\mathbf{a}^{\top}\mathbf{b}&=
\begin{bmatrix}
a_1 & a_2 & \cdots & a_n
\end{bmatrix}
\begin{bmatrix}
b_1 \\
b_2 \\
\vdots \\
b_n \\
\end{bmatrix}\\
&=a_1b_1+a_2b_2+\cdots+a_nb_n
\end{align}
\begin{align}
&\mathbf{a}^{\top}は\mathbf{a}の転置\\
&本によっては\\
&^t\!\mathbf{a}, \mathbf{a}^T, \mathbf{a}^{tr}, \mathbf{a}'
\end{align}
例
\begin{align}
\begin{bmatrix}
1 & 2
\end{bmatrix}
\begin{bmatrix}
3 \\
4
\end{bmatrix}&=1\cdot 3+2\cdot 4\\
&=11
\end{align}
また、線形式はベクトルで次のように表せる。
\begin{align}
y&=a_1 x_1+b_1 + a_2 x_2 + \cdots + a_n x_n \\
&=
\begin{bmatrix}
a_1 & a_2 & \cdots \ a_n
\end{bmatrix}
\begin{bmatrix}
x_1 \\
x_2 \\
\vdots \\
x_n
\end{bmatrix}\\
&=\mathbf{a^{\top}x}
\end{align}
★ 行列同士、および行列とベクトルの計算方法を正しく理解し、複数の線形式を行列の積で表現できる
- 行列同士の掛け算
行列の積の定義
$m\times n$行列$\mathbf{A_mn}$と$n\times l$行列$\mathbf{B_{nl}}$の積は
\begin{align}
\mathbf{A}&=
\begin{bmatrix}
a_{11} & a_{12} & \cdots & a_{1n} \\
a_{21} & \ddots & & \vdots \\
\vdots & & \ddots & \vdots \\
a_{m1} & \cdots & \cdots & a_{mn}
\end{bmatrix}\\
\mathbf{B}&=
\begin{bmatrix}
b_{11} & b_{12} & \cdots & b_{1l} \\
b_{21} & \ddots & & \vdots \\
\vdots & & \ddots & \vdots \\
b_{n1} & \cdots & \cdots & b_{nl}
\end{bmatrix}\\
\mathbf{AB}&=
\begin{bmatrix}
\sum_{k=1}^n{a_{1k}b_{k1}} & \sum_{k=1}^n{a_{1k}b_{k2}} & \cdots & \sum_{k=1}^n{a_{1k}b_{kl}} \\
\sum_{k=1}^n{a_{2k}b_{k1}} & \ddots & & \vdots \\
\vdots & & \ddots & \vdots \\
\sum_{k=1}^n{a_{mk}b_{k1}} & \cdots & & \sum_{k=1}^n{a_{mk}b_{kl}}
\end{bmatrix}
\end{align}
要素のみで表すと
\begin{align}
\mathbf{AB_ij}&=\sum_{k=1}^n{a_{ik}b_{kj}}\\
i&=1, 2, \cdots, m \\
j&=1, 2, \cdots, l
\end{align}
例:
2x3行列 $\mathbf{A}$と3x2行列$\mathbf{B}$があるとき
\begin{align}
\mathbf{AB}&=\begin{bmatrix}
a_{11} & a_{12} & a_{13} \\
a_{21} & a_{22} & a_{23} \\
\end{bmatrix}
\begin{bmatrix}
b_{11} & b_{12} \\
b_{21} & b_{22} \\
b_{31} & b_{32}
\end{bmatrix}\\
&=\begin{bmatrix}
a_{11}b_{11}+a_{12}b_{21}+a_{13}b_{31} & a_{11}b_{12}+a_{12}b_{22}+a_{13}b_{32} \\
a_{21}b_{11}+a_{22}b_{21}+a_{23}b_{31} & a_{21}b_{12}+a_{22}b_{22}+a_{23}b_{32} \\
\end{bmatrix}
\end{align}
- 行列とベクトル
\begin{align}
\mathbf{A}&=
\begin{bmatrix}
a_{11} & a_{12} & \cdots & a_{1n} \\
a_{21} & \ddots & & \vdots \\
\vdots & & \ddots & \vdots \\
a_{m1} & \cdots & \cdots & a_{mn}
\end{bmatrix}\\
\mathbf{v}&=\begin{bmatrix}
v_1 \\
v_2 \\
\vdots \\
v_n
\end{bmatrix}\\
\mathbf{Av}&=
\begin{bmatrix}
\sum_{j=1}^n{a_{1j}v_j} \\
\sum_{j=1}^n{a_{2j}v_j} \\
\vdots\\
\sum_{j=1}^n{a_{mj}v_j} \\
\end{bmatrix}\\
\end{align}
要素のみで表すと
\begin{align}
