この記事は、Julia Advent Calendar 2017 の3日目の記事です。
Julia では関数は第一級オブジェクトであり、関数の中で関数を定義することとかも普通にできるし、Closure も普通に定義できます。
ただ、Julia に限った話ではないですが、Closure って気軽に手軽に定義できるけれど、決してパフォーマンス良くないんですよね。
その理由と、Julia における「Closure のパフォーマンス改善」について少し解説してみます。
Julia の対象バージョンは v0.6.x(v0.6.1 で動作確認済)1。
お題:Xorshift32
Closure の良い例がなかなか浮かばなかったのですが、単純すぎず複雑すぎずと言うことで、Xorshift(32bit版)を取り上げます2。
Closure によるシンプルな実装
まずはこれを Closure でシンプルに実装してみます。
function xorshift32_cl(seed::UInt32=0x92d68ca2)
y = seed
return function inner()
y = y ⊻ (y << 13)
y = y ⊻ (y >> 17)
y = y ⊻ (y << 5)
return y
end
end
y という関数外(静的スコープ内)の変数を参照・更新しながら、次々と次の値を算出しています。典型的な Closure、典型的な Xorshift32 の実装ですね3。
動作確認:
julia> rgn = xorshift32_cl()
(::inner) (generic function with 1 method)
julia> for _=1:10
println(rgn())
end
723471715
2497366906
2064144800
2008045182
3532304609
374114282
1350636274
691148861
746858951
2653896249
julia> @time for _=1:10000; rgn(); end
0.002749 seconds (59.66 k allocations: 932.203 KiB)
うん、期待通りに動くし、@time マクロの結果を見る限りは、別にそんなにパフォーマンス悪くなくね?て思われるかもしれません。
次に、これを型推論してみた結果を @code_warntype マクロで見てみます。
julia> @code_warntype rgn()
Variables:
#self#::#inner#1
Body:
begin
SSAValue(0) = ((Core.getfield)((Core.getfield)(#self#::#inner#1, :y)::Any, :contents)::Any ⊻ ((Core.getfield)((Core.getfield)(#self#::#inner#1, :y)::Any, :contents)::Any << 13)::Any)::Any
(Core.setfield!)((Core.getfield)(#self#::#inner#1, :y)::Any, :contents, SSAValue(0))::Any # line 5:
SSAValue(1) = ((Core.getfield)((Core.getfield)(#self#::#inner#1, :y)::Any, :contents)::Any ⊻ ((Core.getfield)((Core.getfield)(#self#::#inner#1, :y)::Any, :contents)::Any >> 17)::Any)::Any
(Core.setfield!)((Core.getfield)(#self#::#inner#1, :y)::Any, :contents, SSAValue(1))::Any # line 6:
SSAValue(2) = ((Core.getfield)((Core.getfield)(#self#::#inner#1, :y)::Any, :contents)::Any ⊻ ((Core.getfield)((Core.getfield)(#self#::#inner#1, :y)::Any, :contents)::Any << 5)::Any)::Any
(Core.setfield!)((Core.getfield)(#self#::#inner#1, :y)::Any, :contents, SSAValue(2))::Any # line 7:
