はじめに
愛用のMATLABでアドベントカレンダーがあったので初投稿です。作成ありがとうございました!
今日は、私の愛してやまないアーティスト、B'zの、CDのタイトルと売上数をディープラーニングで学習させて、次のCDのタイトルにはどんなのが良いかなと調べてみました。お遊びなので肩肘張らずにお付き合いください。
環境
MATLAB R2019b
Text Analytics Toolbox
Deep Learning Toolbox
(たぶん)
やったこと
まずは学習データを用意しましょう
2018年7月のデータのようですが、こちらのサイトにB'zのCD売上枚数の表があったので、ここからデータを取ってきます。下記の感じで、とりあえずCDXTrain、CDYTrainという名前のcell配列に入れています。売上数の単位は万枚です。
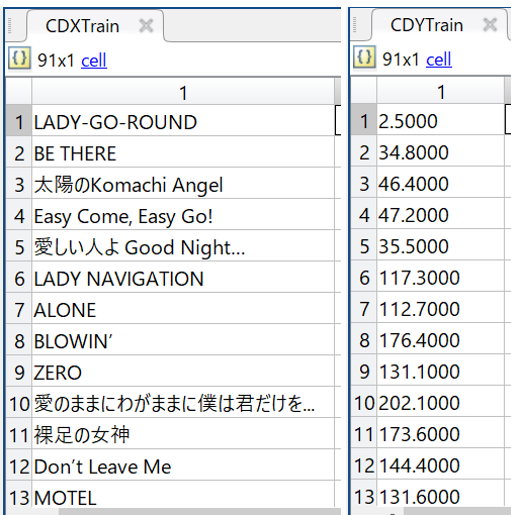
次に、CDXTrainについては、ドキュメントをシーケンスに変換するdoc2sequenceを使って、ディープラーニングに使える形にしておきます。
ここでしれっとCDYTrainも数値型に変換しています。
documents = tokenizedDocument(CDXTrain);
enc = wordEncoding(documents);
XTrain = doc2sequence(enc,documents,'Length',7);
YTrain = cell2num(CDYTrain);
シーケンスの長さを7にしていますが、これは、事前にドキュメントというかタイトルの長さをヒストグラムで確認して決めました。
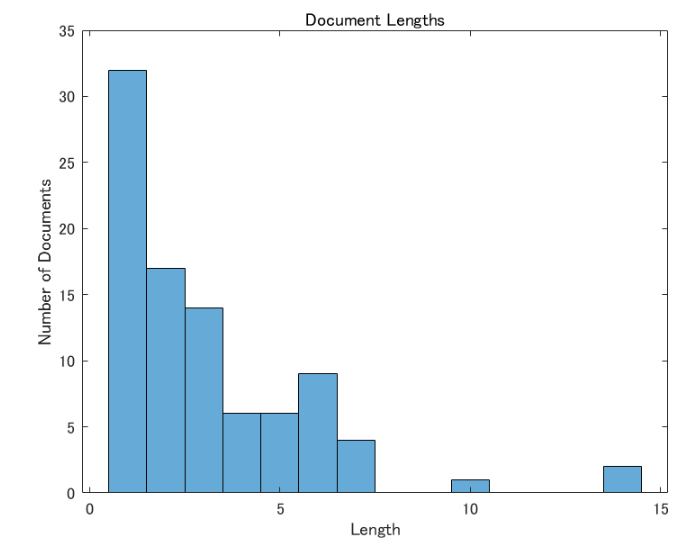
documentLengths = doclength(documents);
figure
histogram(documentLengths)
title("Document Lengths")
xlabel("Length")
ylabel("Number of Documents")
ネットワークの設定
こちらはほぼコピペで。一応、入力のサイズや、回帰レイヤーを採用すること、そして、lstmLayerのOutputModeを'last'にする点だけ気を付けています。
%% Layer settings
numResponses = 1;
featureDimension = size(XTrain{1},1);
numHiddenUnits = 200;
layers = [ ...
sequenceInputLayer(featureDimension)
lstmLayer(numHiddenUnits,'OutputMode','last')
fullyConnectedLayer(50)
dropoutLayer(0.5)
fullyConnectedLayer(numResponses)
regressionLayer];
%% Option settings
maxEpochs = 100;
miniBatchSize = 32;
options = trainingOptions('adam', ...
'MaxEpochs',maxEpochs, ...
'MiniBatchSize',miniBatchSize, ...
'InitialLearnRate',0.01, ...
'GradientThreshold',1, ...
'Shuffle','never', ...
'Plots','training-progress',...
