この記事では、PRMLの第14章の、BaggingとAdaBoostをPythonで実装します。この章までは1つ1つの分類器を扱ってきましたが、この章で扱うのは、複数のモデルを組み合わせるアンサンブル学習の手法です。
対応するjupyter notebookは筆者のgithubリポジトリにあります。連載全体の方針や、PRMLの他のアルゴリズムの実装については、連載のまとめページをご覧いただければと思います。
1 理論のおさらい
1.1 設定
ここでは、2値分類問題を考えます。
- $N \in \mathbb{N}$ : データの個数
- $D \in \mathbb{N}$ : 各データ点の次元
- $X = (x_0, x_1, \dots, x_{N-1})$ : データ点。$x_n \in \mathbb{R}^D$とします。
- $t = (t_0, t_1, \dots, t_{N-1})$ : the target labels. 2値分類を考え、$t_n \in \{ 1, -1 \}$とします。
- $y : \mathbb{R}^D \times \Theta \rightarrow \{1, -1\}$ : 2値分類器。ここで、$\Theta$はパラメーターの空間とします.
この設定に対し、「弱い」ベース分類器を上手く組み合わせることで、「強い」分類器を得るというアプローチを論じていきます。
- 1.2節では「弱い」ベース分類器として非常に単純な決定株を考えます。
- 1.3節では、複数の分類器を組み合わせる簡単な手法の1つとして、Baggingについて述べます。
- 1.4節では、Baggingよりも進んだ分類器の組合せ方として、AdaBoostについて論じます。
1.2 決定株
まず、非常に単純な分類器として、決定株(Decision stump)1 を定義しておきます。
ベース分類器として他のアルゴリズムを用いても良いのですが、これについては後でAdaBoostの節で述べたいと思います。
1.2.1 定義
決定株を以下のように定義(?)します2。
パラメーター$\theta = (d, a, s) \in \{ 0,1, \dots, D-1 \} \times \mathbb{R} \times \{ 1, -1 \} $で定められた分類器$y : \mathbb{R}^D \times \Theta \rightarrow \{ 1, -1 \}$で、次のような予測値を返すもの
$$
\begin{align}
y(x, (d,a,s)) =
\begin{cases}
s & (x^{(d)} \geq a ) \
-s & (x^{(d)} < a)
\end{cases}
\end{align}
$$
ただし、$x \in \mathbb{R}^D$であり、$x^{(d)}$は$x$の$d$番目の成分を指すとします。
換言すると、決定株$y(\cdot, (d,a,s))$は入力の第$d$成分のみに着目し、その値が閾値$a$以上かどうかのみに基づいて分類を行います。
1.2.2 学習
決定株に学習にあたっては、以下の損失函数を最小化するパラメーターを選びます。
$$
\begin{align}
\sum_{n=0}^{N-1} w_n I\left[ y(x_n, \theta) \neq t_n \right],
\end{align}
$$
ただし、$w_n$は学習データ点にかける重みを表し、後でアルゴリズムの詳細に応じて決めます。特に指定がない限りは$w_n = 1$を念頭においています。
さて、上記の最小化ですが、実質的には有限個($2D(N-1)$個)の候補の中から解を選べばよいことが分かります。なぜなら
- 符合$s$の選び方が2通り、
- 着目する軸$d$の選び方が$D$通り、
- 閾値$a$を、$N$個あるデータ点のどの2つの間に置くかの$N-1$通り、
あるからです。
3番目の閾値について補足します:実際は$a$の選び方は連続無限個あるのですが、ここでは$a$を、2つの隣り合う$x$の第$d$成分の平均に限ります。こう限定しても、損失函数の値には影響しません3。また、訓練データには必ず異なるクラスのデータ点が含まれると仮定します。
後の実装では、この$2D(N-1)$通りの候補の中から全探索を行います。
1.3 Bagging
baggingの基本的なアイデアは、$M$個の分類器をそれぞれ「異なる」訓練データに対して学習させ、その平均を取ることで予測を行うことです。といっても、実際は我々は1通りの訓練データしか持っていません。そこで、Baggingでは、元の訓練データから$N$個4の点を(重複を許して)サンプルし、これを新しい「訓練データ」として、各分類器の学習に用います。
Baggingは、決定株に限らず、他の分類器でも用いることができます。
1.3.1 学習
$m = 0,1, \dots, M-1$に対して、
- $N$個のデータ点を$(X,T)$から重複を許してサンプルします。
- $m$番目の分類器$y(\cdot, \theta_m)$をこの再サンプルしたデータを用いて訓練します。
1.3.2 予測
入力$x$に対して、
$$
\begin{align}
y_{bag}(x) = \mathrm{sign} \left[ \sum_{m=0}^{M-1} y(x, \theta_m) \right]
\end{align}
$$
を予測値とします5。
1.4 AdaBoost