\mathbf{Av_ij}&=\sum_{j=1}^n{a_{ij}v_{j}}\\
i&=1, 2, \cdots, m \\
\end{align}
また逆側の場合は
\begin{align}
\mathbf{v}^{\top}\mathbf{A}&=
\begin{bmatrix}
\sum_{i=1}^m{v_i a_{i1}} & \sum_{i=1}^m{v_i a_{i2}} & \cdots & \sum_{i=1}^m{v_i a_{in}} \\
\end{bmatrix}\\
\end{align}
要素のみで表すと
\begin{align}
\mathbf{v}^{\top}\mathbf{A}_{ij}&=\sum_{i=1}^m{v_i a_{ij}}\\
j&=1, 2, \cdots, n \\
\end{align}
微分・積分基礎
★ 微分により計算する導関数が傾きを求めるための式であることを理解している
直線の傾きを求めるには
直線の傾き=\frac{yの増分}{xの増分}
曲線の場合には例えば下図の場合、
\begin{align}
y&=x^2のx=1での傾きは\\
\frac{2^2-1}{2-1}&=3\\
\frac{1.5^2-1}{1.5-1}&=2.5\\
\frac{1.1^2-1}{1.1-1}&=2.1\\
\end{align}
x=1からの増分を小さくすればするほどx=1での傾きに近づくが増分を0にはできない、そこで
f'(x)=\lim_{\Delta x\to 0}{\frac{f(x+\Delta x)-f(x)}{\Delta x}}

★ 積分と面積の関係を理解し、確率密度関数を定積分することで確率が得られることを説明できる
- 積分と面積の関係

関数$f(x)$がある。この$\lbrace x|a\le x\le b\rbrace$の範囲で下部面積を求めることを考える。
$x$軸方向に$n$個に分割する。とすると赤い部分の面積は、
\begin{align}
&\sum_{i=1}^n{f(x_i)\Delta x}\\
&\Delta x=\frac{b-a}{n}
\end{align}
関数$f(x)$の下部面積に近似する。図のとおりこれでは赤い部分面積の方が大きいので短冊をもっと細かく、つまり$n$を無限に大きくすると関数$f(x)$の下部面積となる。
\begin{align}
\lim_{n \to \infty}{\sum_{i=1}^n{f(x_i})\Delta x}&=\int_a^b{f(x)dx}\\
ただし&\Delta x=\frac{b-a}{n}
\end{align}
- 確率密度関数を定積分することで確率
確率密度関数は連続型確率変数が特定の値を取る「密度」を示す。ただし、特定の一点での確率は0である。連続型確率分布の場合は通常ある値の範囲を取る面積として確率を定義する。
確率密度関数を$f(x)$とすると、全区間で積分すると1となる。つまり全事象の確率の和は1。
\int_{-\infty}^{\infty}{f(x)dx}=1
ある範囲、$\lbrace x|a \le x\le b\rbrace$における確率$P(a \le x\le b)$は
P(a \le x\le b)=\int_a^b{f(x)dx}
となる。
集合論基礎
★ 和集合、積集合、差集合、対称差集合、補集合についてベン図を用いて説明できる
- 和集合
集合$\mathbf{A}, \mathbf{B}$がある時にそのいずれかに含まれる要素$\mathrm{x}$のすべての集合
\mathbf{A}\cup\mathbf{B}=\{x|x\in\mathbf{A}\ \lor\ x\in\mathbf{B}\}

- 積集合
集合$\mathbf{A}, \mathbf{B}$がある時にそのどちらにも含まれる要素$\mathrm{x}$のすべての集合
\mathbf{A}\cap\mathbf{B}=\{x|x\in\mathbf{A}\ \land\ x\in\mathbf{B}\}

- 差集合
集合$\mathbf{A}, \mathbf{B}$がある時に集合$\mathbf{A}$に含まれ集合$\mathbf{B}$には含まれない要素$\mathrm{x}$の集合
\mathbf{A}\setminus\mathbf{B}=\{x|x\in\mathbf{A}\ \land \ x\not\in\mathbf{B}\}

- 対称差集合
集合$\mathbf{A}, \mathbf{B}$がある時に集合$\mathbf{A}$に含まれ集合$\mathbf{B}$には含まれない要素$\mathrm{x}$と集合$\mathbf{B}$に含まれ集合$\mathbf{A}$に含まれない要素$\mathrm{x}$の和集合
\mathbf{A}\bigtriangleup\mathbf{B}=\{x|(x\in\mathbf{A}\ \land \ x\not\in\mathbf{B})\lor(x\in\mathbf{B}\ \land x\not\in\mathbf{A})\}
また、
\begin{align}
\mathbf{A}\bigtriangleup\mathbf{B}&=(\mathbf{A}\cup \mathbf{B}) \setminus (\mathbf{A}\cap\mathbf{B}) \\
&=(\mathbf{A}\setminus\mathbf{B})\cup(\mathbf{B}\setminus\mathbf{A})
\end{align}

- $\land$は論理積 つまり and
- $\lor$は論理話 つまり or
- 差集合は$\mathbf{A}-\mathbf{B}$と書く場合もある
