この記事は個人的なお勉強用のメモです。
講義
予備知識
線形回帰モデルを説明する前に、機械学習モデリングプロセス等についても触れる。
機械学習モデリングプロセス
- 問題設定
- データ選定
- データの前処理
- 機械学習モデルの選定
- モデルの学習(パラメータ推定)
- モデルの評価
「1.問題設定」が一番重要。
機械学習をすることが目的ではない。
ルールベースで充分なことも。
問題が解ければ、どのような手段でも構わない。
機械学習
トム・ミッチェルによる機械学習の定義
コンピュータプログラムは、タスクT(アプリケーションにさせたいこと)を
性能指標Pで測定し、その性能が経験E(データ)により改善される場合、
タスクTおよび性能指標Pに関して経験Eから学習すると言われている。
つまり、経験EによってタスクTが学習する。
学習したかどうかを性能指標Pで測定する、ということ。
線形回帰モデル
-
回帰問題
入力から連続の出力を予測する問題のこと。(出力は連続値であることがポイント)
例:不動産における部屋数や築年数などのデータから不動産の価格を予測 -
直線で予測:線形回帰
-
曲線で予測:非線形回帰
-
扱うデータ
-
入力:m次元のベクトル
-
出力:スカラー値
. -
線形回帰モデル
-
回帰問題を解くためのモデル
-
教師あり学習
-
数式
\begin{align}
\hat{y}&=w^Tx+w_0\\
&=\sum_{j=1}^m w_j x_j + w_0
\end{align}
$x$ を与えると1つの $\hat{y}$ が求まる。これが予測。
(予測値にはハットを付ける。ハットなしは正解データを指す。)
予測をするにはモデルの作成が必要。
モデルを作成するというのは、既知のデータ($x$ と $y$)を元に $w$ を求めるということ。
$w$ を求めるには、最小二乗法を使う。
-
線形回帰モデルの種類
-
単回帰モデル($m$ が1次元)
-
重回帰モデル($m$ が2次元以上)
-
単回帰モデル(誤差あり)
\begin{align}
y=w_0+w_1x_1+\epsilon(誤差)
\end{align}
学習データ $x1$ と $y$ を元に、$w_0$ と $w_1$ を決める(=モデルを作る)。
連立方程式を解く。
- 重回帰モデル(2次元、誤差あり)
\begin{align}
y=w_0+w_1x_1+w_2x_2\epsilon(誤差)
\end{align}
単回帰モデルと同様に連立方程式を解く。
データの分割
手元のデータを2つに分ける。
- 学習用データ
- 検証用データ
検証用データを未知のデータとして使う。
精度を測定する。
最小二乗法
平均二乗誤差(残差平方和)
MSE:Mean Squared Error
MSE_{train}=\frac{1}{n_{train}} \sum_{i=1}^{n_{train}} \Bigl(\hat{y}_i^{(train)}-y_i^{(train)}\Bigr)^2
直線の値とデータとの差を二乗して総和をとる。$n$ で割る。
データ $x$ や $y$ は既知。パラメータ $w$ が未知。
つまり、パラメータに依存した関数。
\begin{align}
\hat{y}_i&=w_0+w_ix_i\\
y_i&=w_0+w_ix_i+\epsilon_i
\end{align}
1式目から2式目を引くと
\begin{align}
\hat{y}_i-y_i&=\epsilon_i
\end{align}
MSE=\frac{1}{n}\sum_{i=1}^n \epsilon_i
とも。
※ 誤差($\epsilon$)を二乗、和、平均(nで割る)=平均二乗 誤差
※ 一般に外れ値(大きな誤差)に弱い。平均二乗誤差が大きくなってしまう。
