この記事では、PRMLの第13章で述べられている、隠れマルコフモデルに対するEMアルゴリズムでの最尤推定をPythonで実装します。
対応するjupyter notebookは筆者のgithubリポジトリにあります。連載全体の方針や、PRMLの他のアルゴリズムの実装については、連載のまとめページをご覧いただければと思います。
E stepでの導出がなかなか長い章ですが、この記事では最終的な結果だけを記すことにして、その後の実装に集中することにします1。
1 理論のおさらい
この章では、今までとは趣向を変えて、系列データ2を扱います。
1.1 設定
- $N \in \mathbb{N}$ : データ点の個数
- $X = (x_0, x_1, \dots, x_{N-1})$ : 観測データ。各データ点は、何か適当な集合に属するものとします3。
ここでは、$(x_0, x_1, \dots, x_{N-1})$は1つの時系列から得られたデータの列とします。
複数の時系列からなるデータを扱う場合は、以下のアルゴリズムはそのままでは適用できず、適宜修正する必要があります。
1.2 モデル
状態空間モデルでは、各観測データ点に対して、対応する潜在変数をおきます。
これが、モデルのパラメーターの個数を抑制しつつ、モデルの表現力を上げるための大事なポイントでしたね。
隠れマルコフモデルは、状態空間モデルの中でも、潜在変数の取りうる値が離散値となるものを指します。以下では、潜在変数の取りうる値は有限個とします4。
- $K \in \mathbb{N}$ : 潜在変数が取りうる値の個数。
- $Z = (z_0, z_1, \dots, z_{N-1})$ : 潜在変数。 $z_n \in \{ 0,1 \}^K$であり、$\sum_{k=0}^{K-1}z_{n,k} = 1$を満たすとします。
ここでは、$X$と$Z$の同時分布が次のように表されるモデルを用います:
$$
\begin{align}
p\left( X, Z \middle| \theta \right) =
p\left( z_0 \middle| \pi \right)
\left[ \prod_{n=1}^{N-1} p\left( z_n \middle| z_{n-1} , A\right) \right]
\left[ \prod_{n=0}^{N-1} p\left( x_n \middle| z_n, \phi \right) \right]
\end{align}
$$
ただし、
$$
\begin{align}
\theta &= \left( \pi, A, \phi \right) \
p\left( z_0 \middle| \pi \right) &= \prod_{k=0}^{K-1} \pi_{k}^{z_{0,k}} \
p\left( z_n \middle| z_{n-1}, A \right) &= \prod_{k=0}^{K-1} \prod_{j=0}^{K-1} A_{j,k} ^{z_{n-1,j} z_{n,k}} \
p\left( x_n \middle| z_n, \phi \right) &= \prod_{k=0}^{K-1} p(x_n | \phi_k)^{z_{n,k}}
\end{align}
$$
であり、更に、
- $\pi \in [0,1]^{K}$ : $\pi_k$は$z_{0,k}=1$である確率を表します(初期分布)。$\sum_{k=0}^{K-1} \pi_k = 1$と非負条件$\pi_k \geq 0$を満たします。
- $A = \left( A_{j,k} \right)_{j,k = 0,1,\dots, K-1}$ : $A_{j,k} = p(z_{n,k}=1 | z_{n-1,j}=1)$, i.e., $A_{j,k}$は潜在状態$j$から潜在状態$k$への遷移確率を表します。
- $\phi = \left( \phi_k \right)_{k=0,1, \dots, K-1}$ : 出力確率$p\left(x \middle| z, \phi \right)$のパラメーター.
とします。
以下では、このモデルを訓練するアルゴリズムの概要を述べます。
1.3 EMアルゴリズムによる最尤推定
ここでは、隠れマルコフモデルに対して最尤推定を行います。具体的には、
$$
\begin{align}
p(X|\theta) = \sum_{Z} p(X,Z|\theta)
\end{align}
$$
を最大化するような$\theta = (\pi, A, \phi)$を求めます。
ここでは、PRMLの通り、EMアルゴリズムを用いることにします5。
より具体的には、以下のような手続きで解を求めます:
- 入力 : $\theta_{ini}$, $X$.
