2021/05/02 :最新のSudachiPy v0.5.2で動作するよう改修しました
ニホンゴ ムズカシイデース
執筆者の知識バックボーン
- 大学のとき(30年前)にBASIC製の人工無能プログラムを改造してパソコン通信のホスト局に組み込んだ程度の能力
- 自然言語処理は興味があったけど、学生当時はLispとSmalltalk全盛で、C言語も使えなかったので学んだことがない
- 今では中学校で習った日本語の文法もうろ覚え…
- 今回の開発でPythonを触り始めて1ヶ月ちょっと(他の言語経験は、C言語 6年、VC++ 2年、Java 1年、Perl 20年、PHP 3年、Node.js&AngularJS 2年、etc)
◆ 承前:賢狼様とお話ししたい!
そう、あれは約1ヶ月前、自分がクラマスやってるWorld of Warshipsのクラン用Discord鯖で、プログラミング素人だったメンバーが色々な機能のツールボットをPythonで作りはじめた。それを手伝っていたら私も対抗してDiscord用の対話ボットを作ろうと思ったんですよ(謎動機)
とりあえずDiscord.pyのAPIコールで動作するひな形を作り、Repl-AI(docomoAPI)の雑談会話や知識Q&Aなどの機能を利用してなんとなく会話できるボットをまずは作成。
で、ボットのアイコンに使っていた「狼と香辛料」のホロを眺めながら、
「折角だからホロの口調で会話させたい」
などと、思ってしまったのは賢狼様のお導きか?(白目)
とりあえず、原作でのホロの花魁っぽい口調を思い出しながら、口調を変換するための以下の様な単純なパターン定義ファイルを用意して、テキスト全体に検索と置換をかけてみた。
賢狼様は敬語なんて使わないもんね!
●暫定で適用した単純な口調変換テーブル例(json)
{
"私": "わっち",
"ですか?": "かや?",
"なさいますか?": "するのかや?",
"ですね": "じゃな",
"いですね": "いんじゃ",
"です": "じゃ",
"ですよね": "そうじゃな",
"いですよ。": "いんじゃ。",
"ですよ": "じゃよ",
"だよね。": "じゃな。",
"ですけど。": "じゃが。",
"どうした": "どうしたんじゃ",
"わかりませんでした": "わかりんせん",
"ますよね。": "るのぉ。",
"されて": "して",
"されますか?": "するかや?",
"まれますか?": "むかや?",
"まれるんですか?": "むのかや?",
"ますか?": "るかや?",
"しますか?": "すかや?",
"でしょうか?": "かや?",
"んですか?": "のかや?",
"ました?": "たかや?",
"何か": "なんぞ",
"ごよう": "用",
"お持ち": "持っている",
"でしょうね?": "じゃろ?",
"でしょう": "かや",
"ですかね": "かのぉ",
"ください": "くりゃれ",
"おられますか?": "いるかや?",
}
◆ 結果:こんなの賢狼じゃない!
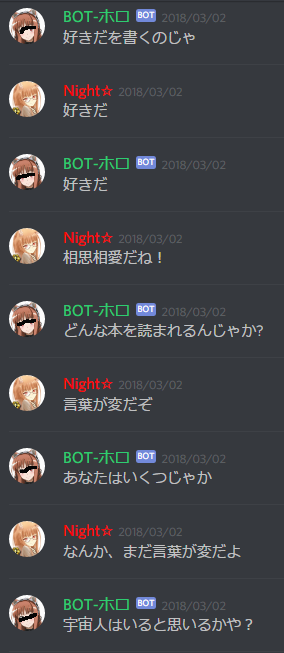
おうふ・・・ orz
活用形による語尾変化とかあるから、パターンにマッチしないか接続が変テコになるケースが多くて全然ホロっぽくない!(>_<) とはいえ、全部のパターンを用意するなんてかなり無理だよね(苦笑)
会話の口調を正しく変えるためには、まずは日本語を正しく理解する必要がある。
そこで、形態素解析器を組み込む必要があると思い、何を使うがいいのかをサーチ。
調べたら「Mecab」と「Janome」があったので、新しい方の「Janome」を使ってみることにしました。
「おお、テキストが用言単位に解析されて返ってくる! すげー!」
そして、テキストの形態素解析の結果に対して、用言単位で変換パターン定義ファイルと照合して変換するようにしてみました。
その結果は、、、
●Janome+NEologd辞書による形態素解析+口調パターン変換結果の例
- 形態素解析結果のIPA辞書形式の用言ごとの項目並びは以下の通り(\tはタブコード)
表層形\t品詞,品詞細分類1,品詞細分類2,品詞細分類3,活用型,活用形,原形,読み,発音 - 括弧内は期待する変換
talk: カルシウムが不足するとイライラするって、俗説だって知ってました?
