この記事は個人的なお勉強用のメモです。
このお勉強の位置
深層学習 Day 1
Section 0 ニューラルネットワークの全体像
Section 1 入力層~中間層
Section 2 活性化関数 ← これ
Section 3 出力層
Section 4 勾配降下法
Section 5 誤差逆伝播法
講義
活性化関数
活性化関数の式
f^{(l)}(u^{(l)})=\Big[f^{(l)}(u_1^{(l)}) .. f^{(l)}(u_j^{(l)})\Bigr]
$f$:活性化関数
$u$:総入力
$l$:何層目か
活性化関数 $f$ は総入力 $u$ を引数にとる。
活性化関数は非線形な関数。
※ 活性化関数が線形な関数だと2つの層の数式をまとめることができてしまい、
もはや中間層の意味がなくなる、とのこと。
活性化関数の種類
-
中間層用
-
ReLU関数(れる、と読む)
-
シグモイド(ロジスティック)関数
-
ステップ関数
-
出力層用
-
ソフトマックス関数
-
恒等写像
-
シグモイド(ロジスティック)関数
ステップ関数
サンプルコード
def step_function(x):
if x > 0:
return 1
else:
return 0
数式
f(x) = \left\{
\begin{array}{ll}
1 & (x \geq 0) \\
0 & (x \lt 0)
\end{array}
\right.
以前は使われていたが、現在は使われていない。
余談だが、上記のサンプルコードと数式は一致していないと思う。
$x$ が $0$ のときサンプルコードでは $0$ を返すが、
数式では $1$ を返す。
手元にある『ゼロから作る Deep Learning』の 3.1.2 項では、
$x$ が $0$ のときステップ関数は $0$ を返す関数として
数式が書かれている。3.2.2 項に書かれているソースコードも同様。
つまり、数式とソースコードが一致している。
シグモイド関数
サンプルコード
def sigmoid(x):
return 1 / (1 + np.exp(-x))
数式
f(u) = \frac{1}{1+e^{-u}}
0から1の間の値を返す。
右肩上がり。
微分可能
よく使われる。
課題:勾配消失問題を起こす。
ReLU関数
サンプルコード
def relu(x):
return np.maximum(0, x)
数式
f(x) = \left\{
\begin{array}{ll}
x & (x \gt 0) \\
0 & (x \leq 0)
\end{array}
\right.
今最もよく使われている。
勾配消失問題が起きない。
良い意味でスパース化する(0より小さい値を0にするので)。
活性化関数の効果
- 重み $W$ での計算は線形、活性化関数 $f$ は非線形なので、バラエティーに富むモデルを作れる。
- 一部の出力は弱く、一部は強く伝播される。
- 学習が進んで、特徴をつかんでいく。
実装演習
実装演習での活性化関数は、functions.py ファイルにまとめられている。

どの関数もシンプルな実装になっており、
PythonがAIの実装に最適とよく言われることに
納得できる。
確認テスト
線形と非線形の違い
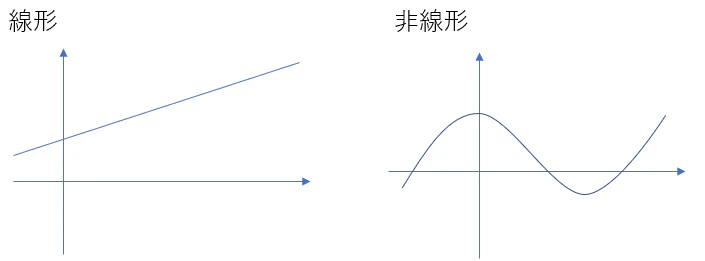
線形は比例である。
非線形は比例ではない。
線形な関数
- 加法性:$f(x+y)=f(x)+f(y)$
- 斉次性:$f(kx)=kf(x)$
非線形な関数は上の2つを満たさない。
該当するソースコード
$z = f(u)$ に該当するソースコード

上記の 2つのfunction.relu(...) の部分。
修了テスト~練習問題~
問題81(ReLU関数)
数式
h(x) = \left\{
\begin{array}{ll}
x & (x \gt 0) \\
0 & (x \leq 0)
\end{array}
\right.