- $\theta^{old} \leftarrow \theta_{ini}$
- while not converge
- E-step : $Q(\theta, \theta^{old}) := \sum_{Z} p \left( Z \middle| X,\theta^{old} \right) \log p(X,Z|\theta)$を$\theta$の函数として求める。
- M-step : $\theta_M$を、$Q(\theta, \theta^{old})$を最大化する$\theta$とし、$\theta^{old} \leftarrow \theta_M$と置く。
収束判定には、尤度函数の値を用いることにします。
1.3.1 E step
導出は省略しますが、隠れマルコフモデルに対して、$Q$は次のように表せます。
$$
\begin{align}
Q(\theta, \theta^{old}) &=
\sum_{k=0}^{K-1} \gamma_{0,k} \log \pi_k
{} + \sum_{n=1}^{N-1} \sum_{j,k=0}^{K-1} \xi_{n,j,k} \log A_{j,k}
{} + \sum_{n=0}^{N-1} \sum_{k=0}^{K-1} \gamma_{n,k} \log p(x_n | \phi_k) \
\gamma_{n,k} &:= p(z_{n,k}=1 | X, \theta^{old}) \ \ (n \geq 0) \
\xi_{n,j,k} &:= p(z_{n-1,j}=1 , z_{n,k}=1 | X, \theta^{old}) \ \ (n \geq 1)
\end{align}
$$
ここで、$\gamma$ and $\xi$は以下のように求めることができます(PRMLの13.2.2節と13.2.4節を参照)
$$
\begin{align}
\gamma_{n,k} &= \hat{\alpha}_{n,k} \hat{\beta}_{n,k} \
\hat{\alpha}_{n,k} &:= p(z_{n,k}=1 | x_0, \dots, x_n ) \
\hat{\beta}_{n,k} &:= \frac{p(x_{n+1}, \dots, x_{N-1} | z_{n,k} = 1)}{ p(x_{n+1}, \dots, x_{N-1} | x_0, \dots, x_n) } \ \ (n= 0, 1, \dots, N-2) \
\hat{\beta}_{N-1,k} &:= 1 \
\xi_{n,j,k} &= \frac{1}{c_n} \hat{\alpha}_{n-1,j} p(x_n|\phi_{k}^{old}) A_{j,k}^{old} \hat{\beta}_{n,k}
\end{align}
$$
また、$\hat{\alpha}$と$\hat{\beta}$は以下のように帰納的に求めることができます:
$$
\begin{align}
\hat\alpha_{0,k} &= \frac{\pi_k p(x_0 | \phi_{k}^{old})}{ \sum_{j=0}^{K-1}\pi_j p(x_0 | \phi_{j}^{old}) } \
c_0 &= \sum_{j=0}^{K-1}\pi_j p(x_0 | \phi_{j}^{old}) \
c_n \hat\alpha_{n,k} &= p(x_n | \phi_{k}^{old}) \sum_{j=0}^{K-1} \hat\alpha_{n-1,j} A_{j,k}^{old} \
c_{n+1} \hat\beta_{n,k} &= \sum_{j=0}^{K-1} \hat\beta_{n+1,j} p(x_{n+1}|\phi_{j}^{old}) A_{k,j}^{old} \
\hat\beta_{N-1,k} &= 1
\end{align}
$$
ただし、$c_n$については、$\hat{\alpha}$の規格化条件$\sum_{k=0}^{K-1} \hat{\alpha}_{n,k} = 1$から定まることに注意。
1.3.2 M step
E-stepで導出した$Q$を最大化する$\pi, A$は以下の通りに与えられます6。
$$
\begin{align}
\pi_k &= \frac{\gamma_{0,k}}{\sum_{j=0}^{K-1} \gamma_{0,j}} \
A_{j,k} &= \frac{ \sum_{n=1}^{N-1} \xi_{n,j,k} }{ \sum_{n=1}^{N-1} \sum_{l=0}^{K-1} \xi_{n,j,l} }
\end{align}
$$
$\phi$についての最大化は出力確率の具体的な形に依存します。
ここでは具体例として、出力確率がベルヌーイ分布になる場合を考えてみましょう:
$$
\begin{align}
p(x|\phi_k) = \phi_{k}^{x} \left( 1 - \phi_{k} \right)^{1-x}
\end{align}
$$
ただし、$x \in { 0,1 }$であり、$\phi_k \in [0,1]$とします。
この形の出力確率に対しては、
$$
\begin{align}
\phi_k = \frac{ \sum_{n=0}^{N-1} \gamma_{n,k} x_n }{ \sum_{n=0}^{N-1} \gamma_{n,k}}
\end{align}
$$
がM stepの解となります。