- 対称差集合は$\mathbf{A}\ominus\mathbf{B}$と書く場合もある
科学的解析の基礎
統計数理基礎
★ 順列や組合せの式 nPr, nCr を理解し、適切に使い分けることができる
- 順列
順列の定義
{}_nP_r=\frac{n!}{(n-r)!}
例:ABCDから2つを取り出して順列を作ると
AB, BA
AC, CA
AD, DA
BC, CB
BD, DB
CD, DC
の12通り
\begin{align}
{}_4P_2&=\frac{4!}{(4-2)!} \\
&=\frac{4\times3\times2\times1}{2\times1}\\
&=12
\end{align}
- 組み合わせ
組み合わせの定義
{}_nC_r=\frac{n!}{r!(n-r)!}
例:ABCDから2つを取り出して組み合わせを作ると
AB (組み合わせは順番を問わないのでBAも同じ、以下同様)
AC
AD
BC
BD
CD
の6通り
\begin{align}
{}_4C_2&=\frac{4!}{2!(4-2)!} \\
&=\frac{4\times3\times2\times1}{2\times1\times2\times1}\\
&=6
\end{align}
{}_nC_rは\binom{n}{r}とも書く
- 順列と組み合わせの違い
- 順列は順番に意味がある、組み合わせは順番に意味がない
- 順列:文字列操作でn個の文字からm個の文字を取り出して並べるならば順番に意味がある
- 組み合わせ:n個のお菓子からm個もらうパターンの種類ならば順番は関係ない
- 順列は順番に意味がある、組み合わせは順番に意味がない
★ 確率に関する基本的な概念の意味を説明できる(確率、条件付き確率、期待値、独立など)
- 確率

全事象を$\Omega$、対象とする事象を$A$とするとき$A$の起こる確率とは
P(A)=\frac{|A|}{|\Omega|}
事象:「できごと」くらいでまずはよい
全事象:起こりうるすべての事象。標本空間ともいう。
|A|:事象の大きさ、つまり起きた件数
- 条件付き確率

条件付き確率の定義
事象A, Bがあり、Aが起きた下でのBが起きる確率は
\begin{align}
P(B|A)&=\frac{P(A\cap B)}{P(A)}\\
ただし&P(A)>0
\end{align}
- 期待値
期待値の定義
起こりうる事象$x$とその事象$x$の値を掛けた平均値
\begin{align}
\mathbf{E}[X]&=\sum_{i=1}^N{x_iP(X=x_i)}\\
離散的な確率変数であれば\\
\mathbf{E}[X]&=\int_{\Omega}{xP(x)dx}\\
\end{align}
例:サイコロの例
出目の確率はすべて$\frac{1}{6}$なので
\begin{align}
\mathbf{E}[x]&=1\times\frac{1}{6}+2\times\frac{1}{6}+3\times\frac{1}{6}+4\times\frac{1}{6}+5\times\frac{1}{6}+6\times\frac{1}{6}\\
&=3.5
\end{align}
- 独立
独立の定義
事象A, Bがあり、AとBが独立であるとは
P(A\cap B)=P(A)P(B)
が成り立つこと。
上記から
\begin{align}
AとB&が独立 \\
\iff&P(A\cap B)=P(A)P(B)\\
\iff&\frac{P(A\cap B)}{P(A)}=P(B)\\
\iff&P(B|A)=P(B)
\end{align}
事象Aが起きた下で事象Bが起きる確率は事象Bの起きる確率に等しい
つまり、事象Aが起きることと事象Bが起きることは独立しているということ
(事象Bが起きた下で事象Aが起きる確率は事象Aの起きる確率に等しい。も同様)
$\iff$ は同値であるということ
★ 平均、中央値、最頻値の算出方法の違いを説明できる
平均、中央値、最頻値の定義
データ数が$N$、データが$x_1, x_2, \cdots, x_N$であった場合に
- 平均
mean=\frac{1}{N}\sum_{i=1}^N{x_i}
- 中央値
\begin{align}
x_i&を昇順か降順に並べ替えx'_iとし、\\
1)\ &Nが奇数の時\\
&x'の\frac{N+1}{2}番目つまりx’_{\frac{N+1}{2}}が中央値\\
2)\ &Nが偶数の時\\
&x'の\frac{N}{2}番目と\frac{N}{2}+1番目なのでその平均を取り、\frac{1}{2}(x'_{\frac{N}{2}}+x'_{\frac{N}{2}+1})が中央値
\end{align}
- 最頻値
$x_i$の値の出現回数を数えた時、最大の個数となるものが最頻値。
同値が複数ある場合はそれら全てが最頻値。
例:3, 5, 6, 9, 3, 4, 3, 2, 3, 8の値があった時
平均:$\frac{3+5+6+9+3+4+3+2+3+8}{10}=4.6$
中央値:昇順にすると2, 3, 3, 3, 3, 4, 5, 6, 8, 9であり3と4の平均なので、3.5
最頻値:3が4回あり一番多いので、3
世の中の例でよく例示されるのが所得の度数分布。
最頻値は示されていないが、グラフから読み取ると、200-300万円が最頻値。
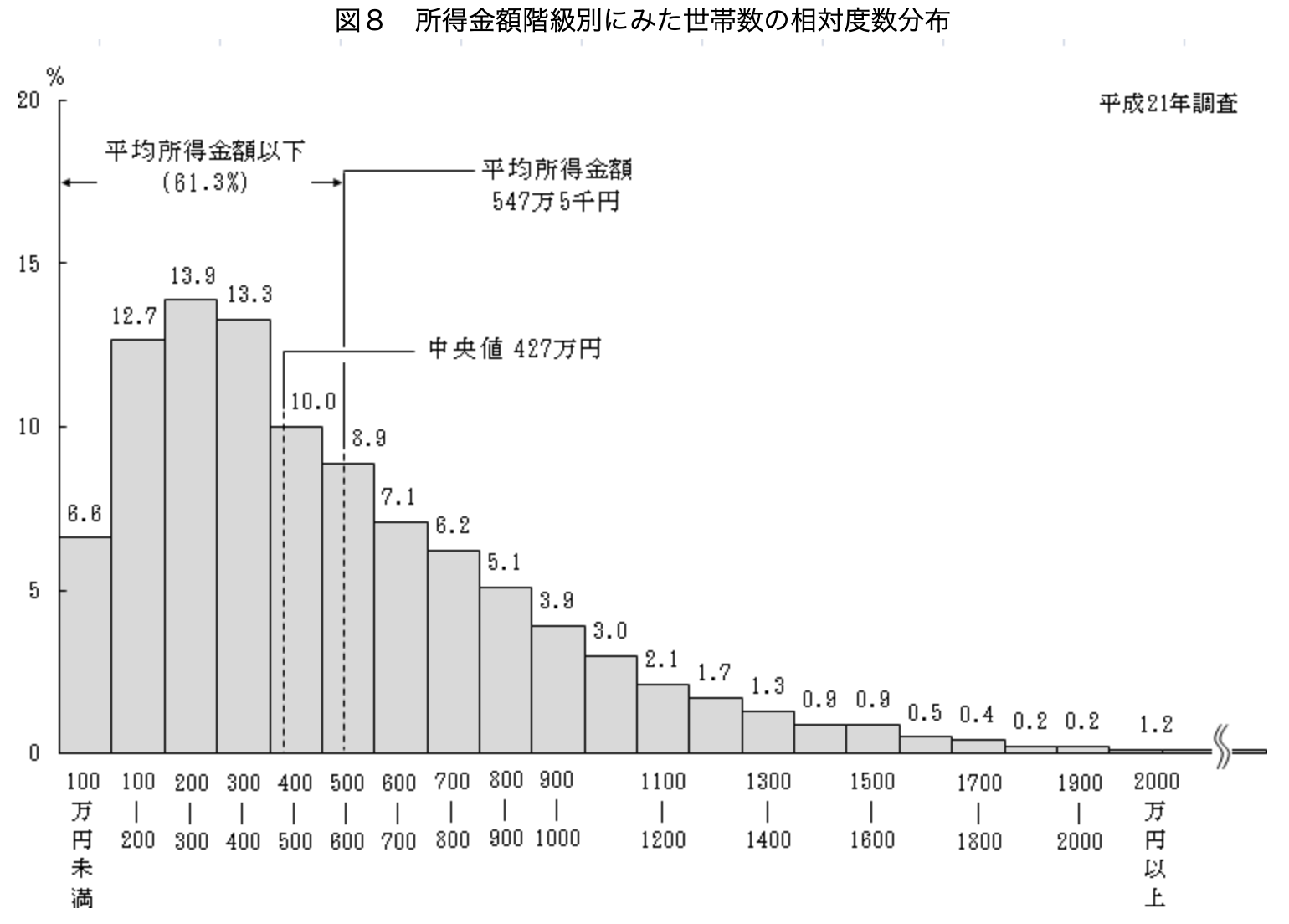
出所:厚生労働省. "平成21年国民生活基礎調査の概況 > 2 所得の分布状況". 厚生労働省. https://www.mhlw.go.jp/toukei/saikin/hw/k-tyosa/k-tyosa09/2-2.html, (参照 2024-11-03).