外れ値が無いかをまず確認する必要がある。
※ 外れ値に強い損失関数としては、Huber損失やTukey損失がある。
最小二乗法
最小二乗法は平均二乗誤差を最小にするパラメータを求める方法。
微分して勾配(傾き)が0になる点を求める。
回帰係数
\hat{w}=\arg \min_{w \in R^{m+1}} MSE_{train}
MSEを最小化するパラメータ $w$ を返す、という意味。
微分によって、回帰係数 $w$ についての以下の式が求まる。
\hat{w}=\Bigl(X^{(train)T}X^{(train)}\Bigr)^{-1}X^{(train)T} y^{(train)}
上の式は、回帰係数 $w$ が、データ $x$ と $y$ によって求まることを意味している。
予測値
\begin{align}
\hat{y}
&=X\hat{w}\\
&=X\Bigl(X^{(train)T}X^{(train)}\Bigr)^{-1}X^{(train)T} y^{(train)}
\end{align}
最尤法
最尤法という方法でも、回帰係数を求められる。
詳細は省略。
【参考】最小二乗誤差の微分
\begin{align}
\frac{\partial}{\partial w}MSE&=0\\
\frac{\partial}{\partial w}\biggl(\frac{1}{n}\sum_i (\hat{y_i}-y_i)^2\biggr)&=0\\
\frac{\partial}{\partial w}\biggl(\frac{1}{n}\sum_i (x_i^T w-y_i)^2\biggr)&=0\\
\frac{\partial}{\partial w}\biggl(\frac{1}{n}(Xw-y)^T(Xw-y)\biggr)&=0\\
\frac{1}{n}\frac{\partial}{\partial w}\biggl((w^TX^T-y^T)(Xw-y)\biggr)&=0\\
\frac{1}{n}\frac{\partial}{\partial w}\biggl(w^TX^TXw-w^TX^Ty-y^TXw+y^Ty\biggr)&=0\\
w^TX^Ty と y^TXw は同じ値なので\\
\frac{1}{n}\frac{\partial}{\partial w}\biggl(w^TX^TXw-2w^TX^Ty+y^Ty\biggr)&=0\\
w^TX^TXw は w の2次項、-2w^TX^Ty は w の1次項\\
公式:\frac{\partial w^Tx}{\partial w}=x, \frac{\partial w^TAw}{\partial w}=(A+A^T)x=2Ax (Aは対称行列)\\
\frac{1}{n}\biggl(2X^TXw-2wX^Ty\biggr)&=0\\
2X^TXw-wX^Ty&=0\\
2X^TXw&=2wX^Ty\\
(X^TX)^{-1}(X^TX)w=(X^TX)^{-1}X^Ty\\
w=(X^TX)^{-1}X^Ty\\
\end{align}
行列の計算については、Matrix Cookbookが参考になる。
実装演習(scikit-learn)
スペースの都合上、以下の2つの実行結果のみキャプチャ。
- 重回帰分析の回帰係数と切片の出力結果

なぜか重回帰分析で回帰係数と切片を出力するときに参照する変数が model になっていたので
model を model2 に変更して実行した。
重回帰分析の場合、回帰係数は約-0.26と8.39。
前者のマイナスの値は犯罪発生率(CRIM)であり、犯罪発生率が高ければ高いほど価格は下がる、というイメージに一致する。
後者のプラスの値は部屋数(RM)であり、部屋数が多ければ多いほど価格は上がる、というイメージに一致する。
