TL;DR
- 対応したこと:Unicode U+32FF(
'㋿')の正式な扱い- utf8proc をハックして自分でビルド
- ↑ をリンクするように Julia を自分でビルド
- 対応してないこと:和暦西暦変換
【2019/05/16 追記】
昨日、Julia の Unicode12.1 対応(utf8proc v2.4 使用)のプルリクエストが master にマージされました。
https://github.com/JuliaLang/julia/pull/32002
これ以降 Julia の最新開発版は令和対応済みとなります(はずです)。のでこの記事の内容は「旧バージョンで令和対応するには」という感じに読み替えてお楽しみください![]()
【追記ここまで】
環境等
Julia の Unicode 対応
Julia の文字列は、もちろん Unicode に対応しています。
ただし、Julia1.1 でサポートしているのは Unicode 11.0.0、Julia1.2-pre 以降は(今のところ)Unicode 12.0.0 です。
一方で、新しい元号を表す合字として '㋿' (U+32FF SQUARE ERA NAME REIWA) が追加されたのは、Unicode 12.1.0 からです。
前回の記事 では、Unicode 12.1.0 で追加された仕様を元にそれをエミュレートする ReiwaString 型を作って遊びました。
今回は、Julia のコアな部分を弄って正式に文字列として U+32FF を扱えるようにしたいと思います。
utf8proc
Julia の Unicode 処理は、外部ライブラリ utf8proc に依っています。
詳細は割愛しますが、これは文字通り「UTF8 の処理をするライブラリ」です。
現在リリースされている最新の utf8proc が Unicode 12.0.0 までにしか対応していないため、現行の Julia は Unicode 12.1.0 に対応できない、という仕組みになっているわけです。
なので、Julia を Unicode 12.1.0 に対応させるためには、utf8proc をハックして Unicode 12.1.0 に対応させ、それを組み込んだ Julia をビルドする必要があります5。
utf8proc ハッキング
【2019/05/11 追記】
私の送ったプルリクエストがマージされました♪
この節の内容は「ソース取ってくる」「ビルドする」「システムにインストールする」だけでOKになりました。
【追記ここまで】
utf8proc をハックしてビルドしてシステムに組み込みます。
以下、Ubuntu/macOS ほぼ共通です。
ソース準備・確認
まずは、適当な場所に git clone します。
ビルド出来るかどうか、テストが通るかどうか確認しておきましょう。
$ git clone https://github.com/JuliaStrings/utf8proc.git
$ cd utf8proc
$ make
# 《わりと一瞬で終わります》
$ make check
# 《中略》
test/normtest data/NormalizationTest.txt
line 42: Part0 # Specific cases
line 70: Part1 # Character by character test
checking line 1000...
checking line 2000...
checking line 3000...
checking line 4000...
checking line 5000...
checking line 6000...
checking line 7000...
checking line 8000...
checking line 9000...
checking line 10000...
checking line 11000...
checking line 12000...
checking line 13000...
checking line 14000...
checking line 15000...
checking line 16000...
line 16969: Part2 # Canonical Order Test
checking line 17000...
checking line 18000...
line 18696: Part3 # PRI #29 Test
Passed tests after 18874 lines!
test/graphemetest data/GraphemeBreakTest.txt
checking line 100...
checking line 200...
checking line 300...
checking line 400...
checking line 500...
checking line 600...
Passed tests after 630 lines!
test/charwidth
Mismatches with system wcwidth (not necessarily errors):
... (positive widths for 135297 chars unknown to wcwidth) ...
Character-width tests SUCCEEDED.
test/misc
NFC "ṛ̇" -> "ṛ̇" vs. "ṛ̇"
NFD "ṛ̇" -> "ṛ̇" vs. "ṛ̇"
NFKC_Casefold "XÈᴬ" -> "xèa" vs. "xèa"
NFKC_Casefold "XÈᴬ" -> "xèa" vs. "xèa"
Unicode version: Makefile has 12.0.0, has API 12.0.0
Misc tests SUCCEEDED.
test/valid
Validity tests SUCCEEDED.
test/iterate
utf8proc_iterate tests SUCCEEDED, (673) tests passed.
test/case
More up-to-date than OS unicode tables for 2746 tests.
utf8proc case conversion tests SUCCEEDED.
test/custom
mapped "AaSba" -> "abssba"
map_custom tests SUCCEEDED.
