1.っていうよく見るアレです。
アレってなんだよっていう方のために結果を先にお見せします。
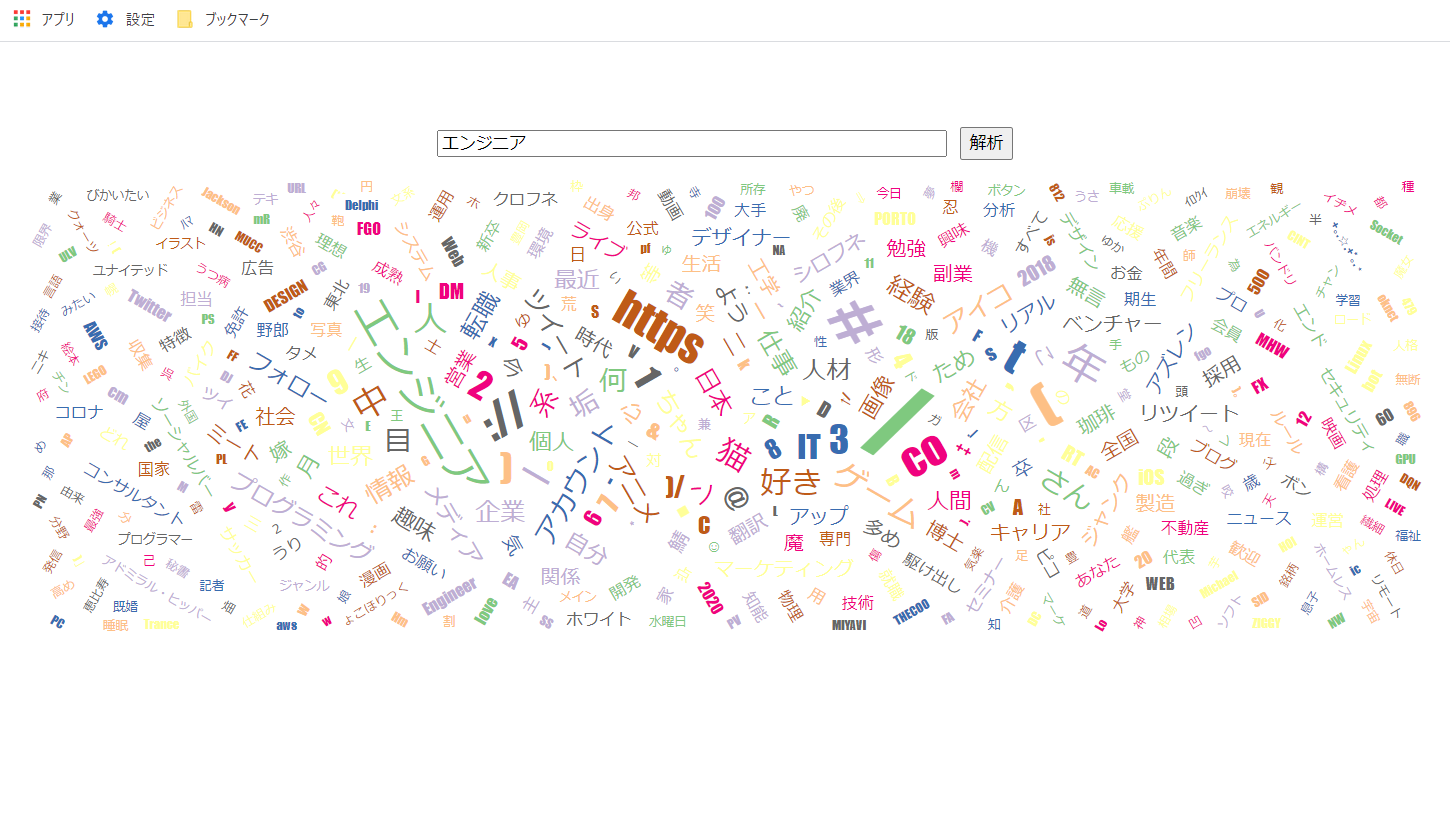
ツイートを検索ワードで検索すると、ヒットしたツイートしてる人のプロフィールの単語をWord Cloudのタグクラウドで表示します。
出現回数が多い文字が大きくなります。
作り方は簡単みたいですが、調べるとだいたいPythonです。
今、Vue.jsとJava(Spring Boot)で開発してるので、それで作れないかな~と思ってちょっとWebアプリを作ってみました。
今回はツイートの内容じゃなくて、ツイートの内容からプロフィールの内容をひっぱってきてるのでそこが少しトリッキーかも。
Webアプリ作成日数:2日
Qiita記事作成:2日
Qiita記事作成のほうがしんどい。
何でこんなに長いタイトルになってしまったのか。
Webアプリの動作の流れはこんな感じです。
TwitterのAPIでツイートのプロフィール情報取得 ↓ プロフィール情報の形態素解析 ↓ 可視化
形態素解析とは?
