はじめに
@eigsさまの記事【COTOHA API x MATLAB】形態素解析と文節可視化:やっぱり辞書は重要の中でmecab-ipadic-NEologdについて紹介されていましたが、私も非常に気になったので、この辞書を取り込む方法について調べてみました。その際、@zincjpさまのWindowsでNEologd辞書を比較的簡単に入れる方法ーユーザー辞書編を大いに参考にさせて頂きました。ありがとうございます。
こちらの記事では、極力GUI上で使えるようにまとめてみました。私の他にもmecab-ipadic-NEologdが気になっている方に、少しでもお役に立てたら幸いです。
mecab-ipadic-NEologd
mecab-ipadic-NEologd : Neologism dictionary for MeCab
Copyright (c) 2015-2019 Toshinori Sato (@overlast) All rights reserved.
詳しくは上のリンクからも確認できるのですが
●MeCab の標準のシステム辞書では正しく分割できない固有表現などの語の表層(表記)とフリガナの組を約318.5万組(重複エントリを含む)採録しています
●この辞書の更新は開発サーバ上で自動的におこなわれます
○少なくとも毎週 2 回更新される予定です
ということで、週に2回の更新てすごいですよね。既存のMecabの辞書だけでも便利な上に、最新の単語にも対応したmecab-ipadic-NEologdユーザー辞書を加えることで、日々言葉がアップデートされていくSNSのテキスト解析なんかに非常に便利だと思います。本当に有難いですね。データ解析において、前処理は大事ですからね。
環境
・Windows10 64bit 言語:日本語
・MATLAB R2020a
・Text Analytics Toolbox(この中にMeCabが入っている)
【下記のインストールが必要】
・MeCab→MeCabの公式ページはこちら
・git for Windows⇒上記@zincjpさまの記事をご参照ください
・7-Zip⇒上記@zincjpさまの記事をご参照ください
#なお、私は既に持っていたので、このステップは飛ばしています。
mecab-ipadic-NEologdユーザー辞書をMATLABに取り込むまでのステップ
1.mecab-ipadic-NEologdをダウンロード
まず、mecab-ipadic-NEologdのページにアクセスし、mecab-ipadic-NEologdをダウンロードしてきます。定期的に更新されるとのことなので、私はpullをしてきましたが、使い慣れてない方はひとまず下記Download ZIPから取ってきても良いと思います。ZIPで取ってきた方はダウンロード後に解凍しましょう。
こんな感じです。
2.ユーザー辞書(.dic形式)の作成
次に、.dic形式のユーザー辞書を作成します。本当はここのステップはもう少し改善したいのですが、かっこいいやり方がわからないのでひとまず現状で紹介します。
2-1.seedファイルの中身を7-Zipで解凍
seedフォルダの中に、.dicの原型といいますか、様々な単語やその詳細情報の格納されたcsvが格納されています。しかしながら、これらのcsvファイルは.xz形式に圧縮してあるので、7-Zipを使って解凍してやる必要があります。
「mecab-user-dict-seed.20200315.csv.xz」を右クリックし、[7-Zip]→[展開]の順にクリックします。解凍が完了したら「mecab-user-dict-seed.20200315.csv」ができあがっていることを確認してください。
なお、ファイル名の中の日付部分は、mecab-ipadic-NEologdをダウンロードしたタイミングによって異なります。
2-2.mecab-user-dict-seed.20200315.csvの中身をテキストエディタで確認&保存
本当はここをどうにか改善したいのですが。
mecab-user-dict-seed.20200315.csvをExcelで開くと、残念ながら文字化けしてしまっていました。そこで、その回避策として、mecab-user-dict-seed.20200315.csvをテキストエディタで開き、保存をし直しました。Excelで開いたときに文字化けしてない方は、ここのステップは飛ばしてしまっても良いかもしれません。
下図は、テキストエディタ(Notepad++)でmecab-user-dict-seed.20200315.csvを開いた時の様子です。顔文字や話題のハッシュタグ?なんかが格納されていることがわかります。(私も知らない単語が多数・・・)
2-3.辞書のコンパイル