AdaBoostでは、複数の学習器を用いることはBaggingと同様ですが、それぞれを独立に学習させるのではなく、前の学習の結果を後の学習の際に用います。
1.4.1 学習
- 入力 : 訓練データ$(X, T)$、ベース分類器$y$、分類器の個数$M$。
- 訓練データの重み$(w_0, w_1, \dots, w_{N-1})$を$w^{(0)}_{n} = 1/N$と初期化します。
- $m = 0, \dots, M-1$に対して:
- ベース分類器の学習:損失函数
$$
\begin{align}
\sum_{n=0}^{N-1} w^{(m)}_{n} I \left[ y(x_n, \theta_m) \neq t_n \right]
\end{align}
$$
を最小化する$\theta_m \in \Theta$を選びます。 - ベース分類器の誤差から得られる次の量を計算します:
$$
\begin{align}
\varepsilon_m &:= \sum_{n=0}^{N-1} w^{(m)}_{n} I \left[ y(x_n, \theta_m) \neq t_n \right] \
\alpha_m &:= \log \left(\frac{1 - \varepsilon_m}{\varepsilon_m} \right)
\end{align}
$$ - 前のステップで求めた$\alpha_m$を用いて、重みを
$$
\begin{align}
\tilde{w}^{(m+1)}_{n} &= w^{(m)}_{n} \exp\left\{ \alpha_m I \left[ y(x_n, \theta_m) \neq t_n \right] \right\} \
w^{(m+1)}_{n} &= \frac{\tilde{w}^{(m+1)}_{n}}{ \sum_{n'=0}^{N-1} \tilde{w}^{(m+1)}_{n'} }
\end{align}
$$
のように更新します。
- ベース分類器の学習:損失函数
いくつか注意:
- 重みは規格化してあります。そのため、$\varepsilon_m$の定義がPRMLの(14.16)式と一見異なりますが、値は同じものとなっています。
- 全ての$m$について$\varepsilon_m < \frac{1}{2}$であること(i.e., ベース分類器は一様ランダムよりはましであること)が暗に仮定されているかと思います6。
- 以下のコードでは、(形式的には)決定株以外のベース分類器を用いることもできます。しかし、その場合はベース分類器が最小化する損失函数は$\sum_{n=0}^{N-1} w^{(m)}_{n} I \left[ y(x_n, \theta_m) \neq t_n \right]$であるとは限りません。その場合に理論的な精度保証が成り立つのか、などといった点については私は理解できていません。。。7
1.4.2 予測
訓練が終われば、予測は非常に単純で、入力$x$に対する予測値は
$$
\begin{align}
\textrm{sign} \left[ \sum_{m=0}^{M-1} \alpha_m y(x, \theta_m) \right]
\end{align}
$$
で与えられます。
2 数式からコードへ
では、ここまでの数式をコードに起こしていきましょう。理論編と同じ順番で、DecisionStump、Bagging、AdaBoostの3つのクラスを実装していきます。ちなみに、DecisionStumpが一番面倒で、後の2つは比較的単純です。
BaggingクラスとAdaBoostクラスについては、fitとprecitのメソッドに加え、以下のデータ属性を持たせることにします:
-
BaseClassifierClass: ベース分類器を表すクラス。インスタンスではなく、クラスとして渡します。fit、predictメソッドを持つとし、特に、AdaBoostにおいては、BaseClassifierClassのfitはsample_weightを引数にとれると仮定します。 -
num_clfs: $M$, i.e., ベース分類器の個数。 -
clfs: ベース分類器を保存しておくためのリスト。
2.1 決定株
まず、決定株を表すDecisionStumpクラスを実装します。
このクラスには、axis($d$に対応)、 sign($s$に対応)、threshold($a$に対応)の3つのデータ属性持たせることにします。
また、fitとpredictのメソッドを持たせることにしますが、fitは以下の2段階に分割します:
- まず、
axisを固定した上でsignとthresholdの全探索を行います。この部分はfit_onedimという別のメソッドで行うことにします。 - 各
axisについての損失函数の値を比較し、最も小さい値を与えるaxisを採用します。
fit_onedimメソッドにおいては、計算をラクにするために、$X, T, w$は$X$の第$d$成分について昇順に整列されているとします。その上で、次のような配列を上手く利用して、損失函数を効率よく計算します:
-
pred: $(N-1, N)$配列。pred[m,n]= $y\left(x_n, \left(d, \frac{x_m + x_{m+1}}{2}, 1 \right) \right)$。整列してあるおかげで、np.triを用いて容易に生成することができます。 -
