13億パラメータ版GPT-2で生成した文章:
GPT-2のような文章生成モデルは、読み手が熟達することで使いやすくなることが期待されている。日本語では「文章が上手い」という表現があるが、この熟達性とは一定のレベルをクリアしなければならないというもので、また一定レベルを満たしていればその文章を読んだだけで「うまい文章」だと思えるというものでもない。文章を書くこと自体はその場の思いつきや書き手と読み手の相性などによって変容する。
みなさんこんにちは。
Transformerの登場以降、目覚ましい発展を遂げている自然言語処理界隈ですが、最近ビッグニュースが飛び込んできましたね。rinna株式会社さんが、これまでよりも大規模なGPT-2の事前学習モデルを公開してくださいました。冒頭の引用文は私が実際にGPT-2で生成した文章です。これ、すごいですよね。
パラメータ数は約13億。とんでもない数ですね・・。
事前学習モデルのバイナリサイズは2.5GBほどになるようです。
「なんだかすごい気がするし、実際試してみたいけど・・・難しいんでしょう?」
という方も多くいらっしゃると思い、簡単に試せる方法をここに記しておこうと思います。
大きな流れ
今回は**「試す」ことを目的に、環境構築には時間をかけずサクッといきたいと思います。
このため、Google Colaboratory での動作を前提とします。
やることはたったの5ステップ**です。
- Google Colaboratryを開く
- Transformersをインストールする
- Sentence Pieceをインストールする
- GPT-2の事前学習モデルをロードする
- 文章を生成する
ちょっとした説明とサンプルコード
1. Google Colaboratryを開く
Google ColaboratryはGoogleが提供する、WEBブラウザ上で使用できるPython実行環境です。
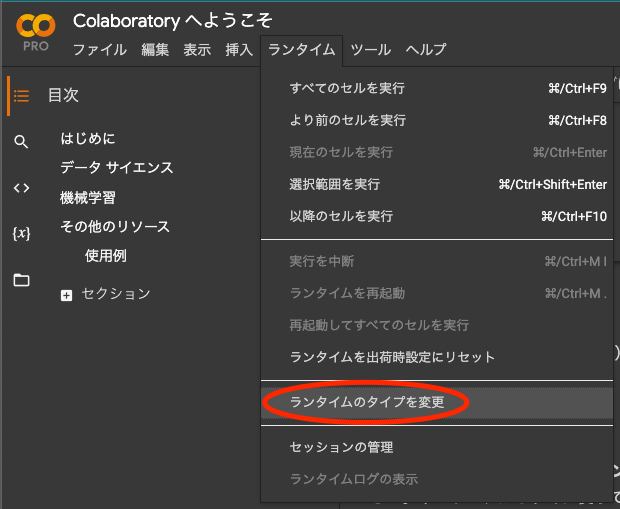
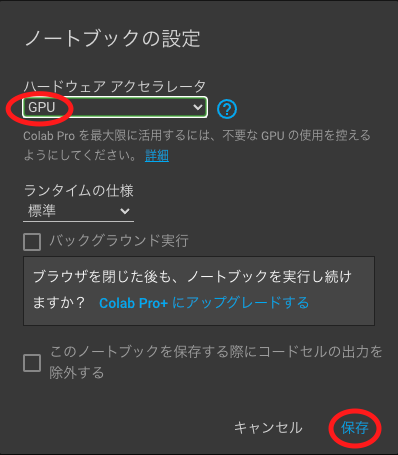
GPUを使うと文章の生成が速く終わるので、「ランタイムのタイプを変更」からGPUを選択しておきます。
なお、これ以降の手順でコードをコピペするのが面倒という方は↓のボタンからどうぞ。
![]()
2. Transformersをインストールする
Google Colaboratory の環境を立ち上げた最初の状態ではTransformersがインストールされていません。このため、pipコマンドを使ってライブラリのインストールを行います。
# Transformersのインストール
!pip install transformers
3. Sentence Pieceをインストールする
rinna株式会社さんが公開しているGPT-2の事前学習モデルは、トークナイズにSentencePieceを使っています。こちらも、pipコマンドを使ってライブラリのインストールを行います。
# SentencePieceのインストール
!pip install sentencepiece
4. GPT-2の事前学習モデルをロードする
さきほどインストールしたTransformersのモジュールを使って事前学習済みモデルをダウンロードし読み込みます。こちらは少し時間がかかります。最後の2行はGPUを使って文章生成をするための設定です。GPUを使うと文章の生成が速くなります。
# ライブラリのインポート
import torch
from transformers import T5Tokenizer, AutoModelForCausalLM
# トークナイザの読み込み
tokenizer = T5Tokenizer.from_pretrained("rinna/japanese-gpt-1b")
# モデル本体の読み込み
model = AutoModelForCausalLM.from_pretrained("rinna/japanese-gpt-1b")
# GPU使用時の設定
if torch.cuda.is_available():
model = model.to("cuda")
5. 文章を生成する
さて、いよいよ文章を生成してみます。
こちらはHuggingFaceにあるサンプルコードを使わさせて頂きました。
「GPT-2のような文章生成モデルは、」という文からスタートして文章を作成します。
# 入力文
text = "GPT-2のような文章生成モデルは、"
# 入力文のトークナイズ
token_ids = tokenizer.encode(text, add_special_tokens=False, return_tensors="pt")
# 入力文とパラメータの設定にしたがって文章を生成
with torch.no_grad():
output_ids = model.generate(
token_ids.to(model.device),
max_length=100,
min_length=100,
do_sample=True,
top_k=500,
top_p=0.95,
pad_token_id=tokenizer.pad_token_id,
bos_token_id=tokenizer.bos_token_id,
eos_token_id=tokenizer.eos_token_id,
bad_word_ids=[[tokenizer.unk_token_id]]
)
# 生成された文章を単語IDから実際の単語に変換
output = tokenizer.decode(output_ids.tolist()[0])
print(output)
生成された文章:
GPT-2のような文章生成モデルは、読み手が熟達することで使いやすくなることが期待されている。日本語では「文章が上手い」という表現があるが、この熟達性とは一定のレベルをクリアしなければならないというもので、また一定レベルを満たしていればその文章を読んだだけで「うまい文章」だと思えるというものでもない。文章を書くこと自体はその場の思いつきや書き手と読み手の相性などによって変容する。しかし「うまい文章」は実際に精読することでしか評価できないのであり、この精読をすることによってようやく
うーん、なるほど・・・
文章生成モデルの使い勝手は読み手にかかっているんですね。なんだか、意思を持ってるんじゃないかってくらい自然な文章が出てきて怖いくらいですね・・・
おわりに
今回は事前学習済みのモデルをそのまま使用して文章を生成してみました。BERTやGPT-2のようなモデルは、さらに少量の訓練データを用意しファインチューニング(微調整)をすることで、より多様なタスクに適応させることができます。ファインチューニングにはそれほど計算リソースを必要としませんが、事前学習においては莫大なリソースを要します。これほど大規模な日本語版事前学習モデルを公開してくださったrinna株式会社さんには、感謝の念に堪えません。