★ 与えられたデータにおける分散、標準偏差、四分位、パーセンタイルを理解し、目的に応じて適切に使い分けることができる
- 分散、標準偏差
データのばらつきを表す指標
分散、標準偏差の定義
データ数が$N$、データが$x_1, x_2, \cdots, x_n$であり、平均を$\mu$とすると分散$\sigma^2$と標準偏差$\sigma$は
\begin{align}
\sigma^2&=\frac{1}{N}\sum_{i=1}^N{(x_i-\mu)^2}\\
\sigma&=\sqrt{\frac{1}{N}\sum_{i=1}^N{(x_i-\mu)^2}}\\
\end{align}
母集団の場合は上記の通り。標本の場合は$N$が$n-1$となる(後述)
- 四分位
四分位の定義
データを昇順に並べたときに、
- 第一四分位数(Q1)
- 下位25%の値、下半分の中央値
- 第二四分位数(Q2)
- 上位、下位50%の値、つまり中央値
- 第三四分位数(Q3)
- 上位25%の値、上半分の中央値
- 値が偶数になるときは中央値と同様に2つの値の平均
- 四分位範囲(IQR)
- IQR=Q3-Q1
- 一般的にQ1 - 1.5×IQR未満またはQ3 + 1.5×IQRを超える場合に異常値とみなす
- 箱ひげ図で示される
- パーセンタイル
パーセンタイルの定義
データを昇順に並べた場合に、全体の何パーセントがその値以下に位置するかを示す。例えば、90パーセンタイルの値は、データの90%がその値以下であり、残りの10%がそれより大きいことを意味する。
データ数$N$、パーセンタイルの順位$P$、求めるパーセンタイルの値を$k$とすると、昇順に並べたデータに対し、下記で求めた$P$番目がそのパーセタイル$k$の値となる。
P=\frac{N+1}{100}k
★ 母(集団)平均と標本平均、不偏分散と標本分散がそれぞれ異なることを説明できる
- 母平均と標本平均
| 項目 | 母平均(Population Mean) | 標本平均(Sample Mean) |
|---|---|---|
| 対象 | 母集団全体のデータ | 母集団から抽出された標本のデータ |
| 計算式 | $\mu=\frac{1}{N}\sum_{i=1}^N{x_i}$ | $\bar{x}=\frac{1}{n}\sum_{i=1}^n{x_i}$ |
| 正確性 | 真の平均値で正確 | 母平均の推定値であり、標本に依存 |
| 変動性 | 母集団が固定されていれば一定 | 標本の選び方によって変動 |
| 用途 | 母集団の特性を直接示す | 母集団の特性を推定するために使用 |
- 不偏分散と標本分散
不偏分散
標本データから母集団の分散を推定する際に用いられる分散の推定量。
標本サイズを$n$、標本データを$x_1, x_2, \cdots, x_n$、標本平均を$\bar{x}$とすると、不偏分散$s^2$は
s^2=\frac{1}{n-1}\sum_{i=1}^n{(x_i-\bar{x})^2}
また、不偏分散の期待値は母集団の分散の期待値に一致するため、不偏性があるという。
\mathbf{E}[s^2]=\sigma^2
- 標本分散
標本分散は、標本データのばらつきを測定するための指標。
同様に、標本サイズを$n$、標本データを$x_1, x_2, \cdots, x_n$、標本平均を$\bar{x}$とすると、標本分散$s^2$は
s^2=\frac{1}{n}\sum_{i=1}^n{(x_i-\bar{x})^2}
標本分散は不偏分散に比べてバイアスがあり不偏推定量ではない。
\mathbf{E}[s_n^2]=\frac{n-1}{n}\sigma^2
- 不偏分散の分母がn-1となる理由
不偏分散$s^2$の期待値を考える
\begin{align}
まず、&\sum_{i=1}^n{(x_i-\bar{x})^2} の期待値を考える\\
\sum_{i=1}^n{(x_i-\bar{x})^2}&=\sum_{i=1}^n{x_i^2}-n\bar{x}^2\\
\mathbf{E}[\sum_{i=1}^n{(x_i-\bar{x})^2}]&=\mathbf[\sum_{i=1}^n{x_i^2}]-n\mathbf[\bar{x}^2]\\
ここで&標本平均\bar{x}の期待値と分散を考慮すると\\