ここまで準備ができれば、後はcsvファイルを.dic形式にコンパイルするだけです。MATLABでmecab-user-dict-seed.20200315.csvがあるディレクトリまで移動し、下記のコマンドを実行します。
system('mecab-dict-index -d "c:\Program Files (x86)\MeCab\dic\ipadic" -u NEologd.20200315.dic -f utf-8 -t utf-8 mecab-user-dict-seed.20200315.csv')
ただし、注意事項として
★MeCabのインストール先に応じて「c:\Program Files (x86)\MeCab\dic\ipadic」の部分は適宜変更してください
★重ねて、mecab-user-dict-seed.20200315.csvのファイル名はダウンロードのタイミングによって変わりますので適宜変更してください
★辞書名NEologd.20200315.dicは、拡張子より前の部分は好きな名前に変更可能です
コマンドを実行すると、こんな感じでプログレスバーが伸びていき・・
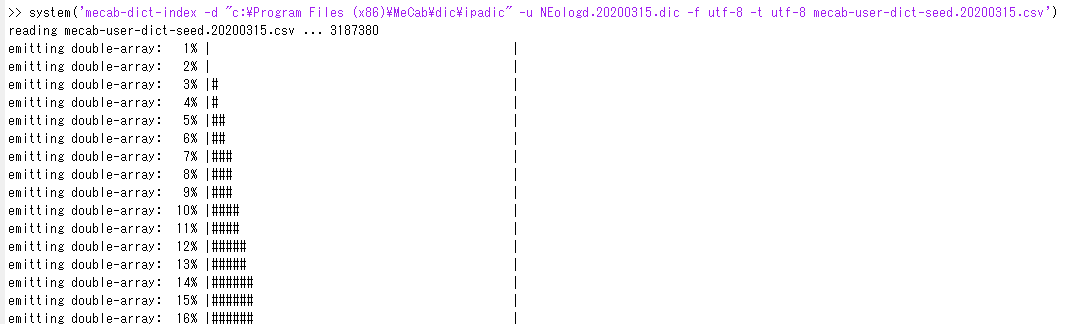
完了するとdone!と表示されます。

辞書NEologd.20200315.dicが作成されていることがわかります。
3.ユーザー辞書を使ってテキスト解析
@eigsさまの記事にユーザー辞書の使い方について記載されているのでこちらを参考にさせていただきました。下にもスクリプトを記載しています。
まずは、仮に文書を用意します。
str = ["2020年に国土交通省に入省(σ*´∀`)" "九産大で英検受けてきた。"];
次に、デフォルトの辞書を使用した場合と、ユーザー辞書を使用した場合で結果を比較してみましょう。
3-1.デフォルトの辞書を使用
documents = tokenizedDocument(str);
tokenDetails(documents)
| Token | DocumentNumber | LineNumber | Type | Language | PartOfSpeech | Lemma | Entity | |
|---|---|---|---|---|---|---|---|---|
| 1 | "2020" | 1 | 1 | digits | ja | numeral | "2020" | non-entity |
| 2 | "年" | 1 | 1 | letters | ja | noun | "年" | non-entity |
| 3 | "に" | 1 | 1 | letters | ja | adposition | "に" | non-entity |
| 4 | "国土" | 1 | 1 | letters | ja | noun | "国土" | non-entity |
| 5 | "交通省" | 1 | 1 | letters | ja | proper-noun | "交通省" | organization |
| 6 | "に" | 1 | 1 | letters | ja | adposition | "に" | non-entity |
| 7 | "入省" | 1 | 1 | letters | ja | noun | "入省" | non-entity |
| 8 | "(" | 1 | 1 | punctuation | ja | symbol | "(" | non-entity |
| 9 | "σ" | 1 | 1 | letters | ja | other | "σ" | non-entity |
| 10 | "*´∀`)" | 1 | 1 | punctuation | ja | symbol | "*´∀`)" | non-entity |
| 11 | "九" | 2 | 1 | letters | ja | numeral | "九" | non-entity |
| 12 | "産" | 2 | 1 | letters | ja | noun | "産" | location |
| 13 | "大" | 2 | 1 | letters | ja | noun | "大" | non-entity |
| 14 | "で" | 2 | 1 | letters | ja | adposition | "で" | non-entity |
| 15 | "英" | 2 | 1 | letters | ja | proper-noun | "英" | location |
| 16 | "検" | 2 | 1 | letters | ja | noun | "検" | non-entity |