文章を単語に分割する作業って感じですが私はそれ以上のことはわからないのでみなさんの方がきっと詳しくなります。
2.環境
Vue.js:2.6.12
Spring Boot:v2.3.3
Java:AdoptOpenJDK:11.0.6
Kuromoji:0.9.0
vue-wordcloud:1.1.1
axios:0.20.0
性懲りもなくVue.jsをフロント、Spring BootをサーバサイドのAPIとします。
大まかなディレクトリ構造はこんな感じです。
┠ src
┃ ┗ main
┃ ┗ java/app/myapp
┃ ┠ common
┃ ┃ ┗ HttpAccess.java
┃ ┠ controller
┃ ┃ ┗ TwitterAnalysisRestController.java
┃ ┠ entity
┃ ┃ ┗ VueWordCloudEntity.java
┃ ┠ service
┃ ┃ ┗ TwitterAnalysisService.java
┃ 色々
┃
┠ web
┃ ┠ 色々
┃ ┠ src
┃ ┃ ┠ 色々
┃ ┃ ┠ router
┃ ┃ ┃ ┗ index.js
┃ ┃ ┠ views
┃ ┃ ┃ ┗ TwitterAnalysis.vue
┃ ┃ ┃
┃ ┃ 色々
┃ 色々
┃
┠ build.gradle
色々
3.手順
3-1.前提
Spring Boot のプロジェクトが作成済。
3-2.TwitterのAPI利用申請
まず、Twitter側にTwitterのAPI利用申請をする必要があります。
Twitterのアカウントを持ってる前提です。
親切に解説してくれてるサイトがあるので、利用申請はこちらを参考にしてください。
2020年度版 Twitter API利用申請の例文からAPIキーの取得まで詳しく解説
情報は日々変わるのですでに変わってるところがあるかもしれませんが、多分もっと簡単になってるはずです。
やることは、Twitter側からのいくつかの質問に答えるだけです。
どうみても英語で書くことを強いられる申請画面なのですが、実は日本語でもよかったりして…
質問に答えたら承認待ちかな…と思ったらそんなことはなく、すぐにトークン(Bearer Token)の表示画面に行けました。
このトークンとあとキーをコピーしておけばOKです。
ちょっと前は承認待ちに数日かかっていたようです。
3-3.Javaの実装
まずはTwitterのAPIを利用してプロフィール情報を取得します。
Twitter4Jというライブラリを使えば便利なようですが、今回は使ってません。
理由は特にありません。
APIのURLはこんな感じです。
API、最近新しくなったみたいですね。
https://api.twitter.com/2/tweets/search/recent?expansions=author_id&user.fields=description&max_results=100&query=<検索キーワード>
| 今回使うパラメータ | 内容 |
|---|---|
| expansions=author_id | ツイートの文章と同時に、そのツイートをした人の情報を取得するために指定 |
| user.fields=description | 取得する情報に、ツイートをした人のプロフィールの文章を含めるために指定 |
| max_results=100 | 最大取得件数 |
| query=<検索ワード> | ツイートに対する検索ワード |
詳しくは公式サイト
で、APIを利用して情報を取得するのはこんな感じ。
トークンには上記で取得したBearer Tokenを指定します。
String urlString = "https://api.twitter.com/2/tweets/search/recent?expansions=author_id&user.fields=description&max_results=100";
String method = "GET";
String bearerToken = <トークン>;
