この記事では、pandas の read_csv のオプションだけで、時系列データとして扱いやすいデータフレームを作成する方法を示します。Jupyter Notebook 上で作業していることを前提にします。
結論
気象庁が公開している csv を、以下のオプション指定で読み込みます。
df = pd.read_csv('data.csv',
encoding='SHIFT-JIS', # 文字コードを指定
skiprows=6, # 読み飛ばす先頭行数を指定
usecols=[0, 1, 4, 7], # どの列を読み込むかを指定
names=['date', 'average', 'high', 'low'], # カラム名を設定
parse_dates=['date'], # datetime で読み込むカラムを指定
index_col=['date']) # インデックスにするカラムを指定
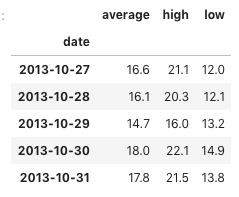
すると、以下のようにインデックスが DatetimeIndex となったデータフレームが作られます。
以下は解説です。
データソースの CSV
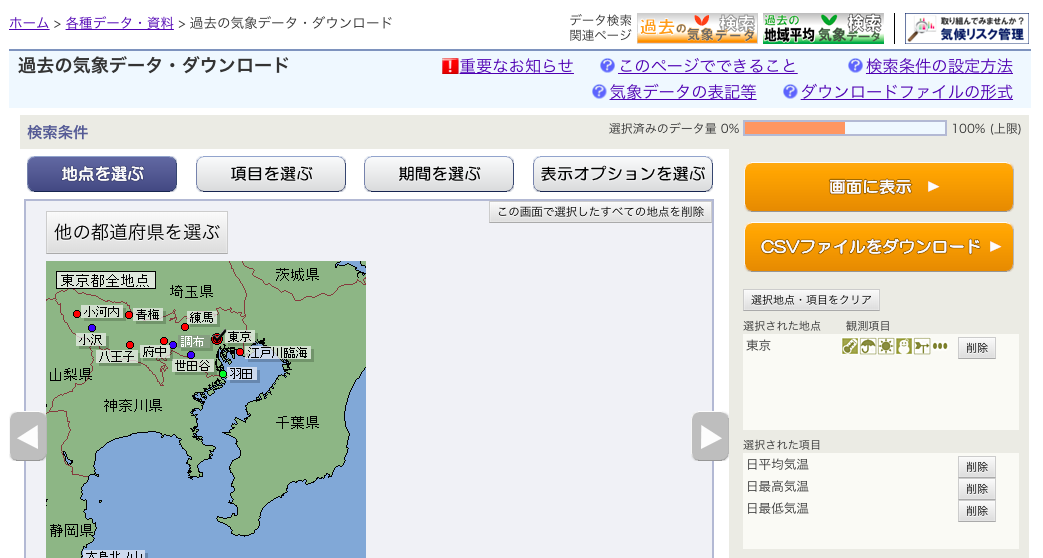
気象庁が公開している気象データを使用します。
https://www.data.jma.go.jp/gmd/risk/obsdl/index.php
地点を東京、項目を日平均気温、日最高気温、日最低気温、期間は過去 5 年分としてダウンロードします。
オプション指定なして read_csv を使用した場合
まず、パッケージをインポートします。
import pandas as pd
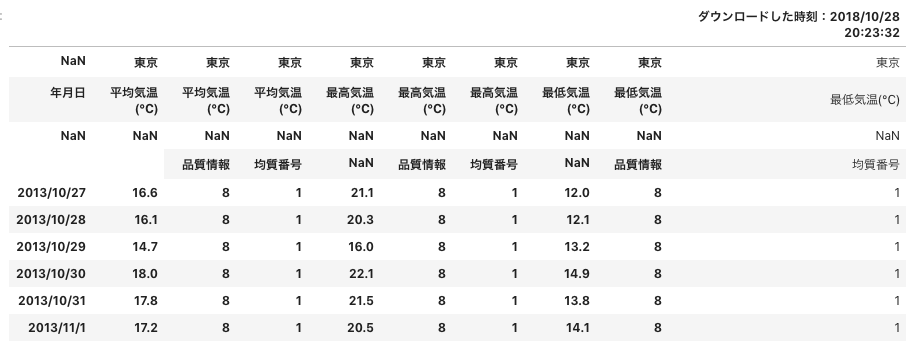
文字コードの指定だけした状態で read_csv で CSV ファイルを読み込みます。
df = pd.read_csv('data.csv', encoding='SHIFT-JIS')
すると以下のようなデータフレームが作られました。ここから加工することもできますが、read_csv 時に綺麗な状態で取り込めるといいですよね。
オプションを指定して read_csv を使用する
上記の結論に書いた内容と重複しますが、read_csv のオプションを活用して、時系列データを扱いやすくするようにデータフレームを読み込みます。
df = pd.read_csv('data.csv',
encoding='SHIFT-JIS', # 文字コードを指定
skiprows=6, # 読み飛ばす先頭行数を指定
usecols=[0, 1, 4, 7], # どの列を読み込むかを指定
names=['date', 'average', 'high', 'low'], # カラム名を設定
parse_dates=['date'], # datetime で読み込むカラムを指定
index_col=['date']) # インデックスにするカラムを指定
すると、次のようなデータフレームが作られます。
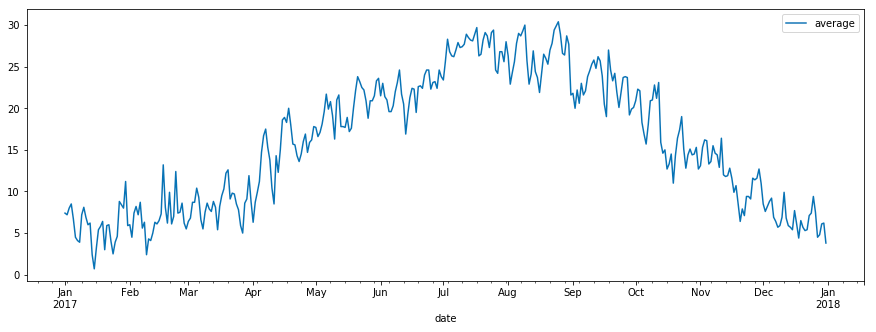
この状態だとインデックスが DatetimeIndex になっていますので、日時を指定した操作がしやすいです。例として、2017 年の日平均気温の折れ線グラフを描画する場合は、以下のように書きます。
%matplotlib inline
df.loc['2017'].plot(y='average', figsize=(15, 5))