はじめに
甲子園も近いということで、覚えたてのpythonでトーナメントシミュレーターを作ってみました。
尚、スキル不足により泥くさい集計をしているので機械学習やディープラーニングといった単語は出てきません。
トーナメント処理は一部抜粋という形にさせていただきます。
ソースはGitHubの方に上げてます。
https://github.com/amnihs/tournament_simulator
コードは動けばいいレベルですのでとても汚くなっております。ご了承下さい。
環境
Windows 10 Pro
Docker for Windows
バージョン
python3.6 anaconda
勝敗決定方法(独断と偏見)
・まず地方予選の得点、失点それぞれ1試合あたりの平均を算出しました
・対戦時、自チームの得点平均と相手チームの失点平均を足したものを自チームの最高得点とします(相手チームも同様)
・地域による戦力差を考慮し、過去10年間の甲子園勝利数を偏差値として最高得点に係数を掛けました。詳細は後述
過去10年間の甲子園勝利数はこちらを参考にさせて頂きました
https://todo-ran.com/t/kiji/13841
・期待値は「最高得点/2」とします
・「期待値」を総合力として競います。尚、引き分けの場合は[0〜最高得点]の乱数で勝負
インポートの設定
まず必要なものをインポートします。
import random
import numpy as np
import pandas as pd
from pandas import Series, DataFrame
dataframe参照時に行が省略されない為の設定。
これを設定しないとすべての行を参照できなかったので、とりあえず101行まで出力出来るよう設定。
pd.set_option("display.max_rows", 101)
csvファイル読み込み
必要な情報を記述したcsvを読み込みます。
# name, score, given_point, entry_round, winning_count
kohshien_df = pd.read_csv('main.csv', encoding="shift-jis")
各項目は下記の通り。
name:学校名(地区)
score:地区予選一試合平均得点
given_point:地区予選一試合平均失点
entry_round:何回戦から参加するか(シード用)
winning_count:代表地区の過去10年間甲子園勝利数
計算の下準備
甲子園勝利数の偏差値を計算するため、平均値と標準偏差を算出します。
mean = np.mean(kohshien_df['winning_count'])
std = np.std(kohshien_df['winning_count'])
meanが平均値、stdが標準偏差です。
さらに計算用の地域戦力差係数をデータフレームの列として追加します。
kohshien_df['勝利数偏差値'] = kohshien_df[['winning_count']].apply(winning_deviation, axis=1)
kohshien_df['rate'] = kohshien_df[['勝利数偏差値']].apply(add_rate, axis=1)
def winning_deviation(winning_count):
deviation = (winning_count - mean) / std
deviation_value = 50 + (deviation * 10)
return deviation_value
def add_rate(calc_deviation):
return (calc_deviation + 50) / 100
地域戦力差係数は「偏差値 + 50 / 100」としました
偏差値80であれば、最高得点に1.3掛け
偏差値40であれば、最高得点に0.9掛け
戦力を分かりやすくするため、うまくばらけるように適当にランク分けしました。
(defのパラメータを減らすとエラーになったり、まだよくわかってない)
検証用にlose(敗退フラグ)、優勝回数列を追加。
kohshien_df['攻撃力ランク'] = kohshien_df[['score','given_point','rate']].apply(attack_rank, axis=1)
kohshien_df['防御力ランク'] = kohshien_df[['score','given_point','rate']].apply(defence_rank, axis=1)
kohshien_df['優勝回数'] = 0
kohshien_df['lose'] = False
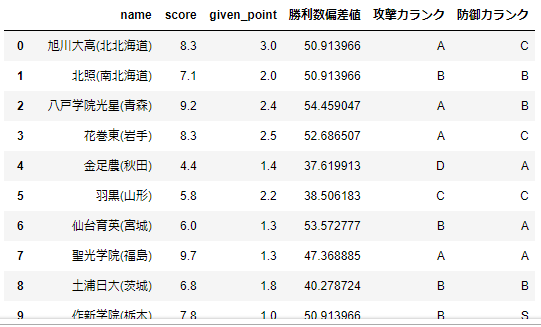
kohshien_df[['name','score','given_point','勝利数偏差値','攻撃力ランク','防御力ランク']]
def attack_rank(point):
score, given_point, rate = point
score = score * rate
if score >= 12:
return 'SS'
elif score >= 10:
return 'S'
elif score >= 8:
return 'A'
elif score >= 6:
return 'B'
elif score >= 4:
return 'C'
else:
return 'D'
