インストールがまだの人は、インストールを完了してください。
AIを始めよう!OpenVINOのインストールからデモの実行まで
インテルが用意した学習済みモデルを使う
OpenVINOツールキットには、インテルが評価用に作成した学習済みモデルが含まれまています。
インテルモデルのフォルダ:/opt/intel/computer_vison_sdk/deployment_tools/intel_models/
このフォルダのindex.htmlを開いて、どのようなモデルが用意されているのか確認しましょう。
物体検出、画像認識、画像再確認、セマンティックセグメンテーションの4種類のモデルが用意されています。
物体検出(顔や人物、車などの画像領域を検出)
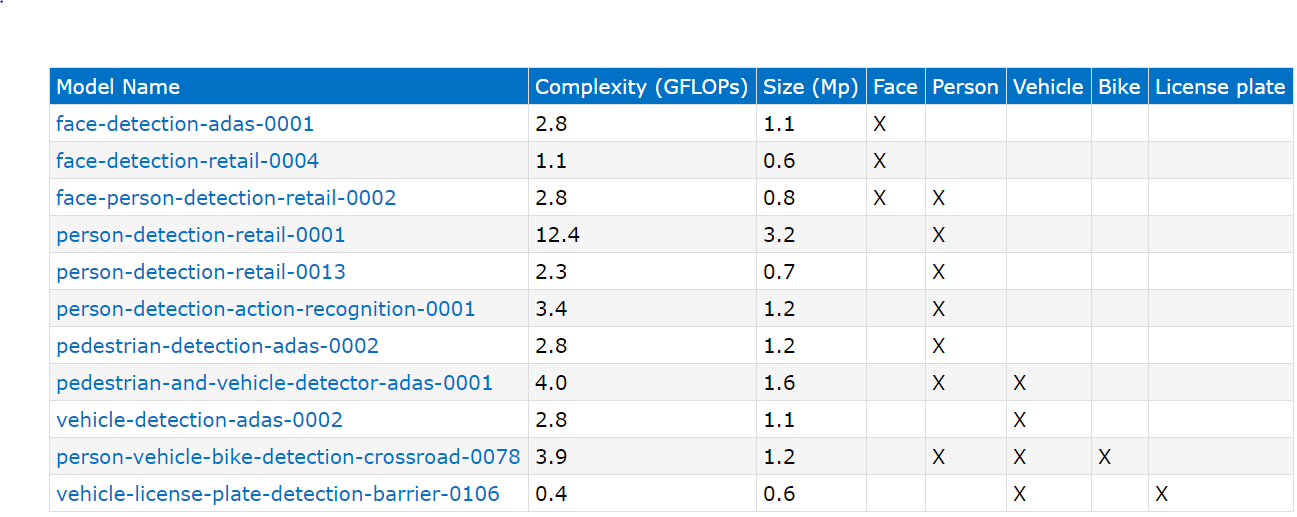
画像認識(車種判定、性別・年齢の判定)

画像再確認(画像の同一性を判定)
動画の各フレームに映ったオブジェクト(人の顔や車の車種)が同じであるか判定する際に使用する。

セマンティックセグメンテーション
画像に映った領域を分割します。例えば、道路と車、標識などの領域を認識します。


また、IRは演算精度を指定して変換する必要があります。演算精度にはFP32(32ビット浮動小数点演算)または、FP16(16ビット浮動小数点演算)の2つが設定できます。先日、Google Cloud Next 2018に参加した際に聞いた話ですが、演算精度はあまり推論結果に影響しないとのことでした。また、推論に使うハードウェアによって使える演算精度に違いがあるので注意が必要です。CPUはFP16が使えません。Movidius(Myriad)はFP32が使えません。
| FP32 | FP16 | |
|---|---|---|
| CPU | X | |
| GPU | X | X |
| MYRIAD | X |
インテルモデルでは、各精度のIRを以下のディレクトリに分けて格納しています。
32ビット精度:/opt/intel/computer_vison_sdk/deployment_tools/intel_models/<モデル名>/FP32/
16ビット精度:/opt/intel/computer_vison_sdk/deployment_tools/intel_models/<モデル名>/FP16/
インテルモデルの実行
では、一番面白い顔検出のサンプルプログラムを実行してみましょう。USBカメラを接続すると、顔の検出結果がリアルタイムに表示されます。使い方は、ヘルプで確認します。
$ cd ~/inference_engine_samples/intel64/Release
$ ./interactive_face_detection_sample -h
InferenceEngine:
API version ............ 1.2
Build .................. 13911
interactive_face_detection [OPTION]
Options:
-h Print a usage message.