Var(\bar{x})&=\mathbf{E}[\bar{x}^2]-[\mathbf{E}[\bar{x}]]^2\\
\mathbf{E}[\bar{x}]&=\mu\\
Var(\bar{x})&=\frac{\sigma^2}{n}\\
より\\
\mathbf{E}[\sum_{i=1}^n{(x_i-\bar{x})^2}]&=n(\sigma^2+\mu^2)-n(\frac{\sigma^2}{n}+\mu^2)\\
&=(n-1)\sigma^2\\
よって\\
\mathbf{E}[s^2]&=\mathbf{E}[\frac{1}{n-1}\sum_{i=1}^n{(x_i-\bar{x})^2}]\\
&=\frac{1}{n-1}(n-1)\sigma^2\\
&=\sigma^2\\
\therefore&不偏分散s^2の期待値が母集団分散\sigma^2に等しい
\end{align}
★ 標準正規分布の平均と分散の値を知っている
\phi(x)=\frac{1}{\sqrt{2\pi}}e^{-\frac{x^2}{2}}
- 期待値(平均)
\begin{align}
\int_{-\infty}^{\infty}{x\phi(x)dx}&=\frac{1}{\sqrt{2\pi}}\int_{-\infty}^{\infty}{xe^{-\frac{x^2}{2}}dx}\\
ここで&xe^{-\frac{x^2}{2}}は奇関数(f(-x)=-f(x))であり、\\
奇関数&を対象な区間で積分すると0になるから\\
右辺&=0\\
よって&期待値は0
\end{align}
- 分散
\begin{align}
Var(X)&=\mathbf{E}[X^2]-\mathbf{E}[X]^2 を持ちると\\
&=\mathbf{E}[X^2] なので\\
\mathbf{E}[X^2]&=\int_{-\infty}^{\infty}{x^2\phi(x)dx}\\
&=\frac{1}{\sqrt{2\pi}}\int_{-\infty}^{\infty}{x^2e^{-\frac{x^2}{2}}dx}\\
ここで&ガウス積分の公式\\
\int_{-\infty}^{\infty}{x^{2k}e^{-ax^2}dx}&=\frac{(2k-1)!!}{(2a)^k}\sqrt{\frac{\pi}{a}}を持ちいると\\
\frac{1}{\sqrt{2\pi}}\int_{-\infty}^{\infty}{x^2e^{-\frac{x^2}{2}}dx}&=\frac{1}{\sqrt{2\pi}}\frac{1!!}{(2\times\frac{1}{2})^1}\sqrt{\frac{\pi}{\frac{1}{2}}}\\
&=1\\
よって&分散は1
\end{align}
★ 相関関係と因果関係の違いを説明できる
相関関係の定義
二つの変数がある場合に、一方の変数が増加(または減少)する際に、もう一方の変数も一定の方向に増加(または減少)する傾向がある場合に相関が存在すると言う。
因果関係の定義
二つの変数がある場合に、一方の変数(原因)が他方の変数(結果)に影響を与える場合に因果関係があると言う。
相関関係があっても因果関係がない場合が発生する理由として
- 偶然
- ある企業の株価と世界中の金融指標を調べれば相関を持つものが出てくるが、それは偶然であり、因果関係があるわけではない
- 交絡
- 原因にも結果にも両方に影響を与える変数を交絡変数と言う。またそのような状態を交絡していると言う。
- アイククリームの売り上げと溺死者数は相関があるが、それは因果関係ではなく、気温が厚いからアイスクリームが売れ、海で泳ぐ人が増えるから溺死者数も増えるという、気温という交絡変数による交絡が発生している。
- 逆の因果関係
- これは因果関係は発生しているが逆の因果関係であること。相関関係を見るだけでは見分けがつかない。
★ 名義尺度、順序尺度、間隔尺度、比例尺度の違いを説明できる
定義、特徴、例
- 名義尺度
- データをカテゴリーやグループに分類するための尺度で、カテゴリー間に順序や数量的な関係が存在しない。
- 順序や距離の概念がないため、データ間の大小関係はない。
- 例
- 性別(男性、女性)
- 出身地(東京、大阪、名古屋など)
- データをカテゴリーやグループに分類するための尺度で、カテゴリー間に順序や数量的な関係が存在しない。