1.3.3 尤度
最後に、尤度は
$$
\begin{align}
p(X) = \prod_{n=0}^{N-1} c_n
\end{align}
$$
で与えられます7。
収束判定にあたって、この値(正確にはその対数の値)を利用することにします。
2 数式からコードへ
では、以上の結果をコードに翻訳し、隠れマルコフモデルを実装していきましょう。
ここでは、隠れマルコフモデルを表すHMMというクラスを定義するという方式で実装を行います。
また、具体的な出力確率としては、上でも例として述べた、ベルヌーイ分布を取ります。
$$
\begin{align}
p(x|\phi_k) = \phi_{k}^{x} \left( 1 - \phi_{k} \right)^{1-x}
\end{align}
$$
従って、観測変数は0, 1のいずれかであると仮定します。
なお、この例では観測変数は1次元ですが、scikit-learnの慣例に従い、データを表す配列$X$は、(データ数, データの次元)の形だとします。
また、以下のコードでは、$\hat{\alpha}, \hat{\beta}$をalpha, betaでそれぞれ表すことにします8。
2.1 概要
HMMクラスには、以下のデータ属性とメソッドを持たせることにします。
データ属性
-
K: $K$, i.e., 潜在要素の個数を表す整数。 -
pi: $\pi$, i.e., 初期分布を表す(K,)配列。 -
A: $A$, i.e., 遷移行列を表す(K, K)配列。 -
phi: $\phi$, i.e., 出力確率のパラメーター。ここでは上記の形のベルヌイー分布を用いるので、$(K,)$配列。
メソッド
基本的にはfittingとprediction(与えられたデータに対して対応する潜在変数を予測する)を行わせたいのですが、fittingの部分は複雑なので、いくつかの部分に分割します。特に、前節で述べたE stepを複数のメソッドに分割します。
-
_init_params: EMアルゴリズムを走らせる前に、パラメーターpi, A, phiを初期化します。(1)手で初期値を指定する、(2)手でrandom seedを指定して初期化する、(3)何も指定せずランダムに初期化する、の3つの方法が取れるようにしておきます9。 -
_calc_pmatrix: 出力確率の値を表す2次元配列pmatrix[n, k]= $p(x_n | \phi_k)$を計算して返します。この値をE stepのforward/backward processで利用します。 -
_forward: forward processの計算を実行し、alphaとc(規格化定数)を返します。 -
_backward: backward processの計算を実行し、betaを返します。 -
_estep:gammaとxiをalpha,beta,cなどの入力から計算し、返します10。 -
_mstep: E stepの結果を利用し、パラメーターpi, A, phiの更新を行います。 -
fit: 以上のメソッドを組み合わせて、EMアルゴリズムによる学習を行います。収束判定には対数尤度の値を用いることにします。 -
predict_proba: 与えられた観測変数のデータに対し、それぞれに対応する潜在変数がどのクラスに属するかの確率を返します。 -
predict: 与えられた観測変数のデータに対し、それぞれに対応する潜在変数が属するクラスを返します。
2.2 配列について
今回は基本的には数式を愚直に翻訳するだけなので、配列の定義についてだけ軽く触れたいと思います。
Xを与えられた観測変数のデータとしたとき、計算に用いる配列を以下のように定めます。
-
alpha:(len(X), self.K)配列。alpha[n,k]= $\hat{\alpha}_{n, k}$です。 -
beta:(len(X), self.K)配列。beta[n,k]= $\hat{\beta}_{n, k}$です。 -
gamma:(len(X), self.K)配列。gamma[n,k]= $\gamma_{n, k}$です。 -
xi: これはやや変則的です。$\xi$の定義$\xi_{n,j,k} := p(z_{n-1,j}=1 , z_{n,k}=1 | X, \theta^{old})$は$n \geq 1$でのみ有効なので、本来は$n = 1, \dots, N-1$の$N-1$個しか要素がありません。ただし、配列の添え字と数式の添え字が一致しないのは気持ち悪いなと考えたので、無理矢理$N$個定義することにしました。具体的には、xiは(N, self.K, self.K)配列で、$n \geq 1$に対してはxi[n, j, k]= $\xi_{n, j, k}$とし、$n=0$に対しては$\xi$の計算式$\xi_{n,j,k} = \frac{1}{c_n} \hat{\alpha}_{n-1,j} p(x_n|\phi_{k}^{old}) A_{j,k}^{old}$を無理矢理適用したものとします11。結局のところxi[0]は使わないので、全て0でも何でも良いのですが、np.rollを利用して一括して計算するためにこうしておきました。
2.3 コード
以上を踏まえて、次のようなコードでHMMクラスを実装しました。
class HMM:
def __init__(self, K):
self.K = K
self.pi = None
self.A = None
self.phi = None