------
→ カルシウム 名詞,一般,*,*,*,*,カルシウム,カルシウム,カルシューム
→ が 助詞,格助詞,一般,*,*,*,が,ガ,ガ
→ 不足 名詞,サ変接続,*,*,*,*,不足,フソク,フソク
→ する 動詞,自立,*,*,サ変・スル,基本形,する,スル,スル
→ と 助詞,接続助詞,*,*,*,*,と,ト,ト
→ イライラ 副詞,助詞類接続,*,*,*,*,イライラ,イライラ,イライラ
→ する 動詞,自立,*,*,サ変・スル,基本形,する,スル,スル
→ って 助詞,格助詞,連語,*,*,*,って,ッテ,ッテ
→ 、 記号,読点,*,*,*,*,、,、,、
→ 俗説 名詞,一般,*,*,*,*,俗説,ゾクセツ,ゾクセツ
→ だって 助詞,副助詞,*,*,*,*,だって,ダッテ,ダッテ
→ 知っ 動詞,自立,*,*,五段・ラ行,連用タ接続,知る,シッ,シッ
→ て 助詞,接続助詞,*,*,*,*,て,テ,テ
→ まし 助動詞,*,*,*,特殊・マス,連用形,ます,マシ,マシ
→ た 助動詞,*,*,*,特殊・タ,基本形,た,タ,タ
→ ? 記号,一般,*,*,*,*,?,?,?
------
Hit keyword: ました?
trans: カルシウムが不足するとイライラするって、俗説だって知ってたかや?
------
知ってました? → 知っ て[助詞] まし[助動詞] た[助動詞] ? → 知っ て た かや ?
talk: 性格が悪いです
------
→ 性格 名詞,一般,*,*,*,*,性格,セイカク,セイカク
→ が 助詞,格助詞,一般,*,*,*,が,ガ,ガ
→ 悪い 形容詞,自立,*,*,形容詞・アウオ段,基本形,悪い,ワルイ,ワルイ
→ です 助動詞,*,*,*,特殊・デス,基本形,です,デス,デス
------
Hit keyword: です
trans: 性格が悪いじゃ
------
(悪い です → 悪い[形容詞] です[助動詞] → 悪い んじゃ or のぉ)
talk: 警備会社に勤めてるんですね。警備会社に応募するのでしょうか?
------
→ 警備会社 名詞,固有名詞,一般,*,*,*,警備会社,ケイビガイシャ,ケイビガイシャ
→ に 助詞,格助詞,一般,*,*,*,に,ニ,ニ
→ 勤め 動詞,自立,*,*,一段,連用形,勤める,ツトメ,ツトメ
→ てる 動詞,非自立,*,*,一段,基本形,てる,テル,テル
→ ん 名詞,非自立,一般,*,*,*,ん,ン,ン
→ です 助動詞,*,*,*,特殊・デス,基本形,です,デス,デス
→ ね 助詞,終助詞,*,*,*,*,ね,ネ,ネ
→ 。 記号,句点,*,*,*,*,。,。,。
→ 警備会社 名詞,固有名詞,一般,*,*,*,警備会社,ケイビガイシャ,ケイビガイシャ
→ に 助詞,格助詞,一般,*,*,*,に,ニ,ニ
→ 応募 名詞,サ変接続,*,*,*,*,応募,オウボ,オーボ
→ する 動詞,自立,*,*,サ変・スル,基本形,する,スル,スル
→ の 名詞,非自立,一般,*,*,*,の,ノ,ノ
→ でしょ 助動詞,*,*,*,特殊・デス,未然形,です,デショ,デショ
→ う 助動詞,*,*,*,不変化型,基本形,う,ウ,ウ
→ か 助詞,副助詞/並立助詞/終助詞,*,*,*,*,か,カ,カ
→ ? 記号,一般,*,*,*,*,?,?,?
