はじめに
スタンフォード大学 Andrew Ng氏による機械学習の講義動画を各週社内メンバーで持ち回りで受講し、学んだことを発表、Qiitaで共有しています。
その最終回が今回の記事です。
社内輪講をやるにあたっての記事です。
【機械学習】社内輪講はじめました
第十回の講義が以下の記事
【機械学習】社内輪講 Week10 〜大量のデータセットの扱い〜
本講義の導入
最近では、スマートフォンなどで、手軽に写真を取れるようになり、みなさんのスマートフォンの中にも、大量の写真データがあると思います。
そんな写真データを手作業でラベリングしていくとなると、膨大な時間がかかり、現実的ではないですよね。
今回は、写真データを用いて、写真の中にあるテキストをどう認識させていくかについて学んでいきます。
写真OCR
下記のような写真を読み込んだ時に、赤枠で囲んだ部分の文字を認識させなければなりません。

人間の目では、パッと見でわかるのですが、(それも今までの経験で学習しているからですが、)
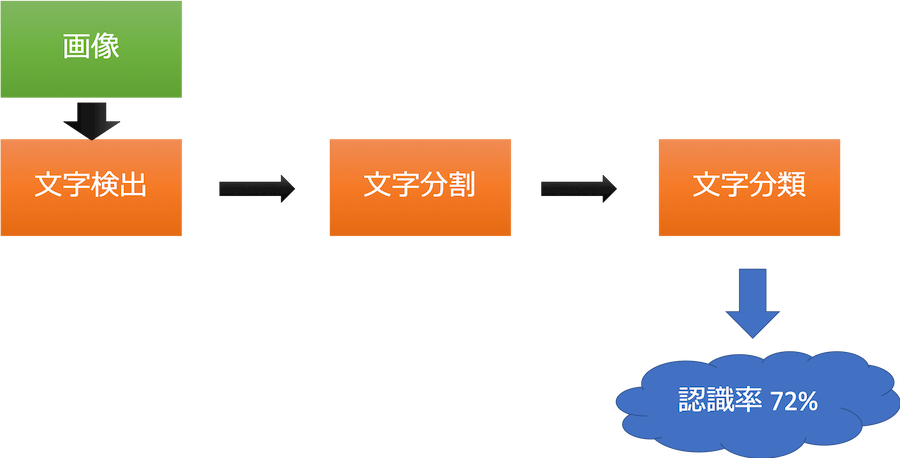
コンピュータで処理するためには、パイプラインと呼ばれる、工程をいくつかに分解して段階的に、文字認識を行っていきます(下図)。

1. 文字検出
文字検出するために、教師あり学習を用います。
文字を含んだ画像を$y=1$とし、文字を含んでいない画像を$y=0$として、学習させていきます。

2. 文字分割
文字分割も同じく、教師あり学習を用います。
今回は、文字と文字の間に境界があり、分割されている画像を$y=1$とし、文字単体であったり、何も写ってない画像を$y=0$として学習させます。

3. 文字分類
文字分類に関しては、今まで学習した、ロジスティック回帰やサポートベクターマシンなどを用いて分類します。
分類する時は、アルファベットは26文字のみなので、良いですが、日本語は、ひらがな・カタカナ・漢字、、、と膨大な組み合わせがあるので、それに伴い、学習データも大量に必要になってきます。
そこで、データを集める方法はというと、
- クラウドソーシングなどを活用
- 人工データを作成
などがあり、今回は、人工データ生成の方法をお伝えいたします。
人工データ生成
例えば、下記のような実際のデータがあった時に、データを増やしたい場合は、まずは文字+背景画像を組み合わせて生成します。

その際に、フォントや背景を変化させることでバリエーションが増えます。
そしてさらに、生成した画像に対して、アフィン変換(回転、引き伸ばし、歪み)をして、画像を実際のデータっぽくします。
どれだけ実際のデータに近づけることができるかで、認識精度にも影響を与えます。
実際に試してみましたが、これはちょっとアーティスティックな作業になります。
こうして組み合わせを変えることで、人工的に膨大な数のデータを生成することができます。
天井分析
機械学習は1回実装したら終わりという訳ではなく、精度を改善していく必要があります。
しかし、闇雲に改善していては、時間と人手がかかりすぎてしまいます。
そこで登場するのが、この天井分析。
先ほど紹介したパイプラインにおいて、どこを改善すると効果的に精度を高めることができるかを分析する手法です。
例えば、1度実装してみた結果、全体の精度が72%だとします。
もっと精度をよくしたい、でもどこから手をつけようかと考えますよね。
では、次に、文字検出を飛ばして、手作業にて100%文字検出されたデータを文字分割に入力として与えます。
そうすると、精度は88%に向上。16%上がったことになります。
次に、手作業にて文字分割まで行い、100%文字が分割された状態のデータを文字分類に入力として与えます。
そうすると、精度は89%まで向上。1%だけ上がったことになります。
最後は全て手作業ですると、もちろん精度は100%になります。
文字分割においては11%向上することが見込まれます。

以上の結果を踏まえ、1番改善すべきポイントは16%改善の余地がある文字検出のアルゴリズム、2番目は10%改善の余地がある文字分類ということがわかります。
以上で、Week11 写真OCRについて終了です。
社内でのAndrew Ng教授による機械学習の輪講もこれにて終了です。
ここまでお疲れ様でした!
次回の輪講も乞うご期待!