$
最後に map_custom tests SUCCEEDED. と表示されればOK。
修正
【2019/05/11 追記】
2019/05/11 10:12(JST) 以降は、以下に相当する修正が既に施されているので、この節の内容の作業は不要です。
【追記ここまで】
以降はプルリク適用前の古い情報です。
ソース、というか以下のファイルをそれぞれ以下のように修正します。
utf8proc.c
103-105行目 あたりを以下のように修正:
UTF8PROC_DLLEXPORT const char *utf8proc_unicode_version(void) {
return "12.0.0";
}
↓
UTF8PROC_DLLEXPORT const char *utf8proc_unicode_version(void) {
return "12.1.0";
}
バージョン番号を変えているだけ。簡単ですね!
data/Makefile
2箇所修正します。
まずは 24-25行目:
# Unicode data version (must also update utf8proc_unicode_version function)
UNICODE_VERSION=12.0.0
↓
# Unicode data version (must also update utf8proc_unicode_version function)
UNICODE_VERSION=12.1.0
これもバージョン番号を変えているだけ。
続いて 51-52行目:
emoji-data.txt:
$(CURL) $(CURLFLAGS) -o $@ -O $(URLCACHE)http://unicode.org/Public/emoji/`echo $(UNICODE_VERSION) | cut -d. -f1-2`/emoji-data.txt
↓
emoji-data.txt:
$(CURL) $(CURLFLAGS) -o $@ -O $(URLCACHE)http://unicode.org/Public/emoji/`echo $(UNICODE_VERSION) | cut -d. -f1`.0/emoji-data.txt
emoji-data.txt のダウンロード元を調整しています。
〜/`echo $(UNICODE_VERSION) | cut -d. -f1-2`/emoji-data.txt が展開されると、UNICODE_VERSION=12.1.0 の場合 〜/12.1/emoji-data.txt となるのですが、Unicode 12.0.0 と 12.1.0 とで emoji に変更がないためか、もしくは単純に 12.1/ ディレクトリを用意し忘れているのか、とにかく存在しないURLとなってしまい正しいファイルがダウンロードできません6。
そこで 〜/12.0/emoji-data.txt を参照するように修正。これ取り敢えず今回のためだけにハードコーディング(=〜/12.0/emoji-data.txt と記述)しちゃっても良かったんですけれどね。
【2019/05/10 追記】
Emoji の方の仕様書が別にあったので見てみました。→ Unicode Emoji
UnicodeのバージョンとEmojiのバージョンは「(メジャーバージョンレベルでは)同期」している模様ですが、仕様書によると「Unicodeのメジャーバージョン間にEmojiの中間バージョンリリースはあるかもしれない」的な記述がありました。
今回はその逆転現象が起きたのでしょう、つまりUnicodeのマイナーバージョンアップ(=UTF+32FF 対応)は入ったけれどEmojiには影響ないのでそちらのバージョンは上がらない、と。
なのでUNICODE_VERSIONとUNICODE_EMOJI_VERSIONを別管理する(同期するとしてもメジャーバージョンのみにする)のが正解だと思われます。
とりあえずUNICODE_VERSIONとUNICODE_EMOJI_VERSIONを分けた形で編集してプルリク送ってみた。→ update for unicode 12.1 by antimon2 · Pull Request #156 · JuliaStrings/utf8proc
【追記ここまで】
【2019/05/11 追記】
マージされました♪
【追記ここまで】
ちなみにこの時点で(事前にビルドしておいた状態で)make check すると…↓
$ make check
# 《中略》
test/normtest data/NormalizationTest.txt
line 42: Part0 # Specific cases
line 70: Part1 # Character by character test
checking line 1000...
checking line 2000...
line 2152: normalization failed for ㋿ -> 令和
make: *** [check] Error 1
$
きちんと『'㋿' (U+32ff)』の処理でエラーが出ます。分かりやすいですね!
