Ruby Kaigi 2023に参加することになった
だけど、自分は処理系のことなんて全く知りません。
だからちょっとだけ予習してゆくことにしました。
参考
Rubyのしくみ -Ruby Under a Microscope- (出版社ページがないのでAmazonリンク)
まず、Rubyを実行するには
Rubyがインストールされている環境において、Rubyファイルを実行するには、
# test.rb
# 先の説明の便のために整数を文字列化する変なことをしている
puts 1234.to_s
例えばこのようにファイルを用意して
$ ruby test.rb
rubyコマンドの第一引数にファイル名を指定して実行するだけです。
ちなみに、Javaを実行するには
Javaファイルを実行するには、
// Test.java
public class Test {
public static void main(String[] args) {
System.out.println(String.valueOf(1234));
}
}
例えばこのようにファイルを用意して
javac Test.java
javacコマンドにファイル名を指定してコンパイルを行い
java Test
javaコマンドにクラス名を指定して実行します。
インタプリタ型?コンパイル型?
Rubyは実行者がコンパイルを行わずに実行できるのに対して、Javaは実行者がコンパイルを行います。
このことから、Rubyはインタプリタ型、Javaはコンパイル型と区分されることがあります。
しかし、Rubyでコンパイルがされていないわけではないです。それは実行時に内部で行われています。
Rubyのコンパイルの流れ
Rubyは実行までにコードを何回読んでいるかと言うと、なんと3回らしいです。
3度形を変えて行って、やっと実行できる姿になります。
最近のRubyではJITコンパイルが加わって4回になったようですが、参考にしている『Rubyのしくみ』は古い本でサポートしていないので、今回は対象外にします。
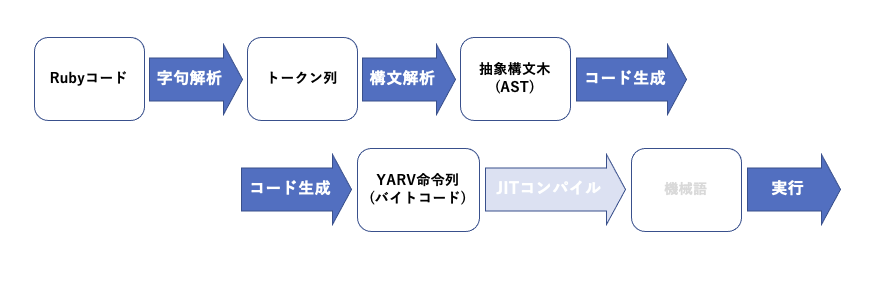
定義によっては、「字句解析」「構文解析」「コード生成」をまとめて『コンパイル』と呼ぶこともあれば、「コード生成」だけを『コンパイル』と呼ぶこともあるようです。
以下にそれぞれの過程を経た後どのような姿になっているかを掲載しておきます。
●Rubyコード
puts 1234.to_s
●トークン列
[[[1, 0], :on_ident, "puts", CMDARG],
[[1, 4], :on_sp, " ", CMDARG],
[[1, 5], :on_int, "1234", END],
[[1, 9], :on_period, ".", DOT],
[[1, 10], :on_ident, "to_s", ARG],
[[1, 14], :on_nl, "\n", BEG]]
●抽象構文木(AST)
[:program,
[[:command,
[:@ident, "puts", [1, 0]],
[:args_add_block,
[[:call,
[:@int, "1234", [1, 5]],
[:@period, ".", [1, 9]],
[:@ident, "to_s", [1, 10]]]],
false]]]]
●YARV命令列
== disasm: #<ISeq:<compiled>@<compiled>:1 (1,0)-(1,14)> (catch: FALSE)
0000 putself ( 1)[Li]
0001 putobject 1234
0003 opt_send_without_block <calldata!mid:to_s, argc:0, ARGS_SIMPLE>
0005 opt_send_without_block <calldata!mid:puts, argc:1, FCALL|ARGS_SIMPLE>
0007 leave
このような変化を経て、実行に至ります。
字句解析
ここで行われていることは「単語に分ける」ことです。
[[[1, 0], :on_ident, "puts", CMDARG],
[[1, 4], :on_sp, " ", CMDARG],
[[1, 5], :on_int, "1234", END],
[[1, 9], :on_period, ".", DOT],