- 順序尺度
- データに順序や順位を付けることができる尺度で、カテゴリー間の順序はわかるが、その間隔は一定ではない。
- 順序が重要であり、データ間の大小関係を評価できる。
- 隣接するカテゴリー間の距離や差異は不明確。
- 例
- 顧客満足度(非常に不満、不満、普通、満足、非常に満足)
- 順位(1位、2位、3位)
- データに順序や順位を付けることができる尺度で、カテゴリー間の順序はわかるが、その間隔は一定ではない。
- 間隔尺度
- 順序尺度の特徴に加え、隣接する値の間隔が等しい尺度。ただし、絶対的なゼロ点が存在しないため、比率の計算はできない。
- 等間隔性があり、データ間の差を測定できる。
- ゼロ点が任意であり、比率(例えば、2倍)は意味を持たない。
- 例
- 気温(摂氏、華氏)
- 時間(時計の時間)
- 順序尺度の特徴に加え、隣接する値の間隔が等しい尺度。ただし、絶対的なゼロ点が存在しないため、比率の計算はできない。
- 比例尺度
- 間隔尺度の特性に加え、絶対的なゼロ点が存在する尺度。比率の計算が可能で、データ間の比較が容易。
- ゼロ点が絶対的であり、存在しない状態を示す。
- 加減乗除の全ての演算が可能。
- 比率(例えば、2倍、3分の1)が意味を持つ。
- 例
- 身長や体重
- 距離
- 時間の経過(絶対的なゼロ点から)
- 間隔尺度の特性に加え、絶対的なゼロ点が存在する尺度。比率の計算が可能で、データ間の比較が容易。
★ ピアソンの相関係数の分母と分子を説明できる
定義
2つの変数$X, Y$があるとき、
\begin{align}
r&=\frac{Cov(X, Y)}{\sigma_X \sigma_Y}\\
&=\frac{\sum_{i=1}^n(X_i-\bar{X})(Y_i-\bar{Y})}{\sqrt{\sum_{i=1}^n{(X_i-\bar{X})^2}}\sqrt{\sum_{i=1}^n{(Y_i-\bar{Y})^2}}}
\end{align}
分子の共分散は相関の傾向を示している。Xの偏差が正に大きくYの偏差も同様であれば相関が正に強い方向に。Yの偏差が負に大きければ相関が負に強い方向に。互いに偏差が小さいか、Xの偏差が正に大きく、Yの偏差が負に大きいような場合は相関が小さい方向に。
分母はその傾向を正規化するように働き、最終的に相関係数が-1から1におさまっている。
★ 5つ以上の代表的な確率分布を説明できる
- 離散型
- 二項分布
- 特徴
- 固定された試行回数$n$、成功確率$p$、各試行が独立
- 用途
- 成功回数の予測、品質管理、マーケティング調査
- 例
- コインを10回投げて表が出る回数
- 特徴
- ポアソン分布
- 特徴
- 単位時間や単位面積あたりの事象発生率$\lambda$、事象が独立
- 用途
- 電話の着信数、交通事故の発生数、ウェブサイトへのアクセス数のモデリング
- 例
- 1時間あたりの電話の着信回数
- 特徴
- 幾何分布
- 特徴
- 初めての成功までの試行回数、成功確率$p$、各試行が独立
- 用途
- 初回成功までの試行回数の予測、品質管理、故障までの使用回数の分析
- 例
- 最初の企画CDの売上成功までの販売回数
- 特徴
- 負の二項分布
- 特徴
- $r$回目の成功までの失敗回数、成功確率$p$、各試行が独立
- 用途
- 成功回数が複数回達成されるまでの試行回数の予測、販売キャンペーンの成果分析
- 例
- 販売員が3回目の成約を得るまでに必要な営業訪問回数
- 特徴
- 超幾何分布
- 特徴
- 集団からのサンプル抽出時の成功数
- サンプル抽出後に戻さないため試行間に依存関係がある
- 用途
- 品質管理における不良品の抽出
- 例
- 全体が20個の部品のうち5個が不良品である中から無作為に4個を取り出し、ちょうど1個が不良品である確率
- 特徴
- 二項分布
| 確率分布 | 確率質量関数 | 主なパラメータ | 期待値 | 分散 |
|---|---|---|---|---|
| 二項分布 | $\begin{align} Bin(X = k) &= \binom{n}{k} p^k (1-p)^{n-k}\\ k&=0, 1, 2, \cdots, n \end{align}$ | 試行回数$n$、成功確率$p$ | $np$ | $np(1-p)$ |