------
Hit keyword: でしょうか?
trans: 警備会社に勤めてるんですね。警備会社に応募するのかや?
------
(勤め てる ん です ね → 勤め てる ん[名詞] です[助動詞] ね[終助詞] → 勤め てる ん じゃな)
する の でしょ う か ? → する の[名詞] でしょ[助動詞] う[助動詞] か[終助詞] ? → する の かや ?
talk: どんな音楽をききますか?
------
→ どんな 連体詞,*,*,*,*,*,どんな,ドンナ,ドンナ
→ 音楽 名詞,一般,*,*,*,*,音楽,オンガク,オンガク
→ を 助詞,格助詞,一般,*,*,*,を,ヲ,ヲ
→ きき 動詞,自立,*,*,五段・カ行イ音便,連用形,きく,キキ,キキ
→ ます 助動詞,*,*,*,特殊・マス,基本形,ます,マス,マス
→ か 助詞,副助詞/並立助詞/終助詞,*,*,*,*,か,カ,カ
→ ? 記号,一般,*,*,*,*,?,*,*
------
(きき[五段・連用形] ます か ? → きく[五段・基本形] ます[助動詞] か[終助詞] ? → きく の かや ?)
talk: あなたはいくつですか
------
→ あなた 名詞,代名詞,一般,*,*,*,あなた,アナタ,アナタ
→ は 助詞,係助詞,*,*,*,*,は,ハ,ワ
→ いくつ 名詞,代名詞,一般,*,*,*,いくつ,イクツ,イクツ
→ です 助動詞,*,*,*,特殊・デス,基本形,です,デス,デス
→ か 助詞,副助詞/並立助詞/終助詞,*,*,*,*,か,カ,カ
------
Hit keyword: ですか
trans: あなたはいくつかや
------
(あなた は → あなた[名詞] は[助詞] → ぬし は)
いくつ です か → いくつ[名詞] です[助動詞] か[終助詞] → いくつ かや
talk: もう食事済みました?
------
→ もう 副詞,一般,*,*,*,*,もう,モウ,モー
→ 食事 名詞,サ変接続,*,*,*,*,食事,ショクジ,ショクジ
→ 済み 動詞,自立,*,*,五段・マ行,連用形,済む,スミ,スミ
→ まし 助動詞,*,*,*,特殊・マス,連用形,ます,マシ,マシ
→ た 助動詞,*,*,*,特殊・タ,基本形,た,タ,タ
→ ? 記号,一般,*,*,*,*,?,?,?
------
Hit keyword: ました?
trans: もう食事済みたかや?
(済み[五段・連用形] まし た → 済む[五段・基本形] まし[助動詞] た[助動詞] → 済ん[五段・連用形] だ[助動詞] かや)
うん、わかってた(白目)
これでは対応しきれないわぁ(´・ω・`)
● 単純変換でうまくいかなかった例と期待する変換例のピックアップ
とりあえず、失敗例をもとに「どうなるべきか」を考えました。
知ってました? → 知っ て[助詞] まし[助動詞] た[助動詞] ? → 知っ て た かや ?
悪い です → 悪い[形容詞] です[助動詞] → 悪い んじゃ(のぉ)
勤め てる ん です ね → 勤め てる ん[名詞] です[助動詞] ね[終助詞] → 勤め てる ん じゃな
する の でしょ う か → する の[名詞] でしょ[助動詞] う[助動詞] か[終助詞] → する の かや
きき[五段・連用形] ます か ? → きく[五段・基本形] ます[助動詞] か[終助詞] ? → きく の かや ?
あなた は → あなた[名詞] は[助詞] → ぬし は
いくつ です か → いくつ[名詞] です[助動詞] か[終助詞] → いくつ かや
済み[五段・連用形] まし た ? → 済む[五段・基本形] まし[助動詞] た[助動詞] ? → 済ん[五段・連用形] だ[助動詞] かや?
