KaggleのStoreSalesに挑戦
時系列予測が必要なため、時系列予測などに強いモデルを使用する。
ARIMAが季節性を取り入れることも可能であり比較的簡単に医用できるので採用。
しかし、より高度な時系列予測も必要そうなデータセットを使用していたので、VAR(VectorAutoRegression)を使用します。
したがって、ARIMAとVARのアンサンブル学習を行います。
環境
- GoogleColaboratory
- Python
データ処理
データを見てみる
import pandas as pd
import matplotlib.pyplot as plt
train_df = pd.read_csv('train.csv')
oil_df = pd.read_csv('oil.csv')
tran_df = pd.read_csv('transactions.csv')
train_df.head(10)
| id | date | store_nbr | family | sales | onpromotion |
|---|---|---|---|---|---|
| 0 | 2013-01-01 | 1.0 | AUTOMOTIVE | 0.0 | 0.0 |
| 1 | 2013-01-01 | 1.0 | BABY CARE | 0.0 | 0.0 |
| 2 | 2013-01-01 | 1.0 | BEAUTY | 0.0 | 0.0 |
| 3 | 2013-01-01 | 1.0 | BEVERAGES | 0.0 | 0.0 |
| 4 | 2013-01-01 | 1.0 | BOOKS | 0.0 | 0.0 |
| 5 | 2013-01-01 | 1.0 | BREAD/BAKERY | 0.0 | 0.0 |
| 6 | 2013-01-01 | 1.0 | CELEBRATION | 0.0 | 0.0 |
| 7 | 2013-01-01 | 1.0 | CLEANING | 0.0 | 0.0 |
| 8 | 2013-01-01 | 1.0 | DAIRY | 0.0 | 0.0 |
| 9 | 2013-01-01 | 1.0 | DELI | 0.0 | 0.0 |
非常に嫌なデータ。前処理が多い、さらにfamilyカラムに存在する値の種類を調べると
import pandas as pd
df = pd.read_csv('train.csv')
destination_count = df['family'].nunique()
print(destination_count)
33
多すぎ。ダミーデータ化するのが面倒そう。でもsalesを予測するには必須だろうな...日付データもめんどくさい。YYYY-MM-DDで入ってることは確定なのでtarin.csvをdateとfamilyをカテコライズして新しく作り直します。 その際に、holidaiys_events.csv`から祝日情報も抜き出し加えます。
新しい学習データファイルを作成
-dateカラムには一つのNanと2013-01PLIANCESという行があるので2013-01-16に置き換え他のカラムは0に置き換えています。
dateカラムの中に30という値を含むデータがあるので探し出す。
import pandas as pd
df = pd.read_csv('train.csv')
print(df[df["date"] == "30"])
-
train.csv,test.csvとholidays_events.csvのdateカラムが一致すればholiday_flagに1を代入しなければ0を代入するようにします -
train.csv,test.csvとoil.csvのdateカラムが一致すればdcoilwticoに価格を代入します -
train.csv,test.csvの欠損値に平均値を代入します -
train.csv,test.csvのdateカラムをYear,Month,Dayカラムに分割しcsvファイルとして書き出す -
idとsalesカラム以外に正規化を行う
※読み込みファイルをtrain.csvとtest.csvに変更すれば、trainもtestも前処理可能