utf8proc_data.c 更新
【2019/05/11 追記】
2019/05/11 10:12(JST) 以降は、以下に相当する修正が既に施されているので、この節の内容の作業は不要です。
【追記ここまで】
以降はプルリク適用前の古い情報です。
次が肝。utf8proc_data.c を更新(再生成して既存のものと置き換え)が必要です。
↓以下のようにします。
$ make clean # 念のため
$ make update
# 《中略》
/path/to/make -C data utf8proc_data.c.new
curl --retry 5 --location -o UnicodeData.txt -O http://www.unicode.org/Public/12.1.0/ucd/UnicodeData.txt
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 1755k 100 1755k 0 0 697k 0 0:00:02 0:00:02 --:--:-- 697k
# 《中略》
100 171k 100 171k 0 0 111k 0 0:00:01 0:00:01 --:--:-- 111k
julia charwidths.jl > CharWidths.txt
curl --retry 5 --location -o emoji-data.txt -O http://unicode.org/Public/emoji/`echo 12.1.0 | cut -d. -f1`.0/emoji-data.txt
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 63812 100 63812 0 0 54615 0 0:00:01 0:00:01 --:--:-- 54633
ruby data_generator.rb < UnicodeData.txt > utf8proc_data.c.new
cp -f data/utf8proc_data.c.new utf8proc_data.c
つまり www.unicode.org に用意されている各種ファイルから、CharWidths.txt や utf8proc_data.c.new ファイルを生成し、最後に utf8proc_data.c.new を utf8proc_data.c として上書きコピーしている、というわけ。
ちなみに utf8proc_data.c ファイルの中身は、適度に符号化されていて直接弄ろうと思ってもどこをどう修正すればどう挙動が変わるのかさっぱり分かりません💦
あと ruby data_generator.rb の実行は多少時間かかります。
参考:ダウンロードされる各種 〜.txt ファイルについて
先ほど編集した data/Makefile ファイルを見ると、www.unicode.org からダウンロードされる各 〜.txt の種類が分かります。
軽く調べたところ、これらのうち Unicode 12.1.0 で 12.0.0 から修正されている箇所はほとんどなく、大まかには以下の2ファイルのみです:
32FF;SQUARE ERA NAME REIWA;So;0;L;<square> 4EE4 548C;;;;N;;;;;
32FF;32FF;32FF;4EE4 548C;4EE4 548C; # (㋿; ㋿; ㋿; 令和; 令和; ) SQUARE ERA NAME REIWA
まぁ文字通り、Unicode 12.1.0 で追加されたのは、1つの文字 U+32FFと、その正規化仕様(U+32FF を :NFKC または :NFKD で "令和" の2文字に正規化)だけであり、上の2つはまさにそれを表しているわけですね。
ビルド
再び make / make check します。エラーなく正常終了すればOK。
インストール
以下を実行します(Linux の場合の実行結果も示しておきます):
$ sudo make install
sed \
-e 's#PREFIX#/usr/local#' \
-e 's#LIBDIR#lib#' \
-e 's#INCLUDEDIR#include#' \
-e 's#VERSION#2.2.0#' \
libutf8proc.pc.in > libutf8proc.pc
mkdir -m 755 -p /usr/local/include
install -m 644 utf8proc.h /usr/local/include
mkdir -m 755 -p /usr/local/lib
install -m 644 libutf8proc.a /usr/local/lib
install -m 755 libutf8proc.so.2.2.0 /usr/local/lib
mkdir -m 755 -p /usr/local/lib/pkgconfig
install -m 644 libutf8proc.pc /usr/local/lib/pkgconfig/libutf8proc.pc
ln -f -s libutf8proc.so.2.2.0 /usr/local/lib/libutf8proc.so