def _init_params(self, pi=None, A=None, phi=None, seed_pi=None, seed_A=None, seed_phi=None):
'''
Initializes parameters pi, A, phi for EM algorithm
'''
self.pi = pi if (pi is not None) else np.random.RandomState(seed=seed_pi).dirichlet(alpha=np.ones(self.K))
self.A = A if (A is not None) else np.random.RandomState(seed=seed_A).dirichlet(alpha=np.ones(self.K), size=self.K)
self.phi = phi if (phi is not None) else np.random.RandomState(seed=seed_phi).rand(self.K) # emissoin probability dependent
def _calc_pmatrix(self, X):
'''
Calculates a 2D array pmatrix (pmatrix[n, k] = $p (x_n | \phi_k)$) for E step.
Parameters
----------
X : 2D numpy array
2D numpy array representing input data, where X[n, i] represents the i-th element of n-th point in X.
Returns
----------
pmatrix : 2D numpy array
(len(X), self.K) numpy array
'''
pmatrix = (self.phi**X) * ((1-self.phi)**(1-X)) # emissoin probability dependent
return pmatrix
def _forward(self, pmatrix):
'''
Performs forward process and returns alpha and c (the normalization constant)
Parameters
----------
pmatrix : 2D numpy array
(N, self.K) numpy array, where pmatrix[n, k] = $p (x_n | \phi_k)$
Returns
----------
alpha : 2D numpy array
(N, self.K) numpy array
c : 1D numpy array
(N,) numpy array
'''
N = len(pmatrix)
alpha = np.zeros((N, self.K))
c = np.zeros(N)
tmp = self.pi * pmatrix[0]
c[0] = np.sum(tmp)
alpha[0] = tmp / c[0]
for n in range(1, N, 1):
tmp = pmatrix[n] * ( (self.A).T @ alpha[n-1] )
c[n] = np.sum(tmp)
alpha[n] = tmp / c[n]
return alpha, c
def _backward(self, pmatrix, c):
'''
Performs backward process and returns beta
Parameters
----------
pmatrix : 2D numpy array
(N, self.K) numpy array
c : 1D numpy array
(N,) numpy array
Returns
----------
beta : 2D numpy array
(N, self.K) numpy array
'''
N = len(pmatrix)
beta = np.zeros((N, self.K))
beta[N - 1] = np.ones(self.K)
for n in range(N-2, -1, -1):
beta[n] = self.A @ ( beta[n+1] * pmatrix[n+1] ) / c[n+1]
return beta
def _estep(self, pmatrix, alpha, beta, c):
'''
Calculates and returns gamma and xi from the inputs including alpha, beta and c
Parameters
----------
pmatrix : 2D numpy array
(N, self.K) numpy array
alpha : 2D numpy array
(N, self.K) numpy array
beta : 2D numpy array
(N, self.K) numpy array
c : 1D numpy array
(N,) numpy array
Returns
----------
gamma : 2D numpy array
(N, self.K) array
xi : 3D numpy array
(N, self.K, self.K) array. Note that xi[0] is meaningless.