◆ 解決方法の考察
以下の手順で文字列パターンの単純変換と、用言単位での変換を処理すればいけそう。
- 全文から敬語を変換する
- 全文から敬語以外の用言をまたぐ特定文字列を変換する
- 1-2で変換したテキストを形態素解析して用言単位に分解する
- 用言リストの先頭からフェッチする(助動詞の場合は用言複数個先読みする場合がある)
- 用言の品詞種類ごとの変換テーブル(json)のキーと照合をかける
- マッチしたら必要に応じて後続の用言群をチェックし、変換が不要ならそのまま出力用文字列に追加し、変換が必要なら変換して書き換えた後続の用言個数分フェッチポインタを進め出力用文字列に追加する
- 次の用言の処理に移動する
変換すべきでない用言の変換が発生しないように文節の終端を考慮して処理する。
文節の終端(EOS)判定(判定優先度順)
- 行末(※用言リスト単位で処理する場合はリストの最後の項目)
- 助詞(接続助詞)
- 句読点・疑問符・感嘆符・その他の記号(「。」「、」「?」「!」など)
- 空白
上記3~4を判定する正規表現 : [。、,.?!?!\s]
具体的には、以下のルールとしました。
敬語の変換
・用言単位ではなくひとかたまりの文字列で変換。活用形を考慮する必要があるなら用言単位の変換処理にする。
- 「ご」「お」+名詞 はそのまま。
- 「お(ご)」+動詞・連用形+「する・になる」は、お+名詞(節)+する・になる と形態素解析され、基になる動詞を切り出せず活用変化不能のため、よく使う動詞の例を網羅し変換テーブルで一連の文字列を変換して対応する。
特定の文字列の変換
- 用言をまたいだ一連の文字列の変換は、変換処理の最初に実施し単純変換する。
名詞の変換
- 名詞の変換は、用言単位で単純変換。連続した用言をまとめて変換する場合は前述の特定文字列変換で対応する。
感動詞の変換
- 感動詞の変換は、用言単位で単純変換。連続した用言をまとめて変換する場合は前述の特定文字列変換で対応する。
形容詞の変換
- 形容詞の変換は、形容詞[基本形・終止形]+助動詞「です」の場合は、形容詞の直後に「ん」を補完する。
副詞・助詞の変換
- 副詞・助詞の変換は、用言単位で単純変換。
助動詞の主に敬語を表す「です」「ます」などの口調変換
- 基本的には省略(削除)する。
- 変換する助動詞の直前が名詞・形容詞の場合はそのまま変換する。※形容詞[基本形・終止形・連体形]+「です」の扱いは前述の通り。
- 変換する助動詞の直前が動詞の場合は活用形に応じた動詞の送り仮名変換をしたうえで変換する。
- Janomeには動詞の活用形を変換するAPIがないため自前で変換する(後述)。
- 助動詞に続く用言群のパターンの終端は、前述の文節終端あるいは接続助詞とする。
- 助動詞の直前が推定の助動詞「らしい」以外の助動詞の場合は変換しない。
- 助動詞「らしい」の後に断定の助動詞「です・だ」が続く場合は、「らしい」+「ん」+助動詞と補完する。
動詞で終わる場合の語尾変換
- (一段活用と五段活用・イ音便を除く)動詞(基本形・終止形)の次が文節終端の場合、連用形に変換し語尾に「んす」を追加する。
例:困る。 → 困りんす。 - (一段活用か五段活用・イ音便の)動詞(基本形・終止形)の次が文節終端の場合、基本形(終止形)を維持して語尾に「んじゃ」を追加する。
例:寝る。 → 寝るんじゃ。
動詞の活用送り仮名・後続の助動詞変換
-
Mecab辞書登録ツールを参考にして作ることにした。
→ 動詞活用変換モジュール"verb_conjugate.py"を作成。引数に動詞の直後の用言が必要なのは五段活用の送り仮名バリエーションを確定するため。 - 五段活用マ行+「まし」+「た~」 → 動詞語幹+「ん」+「だ~」
- 五段活用(連用形)+「ます」 → 動詞(連用形)+「んす」 ※但し、「五段活用・*音便」は除外
◆ 新変換テーブル案(json)
以上の仕様を洗い出し、以下のような変換テーブルのjsonファイル群を作成した。