mistakes: $(N-1, N)$配列。mistakes[m,n]= $I \left[ y\left(x_n, \left(d, \frac{x_m + x_{m+1}}{2}, 1 \right) \right) \neq t_n\right] $ -
errs: $(2, N-1)$配列。ただし、-
errs[0,m]= $\sum_{n=0}^{N-1} w_n I \left[ y\left(x_n, \left(d, \frac{x_m + x_{m+1}}{2}, 1 \right) \right) \neq t_n\right] $ -
errs[1,m]= $\sum_{n=0}^{N-1} w_n I \left[ y\left(x_n, \left(d, \frac{x_m + x_{m+1}}{2}, -1 \right) \right) \neq t_n\right] $
-
これを踏まえて、以下のようなコードでDecisionStumpを定義します:
class DecisionStump:
def __init__(self, axis=None, sign=None, threshold=None):
self.axis = axis
self.sign = sign
self.threshold = threshold
def fit_onedim(self, X, y, sample_weight, axis):
'''
Performing exhaustive search on threshold and sign, where the axis to consider is given.
Parameters
----------
X : 2D numpy array
2D numpy array representing input data, where X[n, i] represents the i-th element of n-th point in X.
y : 1D numpy array
(len(X),) numpy array representing labels, where y[n] represents the label corresponding to n-th point in X.
Each element should be either 1 or -1
sample_weight : 1D numpy array
(len(X), ) numpy array representing the sample weights.
The elements should be non-negative.
axis : integer
A non-negative integer the axis to be considered.
Must be between 0 and X.shape(1)-1
Returns
----------
sign : int, 1 or -1
Integer representing the sign s for the (candidate) decision stump
threshold : float
Threshold a for the (candidate) decision stump
err : float
Training error for the (candidate) decision stump
'''
N = len(X)
# Here we sort everything according the axis-th coordinate of X
sort_ind = np.argsort(X[:, axis])
sorted_label = y[sort_ind]
sorted_input = X[sort_ind]
sorted_sample_weight = sample_weight[sort_ind]
pred = -2*np.tri(N-1, N, k=0, dtype='int') + 1
mistakes = (pred != sorted_label ).astype('int')
# The (weighted) error is calculated for each classifier
errs = np.zeros((2, N-1))
errs[0] = mistakes @ sorted_sample_weight
errs[1] = (1 - mistakes) @ sorted_sample_weight
# Here, we select the best threshold and sign
ind = np.unravel_index(np.argmin(errs, axis=None), errs.shape)
sign = -2*ind[0] + 1
threshold = ( sorted_input[ind[1], axis] + sorted_input[ind[1] + 1, axis] ) / 2
err = errs[ind]
return sign, threshold, err
def fit(self, X, y, sample_weight=None):
'''
Performing fitting by exhaustive search on threshold, sign, and axis.