def defence_rank(point):
score, given_point, rate = point
given_point = given_point / rate
if given_point < 0.6:
return 'SS'
elif given_point < 1.2:
return 'S'
elif given_point < 1.8:
return 'A'
elif given_point < 2.4:
return 'B'
elif given_point < 3:
return 'C'
else:
return 'D'
こんな感じで出力されました。
トーナメント処理
詳細は割愛します。
色々なパターンで検証できるようにパラメータを用意しました。
# 検証用パラメータ
# 期待値で検証するかどうか
is_expect = True
# 地域戦力差を考慮するか設定
is_region = True
# 組み合わせをシャッフルするかどうか
is_shuffle = True
# 残りチーム数を設定(1なら優勝チーム、8ならベスト8まで検証)
remain_team = 1
# 何回検証するか設定
limit = 100
地域戦力差係数を設定
# 最大得点を取得 自チームの攻撃値+敵チームの防御値
own_max = battle_df.loc[own_df.index,'score'].values + battle_df.loc[other_df.index,'given_point'].values
other_max = battle_df.loc[other_df.index,'score'].values + battle_df.loc[own_df.index,'given_point'].values
# 地域戦力差を考慮
if is_region == True:
own_max = own_max * own_df['rate'].values
other_max = other_max * other_df['rate'].values
期待値で検証しない場合は[0-最大得点]の乱数で計算します
決着がつくまで繰り返します
settle = False
# 期待値で計算(引き分けた場合は乱数で勝負)
if is_expect == True:
own_score = own_max / 2
other_score = other_max / 2
# int型に変換
own_score = int(np.round(own_score, 0))
other_score = int(np.round(other_score, 0))
print("期待値で検証")
if (own_score != other_score):
settle = True
# 決着がつくまで繰り返す
while settle == False:
# [0~最大得点]の乱数を取得
own_score = random.uniform(0.0, own_max)
other_score = random.uniform(0.0, other_max)
# int型に変換
own_score = int(np.round(own_score, 0))
other_score = int(np.round(other_score, 0))
if (own_score != other_score):
# 決着
settle = True
else:
# スコアが同じだった場合は再試合
print (battle_df.loc[i,'name'], own_score, "-" , other_score, battle_df.loc[i+1,'name'])
print ("引き分け再試合!")
floatの乱数と四捨五入で少しハマったんですが、random.uniform()でfloatの乱数が取得できました。
四捨五入に関しては、単純にint()とすると小数点以下が切り捨てられてしまったので、
int(np.round())とすることで、四捨五入したあと整数を取得することが出来ました。
組み合わせのシャッフルはトーナメントの対戦相手をシャッフル
データフレームのシャッフルとインデックスのリセット
# 組み合わせシャッフル
if is_shuffle == True:
kohshien_df.reindex(np.random.permutation(kohshien_df.index))
kohshien_df = kohshien_df.reindex(np.random.permutation(kohshien_df.index)).reset_index(drop=True)
優勝回数順にソート
見やすくするためソートします。
df_s = kohshien_df.sort_values('優勝回数', ascending=False)
df_s[['name','勝利数偏差値','攻撃力ランク','防御力ランク','優勝回数']]
期待値で100回トーナメントを回してみた結果、大阪桐蔭が100%優勝してしまいました。

面白味を出すために[0~最高得点]の乱数で計算しなおしてみます。
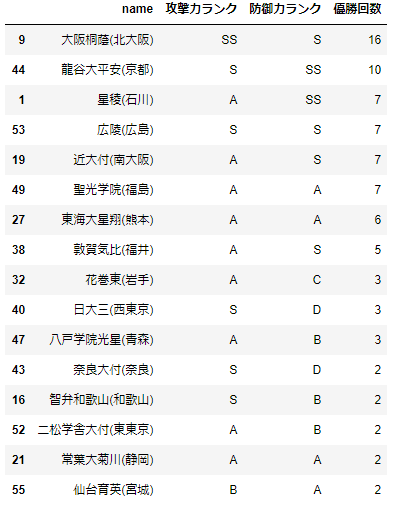
こんな感じで結果が出ました。優勝2回未満は割愛しましたが、うまくばらけました。
やはり戦力が高いチームが上位に来ています。
8/2追記
トーナメント発表されましたね。ベスト8までをシミュレーションしてみました!