敬語変換→特定文字列変換→形態素解析→名詞変換→感動詞変換→形容詞変換→副詞変換→助詞変換→助動詞変換の順に処理する。
- 敬語変換用テーブル(品詞不問・文字列単位)
{
"いらっしゃいます": "います",
"なさいますか": "しますか",
"なされますか": "しますか",
"なさいます": "する",
"なされます": "する",
"されますか": "しますか",
"おられます": "います",
"おっしゃら": "言わ",
"おっしゃり": "言い",
"おっしゃる": "言う",
"おっしゃれ": "言え",
"おっしゃろ": "言お",
"されます": "する",
"おられる": "いる",
"こちら": "こっち",
"あちら": "あっち",
"されて": "して",
"ご覧にな": "見",
"ご覧": "見て",
"お話しください": "話してくりゃれ",
"お話し下さい": "話してくりゃれ",
"お話しになる": "話す",
"お話しする": "話す",
"お話になる": "話す",
"お話する": "話す",
"お聞きください": "聞いてくりゃれ",
"お聞き下さい": "聞いてくりゃれ",
"お聞きになる": "聞く",
"お聞きする": "聞く",
"お読みください": "読んでくりゃれ",
"お読み下さい": "読んでくりゃれ",
"お読みになる": "読む",
"お読みする": "読む",
"お休みください": "休んでくりゃれ",
"お休み下さい": "休んでくりゃれ",
"お休みになる": "休む",
"お休みする": "休む",
"お越しください": "来てくりゃれ",
"お越し下さい": "来てくりゃれ",
"お越しになる": "来る",
"仰ら": "言わ",
"仰り": "言い",
"仰る": "言う",
"仰れ": "言え",
"仰ろ": "言お"
}
- 特定変換用テーブル(品詞不問・文字列単位)
{
"わかりませんでした": "わかりんせん",
"わかりません": "わかりんせん",
"ください": "くりゃれ",
"下さい": "くりゃれ"
"何か": "なんぞ",
"なにか": "なんぞ"
}
- 名詞(代名詞)変換用テーブル(用言単位)
{
"わたし": "わっち",
"あなた": "ぬし",
"貴方": "ぬし",
"私": "わっち",
}
- 感動詞変換用テーブル(用言単位)
{
"すいません": "すまぬな",
"すみません": "すまぬな",
"はい": "そうじゃ",
"いいえ": "いや"
}
- 形容詞変換用テーブル(用言単位)
{
}
- 形容詞後続補完用テーブル(用言単位)
"基本形": ["です", "ん"],
"終止形": ["です", "ん"]
- 副詞変換用テーブル(用言単位)
{
}
- 助詞変換用変換テーブル(用言単位)
{
"けど": "が"
}
- 助動詞変換用テーブル(用言単位)
※キーワード部分と後続の用言群をまとめて置換する
{
"ましょ": { #直前の動詞は基本(終止)形に変換する
"う,か,ね,?": "かのぉ?",
"う,か,ね,。": "かのぉ。",
"う,か,ね": "かのぉ",
"う,か,?": "かや?",
"う,ね,。": "んす。",
"う,よ,。": "んじゃよ。",
"う,か": "かや?",
"う,ね": "んす",
"う,よ": "んじゃよ",
"う,。": "んじゃ。",
"う": "んじゃ",
"?": "かや?",
"。": "んじゃ。",
"": "んじゃ"
},
"でしょう": {
"か,ね,?": "かのぉ?",
"か,ね,。": "かのぉ。",
"か,ね": "かのぉ",
"か,?": "かや?",
"ね,。": "じゃろ。",
"よ,。": "じゃよ。",
"か": "かや?",
"ね": "じゃろ。",
"よ": "じゃよ。",
"。": "じゃ。",
"": "じゃ。",
"?": "じゃろ?"