HttpAccess httpAccess = new HttpAccess();
String response = httpAccess.requestHttp(urlString, method, bearerToken, <検索ワード>);
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.io.UnsupportedEncodingException;
import java.net.HttpURLConnection;
import java.net.URL;
import java.net.URLEncoder;
public class HttpAccess {
public String requestHttp(String urlString, String method, String bearerToken, String query) {
String result = null;
String urlStringFull = null;
if (query == null || query.isEmpty()) return result;
try {
urlStringFull = urlString + "&query=" + URLEncoder.encode(query, "UTF-8");
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
}
if (urlStringFull == null) return result;
HttpURLConnection urlConn = null;
InputStream in = null;
BufferedReader reader = null;
try {
URL url = new URL(urlStringFull);
urlConn = (HttpURLConnection) url.openConnection();
urlConn.setRequestMethod(method);
urlConn.setRequestProperty("Authorization","Bearer " + bearerToken);
urlConn.connect();
int status = urlConn.getResponseCode();
if (status == HttpURLConnection.HTTP_OK) {
in = urlConn.getInputStream();
reader = new BufferedReader(new InputStreamReader(in));
StringBuilder output = new StringBuilder();
String line;
while ((line = reader.readLine()) != null) {
output.append(line);
}
result = output.toString();
}
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
if (reader != null) {
reader.close();
}
if (urlConn != null) {
urlConn.disconnect();
}
} catch (IOException e) {
e.printStackTrace();
}
}
return result;
}
}
次に形態素解析ですが、Javaでやりたい場合はKuromojiが便利です。
build.gradle ファイルに一行追加するだけです。
dependencies {
~略~
implementation 'com.atilika.kuromoji:kuromoji-ipadic:0.9.0'
~略~
}
あと、データをどういう形式で返すかというと、ビューの方でvue-wordcloudが「name」と「value」をキーに持つオブジェクトの配列をデータとして扱うので、「name」と「value」をキーに持つオブジェクトの配列をJSONで返します。
