異常検知(またはoutlier detection、異常検出、外れ値検出)は、重要なデータ探索手法であり、「主要なデータ分布」と異なる異常値(一般的なデータ分布から逸脱した値)を見つけることができます。たとえば、クレジットカード取引から詐欺事件を見つけたり、通常のネットワークデータフローから侵入を見つけたりする際に使用され、非常に広範で実用的な商業価値があります。同時に、これは機械学習タスクの前処理(preprocessing)にも使用でき、少数の異常点の存在によるトレーニングや予測の失敗を防ぐのに役立ちます。
今日紹介するツールライブラリ、Python Outlier Detection(PyOD)は、現在最も人気のあるPython異常検知ツールライブラリであり、主な特徴は次のとおりです:
約20種類の一般的な異常検知アルゴリズムが含まれています。例えば、LOF/LOCI/ABODなどのクラシックな手法から、GAN(Generative Adversarial Network)やアンサンブル異常検知(outlier ensemble)などの最新の深層学習手法まで。
異なるPythonバージョンをサポート:2.7および3.5+。また、Windows、macOS、Linuxなど、複数のオペレーティングシステムをサポートしています。
シンプルで使いやすく、一貫したAPI。数行のコードで異常検知が完了し、多くのアルゴリズムを評価するのに便利です。
JITおよび並列処理(parallelization)を使用して最適化されており、アルゴリズムの実行を高速化し、スケーラビリティを向上させ、大量のデータを処理できます。
2018年5月の正式リリース以来、PyODは300,000回以上ダウンロードされ、2,500以上のGitHubスターを獲得し、すべてのGitHubデータマイニング(data mining)ツールライブラリ[1]で8位にランクインしています。PyODの論文はまた、Journal of Machine Learning Research(JMLR)に掲載されています。同時に、PyODは多くの学術研究[2][3][4][5][6]にも応用されており、私も以前の回答でPyODを使用したことがあります。「データ探索でよく使用される「異常検知」アルゴリズムは何ですか?」。
現時点で、すべてのドキュメントと例が英語であるため、皆さんが利用しやすくするために、この中文使用ガイドを特別に作成しました。転載歓迎(許可は不要)。
パッケージの概要(package overview)
PyODは約20種類の異常検知アルゴリズムを提供しています(詳細は図1を参照)。一部のアルゴリズムの説明は、「データ探索でよく使用される「異常検知」アルゴリズムは何ですか?」や異常検知の分野のクラシックな教科書[7]を参照してください。また、このツールライブラリにはデータ可視化や結果評価など、さまざまな補助機能も含まれています。

ツールライブラリに関する重要な情報は以下の通りです:
GitHubのリポジトリ: pyod
PyPIでのダウンロードリンク: pyod
ドキュメントとAPIの紹介(英語): Welcome to PyOD documentation!
Jupyter Notebookの例(notebooksフォルダ): Binder (beta)
JMLR論文: PyOD: A Python Toolbox for Scalable Outlier Detection
ツールライブラリに関する重要な情報は以下の通りです:
GitHubのリポジトリ: pyod
PyPIでのダウンロードリンク: pyod
ドキュメントとAPIの紹介(英語): Welcome to PyOD documentation!
Jupyter Notebookの例(notebooksフォルダ): Binder (beta)
JMLR論文: PyOD: A Python Toolbox for Scalable Outlier Detection
PyODのインストールは非常に簡単で、個人的にはpipを使用することをお勧めします:
pip install pyod
GitHubからのインストール: pyod
PyPIからのインストール: pyod
組み込まれているアルゴリズムの使用も簡単です。各アルゴリズムには対応する例があり、APIを学ぶのに便利です(examplesフォルダ)。例えば、LOFアルゴリズムの対応する例はlof_example.pyと呼ばれています。これを見つけるのは非常に簡単です。その他にも、作者は対話型のJupyter Notebookの例を提供しており、インストールが不要で、ブラウザから直接notebookを開いてPyODツールライブラリを試すことができます。
API参照と例(API References & Examples)
特に注意すべきなのは、異常検出アルゴリズムは基本的には非監視学習であるため、X(入力データ)だけで十分であり、y(ラベル)は不要です。PyODの使用方法は、Sklearnのクラスタリングと非常に似ており、その検出器(detector)は統一されたAPIを持っています。PyODのすべての検出器clfは、使用しやすいように統一されたAPIを持っており、完全なAPIの使用方法は(API CheatSheet - pyod 0.6.8 documentation)で確認できます:
fit(X): データXで検出器clfを"トレーニング/フィット"します。つまり、検出器clfを初期化した後、Xを使用してそれを"トレーニング"します。
fit_predict_score(X, y): データXで検出器clfをトレーニングし、Xの予測値を予測し、実際のラベルyで評価します。ここでのyは評価用であり、トレーニング用ではありません。