'''
gamma = alpha * beta
xi = np.roll(alpha, shift=1, axis=0).reshape(N, self.K, 1) * np.einsum( "jk,nk->njk", self.A, pmatrix * beta) / np.reshape( c, (N, 1,1))
return gamma, xi
def _mstep(self, X, gamma, xi):
'''
Performs M step, i.e., updates parameters pi, A, phi, using the result of E step
Parameters
----------
X : 2D numpy array
2D numpy array representing input data, where X[n, i] represents the i-th element of n-th point in X.
gamma : 2D numpy array
(N, self.K) array
xi : 3D numpy array
(N, self.K, self.K) array
'''
self.pi = gamma[0] / np.sum(gamma[0])
xitmp = np.sum(xi[1:], axis=0)
self.A = xitmp / np.reshape(np.sum(xitmp, axis=1) , (self.K, 1))
self.phi = (gamma.T @ X[:,0]) / np.sum(gamma, axis=0)
def fit(self, X, max_iter=1000, tol=1e-3, **kwargs):
'''
Performs fitting with EM algorithm
Parameters
----------
X : 2D numpy array
2D numpy array representing input data, where X[n, i] represents the i-th element of n-th point in X.
max_iter : positive int
The maximum number of iteration allowed
tol : positive float
Threshold for termination of iteration.
'''
self._init_params(**kwargs)
log_likelihood = -np.inf
for i in range(max_iter):
pmatrix = self._calc_pmatrix(X)
alpha, c = self._forward(pmatrix)
beta = self._backward(pmatrix, c)
gamma, xi = self._estep(pmatrix, alpha, beta, c)
self._mstep(X, gamma, xi)
log_likelihood_prev = log_likelihood
log_likelihood = np.sum(np.log(c))
if abs(log_likelihood - log_likelihood_prev) < tol:
break
print(f"The number of iteration : {i}")
print(f"Converged : {i < max_iter - 1}")
print(f"log likelihood : {log_likelihood}")
def predict_proba(self, X):
'''
Calculates and returns the probability that latent variables corresponding to the input X are in each class.
Parameters
----------
X : 2D numpy array
2D numpy array representing input data, where X[n, i] represents the i-th element of n-th point in X.
Returns
----------
gamma : 2D numpy array
(len(X), self.K) numpy array, where gamma[n, k] represents the probability that
the lantent variable corresponding to the n-th sample of X belongs to the k-th class.
'''
pmatrix = self._calc_pmatrix(X)
alpha, c = self._forward(pmatrix)
beta = self._backward(pmatrix, c)
gamma = alpha * beta
return gamma
def predict(self, X):
'''
Calculates and returns which classes the latent variables corresponding to the input X are in.
Parameters
----------
X : 2D numpy array
2D numpy array representing input data, where X[n, i] represents the i-th element of n-th point in X.
Returns
----------
pred : 2D numpy array
(len(X), self.K) numpy array, where gamma[n, k] represents the probability that
the lantent variable corresponding to the n-th sample of X belongs to the k-th class.