※キーの名称は変更可能
「name」には形態素解析した結果の単語、「value」にはその単語が何回出現したかを入れます。
今回、名詞のみを対象にするとして、上記のAPIへのアクセスに加えて形態素解析を行い、「name」と「value」をフィールドに持つオブジェクトを作成したのが以下の通りです。
形態素解析にはTokenizerクラスを使います。
import java.util.ArrayList;
import java.util.List;
import java.util.stream.Collectors;
import com.atilika.kuromoji.ipadic.Token;
import com.atilika.kuromoji.ipadic.Tokenizer;
import com.fasterxml.jackson.core.JsonProcessingException;
import com.fasterxml.jackson.databind.JsonNode;
import com.fasterxml.jackson.databind.ObjectMapper;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import app.myapp.common.HttpAccess;
import app.myapp.entity.VueWordCloudEntity;
@Service
public class TwitterAnalysisService {
public List<VueWordCloudEntity> analysisTwitterProfileByQuery(String query) {
List<VueWordCloudEntity> result = new ArrayList<>();
String urlString = "https://api.twitter.com/2/tweets/search/recent?expansions=author_id&user.fields=description&max_results=100";
String method = "GET";
String bearerToken = <トークン>;
HttpAccess httpAccess = new HttpAccess();
String response = httpAccess.requestHttp(urlString, method, bearerToken, query);
if (response == null) return result;
ObjectMapper mapper = new ObjectMapper();
JsonNode root = null;
try {
root = mapper.readTree(response);
} catch (JsonProcessingException e) {
e.printStackTrace();
}
if (root == null || root.get("meta").get("result_count").asInt() == 0) {
return result;
}
Tokenizer tokenizer = new Tokenizer();
List<Token> tokens = new ArrayList<>();
JsonNode users = root.get("includes").get("users");
for(int i = 0; i < users.size(); i++) {
if (users.get(i).get("description") != null) {
tokens.addAll(tokenizer.tokenize(users.get(i).get("description").asText()));
}
}
List<VueWordCloudEntity> vueWordCloudEntityList = new ArrayList<>();