| ポアソン分布 | $\begin{align} Po(X = k) &= \frac{\lambda^k e^{-\lambda}}{k!} \\ k&=0, 1, 2, \cdots\end{align}$ | $\lambda$ | $\lambda$ | $\lambda$ |
| 幾何分布 | $\begin{align} Ge(X = k) &= (1-p)^{k-1} p \\ k&=1, 2, 3, \cdots\end{align}$ | 成功確率$p$ | $\frac{1}{p}$ | $\frac{1-p}{p^2}$ |
| 負の二項分布 | $\begin{align} P(X = k) &= \binom{k+r-1}{k} p^r (1-p)^k \\ k&=0, 1, 2, \cdots \end{align}$ | 成功回数$r$、成功確率$p$ | $\frac{r(1-p)}{p}$ | $\frac{r(1-p)}{p^2}$ |
| 超幾何分布 | $\begin{align} &P(X = k) = \frac{\binom{K}{k} \binom{N-K}{n-k}}{\binom{N}{n}}\\ &k = \max(0, n-(N-K)),\\ &\qquad\dots, \min(K, n) \end{align}$ | 集団サイズ$N$、成功の総数$K$、サンプルサイズ$n$ | $n \frac{K}{N}$ | $n \frac{K}{N} \left(1 - \frac{K}{N}\right) \frac{N-n}{N-1}$ |
- 連続型
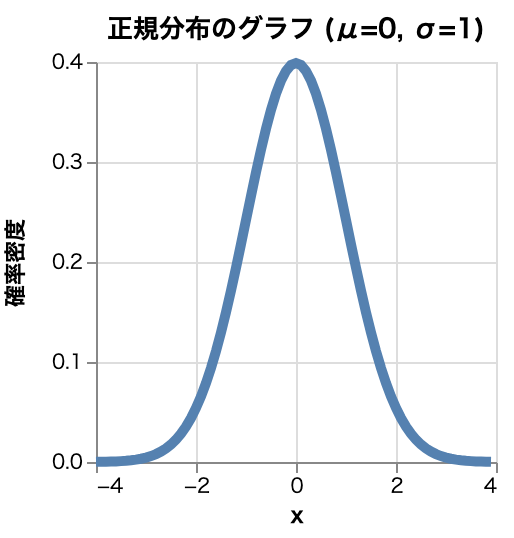
- 正規分布
-
- 特徴
- 鐘形の対称な連続分布。中央極限定理に基づく自然現象のモデル化
- 別名:ベルカーブ、ガウス分布
- 用途
- 自然現象のモデリング、統計的推測、測定誤差ほか
- 例
- 人間の身長、テストの得点分布
-
- 一様分布
-
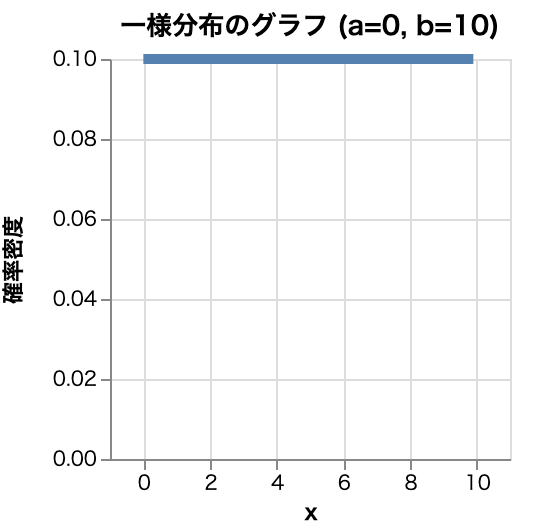
- 特徴
- すべての値が等確率で発生する連続分布
- 用途
- シミュレーション、ランダムサンプリング
- 例
- 0から1までの乱数生成、均等な分布の物理現象
-
- 指数分布
-
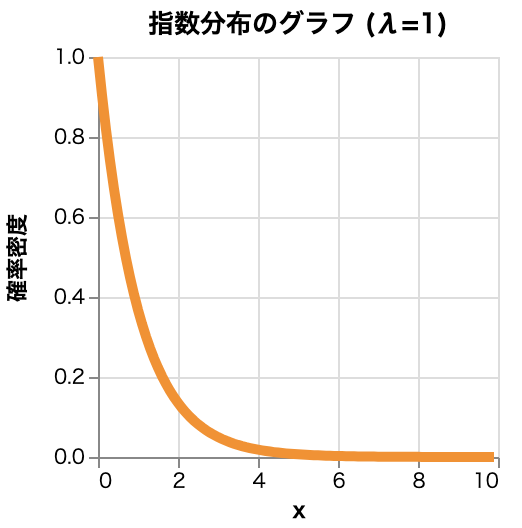
-
特徴
- 非負の連続分布で記憶喪失性を持つ
-
用途
- 待ち時間のモデリング、信頼性工学。
-
例
- 電話の着信間隔、機械の故障までの時間
-
- ガンマ分布
-
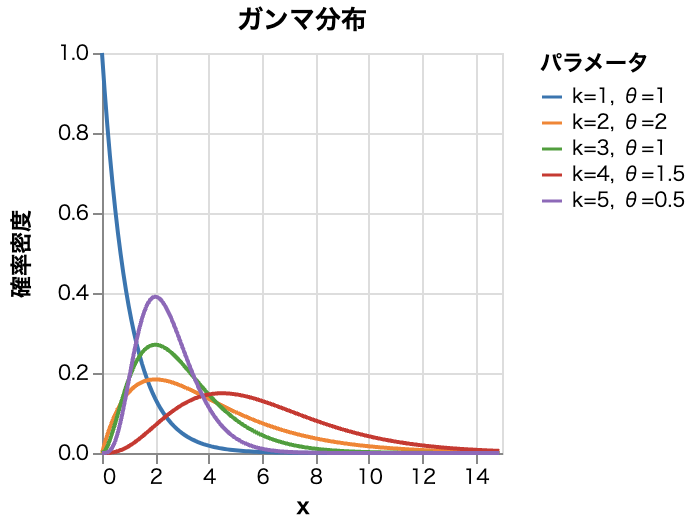
- 特徴
- 形状パラメータと尺度パラメータを持つ非負の連続分布で多様な形状
- 用途
- 待ち時間のモデリング、保険数理、信頼性工学、ベイズ統計
- 例
- 放射性崩壊の待ち時間、保険請求金額のモデル化、機械の故障までの時間
-
- ベータ分布
-
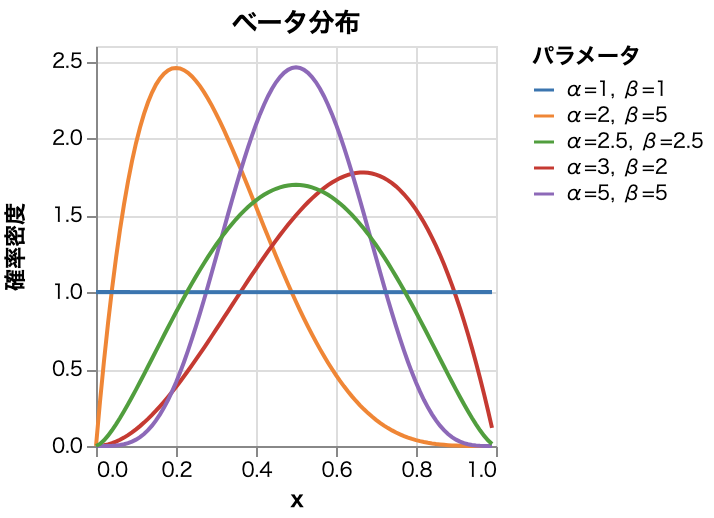
- 特徴
- 形状パラメータを持ち、区間[0, 1]の範囲で多様な形状を持つ
- 用途
- ベイズ統計における事前分布、割合や確率のモデリング、品質管理
- 例
- 成功確率の事前分布、投票率のモデル化、ウェブサイトのクリック率分析
-
- 正規分布
| 確率分布 | 確率密度関数 | 主なパラメータ | 期待値 | 分散 |
|---|---|---|---|---|
| 正規分布 | $\begin{align} f(x)&=\frac{1}{\sqrt{2\pi}\sigma}e^{-\frac{(x-\mu)^2}{2\sigma^2}} \\ &-\infty \lt x\lt \infty \end{align}$ | 平均$\mu$、分散$\sigma^2 $ | $\mu$ | $\sigma^2$ |
| 一様分布 | $f(x)=\begin{cases} \frac{1}{b-1} & a\le x\le b \\ \ \ 0 & x\lt a, x\gt b \end{cases}$ | 最小値 a、最大値 b | $\frac{a+b}{2}$ | $\frac{(b-a)^2}{12}$ |
