はじめに
回帰分析とは
説明変数x(原因)が目的変数y (結果)に与える影響度合いを知るための方法。
説明変数xが一つしかない場合は単回帰分析で、複数ある場合は重回帰分析を用います。
回帰式の理論モデル
y = α + βx + u
目的変数 = 切片 + 傾き*説明変数 + 誤差項
Excelでも単回帰分析はできますが、今回は練習のためにPythonで検証してみました。
(参考資料を確認したり、大学の教授に指導をいただいた上で書いていますが、間違いがある可能性もあります。あれば指摘していただけるとありがたいです![]() )
)
単回帰分析
検証したいこと
今回は「中国、韓国、台湾、香港からの直行便数の増減が、どれだけ訪日客数に影響するか」を検証します。
目的変数は「アジア各国からの訪日客数」で、説明変数は「アジア各国からの直行便数」のみにします。直行便数以外に為替レートや自然災害、治安なども訪日客数の増減要因として考えられるため、検証には重回帰分析のほうが適していると思うのですが、それはまた次回検証したいと思います。
使用するデータ
- 国土交通省観光庁「宿泊旅行統計調査」2015~2018 (http://www.mlit.go.jp/kankocho/siryou/toukei/shukuhakutoukei.html)
- 国土交通省「国際線就航状況」2015~2018 夏ダイヤ、冬ダイヤ (https://www.mlit.go.jp/koku/koku_fr19_000005.html)
上記2つのデータをなんやかんやして以下のようなエクセルシートを作りました。
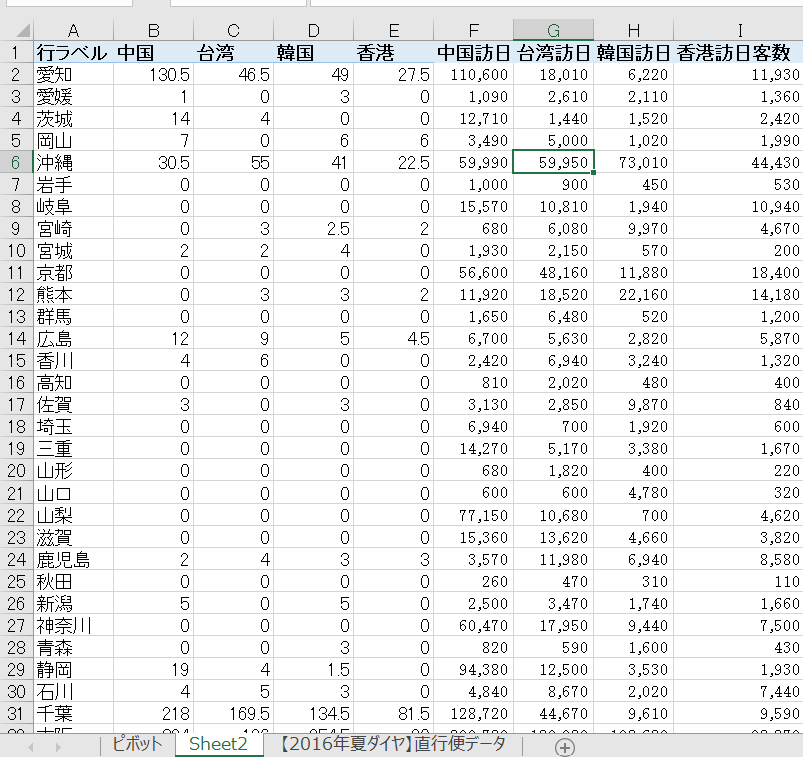
アジア各国からの直行便数と、訪日客数を都道府県ごとにまとめています。直行便が就航してない地域や、そもそも空港がない地域には0を入れています。
データの読み込みと変数作成