1
# holiday_flagを追加
import pandas as pd
train_df = pd.read_csv('train.csv')
holidays_df = pd.read_csv('holidays_events.csv')
# 'date'カラムを日付型に変換
train_df['date'] = pd.to_datetime(train_df['date'])
holidays_df['date'] = pd.to_datetime(holidays_df['date'])
# 'holiday_flag'列を追加し、初期値を0に設定
train_df['holiday_flag'] = 0
# 'date'カラムの値がholidays_events.csvファイルと一致する場合、'holiday_flag'に1を代入
for holiday_date in holidays_df['date']:
train_df.loc[train_df['date'] == holiday_date, 'holiday_flag'] = 1
train_df.to_csv('train-2.csv', index=False)
2
# `date`が一致すれば原油価格を代入
import pandas as pd
test_df = pd.read_csv('train-2.csv')
oil_df = pd.read_csv('oil.csv')
# 'date'カラムを日付型に変換
test_df['date'] = pd.to_datetime(test_df['date'])
oil_df['date'] = pd.to_datetime(oil_df['date'])
# 'dcoilwtico'カラムを追加し、初期値をNaNに設定
test_df['dcoilwtico'] = float('nan')
# test-3.csvの'date'カラムの値がoil.csvの'date'カラムの値と一致する場合、対応する行の'dcoilwtico'カラムの値を代入
for index, row in test_df.iterrows():
test_date = row['date']
corresponding_row = oil_df[oil_df['date'] == test_date]
if not corresponding_row.empty:
test_df.at[index, 'dcoilwtico'] = corresponding_row.iloc[0]['dcoilwtico']
test_df.to_csv('train-3.csv', index=False)
3
# train-4.csvの中の中でNanになっているものには平均値を代入
import pandas as pd
train_df = pd.read_csv('train-3.csv')
train_df.fillna(train_df.mean(), inplace=True)
train_df.to_csv('train-4.csv', index=False)
4
testについて行う場合はここだけダミー変数化を行わないカラムからsalesを削除
# 日付を分割
import pandas as pd
df = pd.read_csv('train-4.csv')
# 日付データを分割して新しいカラムを作成する
df['Year'] = pd.to_datetime(df['date']).dt.year
df['Month'] = pd.to_datetime(df['date']).dt.month
df['Day'] = pd.to_datetime(df['date']).dt.day
df.drop(columns=['date'], inplace=True)
# ダミー変数化する前に除外するカラムを指定
excluded_columns = ['id', 'store_nbr', 'sales', 'onpromotion', 'Year', 'Month', 'Day', 'holiday_flag', 'dcoilwtico']
