はじめに
Power Automate の開発において、例えば Dataverse から取得したレコード(行)を扱うとき、このレコードが1件しかなくても「アクション:それぞれに適用する(Apply to each)」が自動生成されてしまいます。そこで、この記事では自動生成されるループを回避する方法を紹介します。
ループが自動生成される例
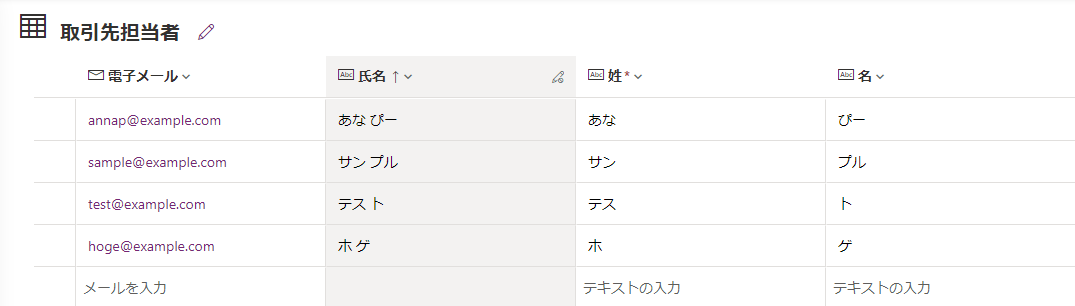
取引先担当者テーブルから、「アクション:行を一覧にする」を用いてユニークなパラメータ「電子メール」でクエリしたデータを取得します。
取引先担当者テーブル:
フロー:
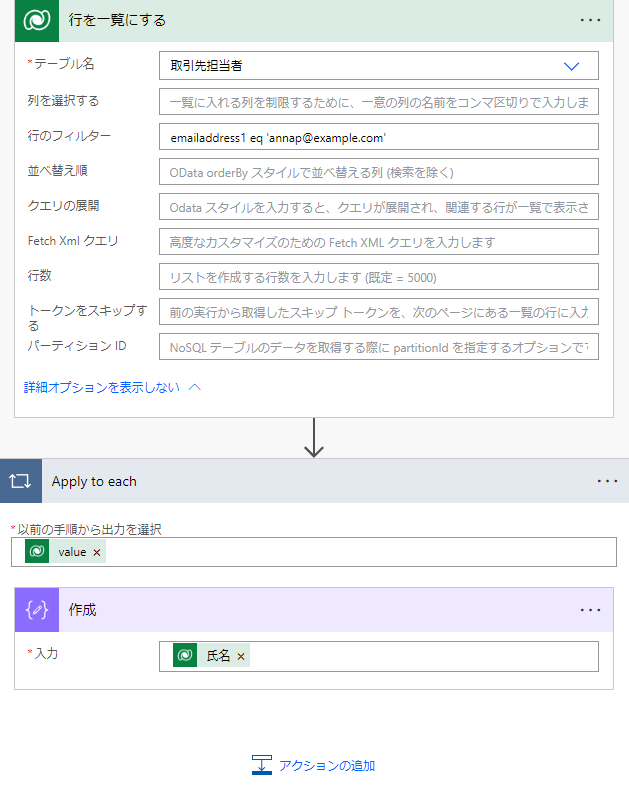
このアクションで取得されるレコードは1件のはずですが、「アクション:作成」に取引先担当者の「氏名」を入力すると、自動で「Apply to each」が生成されてしまいました。
たくさんのレコードを対象に処理する場合には必要なループですが、明らかに1件とわかっている場合には不要です。なにより取得したレコードの値を使用するたびに「Apply to each」が生成されてしまうと、フローが長くなるのはもちろん、可読性の低下にもつながります。
自動生成されるループを回避する方法
① 関数:first を使用する
first(outputs('行を一覧にする')?['body/value'])['fullname']
対象の配列から最初の要素を取り出し、フィールドキー(論理式)を指定することで値を取得します。
② 配列のインデックスを0に指定する
outputs('行を一覧にする')?['body/value'][0]['fullname']
対象の配列から0番目(最初)の要素を取り出し、フィールドキー(論理式)を指定することで値を取得します。
'行を一覧にする'は Dataverse からレコードを取得するアクションの名前、['fullname']は取り出したいフィールドの論理式なので、それぞれ自分のフローにあわせて変更してください。
おまけ:実行時間の違い
例に挙げたフローについて、「Apply to each」を使用した場合とそうでない場合の実行時間を5回平均で比較しました。この結果から、「Apply to each」を使用すると、そうでない場合と比較して実行時間が2倍以上長くなっていることがわかります。
| 1 | 2 | 3 | 4 | 5 | 平均時間(秒) | |
|---|---|---|---|---|---|---|
| Apply to each | 1 | 0.977 | 0.881 | 0.844 | 0.705 | 0.890 |
| first関数 | 0.222 | 0.570 | 0.242 | 0.291 | 0.386 | 0.342 |
| インデックス | 0.513 | 0.783 | 0.370 | 0.253 | 0.264 | 0.437 |
おわりに
今回は自動生成される「Apply to each」を回避する方法について紹介しました。フローの可読性や(おまけ程度ですが)実行時間のから観点も、取得するデータが明らかに1件である場合は、不要な「Appy to each」を避けたほうがいいです。