ln -f -s libutf8proc.so.2.2.0 /usr/local/lib/libutf8proc.so.2
$ sudo /sbin/ldconfig
$ /sbin/ldconfig -p | grep utf8proc
libutf8proc.so.2 (libc6,x86-64) => /usr/local/lib/libutf8proc.so.2
libutf8proc.so (libc6,x86-64) => /usr/local/lib/libutf8proc.so
/usr/local 以下に適切にインストールされます。
sudo /sbin/ldconfig を忘れずに。これを一度実行しておかないと Julia ビルド時に -lutf8proc で libutf8proc.a を見つけられずにエラーで落ちます。
ただしこれは Linux の場合だけで、macOS ではそれなしでも大丈夫なようです(というより ldconfig コマンドが存在しません)。
Julia ビルド
続いて Julia を自分でビルドします。
あらかじめ公式の build.md を読んでおきましょう。
特に Required Build Tools and External Libraries は重要。ビルドしてみて「〜が足りない」のようなエラーが出た場合は、ここを見てビルド要件を満たしているか確認してください。
julia リポジトリの clone と checkout
適当な場所に git clone して適当なブランチを checkout します。
最新開発版で良ければそのままmasterで作業しても良いでしょう。
ここでは、試しに Julia v1.2.0-pre.0 をビルド対象にしてみます↓
$ git clone https://github.com/JuliaLang/julia.git
$ cd julia
$ git checkout release-1.2
この時点で一度 make -j4 等7を実行してビルドしてみると、「自分の環境でビルド出来るかどうか」「ビルドにどれくらい時間がかかるか」が分かると思います。足りないものがあれば比較的すぐにエラーになるので分かりますが、不足がない場合、Julia のビルドにはそれなりの時間がかかるので注意が必要です。
Make.inc の編集
(正式に)ビルドする前に、Make.inc ファイルを編集する必要があります。
今回編集するのは、以下の1行だけ(47行目辺り)です:
USE_SYSTEM_UTF8PROC:=0
↓
USE_SYSTEM_UTF8PROC:=1
早い話、「utf8procをビルド」する代わりに「すでにシステムにインストールされているutf8procを利用」するように変更、と言う指定です。
同様にその行の周辺に、USE_SYSTEM_XXX とか USE_XXX というオプションがいくつかあります。utf8proc 以外でも「これ自分の環境にすでに最新の最適化されたものがインストールされている」という自信があれば、〜=1 に変更することでビルドが少し早くなったりより最適化された Julia がビルドされたりするかもしれません8。
ビルド
ビルドしてみましょう。環境によってはかなり時間がかかる7ので、珈琲を淹れるなりシャワーを浴びるなりして時間を潰してもOKです。
以下の出力はubuntuの場合の出力例です。macOSの場合出力内容が多少異なりますが大体同じです。
$ make -j4
《中略》
Sysimage built. Summary:
Total ─────── 202.280146 seconds
Base: ─────── 70.359755 seconds 34.7833%
Stdlibs: ──── 131.916346 seconds 65.2147%
JULIA usr/lib/julia/sys-o.a
Generating precompile statements... 906 generated in 179.807820 seconds (overhead 123.786504 seconds)
LINK usr/lib/julia/sys.so
$
最後に LINK usr/lib/julia/sys.so(macOSなら LINK usr/lib/julia/sys.dylib およびその後に追加で数行)表示されてプロンプトに戻ってくればビルド完了です。
動作確認
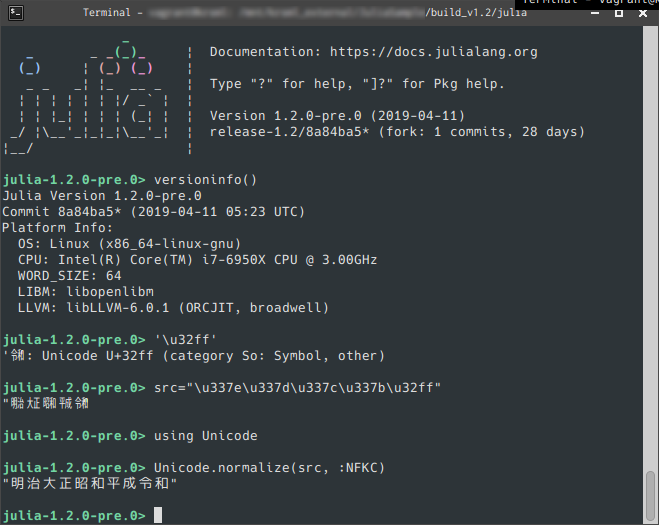
ビルドするとカレントディレクトリに julia コマンドが出来ます(正確には ./usr/bin/julia に本体があってそこへのシンボリックリンクになっています)。これを実行して、'㋿' (U+32FF SQUARE ERA NAME REIWA) がきちんと扱えるか確認してみましょう。
$ ./julia
_
_ _ _(_)_ | Documentation: https://docs.julialang.org
(_) | (_) (_) |
_ _ _| |_ __ _ | Type "?" for help, "]?" for Pkg help.