},
"でしょ": {
"?": "じゃろ?",
"。": "じゃ。",
"": "じゃ。"
},
"まし": { #直前の動詞は連用形に変換する
"た,か,?": "たかや?",
"た,。": "たでありんす。",
"た,?": "たかや?",
"た": "たでありんす。"
},
"でし": {
"た,か,?": "だったかや?",
"た,ね,?": "だったかや?",
"た,ね": "だったかや?",
"た,。": "だったでありんす。",
"た,?": "だったかや?",
"た": "だったでありんす。"
},
"ます": { #直前の動詞は基本(終止)形に変換する
"か,ね": "かや?",
"よ,ね": "んじゃろ",
"か,?": "かや?",
"ね,?": "かや?",
"か": "かや?",
"ね": "んじゃ。",
"わ": "んじゃ。",
"よ": "んじゃ。",
"。": "んじゃ。",
"": "んじゃ。"
},
"です": {
"か,ね,?": "かのぉ?",
"よ,ね,。": "じゃな。",
"か,ね": "かのぉ?",
"よ,ね": "じゃな。",
"か,?": "かや?",
"ね,?": "かや?",
"ね,。": "じゃ。",
"わ,。": "じゃ。",
"よ,。": "じゃよ。",
"か": "かや?",
"ね": "じゃ。",
"わ": "じゃ。",
"よ": "じゃよ。",
"。": "じゃ。",
"": "じゃ"
},
"だ": {
"よ,ね,。": "じゃな。",
"よ,ね": "じゃな。",
"ね,?": "かや?",
"ね,。": "じゃ。",
"わ,。": "じゃ。",
"よ,。": "じゃよ。",
"けど": "じゃが",
"ね": "じゃ。",
"わ": "じゃ。",
"よ": "じゃよ。",
"。": "じゃ。",
"": "じゃ"
}
}
◆ 1ヶ月間のPython学習と日本語口語文法との格闘の果て
うん。まさか、たかだかDiscord用対話ボットの仕様策定と初めてのPython開発で1ヶ月以上かかるとは正直考えていなかったわ orz
でも、苦労した甲斐あって(?)、ホロの花魁っぽい口調を結構再現できてると思います。
(以下は詳細ログ出力モードで実行した結果)
INPUT TEXT (exit = n) > あなたは私に何かくれるんですか?それはちょっと困りますけど、まずはこちらをご覧下さい。
Original text:
-----
あなたは私に何かくれるんですか?それはちょっと困りますけど、まずはこちらをご覧下さい。
-----
Processing log:
-----
Translate honorific words:
-----
Found keyword: "こちら"
Translated: こっち
Found keyword: "ご覧"
Translated: 見て
-----
Translate specific words:
-----
Found keyword: "下さい"
Translated: くりゃれ
Found keyword: "何か"
Translated: なんぞ
-----
Morphological analisis after replacement:
-----
> あなた 代名詞,*,*,*,*,* 貴方 あなた アナタ
> は 助詞,係助詞,*,*,*,* は は ハ
> 私 代名詞,*,*,*,*,* 私 私 ワタクシ
> に 助詞,格助詞,*,*,*,* に に ニ
> なんぞ 助詞,副助詞,*,*,*,* なんぞ なんぞ ナンゾ
> くれる 動詞,非自立可能,*,*,下一段-ラ行,連体形-一般 呉れる くれる クレル
> ん 助詞,準体助詞,*,*,*,* の ん ン
> です 助動詞,*,*,*,助動詞-デス,終止形-一般 です です デス
> か 助詞,終助詞,*,*,*,* か か カ
> ? 補助記号,句点,*,*,*,* ? ? キゴウ
> それ 代名詞,*,*,*,*,* 其れ それ ソレ
> は 助詞,係助詞,*,*,*,* は は ハ
> ちょっと 副詞,*,*,*,*,* 一寸 ちょっと チョット
> 困り 動詞,一般,*,*,五段-ラ行,連用形-一般 困る 困る コマリ
> ます 助動詞,*,*,*,助動詞-マス,終止形-一般 ます ます マス
> けど 助詞,接続助詞,*,*,*,* けれど けど ケド
> 、 補助記号,読点,*,*,*,* 、 、 キゴウ
> まず 副詞,*,*,*,*,* 先ず まず マズ
> は 助詞,係助詞,*,*,*,* は は ハ
> こっち 代名詞,*,*,*,*,* 此方 こっち コッチ
> を 助詞,格助詞,*,*,*,* を を ヲ
> 見 動詞,非自立可能,*,*,上一段-マ行,連用形-一般 見る 見る ミ
> て 助詞,接続助詞,*,*,*,* て て テ
> くりゃ 動詞,非自立可能,*,*,カ行変格,仮定形-融合 来る くる クリャ
> れ 助動詞,*,*,*,助動詞-レル,連用形-一般 れる れる レ
> 。 補助記号,句点,*,*,*,* 。 。 キゴウ
-----
0: あなた 代名詞,*,*,*,*,* 貴方 あなた アナタ
Found keyword: "あなた"
Translated: ぬし
Translate noun token: あなた > ぬし
1: は 助詞,係助詞,*,*,*,* は は ハ
Nothing to translate: は > は
2: 私 代名詞,*,*,*,*,* 私 私 ワタクシ
Found keyword: "私"