-i "<path>" Optional. Path to an video file. Default value is "cam" to work with camera.
-m "<path>" Required. Path to an .xml file with a trained face detection model.
-m_ag "<path>" Optional. Path to an .xml file with a trained age gender model.
-m_hp "<path>" Optional. Path to an .xml file with a trained head pose model.
-m_em "<path>" Optional. Path to an .xml file with a trained emotions model.
-l "<absolute_path>" Required for MKLDNN (CPU)-targeted custom layers.Absolute path to a shared library with the kernels impl.
Or
-c "<absolute_path>" Required for clDNN (GPU)-targeted custom kernels.Absolute path to the xml file with the kernels desc.
-d "<device>" Specify the target device for Face Detection (CPU, GPU, FPGA, or MYRIAD). Sample will look for a suitable plugin for device specified.
-d_ag "<device>" Specify the target device for Age Gender Detection (CPU, GPU, FPGA, or MYRIAD). Sample will look for a suitable plugin for device specified.
-d_hp "<device>" Specify the target device for Head Pose Detection (CPU, GPU, FPGA, or MYRIAD). Sample will look for a suitable plugin for device specified.
-d_em "<device>" Specify the target device for Emotions Detection (CPU, GPU, FPGA, or MYRIAD). Sample will look for a suitable plugin for device specified.
-n_ag "<num>" Specify number of maximum simultaneously processed faces for Age Gender Detection (default is 16).
-n_hp "<num>" Specify number of maximum simultaneously processed faces for Head Pose Detection (default is 16).
-n_em "<num>" Specify number of maximum simultaneously processed faces for Emotions Detection (default is 16).
-dyn_ag Enable dynamic batch size for AgeGender net.
-dyn_hp Enable dynamic batch size for HeadPose net.
-dyn_em Enable dynamic batch size for Emotions net.
-async Enable asynchronous mode
-no_wait No wait for key press in the end.
-no_show No show processed video.
-pc Enables per-layer performance report.
-r Inference results as raw values.
-t Probability threshold for detections.
最低限のパラメーターとして、-iと-mを指定します。-iは入力画像で、今回はUSBカメラを指定しましょう。-mはIRのXMLファイルを指定します。今回は、インテルモデルのface-detection-retail-0004を使用しました。
まずは、USBカメラを接続してください。ノートPCの場合は、本体内蔵のカメラが利用できます。また、コマンド入力の際の入力文字数を少なくしたいので、インテルモデルのフォルダーへのシンボリックリンクを作成しています。
$ln -s /opt/intel/computer_vision_sdk/deployment_tools/intel_models/
$ ./interactive_face_detection_sample -i cam -m intel_models/face-detection-retail-0004/FP32/face-detection-retail-0004.xml -d CPU
InferenceEngine:
API version ............ 1.2
Build .................. 13911
[ INFO ] Parsing input parameters
[ INFO ] Reading input
[ INFO ] Loading plugin CPU
API version ............ 1.2
Build .................. lnx_20180510
Description ....... MKLDNNPlugin
[ INFO ] Loading network files for Face Detection
[ INFO ] Batch size is set to 1
[ INFO ] Checking Face Detection inputs
[ INFO ] Checking Face Detection outputs
[ INFO ] Loading Face Detection model to the CPU plugin
[ INFO ] Age Gender DISABLED
[ INFO ] Head Pose DISABLED
[ INFO ] Emotions Recognition DISABLED
[ INFO ] Start inference
Press any key to stop
[ INFO ] Number of processed frames: 75
[ INFO ] Total image throughput: 14.3954 fps
