元論文
Deep neural networks are easily fooled High confidence predictions for unrecognizable images
DNN の中身を知るために,人間には理解できないが 99% 以上の confidence で DNN に分類させる画像を生成したという内容.
例えば以下のようになるようだ.

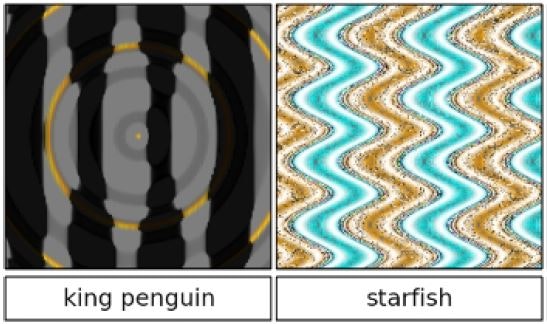
(論文から引用)
この fooling image を generating model に対しても生成してみる.
ふつうのキャプション生成例
こんなかんじ

馬の画像を入れるとこのようなキャプションがでてくる.馬のようなものが2匹見えているらしい.
単語の出現確率から文の出現確率が計算される.出やすい文3つを表示している.
左の数字が小さいほどその画像に対してより適切な文であると判断している.
(実際には単語ごとのsoftmaxの対数の和の符号反転を単語数で割ったもの)
またピクセルの値をランダムにした画像を入れると次のような文が生成される.

一応文になっているが,数字が大きい,つまり画像に何があるのか判断できていないということ.
fooling image 生成結果
とりあえずうまく生成できた.


2枚生成させた.どちらも人間には何かわからず,機械は高い確率で馬に関する文を生成している.(=先の例よりも数字が小さい)
上:direct encoding,画像のピクセルを直接遺伝子としている
下:indirect encoding,ピクセル同士が何か相関を持っている
論文では indirect encoding のほうではきれいな模様ができており,アートとして展示したそうだが,てきとうに NN を作って相関を持たせただけではうまくいかなかった.(多分てきとうすぎた)
どうやった
ある1つの文の生成確率が高くなるように画像を進化させた.
てきとうに最初の例で生成されてた文の1番上の
"a couple of horses are standing in a field"
を選び,この文の生成確率が高くなるように画像を進化させていった.
毎回8つ新しい個体が生成され8つ優れた個体を残すようにし,direct encoding では300世代程度でこのような結果となった.
生成モデルについて
今回はキャプション生成モデル Show, Attend and Tell に対して fooling image の生成を行った.
モデルの COCO に対する BLEU値は 0.689/0.503/0.359/0.255 だった.
まとめ
進化的アルゴリズムを使って生成モデルに対してある文の生成確率が高くなるような fooling image の生成に成功した.この画像は同じCNNで学習した他のモデルに対しても fooling できるのか,複数の文に対して進化させるとどうなるのか,気が向いたら試してみる.