[[1, 10], :on_ident, "to_s", ARG],
[[1, 14], :on_nl, "\n", BEG]]
これをよく見ればわかりますが、配列ごとに "puts"、 " "(半角スペース)、 "1234"etc...と元々のコードが単語単位で切り刻まれています。
最初の要素の[1, 0]等はファイルにおける行列の位置を示しています。
次の :on_ident等はその単語のカテゴリを示している。"puts"と"to_s"は同じ :on_identになっている。:no_spのspはスペースだろうか。
最後の要素はちょっとよくわかりません。
ここで作られたものをトークン列と言いいます。
コードからトークン列を作り出す時は基本的には愚直に前から一文字一文字順に読んでゆき、単語の終わりだと判断できるところまできたら、次の文字からは次の単語になる、ただそれだけです。しかし、前からただ読んだだけでは、単語の終わるであると判断できない場合もあります。例えば、1 → 2 → 3 → 4と辿ってきて次に"."があるわけですが、これはレシーバとメソッドを繋ぐドットである可能性と、Floatの小数点である可能性の両方があります。これがわかるのはto_sのtまで見た時で、ここまで読んで初めてこの"."がレシーバとメソッドを繋ぐドットであると判断できます。
基本的には前から読まれますが、このように多少行ったり来たりを繰り返して、字句解析はなされます。
ちなみに、字句解析にはLexというツールがどの言語でも使われるようですが、Rubyでは自作されています。これについてMatzは『Rubyを作ったあの頃、私は若かった。』と述べています。
Rubyにおいては構文解析を行うパーサの中に。字句解析を行う機能も含めているようです。
構文解析
ここで行われていることは、「文法に沿って解釈する」ことです。
[:program,
[[:command,
[:@ident, "puts", [1, 0]],
[:args_add_block,
[[:call,
[:@int, "1234", [1, 5]],
[:@period, ".", [1, 9]],
[:@ident, "to_s", [1, 10]]]],
false]]]]
字句解析によってできたトークン列は平坦な配列でしたが、構文解析は違います。単語を文法的に解釈して、構文木と言われる木構造を作ります。
凄まじく大きなparse.yファイルに書かれている文法に沿って、木構造に仕立て上げられてゆきます。
ちなみに、字句解析の段階では例えコードに文法間違いが含まれていたとしても、トークン列に無理やり変換されて、シンタックスエラーは起こらないです。この構文解析の段階になって初めてシンタックスエラーが検出できるようになります。
構文解析を行うのは一般的にパーサというツールで、Rubyで使われているのはLALRパーサです。
コード生成
Cなどの言語の場合は、コンパイラによってコンピュータのCPUが直接理解できる機械語に翻訳されます。
一方JavaやRubyの場合は、仮想マシンが理解できるバイトコードに翻訳されます。ちなみにRubyにおける仮想マシンはYet Another Ruby Virtual Machine(YARV)といいます。
実はこのコード生成はRuby1.8の頃はなかったようで、パフォーマンス改善の目的でRuby1.9から導入されました。
これまた非常に大きなcompile.cファイルにしたがって生成されます。
最後に
理解したことからもっと追記していこうと思っています。
上記の出力コード
require 'ripper'
require 'pp'
code = <<~CODE
puts 1234.to_s
CODE
out = PP.pp Ripper.lex(code), '', 40
puts out
puts '------------------------------------------------------------'
out = PP.pp Ripper.sexp(code), '', 40
puts out
puts '------------------------------------------------------------'
puts RubyVM::InstructionSequence.compile(code).disasm