decision_function(X): 検出器clfがfitされた後、この関数を使用して未知のデータの異常度を予測できます。返される値は0と1ではなく、元のスコアです。スコアが高いほど、そのデータポイントの異常度が高くなります。
predict(X): 検出器clfがfitされた後、この関数を使用して未知のデータの異常ラベルを予測できます。返される値は2クラスのラベル(0は正常点、1は異常点)です。
predict_proba(X): 検出器clfがfitされた後、未知のデータの異常確率を予測し、その点が異常点である確率を返します。
検出器clfが初期化され、fit(X)関数が実行されると、clfは2つの重要な属性を生成します:
decision_scores: データXの異常スコア。スコアが高いほど、そのデータポイントの異常度が高くなります。
labels_: データXの異常ラベル。返される値は2クラスのラベル(0は正常点、1は異常点)です。
検出器clfがトレーニングされた後(fit関数が実行された後)、decision_function()およびpredict()関数を使用して未知のデータに対して予測できます。
この背景知識を持って、PyODを使用して単純な異常検出の例を実装できます。
このコードは、PyODのk最近傍(kNN)検出器を使用して異常検出を行う例です。以下はコードの説明です:
from pyod.models.knn import KNN # kNN分類器をインポート
kNN検出器をトレーニングする
clf_name = 'kNN'
clf = KNN() # 検出器clfを初期化
clf.fit(X_train) # X_trainを使用して検出器clfをトレーニング
X_trainの異常ラベルと異常スコアを返す
y_train_pred = clf.labels_ # X_trainの分類ラベルを返す(0:正常、1:異常)
y_train_scores = clf.decision_scores_ # X_trainの異常スコアを返す(スコアが大きいほど異常)
トレーニングされたclfを使用して未知のデータで異常値を予測する
y_test_pred = clf.predict(X_test) # 未知のデータの分類ラベルを返す(0:正常、1:異常)
y_test_scores = clf.decision_function(X_test) # 未知のデータの異常スコアを返す(スコアが大きいほど異常)
説明:
from pyod.models.knn import KNN: PyODライブラリのkNN分類器モデルをインポート。
clf = KNN(): kNN検出器のインスタンスを作成。
clf.fit(X_train): トレーニングデータX_trainを使用して検出器clfをトレーニング。
y_train_pred = clf.labels_: トレーニングデータX_trainの異常ラベルを返し、0は正常、1は異常を示します。
y_train_scores = clf.decision_scores_: トレーニングデータX_trainの異常スコアを返し、スコアが高いほど異常を示します。
y_test_pred = clf.predict(X_test): トレーニングされたclfを使用して未知のデータX_testで異常を予測し、分類ラベルを返します。
y_test_scores = clf.decision_function(X_test): 未知のデータX_testの異常スコアを返し、スコアが高いほど異常を示します。
このコードは、異常検出器の予測結果を評価し、可視化するための追加の部分です。以下はコードの説明です:
予測結果を評価
print("\nテストデータに対する評価:")
evaluate_print(clf_name, y_test, y_test_scores)
可視化
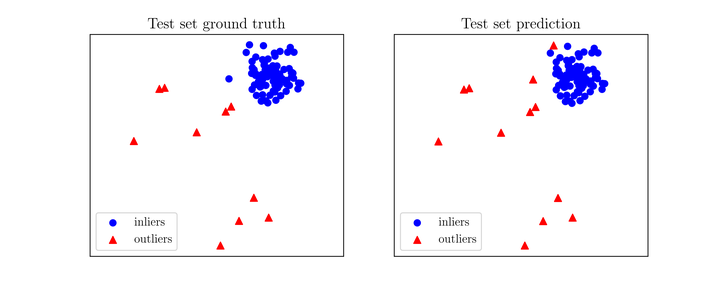
visualize(clf_name, X_train, y_train, X_test, y_test, y_train_pred,
y_test_pred, show_figure=True, save_figure=False)
説明:
evaluate_print(clf_name, y_test, y_test_scores): evaluate_print関数を使用して、テストデータに対する予測結果の評価を印刷します。評価には、異常検出器の名前(clf_name)、テストデータの実際のラベル(y_test)、および予測された異常スコア(y_test_scores)が含まれます。
visualize(clf_name, X_train, y_train, X_test, y_test, y_train_pred, y_test_pred, show_figure=True, save_figure=False): visualize関数を使用して、トレーニングデータとテストデータの異常検出の結果を可視化します。可視化には、異常検出器の名前(clf_name)、トレーニングデータ(X_train、y_train、y_train_pred)、およびテストデータ(X_test、y_test、y_test_pred)が含まれます。show_figureパラメータは、可視化を表示するかどうかを制御し、save_figureパラメータは可視化を保存するかどうかを制御します。
これにより、異常検出器の性能をテストデータに対して評価し、可視化できるようになります。