Translated: わっち
Translate noun token: 私 > わっち
3: に 助詞,格助詞,*,*,*,* に に ニ
Nothing to translate: に > に
4: なんぞ 助詞,副助詞,*,*,*,* なんぞ なんぞ ナンゾ
Nothing to translate: なんぞ > なんぞ
5: くれる 動詞,非自立可能,*,*,下一段-ラ行,連体形-一般 呉れる くれる クレル
Translate (last)verb token: くれる > くれる
6: ん 助詞,準体助詞,*,*,*,* の ん ン
Nothing to translate: ん > ん
7: です 助動詞,*,*,*,助動詞-デス,終止形-一般 です です デス
Found keyword: ()+です+か?
Translated: ()+かや?
Translate auxiliary verb token: ですか? > かや?
10: それ 代名詞,*,*,*,*,* 其れ それ ソレ
Nothing to translate: それ > それ
11: は 助詞,係助詞,*,*,*,* は は ハ
Nothing to translate: は > は
12: ちょっと 副詞,*,*,*,*,* 一寸 ちょっと チョット
Nothing to translate: ちょっと > ちょっと
13: 困り 動詞,一般,*,*,五段-ラ行,連用形-一般 困る 困る コマリ
Found keyword: "困り"
Translated: 困りんす
Translate (last)verb token: 困り > 困りんす
15: けど 助詞,接続助詞,*,*,*,* けれど けど ケド
Found keyword: "けど"
Translated: が
Translate particle token: けど > が
16: 、 補助記号,読点,*,*,*,* 、 、 キゴウ
Nothing to translate: 、 > 、
17: まず 副詞,*,*,*,*,* 先ず まず マズ
Nothing to translate: まず > まず
18: は 助詞,係助詞,*,*,*,* は は ハ
Nothing to translate: は > は
19: こっち 代名詞,*,*,*,*,* 此方 こっち コッチ
Nothing to translate: こっち > こっち
20: を 助詞,格助詞,*,*,*,* を を ヲ
Nothing to translate: を > を
21: 見 動詞,非自立可能,*,*,上一段-マ行,連用形-一般 見る 見る ミ
Translate (last)verb token: 見 > 見
22: て 助詞,接続助詞,*,*,*,* て て テ
Nothing to translate: て > て
23: くりゃ 動詞,非自立可能,*,*,カ行変格,仮定形-融合 来る くる クリャ
Translate (last)verb token: くりゃ > くりゃ
24: れ 助動詞,*,*,*,助動詞-レル,連用形-一般 れる れる レ
Nothing to translate: れ > れ
25: 。 補助記号,句点,*,*,*,* 。 。 キゴウ
Nothing to translate: 。 > 。
-----
Translated text:
-----
ぬしはわっちになんぞくれるんかや?それはちょっと困りんすが、まずはこっちを見てくりゃれ。
-----
INPUT TEXT (exit = n) >
◆ 形態素解析器と辞書は選ぼう
なんとか口調変換モジュールの実装を終えて色々試していたら、時々期待した変換にならないケースが発生。
原因を調べたら、どうやらJanome+NEologd辞書を使っても最近の口語(いわゆるネットスラングや若者言葉)を形態素解析した結果が意図しない結果を返していました。
Analized by Janome 0.3.6 + NEologd
> おう 動詞,自立,*,*,五段・ワ行促音便,基本形,おう,オウ,オウ
これは例えば、同意の男性言葉「おう」、または「お、おう」みたいな、少し引いた感じの相槌で使う感動詞と解釈すべきですが、Janome+NEologdでは動詞「追う」と誤認識しているわけです。形態素解析=辞書の精度が悪いと、当然口調の変換も変換されなかったり意図しない変換になったりするわけなので対策が必要と思いました。
また、Janome+NEologdはメモリをかなり(1GB弱)消費するのでAWSの無料枠で使ってるt2.microインスタンスの1GBメモリ+swap(2GB)設定ではかなりツライのでなんとかならんものかと思っていました。
対策方法
- NEologd辞書を自分で編集していく
- NEologd以外の精度と最新用語への追従が早い辞書を使う
- 辞書の精度が高く最新用語への追従が早い別の形態素解析器を使う
1は誤認識を見付ける度に編集してリコンパイルとなり正直面倒。
2に関しては「UniDic」のテストフォームで前述の「おう」を形態素解析したら正しく感動詞と判別したので、JanomeのNEologd辞書から置き換えて試そうとしました。
でも、辞書形式の変換が必要だったりJanome用に辞書をコンパイルし直すのがメモリ的につらそうだし面倒だったりでどうしようかかなぁというところ。
そして3は、そもそも事前に色々探して見付けたのがJanome+NEologd辞書だったので他にないんだよなぁ、、、と、ダメモトで探したら素晴らしい形態素解析器がありました!