[ INFO ] Execution successful
リアルタイムに顔が検出されるはずです。ESCキーで終了してください。
このサンプルでは、-mのほかに、-m_ag, -m_hp, -m_emの3つのIRが指定できます。
| オプション | モデル | IRファイル |
|---|---|---|
| -m_ag | 年齢性別判定 | age-gender-recognition-retaik-0013.xml |
| -m_hp | 顔向き判定 | head-pos-estimation-adas-0001.xml |
| -m_em | 感情判定 | emotions-recognition-retail-0003.xml |
 |
インターネットに公開されたモデルを使う
次にモデルダウンローダーとモデルオプティマイザを使い、インターネットに公開されている学習済みモデルをダウンロードしてIR(中間表現)を作成しましょう。
ダウンロード可能なモデルを確認します。
$ cd /opt/intel/computer_vision_sdk/deployment_tools/model_downloader/
$ python3 downloader.py --print_all
densenet-121
densenet-161
densenet-169
densenet-201
squeezenet1.0
squeezenet1.1
mtcnn-p
mtcnn-r
mtcnn-o
mobilenet-ssd
vgg19
vgg16
ssd512
ssd300
inception-resnet-v2
dilation
googlenet-v1
googlenet-v2
googlenet-v4
alexnet
ssd_mobilenet_v2_coco
モデルのダウンロード
AI初心者の私にはどのモデルを使えばよいのかわからなかったので、全てのモデルをダウンロードしてみました。
インターネット環境にもよりますが、全てをダウンロードするためには1時間以上必要です。
$ cd /opt/intel/computer_vision_sdk/deployment_tools/model_downloader
$ python3 downloader.py -o ~/openvino_modles
ダウンロード先のディレクトリは、デモプログラムの実行時にホームディレクトリに作成されるopenvino_modlesを指定しました。ダウンロードが終了したところで、ディレクトリを確認してみましょう。
$ tree ~/openvino_models
.
├── classification
│ ├── alexnet
│ │ └── caffe
│ │ ├── alexnet.caffemodel
│ │ └── alexnet.prototxt
│ ├── densenet
│ │ ├── 121
│ │ │ └── caffe
│ │ │ ├── densenet-121.caffemodel
│ │ │ └── densenet-121.prototxt
│ │ ├── 161
│ │ │ └── caffe
│ │ │ ├── densenet-161.caffemodel
│ │ │ └── densenet-161.prototxt
│ │ ├── 169
│ │ │ └── caffe
│ │ │ ├── densenet-169.caffemodel
│ │ │ └── densenet-169.prototxt
│ │ └── 201
│ │ └── caffe
│ │ ├── densenet-201.caffemodel
│ │ └── densenet-201.prototxt
│ ├── googlenet
│ │ ├── v1
│ │ │ └── caffe
│ │ │ ├── googlenet-v1.caffemodel
│ │ │ └── googlenet-v1.prototxt
│ │ ├── v2
│ │ │ └── caffe
│ │ │ ├── googlenet-v2.caffemodel
│ │ │ └── googlenet-v2.prototxt
│ │ └── v4
│ │ └── caffe
│ │ ├── googlenet-v4.caffemodel
│ │ └── googlenet-v4.prototxt
│ ├── inception-resnet
│ │ └── v2
│ │ └── caffe
│ │ ├── inception-resnet-v2.caffemodel
│ │ └── inception-resnet-v2.prototxt
│ ├── squeezenet
│ │ ├── 1.0
│ │ │ └── caffe
│ │ │ ├── squeezenet1.0.caffemodel
│ │ │ └── squeezenet1.0.prototxt
│ │ └── 1.1
│ │ └── caffe
│ │ ├── squeezenet1.1.caffemodel
│ │ └── squeezenet1.1.prototxt
│ └── vgg
│ ├── 16
│ │ └── caffe
│ │ ├── vgg16.caffemodel
│ │ └── vgg16.prototxt
│ └── 19
│ └── caffe
│ ├── vgg19.caffemodel
│ └── vgg19.prototxt
├── ir
│ └── squeezenet1.1
│ ├── squeezenet1.1.bin
│ ├── squeezenet1.1.labels
│ ├── squeezenet1.1.mapping
│ └── squeezenet1.1.xml
├── object_detection
│ └── common
│ ├── mobilenet-ssd
│ │ └── caffe
│ │ ├── mobilenet-ssd.caffemodel
│ │ └── mobilenet-ssd.prototxt
│ ├── mtcnn
│ │ ├── o
│ │ │ └── caffe
│ │ │ ├── mtcnn-o.caffemodel
│ │ │ └── mtcnn-o.prototxt
│ │ ├── p
│ │ │ └── caffe
│ │ │ ├── mtcnn-p.caffemodel
│ │ │ └── mtcnn-p.prototxt
│ │ └── r
│ │ └── caffe
│ │ ├── mtcnn-r.caffemodel
│ │ └── mtcnn-r.prototxt
│ ├── ssd
│ │ ├── 300
│ │ │ └── caffe
│ │ │ ├── models
│ │ │ │ └── VGGNet
│ │ │ │ └── VOC0712Plus
│ │ │ │ └── SSD_300x300_ft
│ │ │ │ ├── finetune_ssd_pascal.py
│ │ │ │ ├── solver.prototxt
│ │ │ │ ├── test.prototxt