| 指数分布 | $f(x)=\begin{cases} \lambda e^{-\lambda x} & x\ge 0 \\ \ \ 0 & x\lt 0 \end{cases}$ | λ | $\frac{1}{\lambda}$ | $\frac{1}{\lambda^2}$ |
| ガンマ分布 | $f(x)=\begin{cases} \frac{1}{\beta^{\alpha}\Gamma(\alpha)}x^{\alpha-1}e^{-\frac{x}{\beta}} & x\ge 0 \\ \ \ 0 & x\lt 0 \end{cases}$ | $\alpha, \beta$ $k, \theta$とする場合もある ($\alpha=k,$ $\beta=\frac{1}{\theta}$) |
$\alpha\beta$ | $\alpha\beta^2$ |
| ベータ分布 | $\begin{align} f(x)&=\frac{x^{\alpha-1}(1-x)^{}}{B(\alpha, \beta)} \\ &0\le x\le 1 \end{align}$ | $\alpha, \beta$ | $\frac{\alpha}{\alpha+\beta}$ | $\frac{\alpha\beta}{(\alpha+\beta)^2(\alpha+\beta+1}$ |
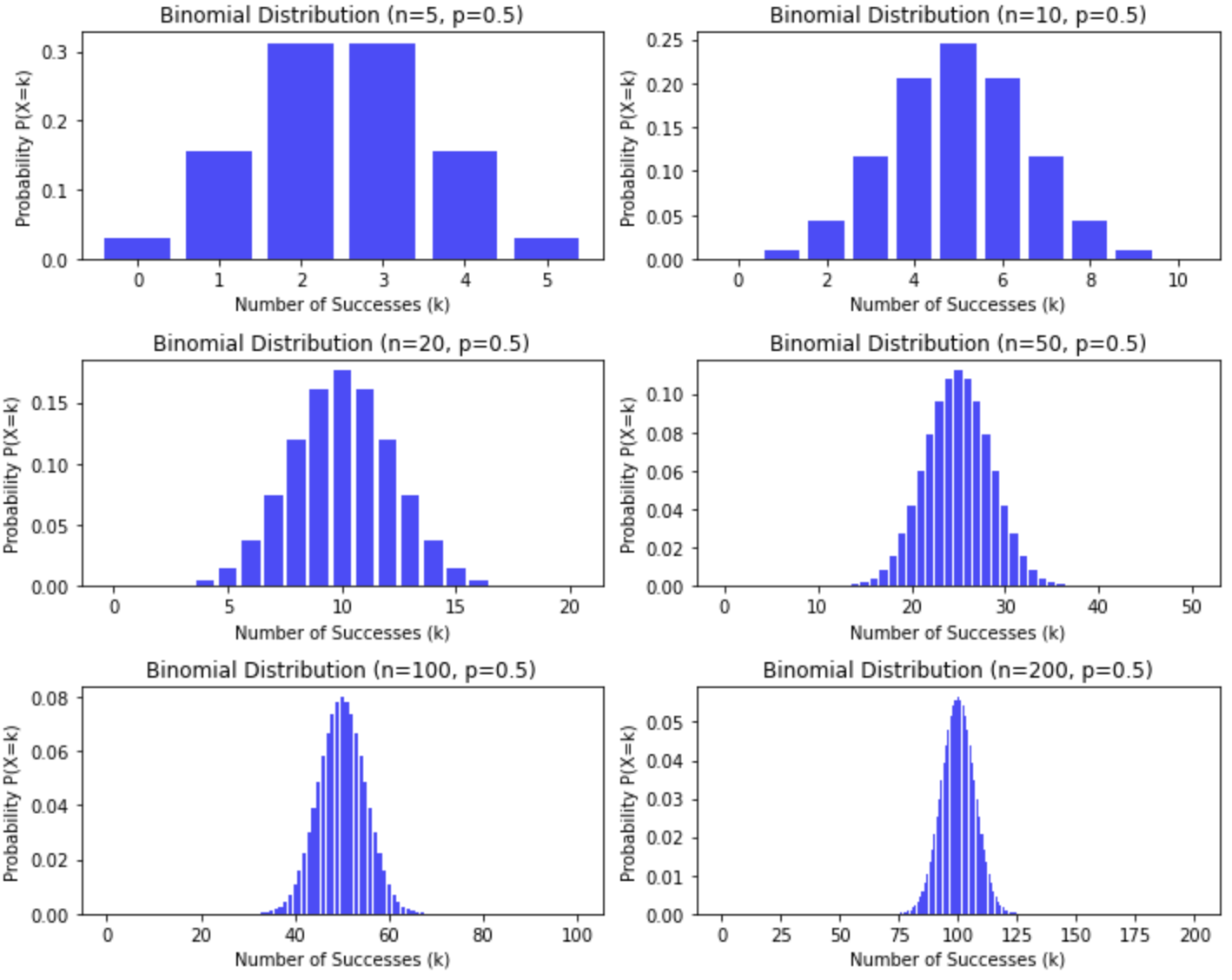
★ 二項分布は試行回数が増えていくとどのような分布に近似されるかを知っている
- p=0.5, n=5, 10, 20, 50, 100, 200で二項分布を描いた。プロットの隙間の都合で縞模様が付いてしまうが、正規分布に近づいているのがわかる。
★ 指数関数とlog関数の関係を理解し、片対数グラフ、両対数グラフ、対数化されていないグラフを適切に使いわけることができる
指数関数とlog関数(対数関数)の定義
y=a^x \iff \log_a{y}=x
- 片対数グラフ
- 片方の変数が加算的に変化し、片方の変数が指数的に変化する場合
- 両対数グラフ
- 両方の変数が指数的に変化する場合
- 対数化されていないグラフ
- 両方の変数が加算的に変化する場合
★ ベイズの定理を説明できる
ベイズの定理
P(A|B)=\frac{P(B|A)P(A)}{P(B)}
ここで、
$P(A|B)$:事後確率:事象Bが起きた上での事象Aが起こる確率
$P(B|A)$:尤度:事象Aが真であるとき事象Bが起こる確率
$P(A)$:事前確率:事象Aが起こる確率
$P(B)$:周辺確率:事象Bが起こる全体の確率
条件付き確率より、
\begin{align}
P(A\cap B)=P(A|B)P(B)&=P(B|A)P(A) \\
\therefore P(A|B)&=\frac{P(B|A)P(A)}{P(B)}
\end{align}
よく出される例
- スパムメールのフィルタリング
- 問題設定: メールがスパムである確率 $P(A)=0.2$
- メールがスパムであるとき、特定のキーワード「無料」が含まれる確率 $P(B|A)=0.9$
- スパムでないとき、「無料」が含まれる確率$P(B|\bar{A})=0.1$
- 質問: メールに「無料」というキーワードが含まれていた場合、そのメールがスパムである確率 $P(A|B)$は?
- 問題の意図:
- メールがスパムであるかどうかを調べることはできるが、これが大変なので自動化したい
- 特定のキーワード「無料」があれば高確率でスパムと分かれば、キーワードによるフィルタリングができる
- 解答:
- メールに「無料」が含まれる確率$P(B)$を求める
\begin{align} P(B)&=P(B|A)P(A)+P(B|\bar{A})P(\bar{A})\\ &=0.9\times 0.2+0.1\times 0.8\\ &=0.26 \end{align} - ベイズの定理より
\begin{align} P(A|B)&=\frac{P(B|A)P(A)}{P(B)}\\ &=\frac{0.9\times 0.2}{0.26}\\ &\approx 0.6923 \end{align}
- メールに「無料」が含まれる確率$P(B)$を求める
- 結論:メールに「無料」というキーワードが含まれていた場合、そのメールがスパムである確率は約69.23%。
- 問題設定: メールがスパムである確率 $P(A)=0.2$