# 指定したカラムを除外してダミー変数化を行う
df_encoded = pd.get_dummies(df.drop(excluded_columns, axis=1))
# 元のデータフレームにダミー変数化されたデータを再度代入する
df = pd.concat([df[excluded_columns], df_encoded], axis=1)
df.to_csv('df_train.csv', index=False)
5
df_train.csvの場合はidとsalesの二つを除外する。(目的関数と学習には必要のない値なので)
import pandas as pd
from sklearn.preprocessing import MinMaxScaler
df = pd.read_csv('df_train.csv')
exclude_columns = ['id', 'sales']
excluded_data = df[exclude_columns]
features = df.drop(columns=exclude_columns)
scaler = MinMaxScaler()
scaled_data = scaler.fit_transform(features)
scaled_df = pd.DataFrame(scaled_data, columns=features.columns)
result_df = pd.concat([excluded_data, scaled_df], axis=1)
result_df.to_csv('df_scaled_test.csv', index=False)
相関関係数を出力
データの処理が終わったので、df_train.csvの中のsalesカラムとその他のカラムの相関関係を出力します。
import pandas as pd
df = pd.read_csv('df_scaled_train.csv')
corr = df.corr()['sales']
corr.to_csv('df_scaled_corr.csv')
結果(絶対値を取って降順に変更しています。)

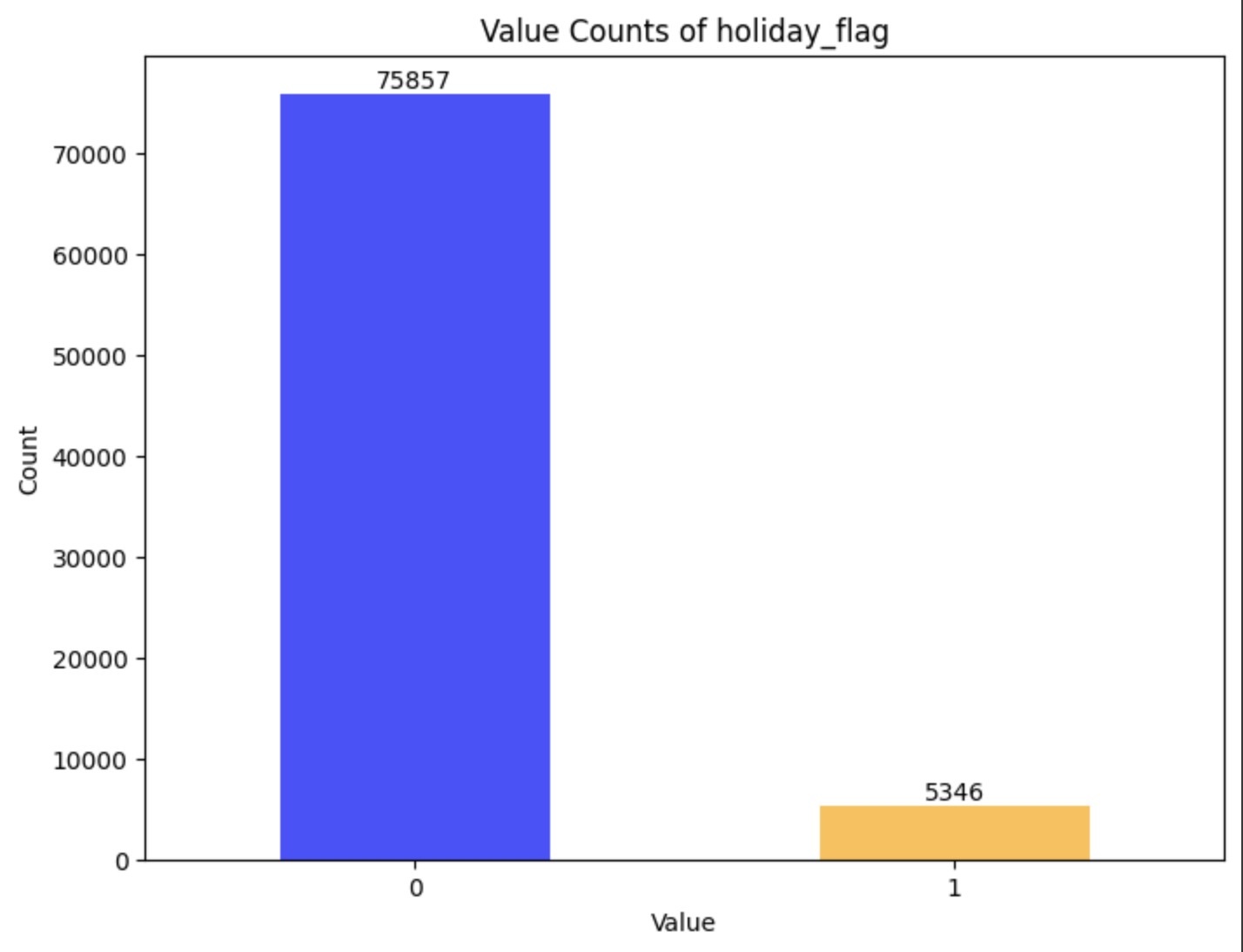
df_scaled_train.csvとdf_scaled_test.csvのholiday_flagの割合
上記の通り、割合がどの程度化を棒グラフで出力します。
同様に読み込むファイル名を変えれば良いだけです。
import pandas as pd
import matplotlib.pyplot as plt
df = pd.read_csv('df_scaled_train.csv')
target_columns = ['holiday_flag']
for column in target_columns:
target_df = df[[column]]
value_counts = target_df[column].value_counts(dropna=False)
plt.figure(figsize=(8, 6))
value_counts.plot(kind='bar', color=['blue', 'orange', 'gray'], alpha=0.7)
for i, v in enumerate(value_counts):
plt.text(i, v, str(v), ha='center', va='bottom')
plt.title(f'Value Counts of {column}')
plt.xlabel('Value')
plt.ylabel('Count')
plt.xticks(rotation=0)
plt.show()
df_train.csv
df_test.csv
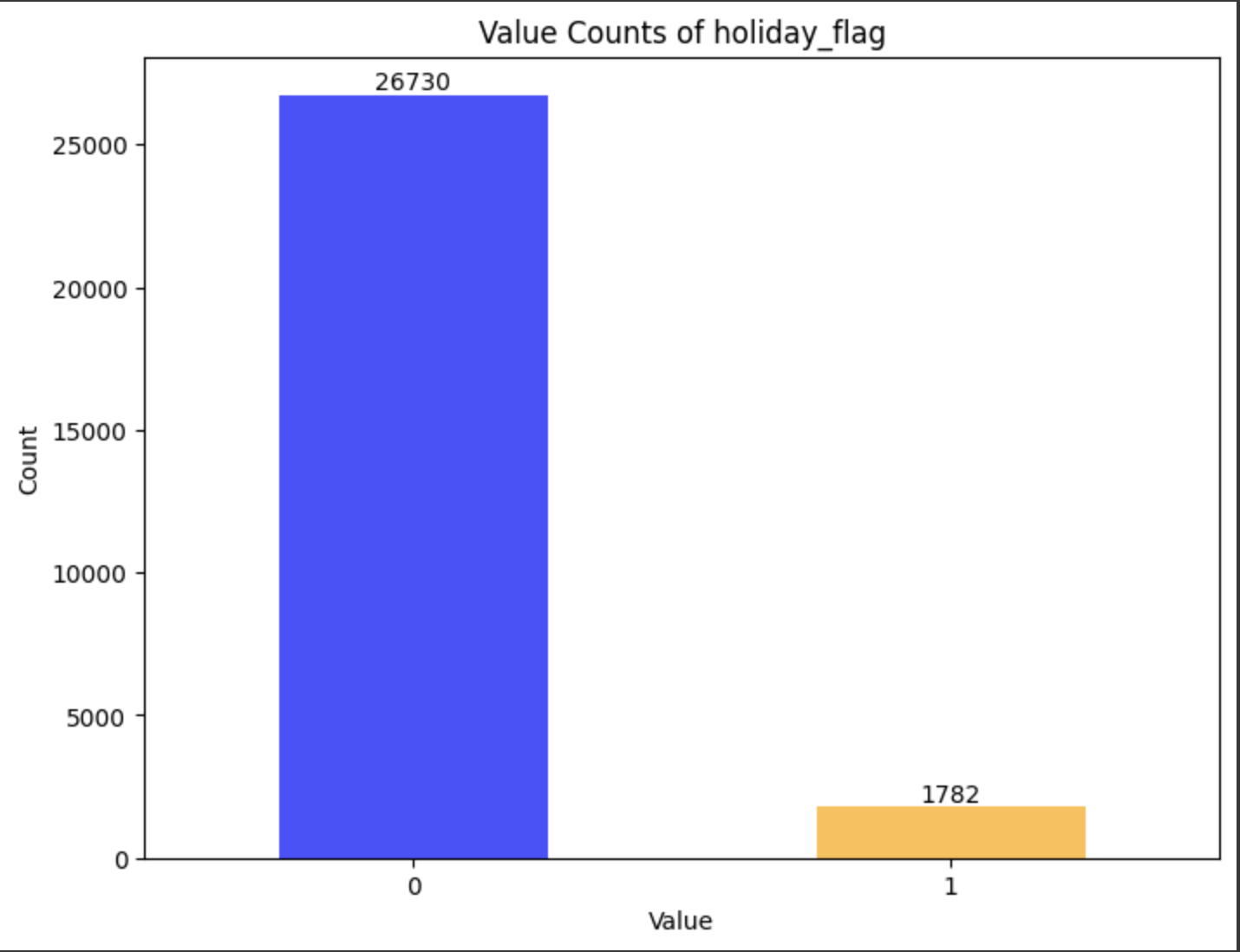
でした。
休みの日の割合は
| train | test | |
|---|---|---|
| 割合(%) | 7.0 | 6.7 |
だいたい同じですね。相関自体は小さいですが入れたほうが...?