'Verbose',0);
学習
net = trainNetwork(XTrain,YTrain,layers,options);
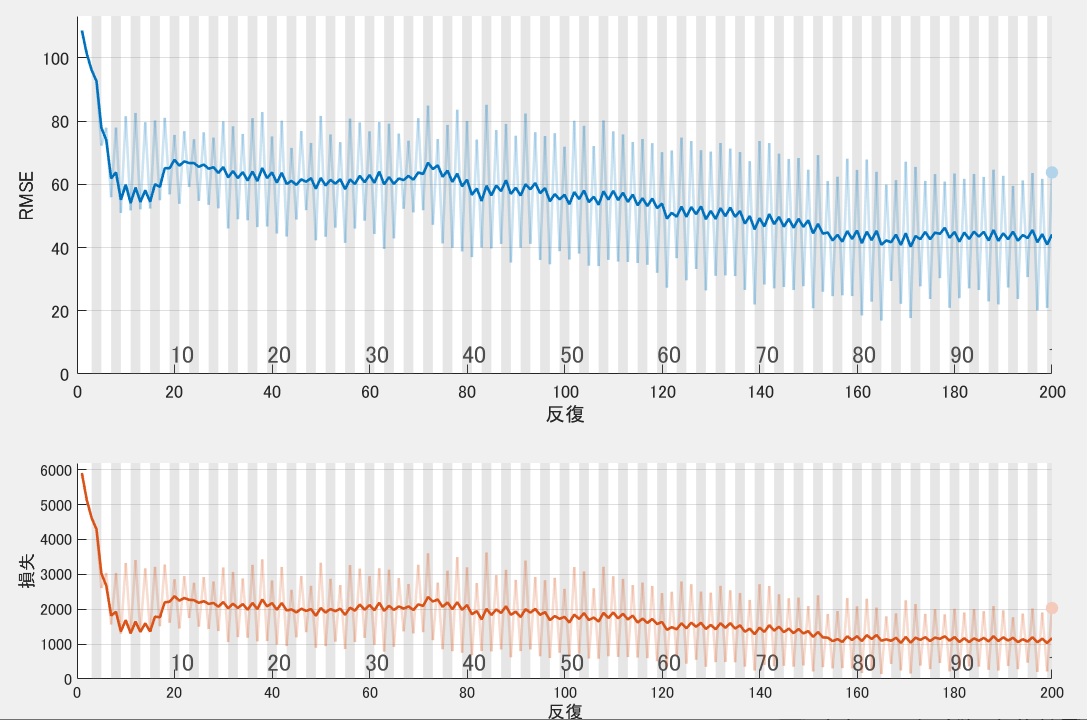
精度はそんなによくなさそうですが結果やいかに・・
新しいタイトルを入れてCD売上数を予測
以下のコードで実施しました。
result = predict(net,preprocesstitle(enc,TitleCandidates))
function output = preprocesstitle(enc, titleword)
documents = tokenizedDocument(titleword);
output = doc2sequence(enc,documents,'Length',7);
end
すると・・

解説しましょう。
・愛のままにわがままなUltra Komachi
めちゃくちゃなタイトルですが、こちらは、202万枚を売り上げた「愛のままにわがままに僕は君だけを傷つけない」と、46万枚を売り上げた「太陽のKomachi Angel」、そして、「ultra soul」や「B’z The Best "ULTRA Pleasure"」「B’z The Best "ULTRA Treasure"」で使われているultraという単語をつなぎ合わせてみました。このタイトルをつけると173万枚売れるとの予測です。うふふ。
・さよならなんかは言わせない
こちらはB'zの6作目のアルバム「RUN」の8曲目に収められている曲で、リンク先のWikipedia情報によると“ベストアルバム『B'z The Best "Treasure"』のファン投票ではトップ20入り、『B'z The Best "ULTRA Treasure"』の投票では8位にランクインして収録された。”そうです。私も大好きな曲の1つなのですが、これをCDのタイトルにすると144万枚売れるとの予測です。シングル化決定ですね!(願望)
ちなみに、学習データにこの曲名が入っていなかったのに、売上予測枚数が高く算出されたのはなかなか面白い結果でした。
・だれにも言えねえ井戸
こちらは、B'zのライブで何度か出てきている、ライブに行った者のみぞ知るちょっとコアなワードです。元ネタは各自Google検索にてご確認くださいませ。この名前でCDを出しても、ミリオンセラーの予測です。実は既に「だれにも言えねえ」という曲は出ているのですが、こちらも、学習データにこの曲名が入っていなかったのに、売上予測枚数が高く算出されたので面白い結果でした。
・新一と蘭の大冒険
B'zの曲は、名探偵コナンのテーマソングによく採用されるので、適当にタイトルを作ってみました。これでも50万枚の売上予測・・・なんか怖くなってきました。
・おしりたんてい
最後に全く関係ないワードを入れてたところ、マイナスになってしまいました。稲葉さんがおしりとか歌ってるイメージないですもんね。
まとめ
元の学習データに入っていないワードでも、B'zに関連する言葉を入れて予測をすると、CD売上予測枚数が結構高くなったので、面白いやら怖いやら、不思議な感じでした。しかしながら全部が全部そうではないですし、学習データ数も少ないので、あくまで参考までに見てください。
おわりに
これからも沢山CD出してください!