│ │ │ │ └── train.prototxt
│ │ │ ├── ssd300.caffemodel
│ │ │ ├── ssd300.prototxt
│ │ │ └── ssd300.tar.gz
│ │ └── 512
│ │ └── caffe
│ │ ├── models
│ │ │ └── VGGNet
│ │ │ └── VOC0712Plus
│ │ │ └── SSD_512x512
│ │ │ ├── solver.prototxt
│ │ │ ├── ssd_pascal_512.py
│ │ │ ├── test.prototxt
│ │ │ └── train.prototxt
│ │ ├── ssd512.caffemodel
│ │ ├── ssd512.prototxt
│ │ └── ssd512.tar.gz
│ └── ssd_mobilenet_v2_coco
│ └── tf
│ ├── ssd_mobilenet_v2_coco_2018_03_29
│ │ ├── checkpoint
│ │ ├── frozen_inference_graph.pb
│ │ ├── model.ckpt.data-00000-of-00001
│ │ ├── model.ckpt.index
│ │ ├── model.ckpt.meta
│ │ ├── pipeline.config
│ │ └── saved_model
│ │ ├── saved_model.pb
│ │ └── variables
│ └── ssd_mobilenet_v2_coco.tar.gz
└── semantic_segmentation
└── dilation
└── cityscapes
└── caffe
├── dilation.caffemodel
└── dilation.prototxt
モデルは、以下の3つのディレクトリにダウンロードされます。
- classification オブジェクト分類
- object_detection オブジェクト検出
- semantic_segmentation セマンティックセグメンテーション
学習済みモデルをIR(中間表現)に変換
ダウンロードが完了したら、IR(中間表現)への変換を行います。早速GoogLeNet V4をIRに変換してみます。
以下のスクリプトを保存して、実行してください。IRの保存先は、openvino_modles/ir/としました。
また、インテルモデルに倣って、演算精度ごとにデレクトリーFP32とFP16に分けています。
オプションとして"--scale 256 --mean_values [105,105,105]”を指定していますが、これを指定しないとGoogLeNet V4では、正しく推論されないそうです。最初指定せずに試しましたが、推論結果がでたらめだったので、インテルの方に相談したところ、このオプションをつけることを助言されました。詳細は不明ですが、スケーリングが必要なモデルは、この指定が必要なようです。推論が正常に終了したが、結果が正しくない場合は、このオプションを試してみましょう。
# !/bin/bash
mo_path='/opt/intel/computer_vision_sdk/deployment_tools/model_optimizer/mo.py'
# classifdication
model_path=$HOME'/openvino_models/classification/googlenet/v4/caffe/googlenet-v4.caffemodel'
ir_path=$HOME'/openvino_models/ir/'
model_name='googlenet-v4'
add_option='--scale 256 --mean_values [105,105,105]'
data_type='FP32'
$mo_path --input_model $model_path --output_dir $ir_path$data_type/$model_name --data_type $data_type $add_option
data_type='FP16'
$mo_path --input_model $model_path --output_dir $ir_path$data_type/$model_name --data_type $data_type $add_option
変換を実行します。
$ ./conv_googlenetv4.sh
Model Optimizer arguments:
Common parameters:
- Path to the Input Model: /home/xxxx/openvino_models/classification/googlenet/v4/caffe/googlenet-v4.caffemodel
- Path for generated IR: /home/xxxx/openvino_models/ir/FP32/googlenet-v4
- IR output name: googlenet-v4
- Log level: ERROR
- Batch: Not specified, inherited from the model
- Input layers: Not specified, inherited from the model
- Output layers: Not specified, inherited from the model
- Input shapes: Not specified, inherited from the model
- Mean values: [105,105,105]
- Scale values: Not specified
- Scale factor: 256.0
- Precision of IR: FP32
- Enable fusing: True
- Enable grouped convolutions fusing: True
- Move mean values to preprocess section: False
- Reverse input channels: False
Caffe specific parameters:
- Enable resnet optimization: True
- Path to the Input prototxt: /home/xxxx/openvino_models/classification/googlenet/v4/caffe/googlenet-v4.prototxt
- Path to CustomLayersMapping.xml: Default
- Path to a mean file: Not specified
- Offsets for a mean file: Not specified
Model Optimizer version: 1.2.185.5335e231
[ SUCCESS ] Generated IR model.