tokens.stream()
.filter(x -> x.getPartOfSpeechLevel1().equals("名詞"))
.map(x -> x.getSurface())
.collect(Collectors.groupingBy(x -> x, Collectors.counting()))
.forEach((k, v) -> {
VueWordCloudEntity vueWordCloudEntity = new VueWordCloudEntity();
vueWordCloudEntity.setName(k);
vueWordCloudEntity.setValue(v);
vueWordCloudEntityList.add(vueWordCloudEntity);
});
result = vueWordCloudEntityList;
return result;
}
}
import lombok.Data;
@Data
public class VueWordCloudEntity {
private String name;
private Long value;
}
import java.util.List;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.http.HttpHeaders;
import org.springframework.http.HttpStatus;
import org.springframework.http.ResponseEntity;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import lombok.RequiredArgsConstructor;
import app.myapp.entity.VueWordCloudEntity;
import app.myapp.service.TwitterAnalysisService;
@RestController
@RequiredArgsConstructor
@RequestMapping("/api")
public class TwitterAnalysisRestController {
@Autowired
private TwitterAnalysisService twitterAnalysisService;
@GetMapping("/twitter/analysis/profile/by/{query}")
public ResponseEntity<List<VueWordCloudEntity>> analysisTwitterProfileByQuery(
@PathVariable String query) {
List<VueWordCloudEntity> result
= twitterAnalysisService.analysisTwitterProfileByQuery(query);
// テストアプリのためここでCORS対応
HttpHeaders headers = new HttpHeaders();
headers.add("Access-Control-Allow-Credentials", "true");
headers.add("Access-Control-Allow-Origin", "http://localhost:<Vue.js実行環境ポート番号>");
return new ResponseEntity<>(result, headers, HttpStatus.OK);
}
}
きっとJavaでTwitter4Jを使わない場合のもっと簡単なやり方があるはず!
どこかにあるよきっとそんなサンプル。
今回は残念、私のサンプルでした。
※ソースコードは「動作する」優先です、という言い訳をしてみる…
3-4.Vue.jsの実装
こっちはvue-wordcloudをインストールしてvue-wordcloud公式のソースをほぼコピペするだけなので簡単です。