・期待値によるシミュレーション

8チーム目の座を狙う東海大星翔、花咲徳栄、愛産大三河のグループは乱戦模様。
・[0~最高得点]の乱数によるシミュレーション
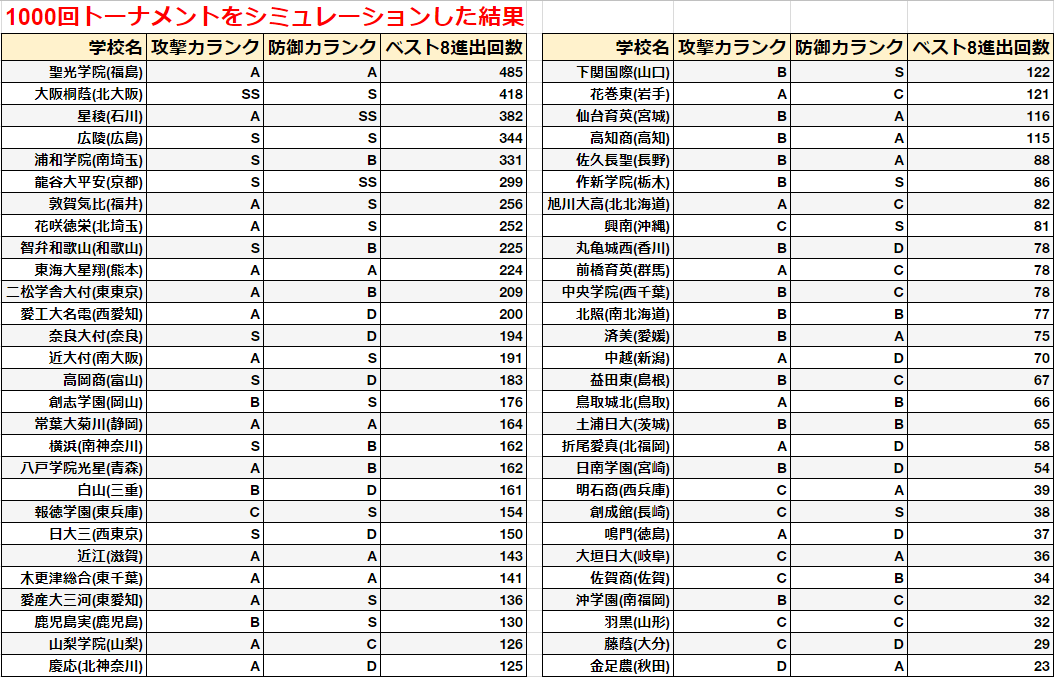
乱数だとどの高校もベスト8に入ることが出来ました。どうなるのか楽しみです。
おわり
pythonはUdemyのレッスン程度しか経験がありませんでしたが、
作りたい物が出来ると夢中で学習する事が出来てとても勉強になりました。
また、全国の地方戦の結果を調べるのが意外と楽しくて集計に2時間程度かかりましたが、
全国の高校に詳しくなってしまいました。
機械学習についても学習を進めて、より精度の高い予測を出来たらなと思います。
今後組み合わせが発表されたらまたシミュレーションしてみようと思うのと、
某TV番組で言っていた準優勝校の甲子園、略して「準甲」のシミュレーションでもしていきます。
twitterのアカウントを作りましたのでそちらにシミュレーション結果など載せていきます。
もし興味がある方は見てもらえたら嬉しいです。
全高校の戦力画像も載せています。
https://twitter.com/amnihs32
以上、雑文でしたがご覧いただきありがとうございました。