Parameters
----------
X : 2D numpy array
2D numpy array representing input data, where X[n, i] represents the i-th element of n-th point in X.
y : 1D numpy array
(len(X),) numpy array representing labels, where y[n] represents the label corresponding to n-th point in X.
Each element should be either 1 or -1
sample_weight : 1D numpy array
(len(X), ) numpy array representing the sample weights.
The elements should be non-negative.
If None, the sample_weight is assumed to be uniform.
'''
N, D = X.shape
if sample_weight is None:
sample_weight = np.ones(N)/N
signs = np.zeros(D)
threshs = np.zeros(D)
errs = np.zeros(D)
for axis in range(D):
signs[axis], threshs[axis], errs[axis] = self.fit_onedim(X, y, sample_weight, axis)
self.axis = np.argmin(errs)
self.sign = signs[self.axis]
self.threshold = threshs[self.axis]
def predict(self, X):
'''
The method predicts the labels for the given input data X.
Parameters
----------
X : 2D numpy array
2D numpy array representing input data, where X[n, i] represents the i-th element of n-th point in X.
Returns
----------
y : 1D numpy array
(len(X),) numpy array representing the predicted labels, where y[n] represents the label corresponding to n-th point in X.
'''
return self.sign*( 2*(X[:, self.axis] >= self.threshold) - 1 )
2.2 Bagging
こちらは実装はstraightforwardですね。
ベース分類器としては決定株以外も使えるように書いてあります。
class Bagging:
def __init__(self, BaseClassifierClass, num_clfs):
self.BaseClassifierClass = BaseClassifierClass # base classifier class
self.num_clfs = num_clfs
self.clfs = [self.BaseClassifierClass() for _ in range(self.num_clfs)]
def fit(self, X, y):
'''
The method performs fitting by bagging using the given base classifier.
Parameters
----------
X : 2D numpy array
2D numpy array representing input data, where X[n, i] represents the i-th element of n-th point in X.
y : 1D numpy array
(len(X),) numpy array representing labels, where y[n] represents the label corresponding to n-th point in X.
Each element should be either 1 or -1
'''
N = len(X)
for m in range(self.num_clfs):
# resampling is performed here
sample_ind = np.random.randint(0, N, N)
X_resampled = X[sample_ind]
y_resampled = y[sample_ind]
# traing the classifier using the resampled training data
self.clfs[m].fit(X_resampled, y_resampled)
def predict(self, X):
'''
The method predicts the labels for the given input data X.
Parameters
----------
X : 2D numpy array
2D numpy array representing input data, where X[n, i] represents the i-th element of n-th point in X.
y : 1D numpy array
(len(X),) numpy array representing the predicted labels, where y[n] represents the label corresponding to n-th point in X.
'''
base_pred = np.zeros((self.num_clfs, len(X)))
for m in range(self.num_clfs):
base_pred[m] = self.clfs[m].predict(X)
return np.sign( np.sum(base_pred, axis = 0 ) )
2.3 AdaBoost
Baggingに引き続き、こちらも比較的straightforwardではないかと思います。$\alpha$を表す配列として、alphaをデータ属性として持たせてあります。
class AdaBoost:
def __init__(self, BaseClassifierClass, num_clfs):
self.BaseClassifierClass = BaseClassifierClass # base classifier class
self.num_clfs = num_clfs
self.alpha = np.zeros(self.num_clfs)
self.clfs = [self.BaseClassifierClass() for _ in range(self.num_clfs)]
def fit(self, X, y):
'''
The method performs fitting by AdaBoost using the given base classifier.