vue-cliのGUIでプロジェクトを作成して上記のディレクト構造の場所へ配置します。
その後、vue-cliのGUIでvue-wordcloudをインストールします。
あ、あとaxiosも。
あとは、公式のサンプルをコピペし、ちょこっと直してSpring BootのAPIからデータを取得します。
<template>
<div id="twitter-analysis">
<input v-model="query" placeholder="キーワードを入力してください" style="width:400px;">
<button @click="analyzeProfile" style="margin-left:10px;">解析</button>
<wordcloud
:data="analyzedWords"
nameKey="name"
valueKey="value"
color="Accent"
:showTooltip="true"
:wordClick="wordClickHandler">
</wordcloud>
</div>
</template>
<script>
import wordcloud from 'vue-wordcloud'
import axios from 'axios'
axios.defaults.withCredentials = true
export default {
name: 'TwitterAnalysis',
components: {
wordcloud
},
data() {
return {
query: '',
analyzedWords: [],
}
},
methods: {
wordClickHandler(name, value, vm) {
console.log('wordClickHandler', name, value, vm);
},
analyzeProfile: async function () {
if (this.query == null || this.query === '') return
await axios.get('http://localhost:<Spring Boot実行環境ポート番号>/api/twitter/analysis/profile/by/'
+ encodeURIComponent(this.query))
.then(res => {
if (res.data != null) {
this.analyzedWords = res.data
}
})
.catch(err => {
alert(err + ' エラーです。')
})
},
},
}
</script>
import Vue from 'vue'
import VueRouter from 'vue-router'
Vue.use(VueRouter)
const routes = [
{
path: '/',
name: 'TwitterAnalysis',
component: () => import(/* webpackChunkName: "twitteranalysis" */ '../views/TwitterAnalysis.vue')
},
]
const router = new VueRouter({
mode: 'history',
routes
})
export default router
これで
http://localhost:<Vue.js実行環境ポート番号>/
にアクセスします。
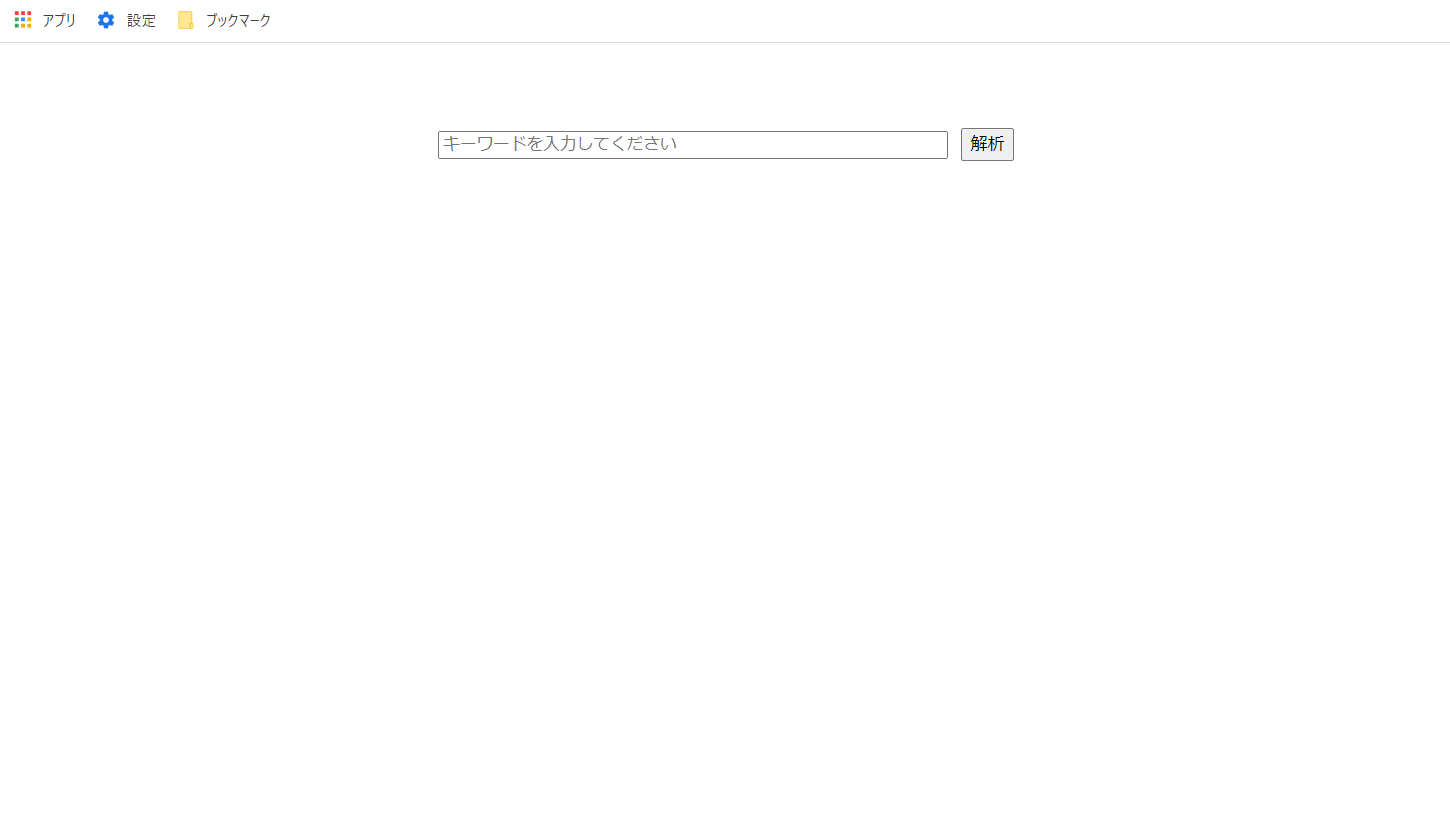
検索ワードを入力して解析ボタンを押すと
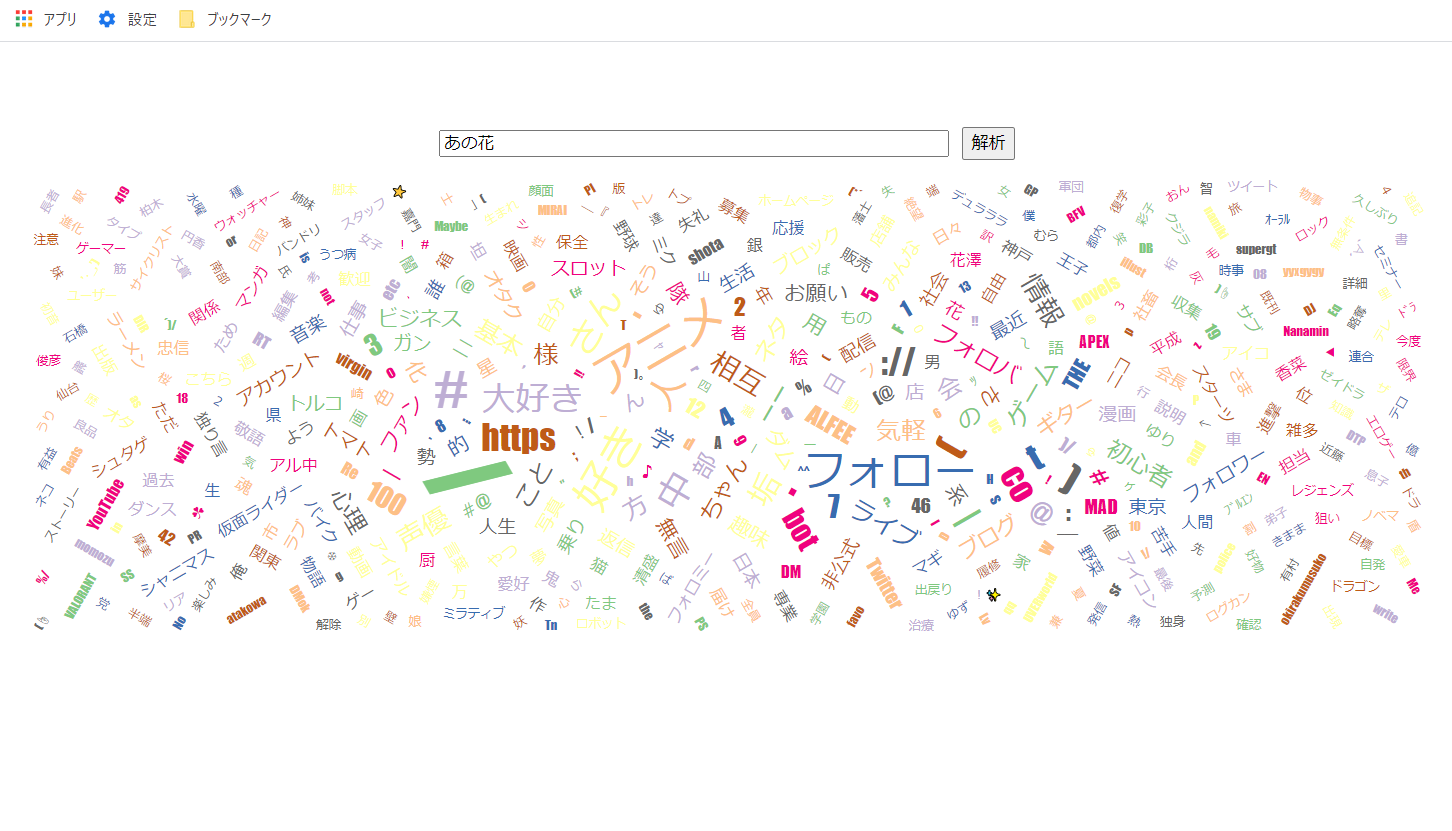
成功!するはず。
見ると、スラッシュとかhttpとかどうでもいい単語があるので、こういうのはきっと除外するんだと思います。
このアプリで何か面白い傾向がわかるかな~と思ったんですが、あんまりわからない!
そもそも、そもそもな感じ。
色々勉強が必要みたいですねぇ…