- 最後のグラフ表示
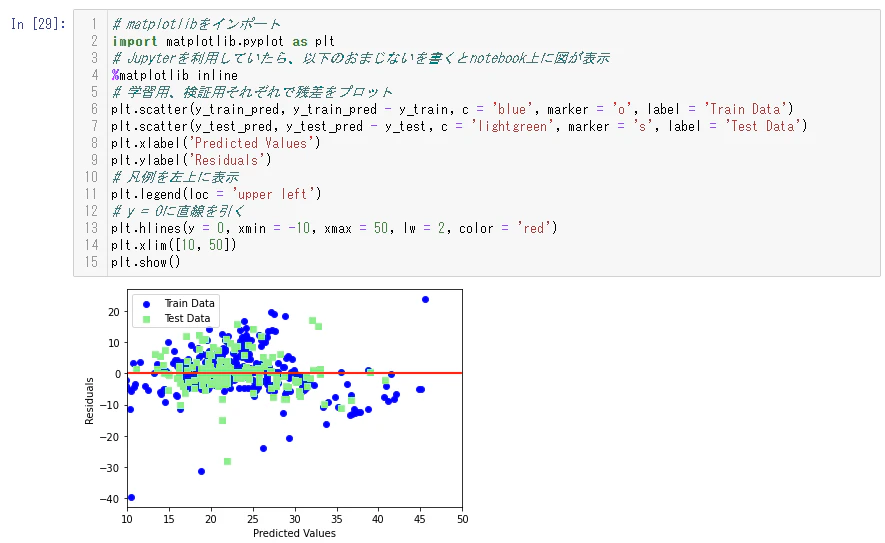
このグラフから読み取れるのは、Train DataとTest Dataの傾向が同じであること。
つまり、Train Dataを元にして予測したTest Dataの結果は、Train Dataと比べて分布に大きな差がなく、
予測の精度がある程度正しいことを意味していると思われる。
実装演習サマリー(scikit-learn)
- scikit-learnのモジュールを読み込む。
- ボストンデータ(入力データと出力データ)を読み込む。
- 読み込んだデータをデータフレームに入れる。
- df['RM']変数(部屋数)を学習用の説明変数dataに入れる。(単回帰分析)
- df['PRICE'](価格)を学習用の目的変数targetに入れる。
- 線形回帰用のクラスLinearRegressionからインスタンスを作る。
- fit関数にdata(説明変数)とtarget(目的変数)を指定することで、学習する。
- predift関数に予測したい値を入力することで、予測値を出力する。
重回帰分析の場合は、説明変数にCRIM(犯罪率)とRM(部屋数)を用いている。
scikit-learnの場合は、fit関数やpredift関数によって勝手に学習や予測をしてくれるので
利用者はその内部の作りを知らなくても学習や予測ができる。
実装演習(NumPy)
予測の結果をグラフ表示

青い線:正解値を直線で表したもの
青い丸:青い線の関数を元に、誤差を加えたもの
橙の線:青い丸のデータを元に、傾きと切片を求めたもの
青い線と橙の線がほぼ一致していることから、正解に対してかなり精度の高い予測ができていることがうかがえる。
重回帰分析
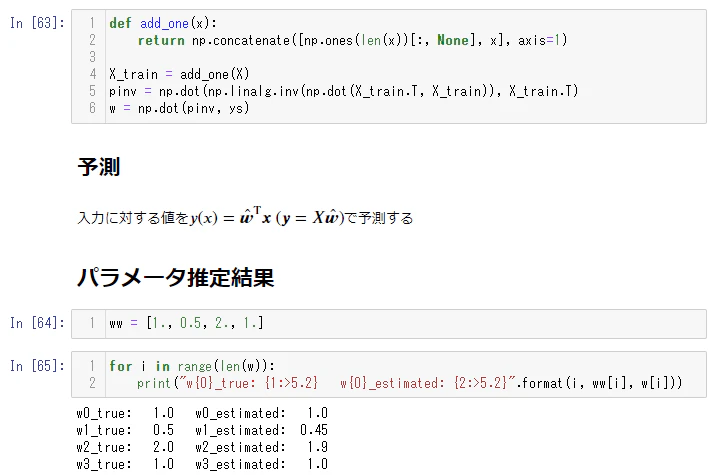
上の $w$ を求めるコードは、コメントアウトされていたので、コメントアウトを解除した。
真のパラメータと推定したパラメータがほぼ一致していることが確認できる。
実装演習サマリー(NumPy)
- 訓練データを作成する。訓練データは、$y=2x+5$ にランダムな誤差を加えたもの。
- 訓練データを元に傾きと切片を求める。最小二乗法の式を事前に微分して計算して得られた式を使う。その式はこちら。
y(x)=ax+bのとき\\
\hat{a}=\frac{Cov[x,y]}{Var[x]}\\
\hat{b}=\mu_y-\hat{a}\mu_x
$\hat{a}$ の分子は $x$ と $y$ の共分散。
$\hat{a}$ の分母は $x$ の分散。
このように $\hat{a}$ を簡潔な式で表せるのは、分散が偏差の二乗和で構成されているため。
共分散および分散は np.cov 関数で求める。
np.cov 関数にデータを渡すと、分散共分散行列が得られる。
分散共分散行列から、共分散と分散を抽出する。
3.100件のサンプルに対して、2. で求めた傾きと切片を使って出力値を予測する。
重回帰分析
- 訓練データを作る。その式は $y=w_0+w_1x_1+w_2x_2+w_3x_3 + 誤差$ 。
- 事前に $\hat{w}$ をを求める式を微分しておく。$\hat{w}=(X^TX)^{-1}X^Ty$
- 正解のパラメータと推定したパラメータを表示して見比べる。
演習問題
1.1
線形回帰の特徴
- 教師あり学習 ... 1.1.1の解答
- 回帰手法. 1.1.1の解答
- 線形なモデルを学習
- 学習の際は二乗誤差を最小化 ... 1.1.2の解答
続きをやろうと思ったら、次の日には問題が無くなっていた。
終了テスト~練習問題~
問題79(MSE)
MSE=\frac{1}{n}\sum_{i=1}^n (y_i-f(x_i))^2
