pandas の使い方を学ぶために色々と触ってみました。
メモを残しておきます。
この記事に書いたこと
- CSVの読み込み
- データの構造確認
- 範囲指定での表示
- 指定条件での抽出
- グループごとに集計
- ピボットテーブル
- グラフ描画
使用したデータ
ポケモンの種族値データを使用します。
スキーマの整ったきれいなデータかつ、データの中身に意味のあるものを使いたかったのが理由です。
ポケモンの種族値データはこちらで配布されているものを使用させていただきました。ありがとうございます。
ポケモンの種族値データシートの配布【第7世代】
準備
まずは、pandas を import します。
import pandas as pd
CSV の読み込み
df = pd.read_csv("pokemon_status.csv")
# utf-8 でない場合は、エンコードを指定します。
df = pd.read_csv("pokemon_status.csv", encoding="shift-jis")
[参考] pandasでread_csv時にUnicodeDecodeErrorが起きた時の対処 (pd.read_table())
ちなみに df はデータフレームから取っています。
カラム名の設定
のちの操作をしやすくするために、カラム名を設定します。
df.columns = ["図鑑番号", "ポケモン名", "タイプ1", "タイプ2",\
"通常特性1", "通常特性2", "夢特性",\
"HP", "こうげき", "ぼうぎょ", "とくこう", "とくぼう", "すばやさ", "合計"]
データの構造確認
# 行数
len(df)
# 列名
df.columns
# 次元数 (行数、列数)
df.shape
# データフレームの情報サマリ (行数、列名と型、など)
df.info()
# サマリを表示
df.describe()
範囲指定での表示
# 先頭 5 行を表示
df.head()
# ポケモン名の一覧
df["ポケモン名"]
# 指定列だけ表示
df.loc[:,["ポケモン名", "タイプ1", "タイプ2"]]
列の追加、削除
計算結果を新たな列として追加。
# 以降の作業はコピーしたデータフレームに対して実施。
df2 = df.copy()
# 物理耐久最大値列を追加。(レベル 50 物理耐久特化時の HP × ぼうぎょの計算結果)
df2["物理耐久最大値"] = (df2["HP"] + 107 ) * (df2["ぼうぎょ"] + 52 * 1.1)
指定した列を削除。
df3 = df.drop(["通常特性1", "通常特性2", "夢特性"], axis=1)
ソート
# 素早さの降順でソート
df.sort("すばやさ", ascending=False)
指定条件で抽出
# でんきタイプの素早さ種族値 100 以上のポケモンを抽出し、素早さの降順にソートしてポケモン名と種族値を表示
df.query("タイプ1 == 'でんき' | タイプ2 == 'でんき'").\
query("すばやさ >= 100").\
sort("すばやさ", ascending=False).\
loc[:,["ポケモン名", "HP", "こうげき", "ぼうぎょ", "とくこう", "とくぼう", "すばやさ", "合計"]]