| 17 | "受け" | 2 | 1 | letters | ja | verb | "受ける" | non-entity |
| 18 | "て" | 2 | 1 | letters | ja | adposition | "て" | non-entity |
| 19 | "き" | 2 | 1 | letters | ja | auxiliary-verb | "くる" | non-entity |
| 20 | "た" | 2 | 1 | letters | ja | auxiliary-verb | "た" | non-entity |
| 21 | "。" | 2 | 1 | punctuation | ja | punctuation | "。" | non-entity |
3-2.ユーザー辞書を使用
mOptions = mecabOptions('UserModel',"NEologd.20200315.dic");
documents = tokenizedDocument(str,"TokenizeMethod",mOptions);
tokenDetails(documents)
| Token | DocumentNumber | LineNumber | Type | Language | PartOfSpeech | Lemma | Entity | |
|---|---|---|---|---|---|---|---|---|
| 1 | "2020年" | 1 | 1 | other | ja | "2020年" | ||
| 2 | "に" | 1 | 1 | letters | ja | adposition | "に" | non-entity |
| 3 | "国土交通省" | 1 | 1 | letters | ja | "国土交通省" | ||
| 4 | "に" | 1 | 1 | letters | ja | adposition | "に" | non-entity |
| 5 | "入省" | 1 | 1 | letters | ja | noun | "入省" | non-entity |
| 6 | "(σ*´∀`)" | 1 | 1 | other | ja | "(σ*´∀`)" | ||
| 7 | "九産大" | 2 | 1 | letters | ja | "九産大" | ||
| 8 | "で" | 2 | 1 | letters | ja | adposition | "で" | non-entity |
| 9 | "英検" | 2 | 1 | letters | ja | "英検" | ||
| 10 | "受け" | 2 | 1 | letters | ja | verb | "受ける" | non-entity |
| 11 | "て" | 2 | 1 | letters | ja | adposition | "て" | non-entity |
| 12 | "き" | 2 | 1 | letters | ja | auxiliary-verb | "くる" | non-entity |
| 13 | "た" | 2 | 1 | letters | ja | auxiliary-verb | "た" | non-entity |
| 14 | "。" | 2 | 1 | punctuation | ja | punctuation | "。" | non-entity |
Pros
・「2020年」「国土交通省」「九産大」「英検」などの単語が1つのワードとして認識されている
・顔文字が認識されている
Cons
・ユーザー辞書で認識している部分(英検など)は品詞情報およびエンティティ情報が認識されない
・・・
ゆえに、残念ながら品詞情報でのソートはできないのですが、Bag-Of-Wordsを作ったり、ワードクラウドを作ったり・・といった用途の範囲では問題なさそうです。
おわりに
今回ユーザー辞書を使用することで、私たち人間が認識する単語の区切り方にぐっと近づくことができたと思っています。@eigsさまも書かれていた通り、やはり辞書は大事ですね。
しかしながら、mecab-ipadic-NEologdのwikiにもあります通り、やはり、解析の前には正規化が必要になってきます。
辞書データを生成する際には以下で述べる正規化処理を全て適用しているため、 解析対象のテキストに対して以下の正規化処理を適用すると、辞書中の語とマッチしやすくなる。
PythonやRubyだとすでに正規化用の関数が用意されているようですが、MATLABからもうまくできないかしらというのが次の課題です。何か良い方法をご存知の方がいらっしゃればコメント頂けると幸いです。