しかし、前回相関関係は近いものを使用した方が学習時により良い結果が得られた...どうなんだろう。
学習
学習方法
-
ARIMAとVARを使用 - カラムは相関係数が大事を信じ0.1よりも大きいカラムの3つで行います
- 学習データとテストデータの割合は8対2
-
random_stateは再現性確保のため1指定で固定 -
ARIMAのハイパーパラメータ(p, d, q)- p(自己回帰次数): 過去の観測値が現在の値に与える影響の次数。(部分自己相関関数(PACF)を使用して適切な値を見つける。)
- d(差分次数) : 原系列の階差を取る回数。系列が定常でない場合に指定する必要がある
- q(移動平均次数): 過去の誤差項が現在の値に与える影響の次数。(自己相関関数(ACF)を使用して適切な値を見つける。)
- VARのハイパーパラメータ(VAR次数)
- VAR次数: モデル内の変数間のラグの数。(次数を増やし最小となるところ見つける。)
- 予測結果はRMSE(ルート平均二乗誤差)を使用して評価する
- アンサンブル学習の際は、重み付き平均のアンサンブル手法を使用します
- それぞれの結果を出力し、必要に応じて変更等を加える
最適なハイパーパラメータを探る
PACFグラフとACFグラフを出力します。
lags=31はdf_train.csvを見たところデータの期間が31日間であったため、日ごとの相関を出すためです。
import statsmodels.api as sm
import matplotlib.pyplot as plt
data = pd.read_csv('df_scaled_train.csv')
def plot_acf_pacf(data, lags=31):
fig, ax = plt.subplots(2, 1, figsize=(10, 10))
# ACFの計算とグラフの出力
sm.graphics.tsa.plot_acf(data, lags=lags, ax=ax[0])
ax[0].set_title('Autocorrelation Function (ACF)')
ax[0].set_xlabel('Lags')
ax[0].set_ylabel('Autocorrelation')
# PACFの計算とグラフの出力
sm.graphics.tsa.plot_pacf(data, lags=lags, ax=ax[1])
ax[1].set_title('Partial Autocorrelation Function (PACF)')
ax[1].set_xlabel('Lags')
ax[1].set_ylabel('Partial Autocorrelation')
plt.tight_layout()
plt.show()
plot_acf_pacf(data['sales'])
結果
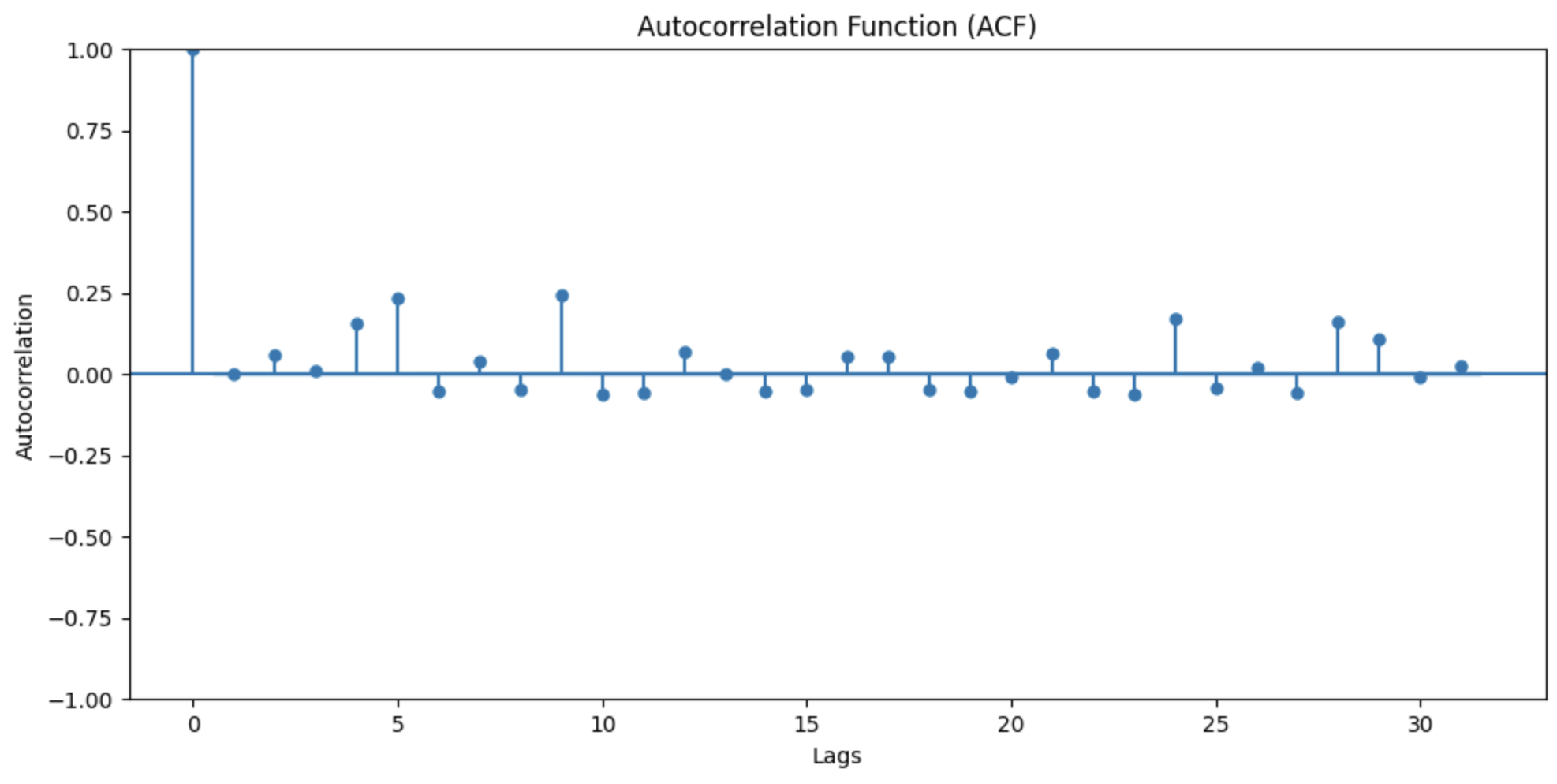
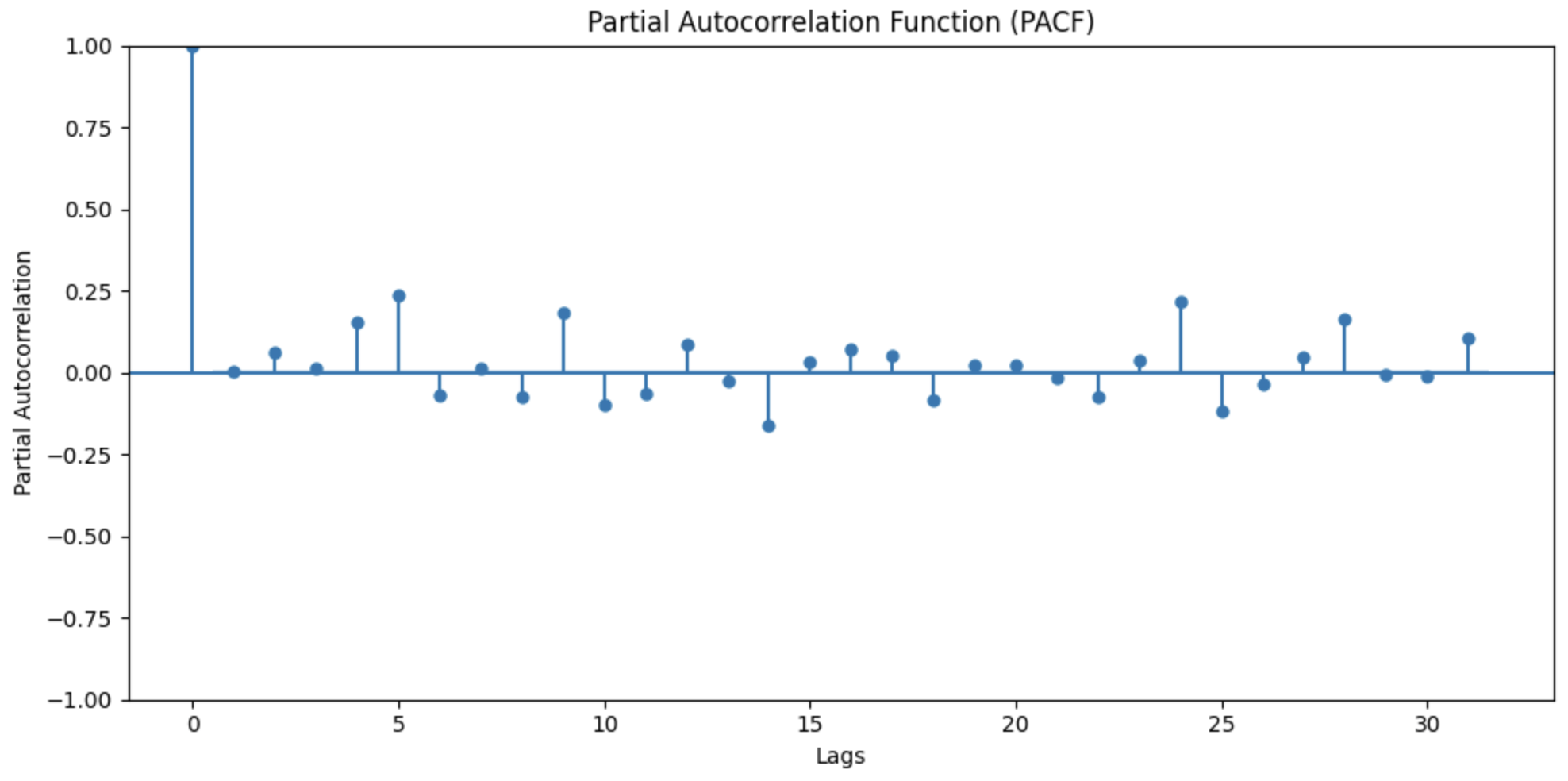
この結果から、ラグ0でどちらも1を取る。その後、急激に0付近に落ち込むことから、
MAモデル。したがって、p=1かつq=0
定常性。したがってd=1
である。と予測を立てたまでは良かったですか。このときに、自動ARIMAというものに出会いました。
自動ARIMAは、AIC(赤池情報量基準)やBIC(ベイズ情報量基準)などの情報量基準を使用してモデルの適合度と複雑さを評価し、最適なハイパーパラメータを選択するものです。
!pip install pmdarima
import pmdarima as pm
のように使用します。
こんないいものが...ということで、ここまでハイパーパラメータの最適化を行いましたが、自動ARIMAを使用します!!!(便利なものは使わないとね)
学習
上記の結果を使用して実際に学習し結果を表示して見ます。(VARでエラーにはまりめちゃめちゃ大変でした。)
!pip install pmdarima
import pandas as pd
from statsmodels.tsa.arima.model import ARIMA
from statsmodels.tsa.api import VAR
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
import pmdarima as pm
df = pd.read_csv('df_scaled_train.csv')
target_variable = 'sales'
feature_columns = ['family_GROCERY I', 'family_BEVERAGES', 'family_CLEANING']
X = df[feature_columns]
y = df[target_variable]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=1)