return (Core.getfield)((Core.getfield)(#self#::#inner#1, :y)::Any, :contents)::Any
end::Any
これ、Qiita のシンタックスハイライトでは現れないのですが、Julia の REPL や Jupyter notebook 等で実行↓すると、結果中の ::Any の部分が赤(系の警告色)で表示されています4。
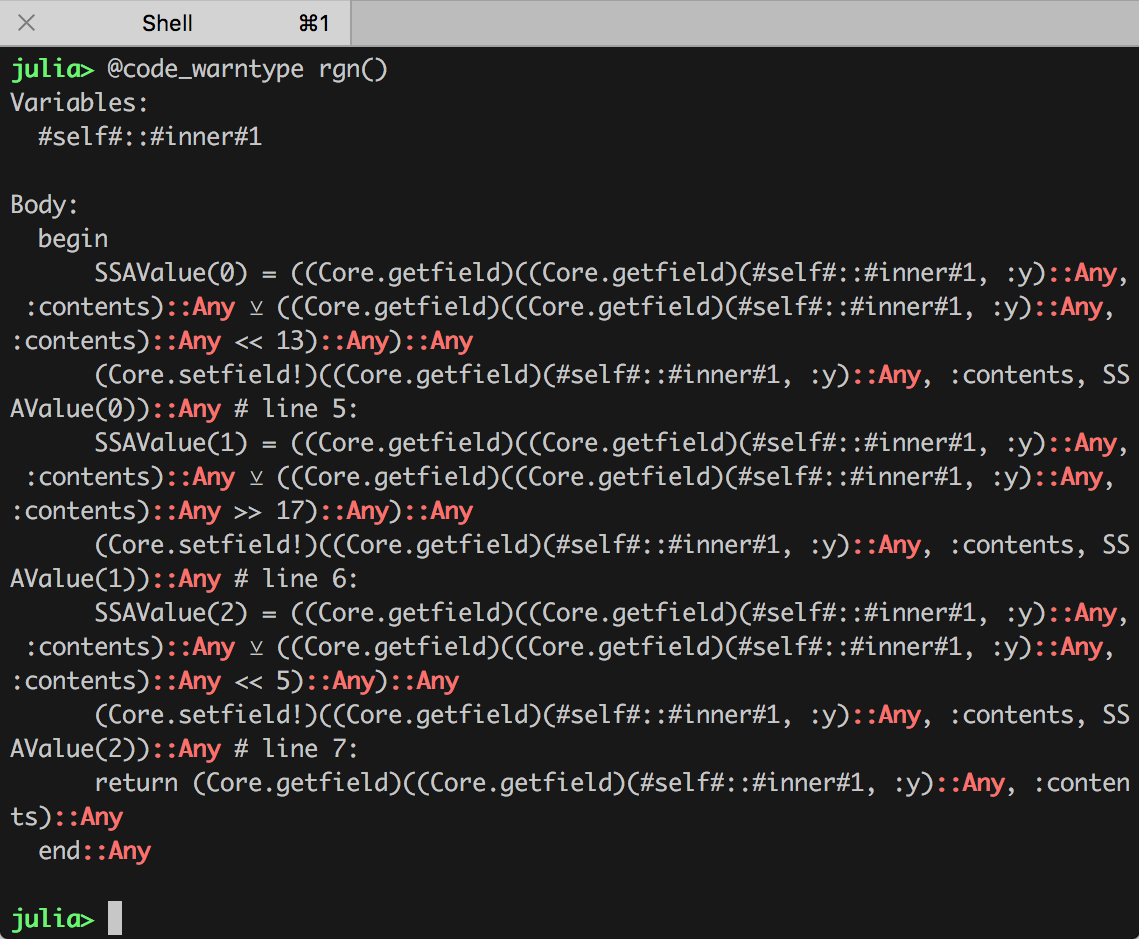
これが何を意味しているのかというと。
まず型推論の結果、y という関数外(静的スコープ内)の変数の型が推論できず、「しょうがないから Any 型として扱っちゃいますよ」という事態が起こっているのです。実際には UInt32 型のはずなのに、JITコンパイラ(正確にはその手前の型推論時の最適化処理時)にはそれが分からないのです。
そして y 以外の箇所も(多くは演算結果の型を推論した箇所ですが)やはり「型が分からない値の処理結果なのでやはり型が分からないので、やっぱり Any 型としか扱えないですよ」ということ。早い話が、最適化が全く期待できないのです。
あとついでに言うと、『関数外(静的スコープ内)の変数を参照・更新』、という言葉通り、変数 y を参照・更新する箇所に軒並み (Core.getfield)((Core.getfield)(#self#::#inner#1, :y)::Any, :contents)::Any という中間コードが現れています。日本語で読み解くと、『#self#(これが静的スコープですね)から y という変数を参照して、さらにその中身を取得する(でもその型は不明だからとりあえず ::Any で)』みたいな感じになっています。これ、なんだかもったいなさそうですよね。特に getfield() が入れ子になって2ステップ踏んでる。これ減らせると、パフォーマンス改善に繋がりそうですよね。
この2点を解決・解消する、2つの方法を紹介します。その2つとは以下:
- 型アノテーションを付ける
- Functor に乗り換える
Closure + 型アノテーションによる実装
適当な箇所に型アノテーションを付けたりして、以下のように書き換えてみました。
function xorshift32_cl2(seed::UInt32=0x92d68ca2)
y = seed
return function inner()::UInt32
_y = y::UInt32
_y = _y ⊻ (_y << 13)
_y = _y ⊻ (_y >> 17)
_y = _y ⊻ (_y << 5)
y = _y
return _y
end
end
y という関数外(静的スコープ内)の変数の参照・更新は最低限にして、その代わりローカル変数 _y を用意し基本そちらで処理。
あとポイントは、最初の変数代入時に _y = y::UInt32 と 型アノテーション を付けていること。
動作確認:
julia> rgn2 = xorshift32_cl2()
(::inner) (generic function with 1 method)
julia> for _=1:10
println(rgn2())
end
723471715
2497366906
2064144800
2008045182
3532304609
374114282
1350636274
691148861
746858951
2653896249
julia> @time for _=1:10000; rgn2(); end
0.000561 seconds (20.00 k allocations: 312.500 KiB)
実行結果は期待通り。
@time マクロの結果を見ると、実行時間は 約1/5、メモリ使用量は 約1/3!
@code_warntype の結果も見てみましょう。
julia> @code_warntype rgn2()
Variables:
#self#::#inner#2
_y::UInt32
Body:
begin
_y::UInt32 = (Core.typeassert)((Core.getfield)((Core.getfield)(#self#::#inner#2, :y)::Any, :contents)::Any, Main.UInt32)::UInt32 # line 5:
_y::UInt32 = (Base.xor_int)(_y::UInt32, (Base.select_value)((Base.sle_int)(0, 13)::Bool, (Base.shl_int)(_y::UInt32, (Base.bitcast)(UInt64, 13))::UInt32, (Base.lshr_int)(_y::UInt32, (Base.bitcast)(UInt64, (Base.neg_int)(13)::Int64))::UInt32)::UInt32)::UInt32 # line 6:
_y::UInt32 = (Base.xor_int)(_y::UInt32, (Base.select_value)((Base.sle_int)(0, 17)::Bool, (Base.lshr_int)(_y::UInt32, (Base.bitcast)(UInt64, 17))::UInt32, (Base.shl_int)(_y::UInt32, (Base.bitcast)(UInt64, (Base.neg_int)(17)::Int64))::UInt32)::UInt32)::UInt32 # line 7:
_y::UInt32 = (Base.xor_int)(_y::UInt32, (Base.select_value)((Base.sle_int)(0, 5)::Bool, (Base.shl_int)(_y::UInt32, (Base.bitcast)(UInt64, 5))::UInt32, (Base.lshr_int)(_y::UInt32, (Base.bitcast)(UInt64, (Base.neg_int)(5)::Int64))::UInt32)::UInt32)::UInt32 # line 8:
SSAValue(1) = _y::UInt32
(Core.setfield!)((Core.getfield)(#self#::#inner#2, :y)::Any, :contents, SSAValue(1))::UInt32 # line 9:
return _y::UInt32
end::UInt32
::Any は、コードの最初の方に2箇所、最後に1箇所の、計3箇所に減りました。変数 _y は正しく ::UInt32 と推論されています。
一方で、変換後のコード自体はむしろごちゃごちゃした印象を受けるかもしれません。でもこれで正解です。これは、適切な最適化処理が走り、⊻, <<, >> の各演算子が適切な関数に置き換えられたコードが表示されているのです。
逆に元のシンプルな Closure の方は、最適化処理が走っていないために、プログラマが記述したコードほぼそのまま直訳したモノになってしまっているわけです。
Functor による実装
続いて、これを Functor という形で書き直してみます。
mutable struct Xorshift32
y::UInt32
Xorshift32() = new(0x92d68ca2)
end
function (g::Xorshift32)()
_y = g.y
_y = _y ⊻ (_y << 13)
_y = _y ⊻ (_y >> 17)
_y = _y ⊻ (_y << 5)
g.y = _y
return _y
end
mutable struct Xorshift32 〜 end は、変更可能な型の定義5。
その後の function (g::Xorshift32)() 〜 end が、Functor の定義。通常の関数定義とほぼ同じ書式で、関数名の代わりに (g::Xorshift32) のように『(対象となるインスタンスとその)型』を記述した形になっています6。
Functor7 とは、簡単に言うと、「呼び出し可能オブジェクト」のことです。呼び出し可能オブジェクトとは、obj() のように、関数呼び出しの書式で特定の処理を実行できるオブジェクトのこと。
特に Julia(や Python など)では、「呼び出し可能オブジェクトのうち、関数・型(Python ならクラス、クラスのメソッドなども)以外のもの」を指して Functor と呼びます8。
つまり。ここでは新しい型を定義しているのですが、そのインスタンスを「呼び出し可能オブジェクト(Functor)」として、Closure と同じような感覚で使えるようにしたモノを使ってみる、ということ。
具体的には、以下の動作確認を見てください:
julia> rgn3 = Xorshift32()