'''
pred = self.predict_proba(X).argmax(axis=1)
return pred
3 実験
では、以上で実装したHMMクラスを実際に動かしてみましょう。
3.1 データ
ここでは、非常に単純なトイデータを用います。具体的には、「2つの状態を持つコインのコイントスの結果」とでも呼べるようなデータを用います。
- コインは$0, 1$の2つの状態を持つとします。状態$j$では、コインは確率$\mu_j$で1を出力し、確率$1- \mu_j$で0を出力するとします。この出力が観測変数です。
- 各コイントスの後、確率
tpでコインは状態を変えるとします。
読んで分かるとおり、観測変数のデータは、隠れマルコフモデルから出力されています12。具体的にコードで書くと、以下の通りです:
N = 200 # the number of data
# Here we consider a heavily biased coin.
mu0 = 0.1
mu1 = 0.8
tp = 0.03 # transition probability
rv_cointoss = np.random.RandomState(seed=0).rand(N)
rv_transition = np.random.RandomState(seed=1).rand(N)
X = np.zeros((N, 1))
states = np.zeros(N)
current_state = 0
for n in range(N):
states[n] = current_state
if rv_cointoss[n] < mu0*(int(not(current_state))) + mu1*current_state:
X[n][0] = 1.0
if rv_transition[n] < tp:
current_state = int(not(current_state))
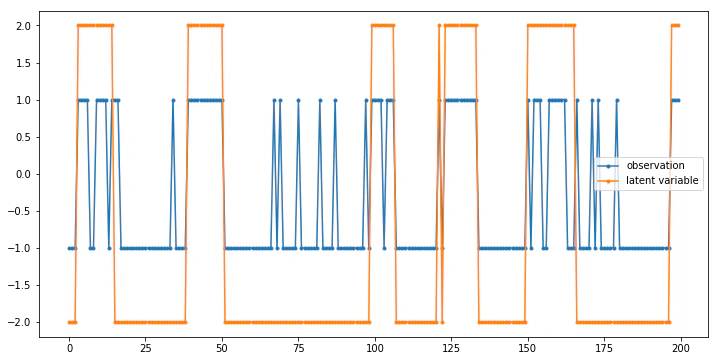
あんまり美しくないのですが、これを無理矢理図示したのが以下の図です。重ならないように適当にスケールしましたが、0,1の大小関係はそのままになるようにしてあります。
状態0のときは0が多く出力され、状態1のときは1が多く出力されていることが見て取れます。
3.2 学習とその結果
では、このデータに対してHMMクラスを適用してみましょう。今回はやや自明なのですが、$K=2$とします。
得られたパラメーターは以下の通りです:
pi : [1.01243169e-11 1.00000000e+00]
A : [[0.87599792 0.12400208]
[0.06322307 0.93677693]]
phi : [0.87238852 0.08079113]
piとphiの値からも分かるかと思いますが、データの生成に利用した潜在変数と、学習で得られた潜在変数のラベルは逆になっています13。
そのことに留意しつつパラメーターの値を見ると、異なる状態の間の遷移は稀で、片方の状態はより0を出しやすく、もう片方の状態は逆であることが、適切に学習できています。
最後に、比較のために「実際の潜在変数の値14」と「モデルの潜在状態0にいる確率」をプロットして比較してみましょう15。
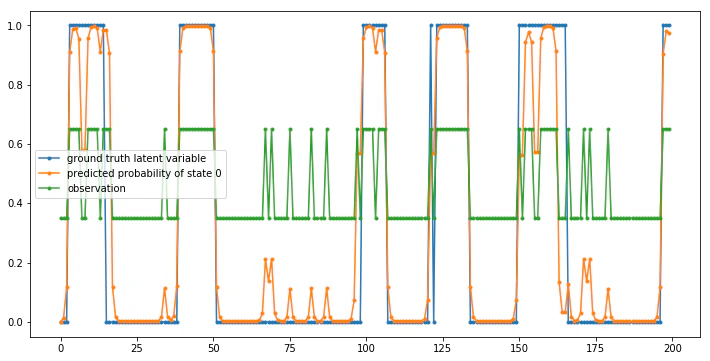
実際の潜在変数の値と、モデルの予測がよく符合していることが見て取れるかと思います。また、予測確率が時々スパイクのような振る舞いを見せる箇所は、コインが「例外的な」振る舞いをしている箇所と一致することも分かるかと思います。