# 自動ARIMAモデルの定義・学習
auto_arima_model = pm.auto_arima(y_train, exogenous=X_train, seasonal=False, trace=True)
order = auto_arima_model.order
model_arima = ARIMA(y_train, order=order, exog=X_train)
model_fit_arima = model_arima.fit()
# ARIMAモデルで予測
y_pred_arima = model_fit_arima.forecast(steps=len(X_test), exog=X_test)
# VARモデルの定義・学習
endog_train = df[[target_variable] + feature_columns].to_numpy()
model_var = VAR(endog_train)
model_result_var = model_var.fit(maxlags=12, ic='aic')
# VARモデルで予測
predict_var = model_result_var.forecast(model_result_var.endog, steps=len(X_test))
predict_var = pd.DataFrame(predict_var, columns=[target_variable] + feature_columns)
y_pred_var = predict_var[target_variable].values
# アンサンブル学習(仮で0.5)
weight_arima = 0.5
weight_var = 0.5
y_pred_ensemble = weight_arima * y_pred_arima + weight_var * y_pred_var
# モデルの評価: ルート平均二乗誤差(RMSE)
rmse_arima = mean_squared_error(y_test, y_pred_arima) ** 0.5
rmse_var = mean_squared_error(y_test, y_pred_var) ** 0.5
rmse_ensemble = mean_squared_error(y_test, y_pred_ensemble) ** 0.5
# 評価指標の出力
print("ARIMA RMSE:", rmse_arima)
print("VAR RMSE:", rmse_var)
print("Ensemble RMSE:", rmse_ensemble)
結果
とりあえず、結果を見てもらいましょう。(誤差なので小さいほど良いです。)
ARIMA RMSE: 456.2491819478922
VAR RMSE: 648.0050591095548
Ensemble RMSE: 508.59719163963996
うむうむ。salesカラムの最大値と最小値の幅から評価したいので、出力するようにします。
import pandas as pd
df = pd.read_csv('df_scaled_train.csv')
max_sales = df['sales'].max()
min_sales = df['sales'].min()
print("最大値:", max_sales)
print("最小値:", min_sales)
最大値: 19849.0
最小値: 0.0
ということで幅は最大値の値のまま19849ということです。
なので、今回の誤差が幅の何%に当たるのかを計算すると、
ARIMA: 2.297
VAR: 3.264
Ensemble: 2.559
ということが分かりました。最初から精度いいな...ここからカラムの追加等を行って精度が良くなるようにします。
また、自動ARIMAについてですが、私はACFとPACFの結果から (p, d, q,)=(1, 1, 0) と予測しましたが結果は
Performing stepwise search to minimize aic
ARIMA(2,0,2)(0,0,0)[0] : AIC=inf, Time=74.84 sec
ARIMA(0,0,0)(0,0,0)[0] : AIC=1034683.283, Time=0.69 sec
ARIMA(1,0,0)(0,0,0)[0] : AIC=1034294.979, Time=0.81 sec
ARIMA(0,0,1)(0,0,0)[0] : AIC=1034343.333, Time=2.24 sec
ARIMA(2,0,0)(0,0,0)[0] : AIC=1033955.444, Time=1.49 sec
ARIMA(3,0,0)(0,0,0)[0] : AIC=1033671.732, Time=3.52 sec