平均二乗誤差(MSE)
- データごとに平均との差を求める
- 差を二乗する
- 二乗した差の総和をとる
- データの個数で割る
問題83(最小二乗法)
y_i=\sum_{j=1}^K x_{ij} \beta_j + \beta_0 + \epsilon_i
このとき、
- 「すべての $i$ について誤差項は互いに独立」とあるので、$\epsilon_i$ は互いに無相関。
- 「すべての $i$ について誤差項は(中略)$\epsilon_i=N(0,\sigma^2)$ 」とあるので、分散はすべて $\sigma^2$ である。
- 「すべての $i$ について誤差項は(中略)$\epsilon_i=N(0,\sigma^2)$ 」とあるので、平均は $0$ である。
- $\epsilon_i$ と $x_{ij}$ の大小関係は不明。
問題84(最小二乗法)
誤差項 $\epsilon_i$ は正規分布に従う。
正規分布の式はこちら。
f(x) = \frac{1}{\sqrt{2\pi\sigma^2}}\exp \biggl(-\frac{(x-\mu)^2}{2\sigma^2}\biggr)
上記の式の $(x-\mu)$ は入力値 $x$ と平均値 $\mu$ の差(偏差)であることを踏まえると、
誤差項 $\epsilon_i$ も同様に偏差に相当するので、上記の $(x-\mu)$ の部分に以下の誤差項の式を代入する。
\epsilon_i=y_i-\Bigl(\sum_{j=1}^K x_{ij} \beta_j + \beta_0\Bigr)
すると、以下の式になる。
\begin{align}
f &= \frac{1}{\sqrt{2\pi\sigma^2}}\exp \biggl(-\frac{(x-\mu)^2}{2\sigma^2}\biggr)\\
&= \frac{1}{\sqrt{2\pi\sigma^2}}\exp \Biggl(-\frac{(y_i-\Bigl(\sum_{j=1}^K x_{ij} \beta_j + \beta_0\Bigr))^2}{2\sigma^2}\Biggr)
\end{align}
問題85(最小二乗法)
対数尤度関数
\begin{align}
l(\theta)
&=\log L(\theta)\\
&=
\sum_{i=1}^n \ln \Biggl[ \frac{1}{\sqrt{2\pi\sigma^2}}\exp \Biggl(-\frac{(y_i-\Bigl(\sum_{j=1}^K x_{ij} \beta_j + \beta_0\Bigr))^2}{2\sigma^2}\Biggr)\Biggr]
\\
&=
\sum_{i=1}^n\Biggl[-\ln(\sqrt{2\pi\sigma^2}) + \Biggl(-\frac{(y_i-\Bigl(\sum_{j=1}^K x_{ij} \beta_j + \beta_0\Bigr))^2}{2\sigma^2}\Biggr)\Biggr]
\\
&=
\sum_{i=1}^n\Biggl[-\frac{1}{2}\ln(2\pi\sigma^2) + \Biggl(-\frac{(y_i-\Bigl(\sum_{j=1}^K x_{ij} \beta_j + \beta_0\Bigr))^2}{2\sigma^2}\Biggr)\Biggr]
\\
&=
-\frac{n}{2}\ln(2\pi\sigma^2) -\frac{1}{2\sigma^2} \sum_{i=1}^n \Biggl((y_i-\Bigl(\sum_{j=1}^K x_{ij} \beta_j + \beta_0\Bigr))^2 \Biggr)
\end{align}