Xorshift32(0x92d68ca2)
julia> for _=1:10
println(rgn3())
end
723471715
2497366906
2064144800
2008045182
3532304609
374114282
1350636274
691148861
746858951
2653896249
julia> @time for _=1:10000; rgn3(); end
0.000241 seconds (10.00 k allocations: 156.250 KiB)
ほら。生成方法・実行方法は、Closure と見た目全く同様。実行結果ももちろん全く同じ。
そしてパフォーマンスを見ると、元のシンプルな Closure 実装と比較して、所要時間は1/10以下、使用メモリは約1/6! 型アノテーションを付けた Closure 実装と比較するとどちらも 約1/2!
@code_warntype の結果は以下の通り。
julia> @code_warntype rgn3()
Variables:
g::Xorshift32
_y::UInt32
Body:
begin
_y::UInt32 = (Core.getfield)(g::Xorshift32, :y)::UInt32 # line 8:
_y::UInt32 = (Base.xor_int)(_y::UInt32, (Base.select_value)((Base.sle_int)(0, 13)::Bool, (Base.shl_int)(_y::UInt32, (Base.bitcast)(UInt64, 13))::UInt32, (Base.lshr_int)(_y::UInt32, (Base.bitcast)(UInt64, (Base.neg_int)(13)::Int64))::UInt32)::UInt32)::UInt32 # line 9:
_y::UInt32 = (Base.xor_int)(_y::UInt32, (Base.select_value)((Base.sle_int)(0, 17)::Bool, (Base.lshr_int)(_y::UInt32, (Base.bitcast)(UInt64, 17))::UInt32, (Base.shl_int)(_y::UInt32, (Base.bitcast)(UInt64, (Base.neg_int)(17)::Int64))::UInt32)::UInt32)::UInt32 # line 10:
_y::UInt32 = (Base.xor_int)(_y::UInt32, (Base.select_value)((Base.sle_int)(0, 5)::Bool, (Base.shl_int)(_y::UInt32, (Base.bitcast)(UInt64, 5))::UInt32, (Base.lshr_int)(_y::UInt32, (Base.bitcast)(UInt64, (Base.neg_int)(5)::Int64))::UInt32)::UInt32)::UInt32 # line 11:
(Core.setfield!)(g::Xorshift32, :y, _y::UInt32)::UInt32 # line 12:
return _y::UInt32
end::UInt32
まず、::Any が1箇所もありません。あと Closure の場合と比較すると、先ほど関数外(静的スコープ内)から参照していた箇所がローカル変数 g からのメンバ参照となりその部分が (Core.getfield)(g::Xorshift32, :y) という1ステップで済んでいます。更新する際も
setfield! が1回呼ばれているだけ。これらが、残りの「パフォーマンスの差」として現れている模様です。
そもそも…
Functor、というか 型定義 して処理、って話が出た時点で、中級以上の方は「いやいやそもそも新しい型を定義するのが面倒だから Closure 利用するんだよ」って仰る方もいらっしゃるかもしれません。
また Functor というものはそもそも、Closure の完全なる代替物ではありません。
ちょっとそのあたりの、共通点や差異をまとめてみました。
| Closure | Functor | |
|---|---|---|
| 定義のしかた | 関数内関数(など) | 型定義+関数(のような特別な書式) |