「Sudachi」という新しい日本語形態素解析モジュールで、メモリ効率はJanomeどころかMecabよりもいいし反応も速く、何より辞書はNEologdとUniDicの両方をベースに作成し更新がこれからも継続するってことです(10年間は更新すると言ってますw)。また、プラグインで機能拡張できるようにしているのも面白いですね。
このSudachiはオリジナルはJava製ですが、プロト版でPythonの「SudachiPy」がありました。
早速形態素解析モジュールをSudachiPyに置き換えて先程の「おう」を解析したら、
Tokenized by Sudachipy 0.1.0 (arranged UniDic+NEologd)
> おう,感動詞,一般,*,*,*,*,おお,おう,オウ
素晴らしい! おまけに辞書や解析器のインスタンスを生成してもさほどメモリを消費していません。
これで形態素解析器の精度やメモリの問題は改善されました。
◆ モジュールの配布
というわけで、開発したモジュールはGithubに登録したので、興味がありましたら是非使ってみて下さい。
なにぶんPythonを触り始めて1ヶ月程度なので、プロジェクトの構造やソースコードのリファインの稚拙さは何卒ご容赦を(;´Д`) (「こう書くべき」「こう書いた方がいい」などご教授いただけると助かります)
なお、同梱してある開発の副産物として動詞の活用形に応じた送り仮名変換をするモジュール"verb_conjugate.py"は、単独で別のプログラムから呼びだして使うことができるので、よかったら活用して下さい。
◆ モジュールの動作環境
- Python3.7系(3.6以上推奨。開発環境はAWS EC2 Linux上のPython 3.7)
- SudachiPy 0.5.2以上 のインストール必須
◆ これ、他のキャラや方言にも応用できんじゃね?
一応、仕様策定と作り込み段階で「どうせ作るならなるべく変換パターンをjsonファイルだけで定義できるようにして汎用的にしよう」とは思っていたので、「口調モデル」としてjsonファイル群をフォルダ分けして追加できる仕組みにするのはさほど面倒ではありませんでした。
modelsフォルダ配下に他のキャラクターの口調や方言への変換ができるjsonファイル群を既存のをベースにして改造して別フォルダ(フォルダ名=口調モデル名)に格納すれば、色々なパターンを作成できるはずです。Githubからforkして新しい口調モデルを作ったら是非プルリクしてくださいね!
それでも、コード内の語尾の変換などの条件判断部分で、一部の表層形や活用形の指定が「ホロの口調」を前提にコーディングされてますが、それでも一般的な日本語では問題ないと思います(方言は多彩なので全ての方言でOKとはいかないと思うけど…)。
また、方言などでは動詞の語幹も含めて変換が必要になりそうですが、現時点では動詞の変換テーブルには対応していません。追々リファインしながら改造していきたいと思っています。
それでは、初投稿で少し気張りましたが今回のネタはここまで。そのうち、Discord用ボット本体のほうも辞書学習機能などの追加開発が落ち着いたら掲載したいと思います。
ケモミミ サイコー!