ARIMA(4,0,0)(0,0,0)[0] : AIC=1033443.924, Time=2.33 sec
ARIMA(5,0,0)(0,0,0)[0] : AIC=1033221.007, Time=2.57 sec
ARIMA(5,0,1)(0,0,0)[0] : AIC=inf, Time=99.40 sec
ARIMA(4,0,1)(0,0,0)[0] : AIC=inf, Time=74.53 sec
ARIMA(5,0,0)(0,0,0)[0] intercept : AIC=1029471.062, Time=4.88 sec
ARIMA(4,0,0)(0,0,0)[0] intercept : AIC=1029469.087, Time=4.91 sec
ARIMA(3,0,0)(0,0,0)[0] intercept : AIC=1029467.877, Time=3.05 sec
ARIMA(2,0,0)(0,0,0)[0] intercept : AIC=1029465.900, Time=2.48 sec
ARIMA(1,0,0)(0,0,0)[0] intercept : AIC=1029463.939, Time=1.89 sec
ARIMA(0,0,0)(0,0,0)[0] intercept : AIC=1029461.940, Time=2.25 sec
ARIMA(0,0,1)(0,0,0)[0] intercept : AIC=1029463.939, Time=4.28 sec
ARIMA(1,0,1)(0,0,0)[0] intercept : AIC=1029465.944, Time=4.40 sec
Best model: ARIMA(0,0,0)(0,0,0)[0] intercept
となり、 (p, d, q)=(0 ,0, 0) が最適なようです。しかし、AICが高いような...まぁ結果出てるから!
より良いモデルがあれば、まとめに書きます。
まとめ
全カラムに対して学習すると良い良い結果が得られた。しかし、VARはカラムが10個のあたりから精度が変化しないことから重みを低く設定しARIMAを高めの設定にします。その最適化の結果が下記です。
学習
!pip install pmdarima
import pandas as pd
from statsmodels.tsa.arima.model import ARIMA
from statsmodels.tsa.api import VAR
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
import pmdarima as pm
df = pd.read_csv('df_scaled_train.csv')
target_variable = 'sales'
feature_columns = ['family_GROCERY I', 'family_BEVERAGES', 'family_CLEANING', 'family_HOME CARE', 'family_HOME AND KITCHEN I', 'family_HOME AND KITCHEN II', 'family_CELEBRATION', 'family_BOOKS', 'family_BABY CARE', 'family_LADIESWEAR']
# 除外するカラム
# exclude_columns = ['id', 'sales', 'onpromotion', 'Year']
X = df[feature_columns]
# 除外したカラム以外で学習
# X = df.drop(columns=exclude_columns, axis=1)
y = df[target_variable]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=1)
# 自動ARIMAモデルの作成と学習
auto_arima_model = pm.auto_arima(y_train, exogenous=X_train, seasonal=False, trace=True)
order = auto_arima_model.order
model_arima = ARIMA(y_train, order=order, exog=X_train)
model_fit_arima = model_arima.fit()
# ARIMAモデルによる予測
y_pred_arima = model_fit_arima.forecast(steps=len(X_test), exog=X_test)
# VARモデルの作成と学習
endog_train = df[[target_variable] + feature_columns].to_numpy()
model_var = VAR(endog_train)
model_result_var = model_var.fit(maxlags=12, ic='aic')