| | | | | | |/ _` | |
| | |_| | | | (_| | | Version 1.2.0-pre.0 (2019-04-11)
_/ |\__'_|_|_|\__'_| | release-1.2/8a84ba5018* (fork: 1 commits, 27 days)
|__/ |
julia> versioninfo()
Julia Version 1.2.0-pre.0
Commit 8a84ba5018* (2019-04-11 05:23 UTC)
Platform Info:
《略》
julia> '\u32ff'
'㋿': Unicode U+32ff (category So: Symbol, other)
julia> src="\u337e\u337d\u337c\u337b\u32ff"
"㍾㍽㍼㍻㋿"
julia> using Unicode
julia> Unicode.normalize(src, :NFKC)
"明治大正昭和平成令和"
julia>
実行例(ubuntu 16.04):
実行例(macOS High Sierra):
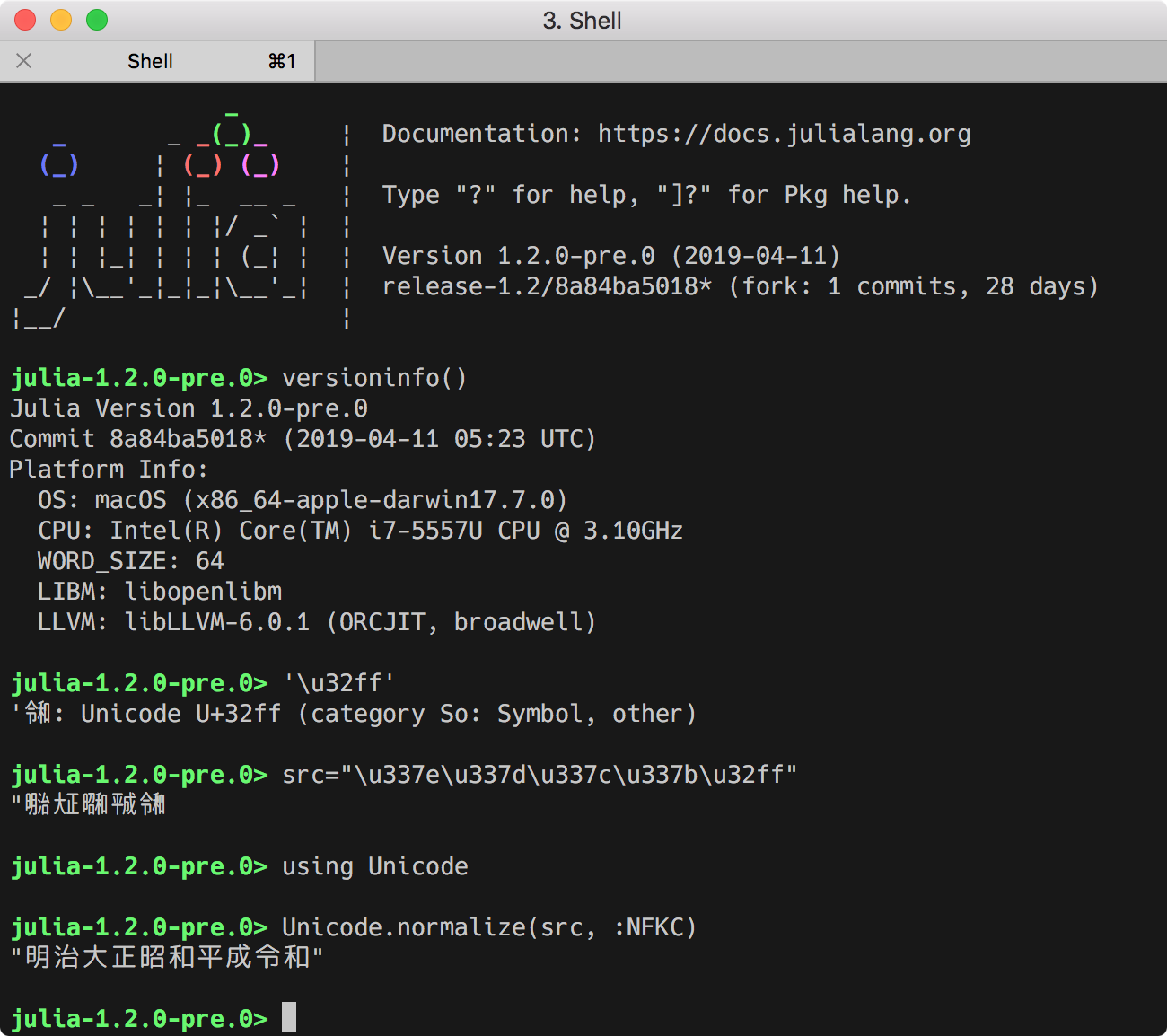
きちんと '\u32ff' が '㋿' と表示され、Unicode.normalize() で "令和" に変換されました!
