はじめに
タイトルの通り、日本語でword2vecを行ったので、そのやり方を備忘録として記録します。
細かい説明は省略させて頂きますが、AI用語辞典によると
Word2Vecは、テキスト処理を行うためのニューラルネットワークのこと。膨大なテキストデータを解析し、単語の意味をベクトル化することでその意味の類似性を計算したり、単語同士の意味を足し引きしたりできるようになる。
とのことで、どのようにベクトル化しているのか、という詳しい仕組みは@Hironsanさまが絵で理解するWord2vecの仕組みという記事で非常にわかりやすくまとめてくださっているのでリンクを貼らせて頂きます。
例えば、こちらにMathWorks社公式のword2vecの例題があります。この例では
①fastTextWordEmbeddingという学習済みのfastText(単語ベクトルのようなもの)をインポート
②Italy, Rome, Parisという単語をword2vecを使ってベクトル化
③ベクトル化した単語を足し算、引き算して、vec2wordを使って再度単語に変換
というステップを踏んでいます。
emb = fastTextWordEmbedding
italy = word2vec(emb,"Italy");
rome = word2vec(emb,"Rome");
paris = word2vec(emb,"Paris");
word = vec2word(emb,italy - rome + paris)
それで、この「italy - rome + paris」の結果が「France」になりますよ、と締めくくります。この面白さがword2vecの醍醐味ですよね。
ただ、この例題で使用している学習済みのfastText(fastTextWordEmbedding)は、残念ながら英語しか対応していません。日本語でも試したい!と思ってもできないのが現実です。そこで、日本語でもword2vecを行う方法を探したので次の章から記載していきます。
日本語でのword2vec
他にもあるかもしれませんが、私の知っているやり方は2つあります。
1つ目は、学習済みの単語ベクトルを拝借する方法。2つ目は、自分で単語ベクトルを作成させる方法です。
いずれも非常に簡単に実行できますが、学習済みの単語ベクトルを使用する方が精度的に良さそうなので、こちらの方法をメインにご紹介し、自分で単語ベクトルを作成する方法は最後におまけとして載せます。
まずは、学習済みの単語ベクトルを拝借する方法です。順にご参照ください。
1.vecファイルのダウンロード
まずは、Facebook社の提供しているfastTextのページから、日本語のベクトルファイルを取得してきます。具体的には、このページから探します。ページから直接行く場合は、下図のtextボタンからダウンロードします。

cc.ja.300.vec.gzというファイルのインストールが走ると思いますので、ダウンロードが完了したらgzファイルを解凍しましょう。
MATLABのスクリプト上で実行する場合は下記です。
filename = "cc.ja.300.vec";
if ~isfile(filename)
url = 'https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.ja.300.vec.gz';
dlfilename = "cc.ja.300.vec.gz";
websave(dlfilename,url);
gunzip(dlfilename);
end
2.vecファイルの読み込み
readWordEmbedding関数を使用します。
emb = readWordEmbedding(filename)
これで準備は完了です。
3-1.word2vecで遊んでみる
先ほどの例にあった「italy - rome + paris」を日本語で試してみましょう。
italy = word2vec(emb, 'イタリア');
rome = word2vec(emb, 'ローマ');
paris = word2vec(emb, 'パリ');
word = vec2word(emb, italy - rome + paris, 5)
上のスクリプトでは、wordの候補を5つ出しています。結果は下記。
word =
5×1 の string 配列
"パリ"
"フランス"
"ニース"
"ブリュッセル"
"ストラスブール"
残念ながら、1番目はパリになってしまいましたが、2番目にフランスが来ていることがわかります。
3-2.word2vecで遊んでみる②
次に、お好み焼きをベクトル化して、また単語に戻してみました。
okonomi = word2vec(emb, 'お好み焼き');
word = vec2word(emb, okonomi, 5)
すると結果は・・
word =
5×1 の string 配列
"お好み焼き"
"たこ焼き"
"もんじゃ焼き"
"オムソバ"
"タコ焼き"
楽しい!食べ物のレコメンドなんかに使えたりして。
3-3.word2vecで遊んでみる③
ここでは結果だけにしますが、同じサイトから韓国語のvecファイルをダウンロードしてみました。
korea = word2vec(emb, '韓国')
word = vec2word(emb, korea, 5)
結果はこちら。
word =
5×1 の string 配列
"韓国"
"カフェ"
"韩国"
"写真"
"で"
日本語や中国語が出てきてますが、確かに韓国語のvecファイルで実行しています。韓国ではほとんど漢字を使わないので、学習データが偏っているのかもしれません。
一方、日本語のvecファイルで同じスクリプトを動かすと
word =
5×1 の string 配列
"韓国"
"南朝鮮"
"大韓民国"
"朝鮮"
"韓"
ということで、言いたかったのは、fastTextの学習内容によって結果が変わって来ることがわかりました。
韓国語のvecファイルで実行した際は、2番目にカフェという単語が出てきましたが、文化だったり慣習だったり?目に見えない何かが反映されてそうです。
3-4.word2vecで遊んでみる④
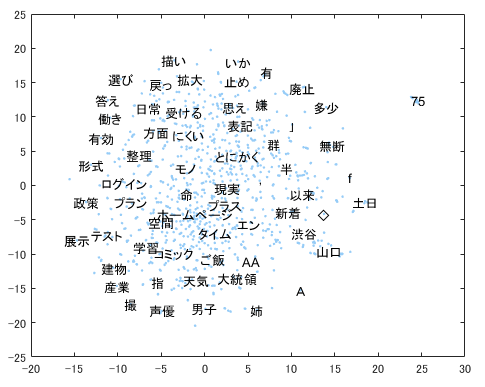
晴れて単語ベクトルの作成ができると、こんな可視化もできるように。t-SNEで300次元あるベクトルの次元を削減して、scatterプロットをしています。
words = emb.Vocabulary(2000:2999);
V = word2vec(emb,words);
XY = tsne(V);
textscatter(XY,words)
3-5.word2vecで遊んでみる⑤
単語同士の類似度をコサインで計算させたりもしました。
d1 = word2vec(emb,"お好み焼き");
d2 = word2vec(emb,"たこ焼き");
dot(d1,d2)/(rssq(d1)*rssq(d2))
ans =
single
0.7707
d1 = word2vec(emb,"楽譜");
d2 = word2vec(emb,"ダンプカー");
dot(d1,d2)/(rssq(d1)*rssq(d2))
ans =
single
0.1702
自分で単語ベクトルを作成させる方法
word2vecで色々と遊んでみましたが、冒頭にも書きました通り、自分でこのvecファイルを学習して作成させることも可能なようです。
単語の学習にはtrainWordEmbedding関数を、vecファイルの作成にはwriteWordEmbedding関数を使用します。一連の流れはこちらの例を見るとわかりやすいと思います。社内で特別な文書を持っている場合や、オリジナルのタームを多数持っている場合など?フレキシブルに使える点で良さそうですね。