| 利用方法 | 普通の関数呼び出し (だって関数なので) |
見た目普通の関数呼び出し (呼び出し可能オブジェクト) |
| 型 | Function(の subtype) | 任意の型 |
| 内部変数 | アクセスできない (カプセル化) |
アクセスできる (例: t.a) |
| パフォーマンス | 少し悪い | 良い |
| 記述量 | そこそこ少ない | ←より少し多い |
Closure(日本語では『関数閉包』)とは、自身が定義された静的スコープの変数等の参照を保持している関数オブジェクト。
その一番の特徴は、内部状態(を保持する静的スコープの変数等)に直接アクセスできない、ということ(カプセル化)。加えて「それを少ない記述量で実現できる」のでよく利用される、というわけです。
一方で(Julia の)Functor は、実体はただの『ある型のインスタンス』であり、その型のメンバ変数は(Julia の struct には private メンバという概念・仕様はないので)普通にアクセスできてしまいます。つまり厳密なカプセル化は実現不可能です。
ただその分、単純な変数アクセスやメンバ参照しかないため、余分なオーバーヘッドも少ないし最適化もされやすい、というわけです。
なのでもし、「別に内部状態を知られても(あまつさえ外部から更新されても)問題ない」ような案件で、Closure を使いたい場面に出会ったら、新しい型を定義して Functor を利用するようにすると、幸せになれるかもしれません。
まとめ
- Closure は、シンプルに書くとパフォーマンスが決して良くない。
- 型アノテーションやローカル変数を有効利用すると、Closure でもけっこうパフォーマンス改善が期待できる。
- 記述量が少し増えるだけ。
- Closure と同じ機能を持つ Functor は、Closure よりはるかに高いパフォーマンスが期待できる。
- どうしても内部状態をカプセル化したい(絶対に見られたくない or 変更されたくない)場合は、Functor では無理なので Closure でがんばる。
- あとついでに、パフォーマンスが気になったら
@code_warntypeすると良いよ。
参考
- 実験コード(Jupyter notebook):
- ClosurePerformance.ipynb(nbviewer)(for v0.6.x or later)
- ClosurePerformance_v05.ipynb(nbviewer)(for v0.5.x)
- Wikipedia: クロージャ
- Function-like objects (Julia 公式マニュアル 内)
-
この記事で紹介しているコードは v0.6.x 以降用ですが、考え方は v0.5.x 以前でも全く同様ですし、コードも少しの手直しで v0.5.x で動作します(参考リンク参照)。 ↩
-
というか正直に告白すると、 @SatoshiTerasaki さんの記事 Xorshift のJuliaでの実装 (32ビット版だけ) を見て色々弄っていてこの記事を書くことを思いついた、というのが本当のところですm(_ _)m ↩
-
このコード中の
⊻は、Julia の xor 演算子(v0.6 以降用)。v0.5.x 以前は$が使用されていましたが、v0.6 で deprecated になり、v0.7 以降では使用できなくなる予定です。 ↩ -
参考リンクに、実際に実行してみた実験コードの Jupyter notebook をおいてあります。nbviewer で見てみると、警告色等もきちんと再現されるので、ぜひ見てみてください。 ↩
-
v0.5 までは
typeキーワードで変更可能な型を定義していました。これは v0.6 でも Warning は出ませんが、v0.7 では deprecated になり、将来バージョンではtypeキーワードは使用できなくなる予定です。 ↩ -
Python ならば
__call__()特殊メソッドの定義がこれにあたります。他の言語では、例えば Scala ならapply()メソッドを定義すれば同様のことができます。 ↩ -
この記事では、圏論における Functor(関手)は扱いません。 ↩
-
Julia 公式ドキュメントでは正確には「Function-like object」と言っており、カッコ書きで「(このような『呼び出し可能な』オブジェクトはしばしば『functor』と呼ばれます)」と言及しているだけだったりします。 ↩