# VARモデルによる予測
predict_var = model_result_var.forecast(model_result_var.endog, steps=len(X_test))
predict_var = pd.DataFrame(predict_var, columns=[target_variable] + feature_columns)
y_pred_var = predict_var[target_variable].values
# アンサンブル学習では予測を重み付き平均する
weight_arima = 0.5931
weight_var = 0.4069
y_pred_ensemble = weight_arima * y_pred_arima + weight_var * y_pred_var
# モデルの評価: ルート平均二乗誤差(RMSE)
rmse_arima = mean_squared_error(y_test, y_pred_arima) ** 0.5
rmse_var = mean_squared_error(y_test, y_pred_var) ** 0.5
rmse_ensemble = mean_squared_error(y_test, y_pred_ensemble) ** 0.5
# 評価指標の出力
print("ARIMA RMSE:", rmse_arima)
print("VAR RMSE:", rmse_var)
print("Ensemble RMSE:", rmse_ensemble)
色々試した結果
# カラム3
ARIMA RMSE: 456.2491819478922
VAR RMSE: 648.0050591095548
Ensemble RMSE: 508.59719163963996
# カラム10
ARIMA RMSE: 454.96773399732973
VAR RMSE: 648.0323978589845
Ensemble RMSE: 507.71686526954943
# 全カラム
ARIMA RMSE: 444.5012332005806
VAR RMSE: 648.0323978589845
Ensemble RMSE: 500.67140297994246
# 7:3
ARIMA RMSE: 444.5012332005806
VAR RMSE: 648.0323978589845
Ensemble RMSE: 464.2128988812459
# 8:2
ARIMA RMSE: 444.5012332005806
VAR RMSE: 648.0323978589845
Ensemble RMSE: 452.63176423967025
# 0.5931:0.4069 アンサンブルの精度が最も良さそう。計算値
ARIMA RMSE: 444.5012332005806
VAR RMSE: 648.0323978589845
Ensemble RMSE: 481.64693947011176
# カラム3
ARIMA RMSE: 456.2491819478922
VAR RMSE: 648.0050591095548
Ensemble RMSE: 508.59719163963996
# カラム10
ARIMA RMSE: 454.96773399732973
VAR RMSE: 648.0323978589845
Ensemble RMSE: 507.71686526954943
# 全カラム
ARIMA RMSE: 444.5012332005806
VAR RMSE: 648.0323978589845
Ensemble RMSE: 500.67140297994246
# 7:3
ARIMA RMSE: 5093.568584420654
VAR RMSE: 648.0323978589845
Ensemble RMSE: 464.2128988812459
# 8:2
ARIMA RMSE: 444.5012332005806
VAR RMSE: 648.0323978589845
Ensemble RMSE: 452.63176423967025
# 0.5931:0.4069 アンサンブルの精度が最も良さそう。計算値
ARIMA RMSE: 444.5012332005806
VAR RMSE: 648.0323978589845
Ensemble RMSE: 481.64693947011176
# 15カラム 0.5931:0.4069
ARIMA RMSE: 453.4162909817819
VAR RMSE: 756.8136533784282
Ensemble RMSE: 513.5280495556575
# 13カラム 0.5931:0.4069
ARIMA RMSE: 454.142427923321
VAR RMSE: 756.809505295291