[ SUCCESS ] XML file: /home/xxxx/openvino_models/ir/FP32/googlenet-v4/googlenet-v4.xml
[ SUCCESS ] BIN file: /home/xxxx/openvino_models/ir/FP32/googlenet-v4/googlenet-v4.bin
[ SUCCESS ] Total execution time: 15.38 seconds.
Model Optimizer arguments:
Common parameters:
- Path to the Input Model: /home/xxxx/openvino_models/classification/googlenet/v4/caffe/googlenet-v4.caffemodel
- Path for generated IR: /home/xxxx/openvino_models/ir/FP16/googlenet-v4
- IR output name: googlenet-v4
- Log level: ERROR
- Batch: Not specified, inherited from the model
- Input layers: Not specified, inherited from the model
- Output layers: Not specified, inherited from the model
- Input shapes: Not specified, inherited from the model
- Mean values: [105,105,105]
- Scale values: Not specified
- Scale factor: 256.0
- Precision of IR: FP16
- Enable fusing: True
- Enable grouped convolutions fusing: True
- Move mean values to preprocess section: False
- Reverse input channels: False
Caffe specific parameters:
- Enable resnet optimization: True
- Path to the Input prototxt: /home/xxxx/openvino_models/classification/googlenet/v4/caffe/googlenet-v4.prototxt
- Path to CustomLayersMapping.xml: Default
- Path to a mean file: Not specified
- Offsets for a mean file: Not specified
Model Optimizer version: 1.2.185.5335e231
[ SUCCESS ] Generated IR model.
[ SUCCESS ] XML file: /home/xxxx/openvino_models/ir/FP16/googlenet-v4/googlenet-v4.xml
[ SUCCESS ] BIN file: /home/xxxx/openvino_models/ir/FP16/googlenet-v4/googlenet-v4.bin
[ SUCCESS ] Total execution time: 15.89 seconds.