pandasを使ってデータを読み込み、データファイルに格納します。
xには直行便数、yには訪日客数を入れます。
import pandas as pd
df = pd.read_excel('2016_summer_original.xlsx', sheet_name='Sheet2', encoding='utf-8')
x = df[['韓国']]
y = df[['韓国訪日客数']]
scikit-learnで単回帰分析
scikit-learnを使って単回帰分析をしてmatplotlibでグラフにします。
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.linear_model import LinearRegression
## 回帰線を作図
model_lr = LinearRegression()
model_lr.fit(x, y)
plt.plot(x, y, 'o')
plt.plot(x, model_lr.predict(x), linestyle="solid")
plt.show()
ついでにstatsmodelで記述統計も作ります。
import statsmodels.api as sm
# 記述統計を表示
x_add_const = sm.add_constant(x)
model_sm = sm.OLS(y, x_add_const).fit()
print(model_sm.summary())
以下が実行結果です。瞬殺ですね![]()
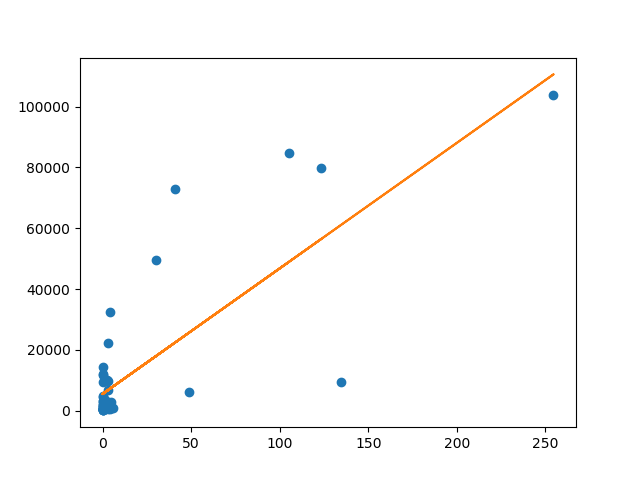
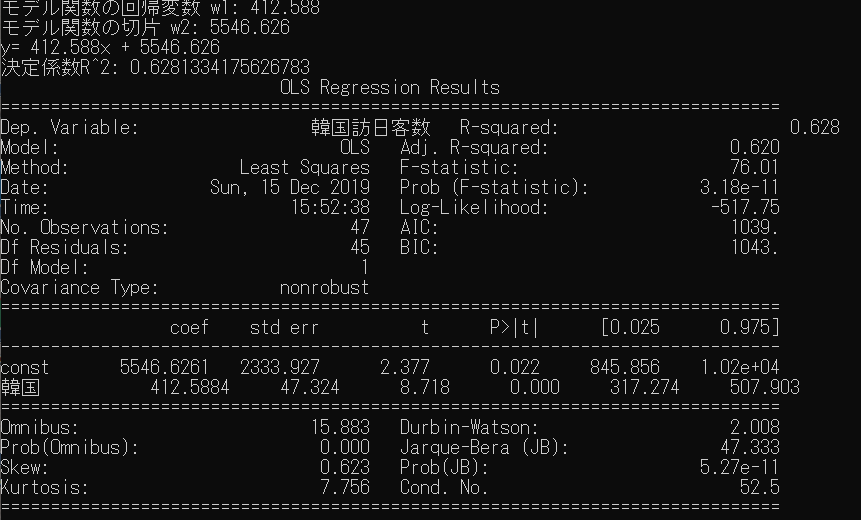
結果の解釈
2015年夏ダイヤの中国と香港の結果を比較してみてみます。
中国
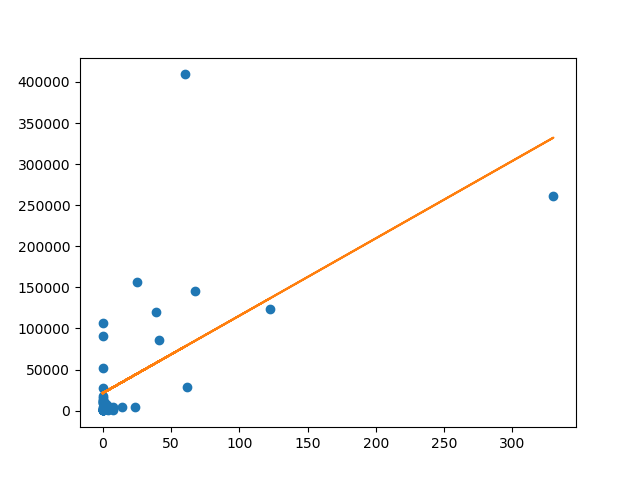