Ensemble RMSE: 514.1126849128196
# 11カラム 0.5931:0.4069
ARIMA RMSE: 454.7205197059519
VAR RMSE: 756.826237116249
Ensemble RMSE: 514.4598835472658
# カラム10 0.5931:0.4069
ARIMA RMSE: 454.96773399732973
VAR RMSE: 648.0323978589845
Ensemble RMSE: 489.77718099724
カラム10個がいいですね。
予測
※全カラムを学習対象にすると自動ARIMAの計算に時間がかかり過ぎてしまいColabではクラッシュしてしまうので、カラムを絞っています。
学習データとテストデータを8:2で分けていたのでそれを全部学習に回すだけで自動ARIMAの収束がここまで遅くなるとは思いませんでした。
!pip install pmdarima
import pandas as pd
from statsmodels.tsa.arima.model import ARIMA
from statsmodels.tsa.api import VAR
import pmdarima as pm
df_train = pd.read_csv('df_scaled_train.csv')
df_test = pd.read_csv('df_scaled_test.csv')
target_variable = 'sales'
feature_columns = ['family_GROCERY I', 'family_BEVERAGES', 'family_CLEANING', 'family_HOME CARE', 'family_HOME AND KITCHEN I', 'family_HOME AND KITCHEN II', 'family_CELEBRATION', 'family_BOOKS', 'family_BABY CARE', 'family_LADIESWEAR']
# 学習データを定義
X_train = df_train[feature_columns]
y_train = df_train[target_variable]
# ARIMAモデルの定義と学習
auto_arima_model = pm.auto_arima(y_train, exogenous=X_train, seasonal=False, trace=True)
order = auto_arima_model.order
model_arima = ARIMA(y_train, order=order, exog=X_train)
model_fit_arima = model_arima.fit()
# VARモデルの定義と学習
endog_train = df_train[[target_variable] + feature_columns].to_numpy()
model_var = VAR(endog_train)
model_result_var = model_var.fit(maxlags=12, ic='aic')
# テストデータの定義
X_test = df_test[feature_columns]
# ARIMAモデルによる予測
y_pred_arima = model_fit_arima.forecast(steps=len(X_test), exog=X_test)
# VARモデルによる予測
predict_var = model_result_var.forecast(model_result_var.endog, steps=len(X_test))
predict_var = pd.DataFrame(predict_var, columns=[target_variable] + feature_columns)
y_pred_var = predict_var[target_variable].values
# アンサンブル学習
weight_arima = 0.8
weight_var = 0.2
y_pred_ensemble = weight_arima * y_pred_arima + weight_var * y_pred_var
# df_scaled_test.csvのidカラムを取得
test_ids = df_test['id']
results = pd.DataFrame(zip(test_ids.astype(int), y_pred_ensemble), columns=['id', 'sales'])
results.to_csv('predictions_ensemble_8_2.csv', index=False)
で作成した結果を提出したところ
スコア: 2.14173
でした。せめて1.0代には乗りたかった...
8:2が最もよく精度がよく
スコア: 2.11256
でした。