IRが作成されますので、treeで確認してみましょう。
実際に、推論に使われるファイルは、拡張子がxmlとbinの2つです、
$ tree ir
ir
├── FP16
│ └── googlenet-v4
│ ├── googlenet-v4.bin
│ ├── googlenet-v4.mapping
│ └── googlenet-v4.xml
├── FP32
│ └── googlenet-v4
│ ├── googlenet-v4.bin
│ ├── googlenet-v4.mapping
│ └── googlenet-v4.xml
└── squeezenet1.1
├── squeezenet1.1.bin
├── squeezenet1.1.labels
├── squeezenet1.1.mapping
└── squeezenet1.1.xml
推論の実行
モデルがIRに変換できたところで、実際に試してみましょう。
入力のファイルは、インストールディレクトリのdemoフォルダーにある車の写真を使いました。
$ cd ~/inference_engine_samples/intel64/Release
$ ./classification_sample -m ~/openvino_models/ir/FP32/googlenet-v4/googlenet-v4.xml -i /opt/intel/computer_vision_sdk/deployment_tools/demo/car.png
[ INFO ] InferenceEngine:
API version ............ 1.2
Build .................. 13911
[ INFO ] Parsing input parameters
[ INFO ] Loading plugin
API version ............ 1.2
Build .................. lnx_20180510
Description ....... MKLDNNPlugin
[ INFO ] Loading network files:
/home/xxxx/openvino_models/ir/FP32/googlenet-v4/googlenet-v4.xml
/home/xxxx/openvino_models/ir/FP32/googlenet-v4/googlenet-v4.bin
[ INFO ] Preparing input blobs
[ WARNING ] Image is resized from (787, 259) to (299, 299)
[ INFO ] Batch size is 1
[ INFO ] Preparing output blobs
[ INFO ] Loading model to the plugin
[ INFO ] Starting inference (1 iterations)
[ INFO ] Processing output blobs
Top 10 results:
Image /opt/intel/computer_vision_sdk/deployment_tools/demo/car.png
817 0.2654692 label #817
511 0.1985555 label #511
436 0.1777671 label #436
581 0.0727099 label #581
479 0.0657209 label #479
627 0.0134304 label #627
656 0.0092363 label #656
468 0.0081523 label #468
717 0.0060212 label #717
751 0.0041756 label #751
total inference time: 214.2507583
Average running time of one iteration: 214.2507583 ms
Throughput: 4.6674281 FPS
[ INFO ] Execution successful
ラベル番号で出力されるのでわかりずらいですね。
ラベルファイルが用意されているので、それをコピーすると認識した候補が表示されます。
ラベルファイルは、インストールディレクトリのdemoフォルダにあります。
/opt/intel/computer_vision_sdk/deployment_tools/demo/squeezenet1.1.labels
これを、IRのフォルダーにコピーします。その際に、拡張子を除くファイル名をIRファイルと同じにします。
$ cp /opt/intel/computer_vision_sdk/deployment_tools/demo/squeezenet1.1.labels ~/openvino_models/ir/FP32/googlenet-v4/googlenet-v4.labels
$ ./classification_sample -m ~/openvino_models/ir/FP32/googlenet-v4/googlenet-v4.xml -i /opt/intel/computer_vision_sdk/deployment_tools/demo/car.png
[ INFO ] InferenceEngine:
API version ............ 1.2
Build .................. 13911
[ INFO ] Parsing input parameters
[ INFO ] Loading plugin
API version ............ 1.2
Build .................. lnx_20180510
Description ....... MKLDNNPlugin
[ INFO ] Loading network files:
/home/xxxx/openvino_models/ir/FP32/googlenet-v4/googlenet-v4.xml
/home/xxxx/openvino_models/ir/FP32/googlenet-v4/googlenet-v4.bin
[ INFO ] Preparing input blobs
[ WARNING ] Image is resized from (787, 259) to (299, 299)
[ INFO ] Batch size is 1
[ INFO ] Preparing output blobs
[ INFO ] Loading model to the plugin
[ INFO ] Starting inference (1 iterations)
[ INFO ] Processing output blobs
Top 10 results:
Image /opt/intel/computer_vision_sdk/deployment_tools/demo/car.png
817 0.2654692 label sports car, sport car
511 0.1985555 label convertible
436 0.1777671 label beach wagon, station wagon, wagon, estate car, beach waggon, station waggon, waggon
581 0.0727099 label grille, radiator grille
479 0.0657209 label car wheel
627 0.0134304 label limousine, limo
656 0.0092363 label minivan
468 0.0081523 label cab, hack, taxi, taxicab
717 0.0060212 label pickup, pickup truck
751 0.0041756 label racer, race car, racing car
total inference time: 305.9048653
Average running time of one iteration: 305.9048653 ms
Throughput: 3.2689902 FPS
[ INFO ] Execution successful
これでわかりやすくなりました。
ちゃんとスポーツカーとして認識されていますね。いろいろな画像を読ませて、正しく識別するか試してみましょう。
サンプルの使い方を理解したところで、次ぎはPythonで画像を入力して推論を行うコードを書いてみましょう。
AIを始めよう!PythonでOpenVINOの仕組みを理解する