目的
複数水準で何条件ってなると書くのは配置が大変なことは別にしても、
なかなか苦労で良いツールを探したが見つからない。
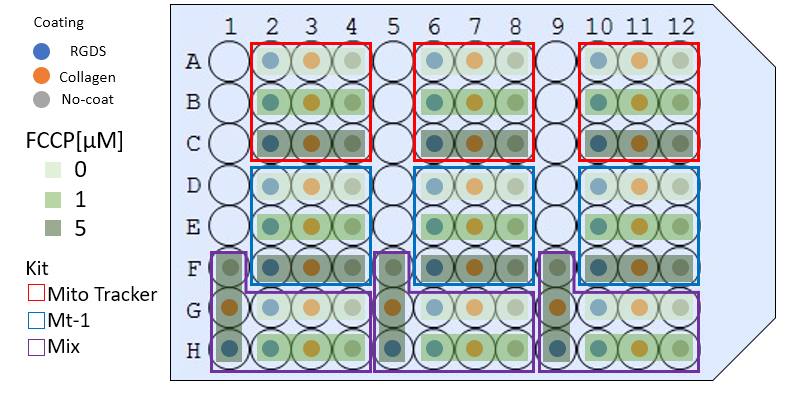
これはパワポで書いているが、こういうのをきれいに自動で書きたい。
方針
結果の解析用に各要因でのwellの水準をエクセルファイルに持っているので、
これからタイル可視化でwell毎に水準を、塗・線・中に文字などの属性で書き分けるプログラムを書く。
手順
エクセルに、行列状態でデータが入ってます。
各シートが各要因になっており、
別のシートにも、同じ列数・行数で別の要因での水準がついてます。

読み込み
xlsx_file <- "../data/layout.xlsx"
sheets <- readxl::excel_sheets(xlsx_file)
df_xlsx <- sheets %>%
map_df( ~ readxl::read_xlsx(xlsx_file,sheet = .x) %>%
pivot_longer(cols = -...1) %>%
rename(well_row=...1,well_col=name) %>%
mutate(value=as.character(value),lavel=.x)) %>%
pivot_wider(names_from = lavel,values_from = value) %>%
mutate(well_col=as.factor(as.numeric(well_col)))
このようなデータフレームが得られる。

96well形式のタイリングで各要因を属性にして可視化
df_xlsx %>%
ggplot(aes(x=well_col,y=fct_rev(well_row)))+
geom_point(aes(colour=Kit,fill=as.factor(FCCP)),shape=22,stroke=5,size=10)+
geom_text(aes(label=Coating),size=3,angle=20)+
scale_colour_brewer(palette = "Set2")+
scale_fill_brewer(palette = "Greens")+
labs(x=NULL,y=NULL,fill="FCCP[µM]")

エクセルでのものを思って書いたが正直ごちゃごちゃしている。
実験操作は各要因で行っていくので、ヒトによっては分けたほうが見やすいのではと思った。
df_xlsx %>% pivot_longer(cols = -c(well_row,well_col)) %>%
group_nest(name) %>%
mutate(g=map2(name,data,~
.y %>%
ggplot(aes(x=well_col,y=fct_rev(well_row)))+
geom_point(aes(fill=value),shape=22,size=5)+
labs(x=NULL,y=NULL,fill=.x))) %>%
pull(g) %>%
patchwork::wrap_plots()

なかなかいいのでは。
まとめ
分けて書く方法とまとめて書く方法の両者を必要に応じて使い分けていく。
おすすめは、分ける方。要因が増えても使えるのがいい。
その他
- 今回はplateが1枚にしか対応していないが、増やすことは可能。エクセルの下につなげて行くといいと思います。(気が向いたら作成します)
- エクセルの読み込みに関して、別の方法(最初のシートからwell_row,well_colだけ取り出してbind_cols)を試した。
library(microbenchmark)
xlsx_file <- "../data/layout.xlsx"
sheets <- readxl::excel_sheets(xlsx_file)
res <- microbenchmark::microbenchmark(
bind = {bind_cols(
readxl::read_xlsx(xlsx_file) %>%
pivot_longer(cols = -...1) %>%
select(-value) %>%
rename(well_row=...1,well_col=name),
sheets %>%
map_dfc( ~ readxl::read_xlsx(xlsx_file,sheet = .x) %>%
pivot_longer(cols = -...1) %>%
select(value) %>%
rename(!!.x :=value))
) %>%
mutate(well_col=fct_relevel(well_col,levels=c("1","2","3","4","5","6","7","8","9","10","11","12")))},
straight = {sheets %>%
map_df( ~ readxl::read_xlsx(xlsx_file,sheet = .x) %>%
pivot_longer(cols = -...1) %>%
rename(well_row=...1,well_col=name) %>%
mutate(value=as.character(value),lavel=.x)) %>%
pivot_wider(names_from = lavel,values_from = value) %>%
mutate(well_col=fct_relevel(well_col,levels=c("1","2","3","4","5","6","7","8","9","10","11","12")))}
)
autoplot(res)

結果としては、本論で扱っていた方が早く、また、全要因の水準パラメーターを文字型に明示的にするので、扱いやすくなると思う。