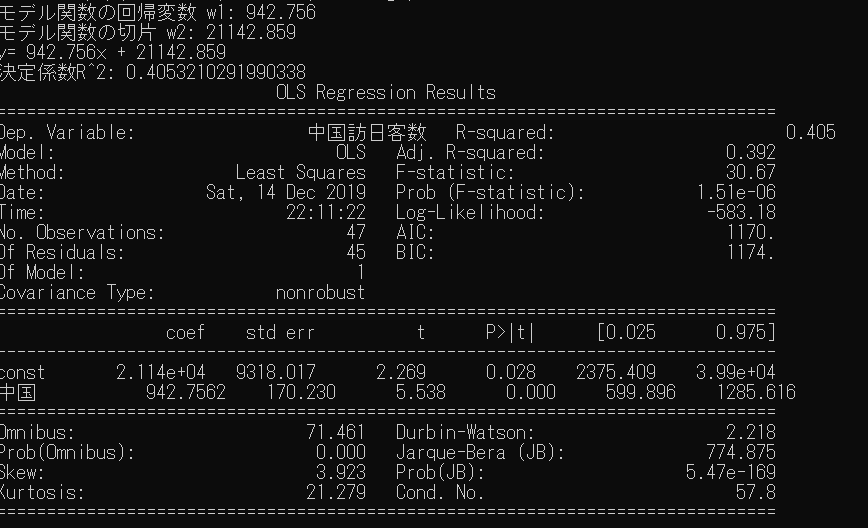
モデル:y = 942.76x + 21142.86
P>|t|:0.000
R-squared:0.405
香港
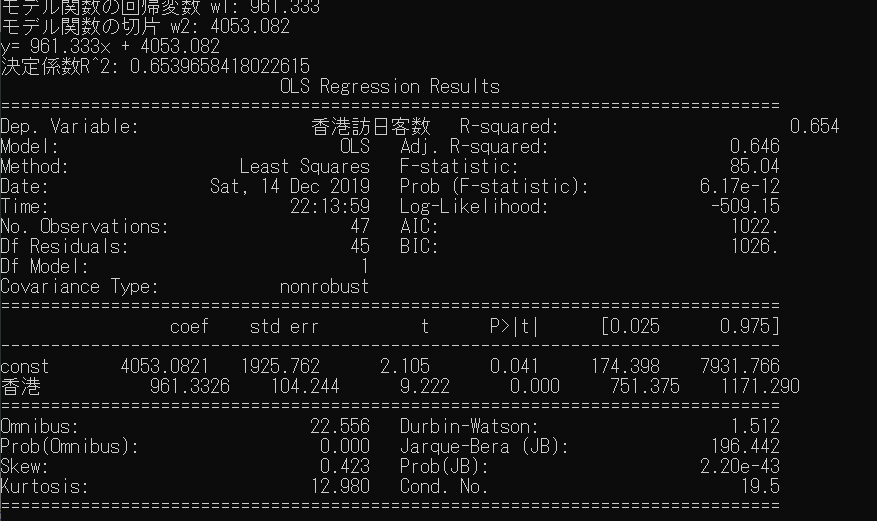
モデル:y = 961.33x + 4053.08
P>|t|:0.000
R-squared:0.654
分析結果の有意性や式の説明力は最低限、記述統計のP値とR2をみればよいと思います。
P値は帰無仮説(主張したい内容と逆の仮説)を棄却する確率です。5%を下回っていれば統計的に有意ということになります。
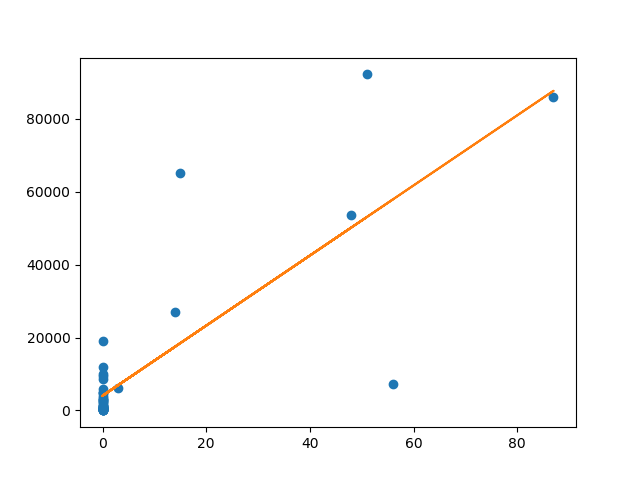
決定係数R2は推定された回帰線がどれだけ観測データにあてはまるかを測る指標です。値が1に近ければ近いほど良くあてはまっていることになります。上図でいえば、青い点がオレンジの線上に近ければあてはまりがよいということになります。
回帰モデルから、中国は直行便が一便増えるごとに943人増加するようです。P値が0なので結果は有意ですが、式の説明力が低めです。
一方で香港は一便増えるごとに961人増加し、有意性も式の説明力もあることがわかります。
さいごに
公表されている直行便のデータが2015年~2018年までなので、分析対象がデータが存在する期間のみに限られてしまうのと、月次データではないので連続した変化を分析することができなかったのが残念でした。メインではないので記事中では触れていませんが、今回は分析よりもデータ集めと前処理のほうが大変でした![]()
次回は重回帰分析で検証したいと思います。
参考資料
Pythonでデータ分析する方法を初心者向けに解説してみた
#1 Scikit-learnで単回帰分析を行う方法
単回帰分析の結果の見方【エクセルデータ分析ツール】【回帰分析シリーズ2】(動画)
栗原伸一・丸山敦史『統計学図鑑』オーム社