Parameters
----------
X : 2D numpy array
2D numpy array representing input data, where X[n, i] represents the i-th element of n-th point in X.
y : 1D numpy array
(len(X),) numpy array representing labels, where y[n] represents the label corresponding to n-th point in X.
Each element should be either 1 or -1
'''
N = len(X)
w = np.ones(N)/N # initialize the weight
for m in range(self.num_clfs):
self.clfs[m].fit(X, y, sample_weight = w)
mistakes = (self.clfs[m].predict(X) != y)
# calculate the epsilon and alpha
ep = np.sum ( w * mistakes)
self.alpha[m] = np.log(1.0/ep - 1)
# update the weight
w = w * np.exp( self.alpha[m] * mistakes )
w = w/np.sum(w)
def predict(self, X):
'''
The method predicts the labels for the given input data X.
Parameters
----------
X : 2D numpy array
2D numpy array representing input data, where X[n, i] represents the i-th element of n-th point in X.
y : 1D numpy array
(len(X),) numpy array representing the predicted labels, where y[n] represents the label corresponding to n-th point in X.
'''
base_pred = np.zeros((self.num_clfs, len(X)))
for m in range(self.num_clfs):
base_pred[m] = self.clfs[m].predict(X)
return np.sign( base_pred.T @ self.alpha )
3 実験
では、ここまで実装したコードを簡単なトイデータに適用してみましょう。
用いたデータはこちら:
sklearn.datasetsのmake_moonsで作った50点のデータです。
このデータに、決定株、決定株を用いたBagging、決定株を用いたAdaBoostを適用した結果を見てみましょう。BaggingとAdaBoostではそれぞれ、num_clfs = 100としてあります。
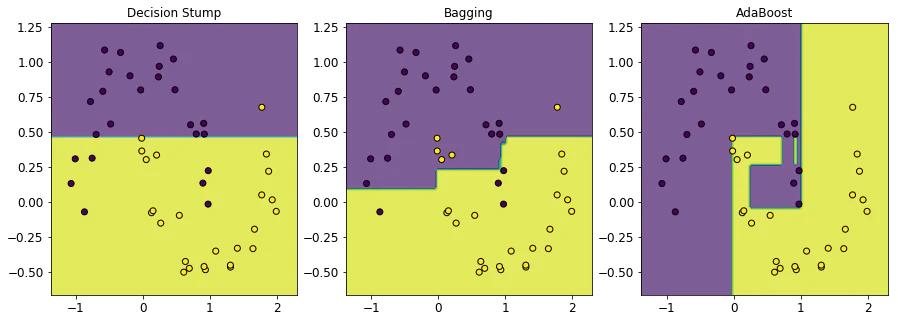