4 まとめ
この記事では、隠れマルコフモデルと、そのEMアルゴリズムによる最尤推定を実装しました。
今までの章とは違い、独立同分布ではなく系列データを扱ったので、PRML本体では数式の導出はなかなか技巧的なところもありました。ただ、結果をありがたく使わせていただく分にはシンプルに実装を行うことができました。
今回は隠れマルコフモデルそのものから生成したトイデータしか扱いませんでしたが、実際のデータに適用して遊んでみたいとも考えています。
また、隠れマルコフモデルはscikit-learnでは実装されていないのですが(正確には、かつてはscikit-learnの一部にあった16のが分離して)、hmmlearnというライブラリがあります。実データで遊ぶときは、このライブラリも試してみたいと思います。
-
とはいえ、モデルのグラフ構造を利用したforward/backward processや、数値的安定性のためのスケーリングなど、読んでて「頭良いなー」と思えて非常に楽しいので、ぜひぜひきちんと読まれることをお勧めします。白状すると私はグラフィカルモデルの話はきちんと理解できいないので、13.2.3節なんかは飛ばしていますが。。。 ↩
-
手が滑って「時系列データ」と書きかけました。ですが、13章の冒頭でも述べられているように、文書やDNAの塩基配列なども系列データで、「時系列」に限定されるわけではないですね。要注意。。。 ↩
-
$d$次元Euclid空間など。 ↩
-
可算無限の場合はどうなるんでしょうか。 ↩
-
EMアルゴリズムを使う理由としては、「混合モデルの一般化に相当するので、最尤推定の解析解が得られない。」「潜在変数についての和を陽にとることが計算量の観点から困難。」などがPRMLでは挙げられていました。 ↩
-
規格化条件をLagrangeの未定乗数法を用いて取り込めば容易。非負条件は解が非負性を満たすことから後付けで確認するということで良いんでしょうか。 ↩
-
この尤度の表式は、あくまで$\theta^{old}$に対するものです。収束判定にはあまり大きく影響しないとは思いますが。。。 ↩
-
$\hat{}$なしの$\alpha$と$\beta$は使わないので。 ↩
-
実験の再現性を担保するため。 ↩
-
本当はfoward/backward processまで含めてE stepなので名前の付け方がよろしくないかもしれません。。。 ↩
-
具体的には、先ほどの計算式で$n=0$とおき、$\hat{\alpha}{-1, j} := \hat{\alpha}{N-1,j}$としたものにします。 ↩
-
もちろん実データではこんなことはないのですが、ここではあくまでトイデータとして生成しました。 ↩
-
潜在変数が有限個の値しかとりえないとき、モデルはそれらのラベルの入れ換えに対して不変です。従って、ラベルの値そのものには特に意味はありません。 ↩
-
繰り返しになりますが、実データではデータが隠れマルコフモデルから生成されるなんてことはないので、「実際の潜在変数の値」は必ずしも定義されているとは限りません。ただ、応用によっては潜在変数が自然な解釈を持つ例も多々あるかと思います。 ↩
-
ここ、ややこしいのですが、今の例の場合だと「モデルの潜在状態0にいる確率」=「元の生成に用いた過程での潜在状態1にいる確率」です。 ↩
-
詳細はこちらなどを参照 http://scikit-learn.sourceforge.net/stable/modules/hmm.html ↩