(任意)ビルドした julia のインストール
ビルドした一連の関連ファイルは、全て ./usr ディレクトリ配下に収まっています。
これを適当なディレクトリにコピー(または移動)して、その中の bin/julia コマンドを実行するか、そこにパスが通るようにすれば、取り敢えず使うことは出来ます。
公式の build.md - Building Julia には、「どこからでも Julia を実行できるようにするには:」として5つの方法が紹介されています。参考にしてください。
私は複数バージョンをインストールして使い分けているので、以下のような対応をしています:
- ホームディレクトリ配下に適当な名前で移動する(例:
mv usr ~/julia-1.2.0-p0+Unicode.12.1.0) - ~/bin 内にシンボリックリンクを張る(例:
cd ~/bin && ln -s $HOME/julia-1.2.0-p0+Unicode.12.1.0/bin/julia julia12p0r)
これで($HOME/bin にパスが通っていること前提ですが)julia12p0r で今回ビルドした Unicode12.1.0対応の Julia v1.2.0-pre.0 がいつでもどこでも実行できます9。
お疲れさまでした!
フォントについて(再)
この記事(の画面キャプチャ画像)を見て「あれ?合字の『令和』の部分が文字化けしていない!?」と思った方。
OSが正式に対応していなくても、フォントと表示環境が対応していれば、このようにきちんと表示されます。つまりこれらの動作確認環境には然るべきフォントをインストール済です。
2019年5月上旬時点で '㋿' (U+32FF SQUARE ERA NAME REIWA) に対応しているフォントをいくつか挙げます:
- Source Han Sans(源ノ角ゴシック) ≥ v2.001
- Cica ≥ v4.2.1
- 小塚ゴシック / 小塚明朝
- IPAex フォント ≥ v004.01
これらのフォントをインストールし適切に設定すれば、'㋿'←この文字はきちんと表示できます。
参考
- Unicode 12.1.0
- JuliaLang/julia: The Julia Language: A fresh approach to technical computing.(GitHub 内)
-
JuliaStrings/utf8proc: a clean C library for processing UTF-8 Unicode data(GitHub 内)
- utf8proc(ドキュメント)
-
手っ取り早く確認したのがこの2つと言うだけで、他の Linux ディストリビューションおよび macOS ならたぶん同様だと思います。Windowsでは確認していませんが、CMake を利用するかCygwinを利用すればたぶん同じようにビルド出来ると思います。 ↩ ↩2
-
標準の gcc5系じゃビルド出来なくて、gcc7系をインストールして
update-alternative等で切り替えてビルドする必要があります。詳細は省略します(ググってみてください ) ↩
) ↩ -
utf8proc のビルド(正確にはソースファイルの生成)に Julia が必要です。「Julia のビルドに Julia が必要なの?」と思うかもしれませんが、ソースファイルの再生成が必要なければ使用されることはないので大丈夫です。 ↩ ↩2
-
utf8proc のビルド(正確にはソースファイルの生成)に Ruby が必要です。Linuxの方に入っていなかったので rbenv で入れました。たぶん apt で入れても良かった。 ↩ ↩2
-
調べ切れていないので、もしかしたら Julia をビルドせずに utf8proc を組込直す方法があるかもしれません、がその場合動的ライブラリ(DLL、linux系なら .so ファイル)を利用することになるのでおそらくパフォーマンス面でディスアドバンテージになるのではないかと思います(いろいろ未確認)。 ↩
-
これでけっこうハマって時間取られました。ファイルが存在しなくても
404 not foundを示すHTMLデータがテキストファイルとしてダウンロードできてしまいエラーにならないので(困る)。 ↩ -
-j4オプションはお使いの環境に合わせてください。ちなみに手元のmacOSでは、-j4付けたら出たエラーがオプションなくしたら出なくなりました(謎)(あとその分時間がかかった)。 ↩ ↩2 -
私は全てのオプションについて動作確認したわけではないので、自己責任でお願いします。 ↩
-
ちなみに単に
juliaとだけ打つと Julia v1.0.3 が、julia11で v1.1.0 が実行されるようにしてあります。マイクロバージョンが上がったら(=パッチリリースが出る度に)手作業でリンク張り直しています💦 ↩