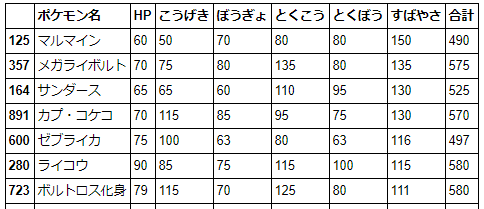
マルマインは第7世代から素早さ種族値が 140 から 150 に上がっています。
グループごとに集計
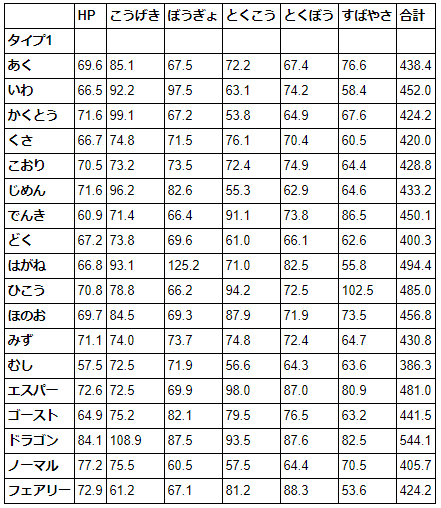
タイプごとに種族値平均値を表示。
# mean は平均、round は小数点以下 1 桁に丸める。
df.groupby("タイプ1").mean().round(1)
※簡略化のため、タイプ1のみで集計
ピボットテーブル
行をタイプ1、列をタイプ2にしてカウント。
# aggfunc はカウント、fill_value は NaN のセルを 0 にする。
pd.pivot_table(df, values="図鑑番号", index="タイプ1", columns="タイプ2", aggfunc=lambda x : len(x), fill_value = 0)
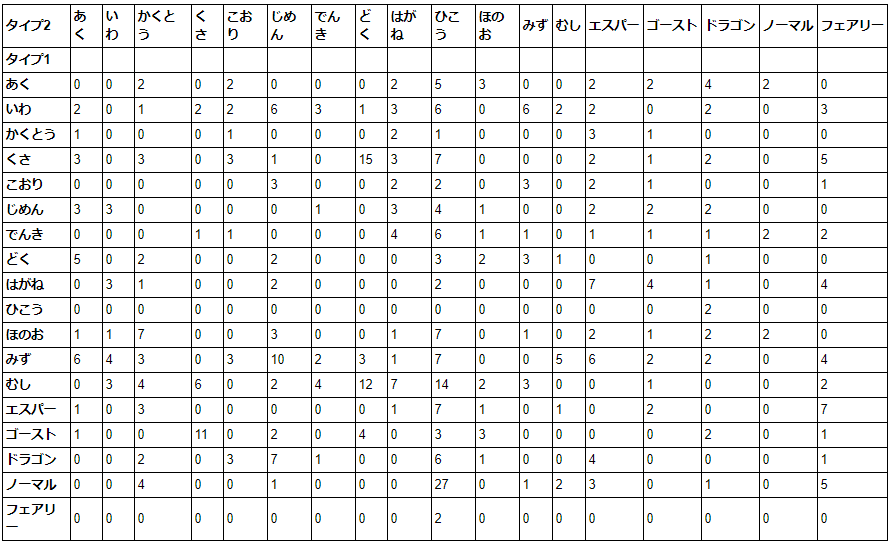
ノーマル、ひこうの組み合わせが一番多いです。
グラフ描画
準備
Jupyter Notebook で作業するときは、下記コマンドを入力しておいてください。
%matplotlib inline
[参考] Jupyter Notebookでmatplotlibのグラフが表示されない
日本語を使えるようにしておきます。
[参考] matplotlibの日本語フォント設定
きれいに描画するためのおまじないだそうです。フォントはIPA明朝としています。
import matplotlib
import matplotlib.pyplot as plt
plt.style.use("ggplot")
font = {"family":"IPAMincho"}
matplotlib.rc("font", **font)
[参考] JPythonでPandasのPlot機能を使えばデータ加工からグラフ作成までマジでシームレス
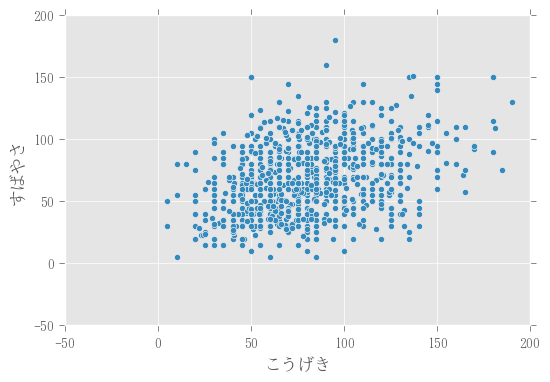
散布図
攻撃と素早さの散布図。
df.plot.scatter(x="こうげき", y="すばやさ")
ヒストグラム
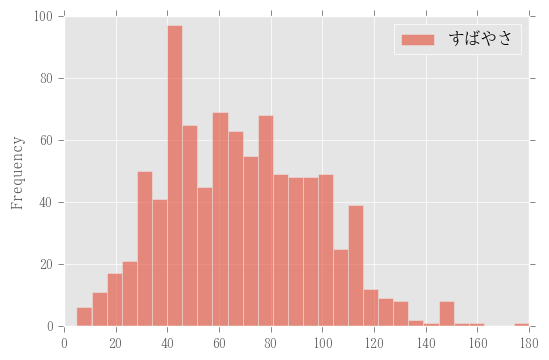
素早さのヒストグラム。
# bins は分割数、アルファは透過度合い。
df.plot.hist(y="すばやさ", bins=30, alpha=0.6)
でんきタイプといわタイプの素早さ分布比較。
df_denki = df.query("タイプ1 == 'でんき' | タイプ2 == 'でんき'")
df_iwa = df.query("タイプ1 == 'いわ' | タイプ2 == 'いわ'")
fig = plt.figure()
ax = fig.add_subplot(1,1,1)
ax.hist([df_denki["すばやさ"], df_iwa["すばやさ"]], bins=15, alpha=0.6, label=["でんき", "いわ"])
ax.legend(loc="upper right")
fig.show()
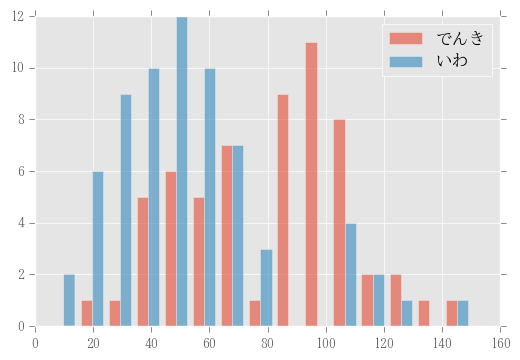
でんきタイプには素早いポケモンが多く、いわタイプは鈍足が多いことがグラフからも読み取れます。