- 決定株は定義より明らかなように、軸に並行な決定境界を描いています。
- Baggingを用いた場合は、決定株に比べてやや複雑な決定境界を表すことができます8。
- AdaBoostの場合は、前の2つに比べ大幅に複雑な決定境界を表現できていることが見て取れるかと思います。
最後に、AdaBoostの$M$を変えたときの振る舞いを見ておきましょう。
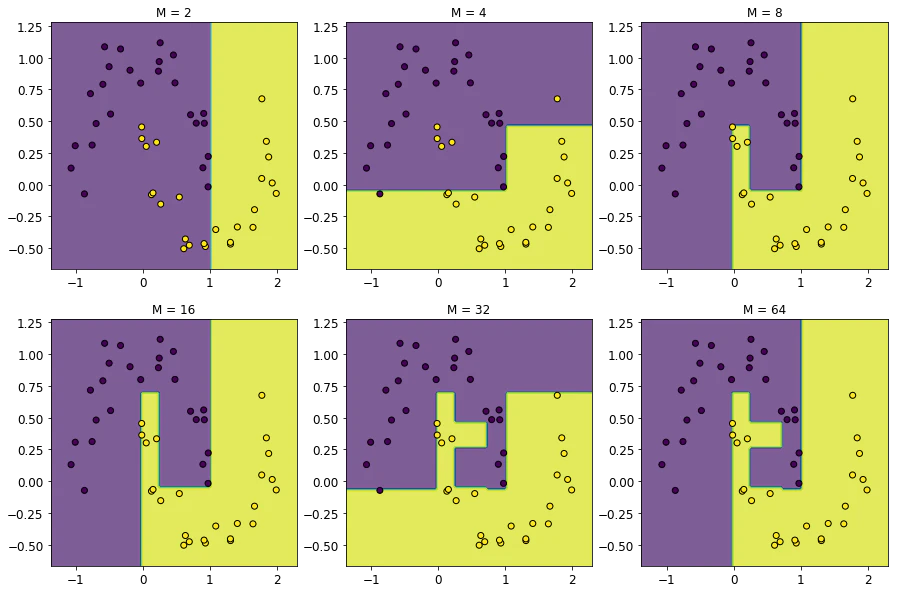
大雑把に言うと、$M$を増やすほど決定境界が複雑になることが見て取れるのではないかと思います。bias-varianceの言葉を用いると、$M$を増やすことはモデルのvarianceを高める効果があるとも言えます。
この振る舞いは、AdaBoostの元々の性質からすると直感的には自然なのではないかと思われます。というのも、AdaBoostにおいては、ベース分類器はその前のベース分類器の誤りを「訂正する」ように働くため、用いるベース分類器が多くなると、より「訂正」の機会が増えるからです。
4 まとめ
この記事では、決定株と、それを用いたBaggingとAdaBoostを実装しました。
決定株を効率的に実装するにあたっては、やや工夫がいりますが、BaggingとAdaBoostはかなりシンプルに実装できることを見ました。
また、実験では、
- 3者の実行結果を比較し、AdaBoostを用いることで、単純なベース分類器からより表現力の高い分類器を得られること9、
- AdaBoostのベース分類器の個数を変えることにより、bias-varianceのトレードオフを調整できること
を観察しました。
-
ノードが1つしかない決定木なので、決定「株」(stump)ということですね。 ↩
-
ゆるふわな定義ですが...。 ↩
-
汎化誤差には影響しますが、いずれにせよ訓練データからはどれを選ぶか決められないので、ここでは単純に中間点としておきます。 ↩
-
ここは別に元の訓練データのサイズ$N$と同じ個数である必然性は特にないのではないかと理解していますが、PRML1.2.3節のbootstrapの記述で$N$個の点をサンプルするとあったので、ここでもひとまず$N$個としておきます。 ↩
-
PRMLの式(14.7)は回帰についての式で、分類の場合は符合を取るか何かの変換をかける必要があります。なお、$1/M$のfactorは省いています(符合には効かないので。)。 ↩
-
$\varepsilon_m > 1/2$の場合は$\alpha_m < 0$となっていまい、「前の分類器が間違えたサンプルを強調する」というAdaBoostの本来の振る舞いに反する重みが与えられてしまいます。 ↩
-
そもそもAdaBoostの汎化誤差についてのきちんとした理論的解析を恥ずかしながら追っていません。。。 ↩
-
ただし、決定株と必ずしも大きく異なるとも限らず、データによっては決定株とほぼ同じ決定境界を描きます。また、サンプリングの結果に依存するので、この部分は完全な再現性は担保できていません。 ↩
-
本当は表現力という点だけでなく汎化性能という点でも評価すべきなのですが、きちんと理論的解析を追っていないため、今回は割愛します。 ↩